

前言
Redis作为一个很多大厂用来解决并发和快速响应的利器,极高的性能让它得到很多公司的青睐,我认为Redis的高性能和其底层的数据结构的设计和实现是分不开的。使用过Redis的同学可能都知道Redis有五种基本的数据类型:string、list、hash、set、zset;这些只是Redis服务对于客户端提供的第一层面的数据结构。其实内部的数据结构还是有第二个层面的实现,Redis利用第二个层面的一种或多种数据类型来实现了第一层面的数据类型。我想有和我一样对Redis底层数据结构感兴趣的人,那我们就一起来研究一下Redis高性能的背后的实现底层数据结构的设计和实现。
这里我们主要研究的是第二层面的数据结构的实现,其Redis中五种基本的数据类型都是通过以下数据结构实现的,我们接下来一个一个来看:
- sds
- ziplist
- quicklist
- dict
- skiplist
1. 动态字符串(SDS)
String类型不管是在什么编程语言中都是最常见和常用的数据类型,Redis底层是使用C语言编写的,但是Redis没有使用C语言字符串类型,而是自定义了一个Simple Dynamic String (简称SDS)作为Redis底层String的实现,其SDS相比于C语言的字符串有以下优势:
- 可动态扩展内存。sds表示的字符串是可以动态扩容的。因为C语言字符串不记录自身的长度,如果改动字符串长度,那就需要重新为新的字符串分配内存,如果不分配内存,可能会产生溢出。但是SDS不需要手动修改内存大小,也不会出现缓冲区溢出问题,因为SDS本身会记录存储的数据大小以及最大的容量,当超过了容量会自动扩容。
- 二进制安全(Binary Safe)。sds能存储任意二进制数据,不仅仅可以存储字符串,还能存储音频、图片、压缩文件等二进制数据。 SDS的api都会以处理二进制的方式来处理存放在buf数组里面,不会对数据做任何限制。
- 除此之外,sds还兼容了C语言的字符类型。
下面是Redis中SDS的部分源码。sds源码
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
其实我们可以通过源码发现sds的内部组成,我们发现sds被定义成了char类型,难道Redis的String类型底层就是char吗?其实sds为了和传统的C语言字符串保持类型兼容,所以它们的类型定义是一样的,都是char *,但是sds不等同是char。
真正存储数据的是在sdshdr中的buf中,这个数据结构除了能存储字符串以外,还可以存储像图片,视频等二进制数据,。SDS为了兼容C语言的字符串,遵循了C语言字符串以空字符结尾的惯例, 所以在buf中, 用户数据后总跟着一个\0. 即图中 "数据" + "\0" 是为所谓的buf。另外注意sdshdr有五种类型,其实sdshdr5是不使用的,其实使用的也就四种。定义这么多的类型头是为了能让不同长度的字符串可以使用不同大小的header。这样短字符串就能使用较小的 header,从而节省内存。
SDS概览如下图:
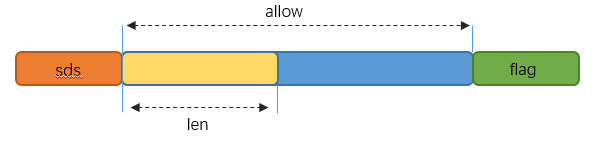
除了sdshdr5之外,其它4个header的结构都包含3个字段
- len: 表示字符串的真正长度(不包含
\0结束符在内)。 - alloc: 表示整个SDS最大容量(不包含
\0字节)。 - flags: 总是占用一个字节。其中的最低3个bit用来表示header的类型。header的类型共有5种,用到的也就4种,在sds.h中有常量定义。
2. 列表 list
2.1 底层数据结构
Redis对外暴露的是list数据类型,它底层实现所依赖的内部数据结构其实有几种,在Redis3.2版本之前,链表的底层实现是linkedList 和zipList,但是在版本3.2之后 linkedList和zipList就基本上被弃用了,使用quickList来作为链表的底层实现,ziplist虽然被被quicklist替代,但是ziplist仍然是hash和zset底层实现之一。
2.2 压缩链表 zipList 转 双向链表 linkedList
这里我们使用Redis2.8版本可以看出来,当我插入键 k5 中 110条比较短的数据时候,列表是ziplist编码,当我再往里面插入10000条数据的时候,k5的数据编码就变成了linkedlist。
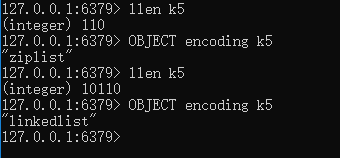
Redis3.2版本之前,list底层默认使用的zipList作为列表底层默认数据结,在一定的条件下,zipList 会转成 linkedList。Redis之所以这样设计,因为双向链表占用的内存比压缩列表要多, 所以当创建新的列表键时, 列表会优先考虑使用压缩列表, 并且在有需要的时候, 才从压缩列表实现转换到双向链表实现。在什么情况下zipList会转成 linkedList,需要满足一下两个任意条件:
- 这个字符串的长度超过 server.list_max_ziplist_value (默认值为 64 )。
- ziplist 包含的节点超过 server.list_max_ziplist_entries (默认值为 512 )。
这两个条件是可以修改的,在 redis.conf 中:
list-max-ziplist-value 64
list-max-ziplist-entries 512
注意:这里列表list的这个配置,只有在Redis3.2版本之前的配置中才能找到,因为Redis3.2和3.2以后的版本去掉了这个配置,因为底层实现不在使用ziplist,而是采用quicklist来作为默认的实现。
2.3 双向链表 linedList
当链表entry数据超过512、或单个value 长度超过64,底层就会将zipList转化成linkedlist编码,linkedlist是标准的双向链表,Node节点包含prev和next指针,可以进行双向遍历;还保存了 head 和 tail 两个指针。因此,对链表的表头和表尾进行插入的时间复杂度都为O (1) , 这是也是高效实现 LPUSH 、 RPOP、 RPOPLPUSH 等命令的关键。
2.4 压缩列表 zipList
虽然Redis3.2版本以后不再直接使用ziplist来实现列表建,但是底层还是间接的利用了ziplist来实现的。
压缩列表是Redis为了节省内存而开发的,Redis官方对于ziplist的定义是(出自Redis源码中src/ziplist.c注释):
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values,where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time. However, because every operation requires a reallocation of the memory used by the ziplist, the actual complexity is related to the amount of memory used by the ziplist
翻译:ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供
push和pop操作。
ziplist 将列表中每一项存放在前后连续的地址空间内,每一项因占用的空间不同,而采用变长编码。当元素个数较少时,Redis 用 ziplist 来存储数据,当元素个数超过某个值时,链表键中会把 ziplist 转化为 linkedlist,字典键中会把 ziplist 转化为 hashtable。由于内存是连续分配的,所以遍历速度很快。
2.4.1 压缩列表的数据结构
ziplist 是一个特殊的双向链表,ziplist没有维护双向指针:prev next;而是存储上一个 entry的长度和 当前entry的长度,通过长度推算下一个元素在什么地方,牺牲读取的性能,获得高效的存储空间,这是典型的"时间换空间"。
ziplist使用连续的内存块,每一个节点(entry)都是连续存储的;ziplist 存储分布如下:
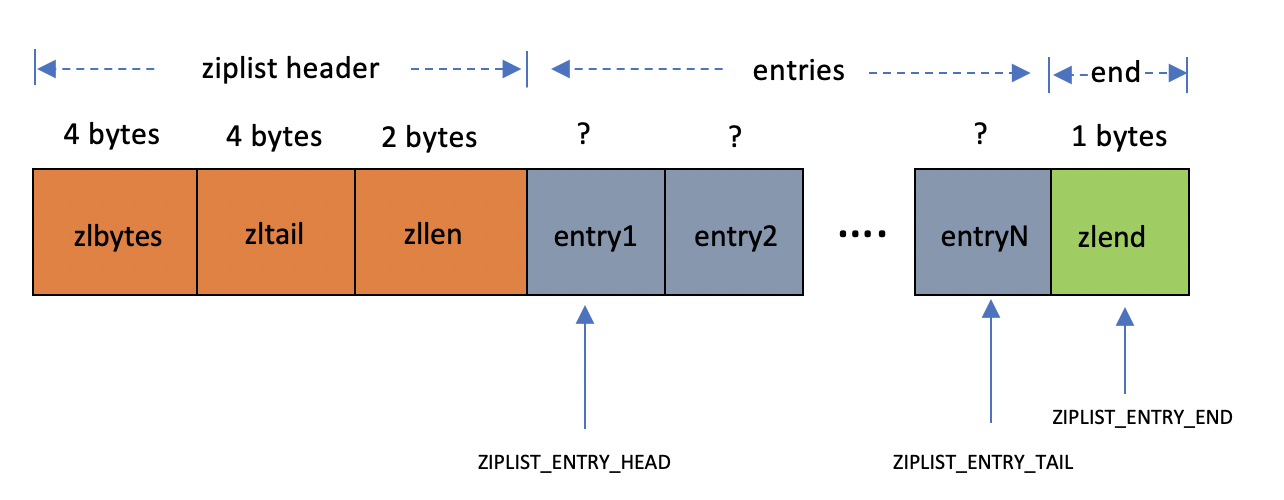
每个字段代表的含义。
zlbytes: 32bit,表示ziplist占用的字节总数(也包括zlbytes本身占用的4个字节)。zltail: 32bit,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。zltail的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。zllen: 16bit, 表示ziplist中数据项(entry)的个数。zllen字段因为只有16bit,所以可以表达的最大值为2^16-1。这里需要特别注意的是,如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以来表示。那怎么表示呢?这里做了这样的规定:如果zllen小于等于2^16-2(也就是不等于2^16-1),那么zllen就表示ziplist中数据项的个数;否则,也就是zllen等于16bit全为1的情况,那么zllen就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。entry: 表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构。zlend: ziplist最后1个字节,是一个结束标记,值固定等于255。
2.4.2 zipList节点entry结构
ziplist每一个存储节点、都是一个 zlentry。zlentry的源码在ziplist.c 第 268行
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* prevrawlensize是指prevrawlen的大小,有1字节和5字节两种*/
unsigned int prevrawlen; /* 前一个节点的长度 */
unsigned int lensize; /* lensize为编码len所需的字节大小*/
unsigned int len; /* len为当前节点长度*/
unsigned int headersize; /* 当前节点的header大小 */
unsigned char encoding; /*节点的编码方式:ZIP_STR_* or ZIP_INT_* */
unsigned char *p; /* 指向节点的指针 */
} zlentry;
- prevrawlen:记录前一个节点所占有的内存字节数,通过该值,我们可以从当前节点计算前一个节点的地址,可以用来实现表尾向表头节点遍历;prevrawlen是变长编码,有两种表示方法
- 如果前一节点的长度小于 254 字节,则使用1字节(uint8_t)来存储prevrawlen;
- 如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。
- len/encoding:记录了当前节点content占有的内存字节数及其存储类型,用来解析content用;
- content:保存了当前节点的值。 最关键的是prevrawlen和len/encoding,content只是实际存储数值的比特位。
2.4.3 为什么zipList 可以做到数据压缩
因为ziplist采用了一段连续的内存来存储数据,减少了内存碎片和指针的内存占用。其次表中每一项存放在前后连续的地址空间内,每一项因占用的空间不同,而采用变长编码,而且当节点较少时,ziplist更容易被加载到CPU缓存中。这也是ziplist可以做到压缩内存的原因。
2.4.4 为什么zipList被舍弃了
通过上面我们已经清楚的了解的ziplist的数据结构,在ziplist中每个zlentry都存储着前一个节点所占的字节数,而这个数值又是变长的,这样的数据结构可能会引起ziplist的连锁更新。假设我们有一个压缩链表 entry1 entry2 entry3 .......,entry1的长度正好是 253个字节,那么按照我们上面所说的,entry2.prevrawlen 记录了entry1的长度,使用1个字节来保存entry1的大小,假如现在在entry1 和 entry2之间插入了一个新的 new_entry节点,而new_entry的大小正好是254,那此时entry2.prevrawlen就需要扩充为5字节;如果entry2的整体长度变化又引起了entry3.prevrawlen的存储长度变化,如此连锁的更新直到尾结点或者某一个节点的prevrawlen足以存放之前节点的长度,当然删除节点也是同样的道理,只要我们的操作的节点之后的prevrawlen发生了改变就会出现这种连锁更新。
由于ziplist连锁更新的问题,也使得ziplist的优缺点极其明显;ziplist被设计出来的目的是节省内存,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存重新分配,可能导致内存拷贝。也使得后续Redis采取折中,利用quicklist替换了ziplist。
2.5 快速列表 quickList
基于上面所说,我们已经知道了ziplist的缺陷,所以在Redis3.2版本以后,列表的底层默认实现就使用了quicklist来代替ziplist和linkedlist?接下来我们就看一下quicklist的数据结构是什么样的,为什么使用quicklist作为Redis列表的底层实现,它的优势相比于ziplist优势在哪里,接下来我们就一起来看一下quicklist的具体实现。下面是我基于Redis3.2的版本做的操作,这里我们可以看到列表的底层默认的实现是quicklist对象编码。
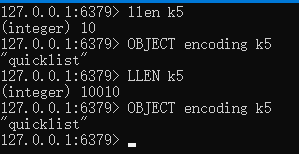
2.5.1 quicklist数据结构
quicklist整体的数据结构如下:
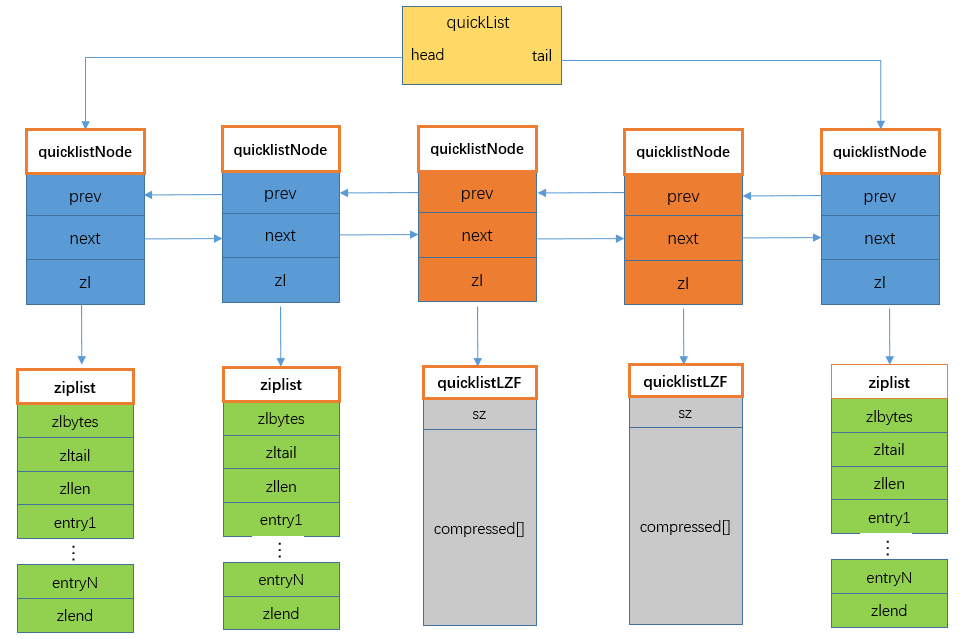
quicklist源码 redis/src/quicklist.h结构定义如下:
typedef struct quicklist {
quicklistNode *head; // 头结点
quicklistNode *tail; // 尾结点
unsigned long count; // 所有ziplist数据项的个数总和
unsigned long len; //quicklistNode的节点个数
int fill : QL_FILL_BITS; //ziplist大小设置,通过配置文件中list-max-ziplist-size参数设置的值。
unsigned int compress : QL_COMP_BITS; //节点压缩深度设置,通过配置文件list-compress-depth参数设置的值。
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
其实就算使用的quicklist结构来代替ziplist,那quicklist也是有一定的缺点,底层仍然使用了ziplist,这样同样会有一个问题,因为ziplist是一个连续的内存地址,如果ziplist太小,就会产生很多小的磁盘碎片,从而降低存储效率,如果ziplist很大,那分配连续的大块内存空间的难度也就越大,也会降低存储的效率。如何平衡ziplist的大小呢?那这样就会取决于使用的场景,Redis提供了一个配置参数list-max-ziplist-size可以调整ziplist的大小。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
当我们数据量很大的时候,最方便访问的数据基本上就是队列头和队尾的数据(时间复杂度为O(1)),中间的数据被访问的频率比较低(访问性能也比较低,时间复杂度是O(N),如果你的使用场景符合这个特点,Redis为了压缩内存的使用,提供了list-compress-depth这个配置能够把中间的数据节点进行压缩。quicklist内部节点的压缩算法,采用的LZF——一种无损压缩算法。
这个参数表示一个quicklist两端不被压缩的节点个数。参数list-compress-depth的取值含义如下:
- 0: 是个特殊值,表示都不压缩。这是Redis的默认值。
- 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
- 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
- 3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
- 依此类推
2.5.2 quicklistNode结构
quicklist是由一个个quicklistNode的双向链表构成。
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz;
char compressed[];
} quicklistLZF;
quicklist中的每个节点都是一个quicklistNode,其中各个字段的含义如下:
- prev: 指向链表前一个节点的指针。
- next: 指向链表后一个节点的指针。
- zl:数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。
- sz:表示zl指向的ziplist的总大小,需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小。
- count: 表示ziplist里面包含的数据项个数。
- encoding:表示ziplist是否压缩了(以及用了哪个压缩算法)。目前只有两种取值:2表示被压缩了(而且用的是LZF压缩算法),1表示没有压缩。
- container:在目前的实现中,这个值是一个固定的值2,表示使用ziplist作为数据容器。
- recompress: 当我们使用类似lindex这样的命令查看了某一项压缩之前的数据时,需要把数据暂时解压,这时就设置recompress = 1做一个标记,等有机会再把数据重新压缩。
- attempted_compress:这不太理解其含义。
- extra:扩展预留字段。
quicklist结构结合ziplist和linkedlist的优点,quicklist权衡了时间和空间的消耗,很大程度的优化了性能,quicklist因为队头和队尾操作的时间复杂度都是O(1),所以Redis的列表也可以被作用队列来使用。
3. 字典 dict
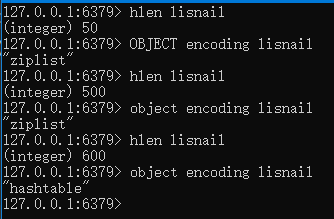
通过上图我们能够看到hash键的底层默认实现的数据结构是ziplist,随着hash键的数量变大时,数据结构就变成了hashtable,虽然这里的我们看到的对象编码格式hashtable,但是Redis底层是使用字典dict来完成了Hash键的底层数据结构,不过字典dict的底层实现是使用哈希表来实现的。Redis服务对于客户端来说,对外暴露的类型是hash,其底层的数据结构实现有两种,一种是压缩列表(ziplist),另外一种则是字典(dict);关于ziplist的,我们在说链表(list)的时候已经说过了,这里不重复去说了。我们这里就着重的去看一下字典(dict)的具体实现。
这里还是要说一下什么情况下会从ziplist转成hashtable呢?redis.conf中提供了两个参数
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
- 表示当hash键中key所对应的项(field,value)数>512 时候转为字典。
- 表示当hash键中key所对应的value长度超过64的时候转为字典
3.1 字典(dict)的实现
字典算是Redis比较重要的一个数据结构了,Redis数据库本身就可以看成是一个大的字典,Redis之所以会有很高的查询效率,其实和Redis底层使用的数据类型是有关系的,通常字典的实现会用哈希表作为底层的存储,redis的字典实现也是基于时间复杂度为O(1)的hash算法。
Redis源码其结构定义如下:dict源码定义
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
下图能更清晰的展示dict的数据结构。
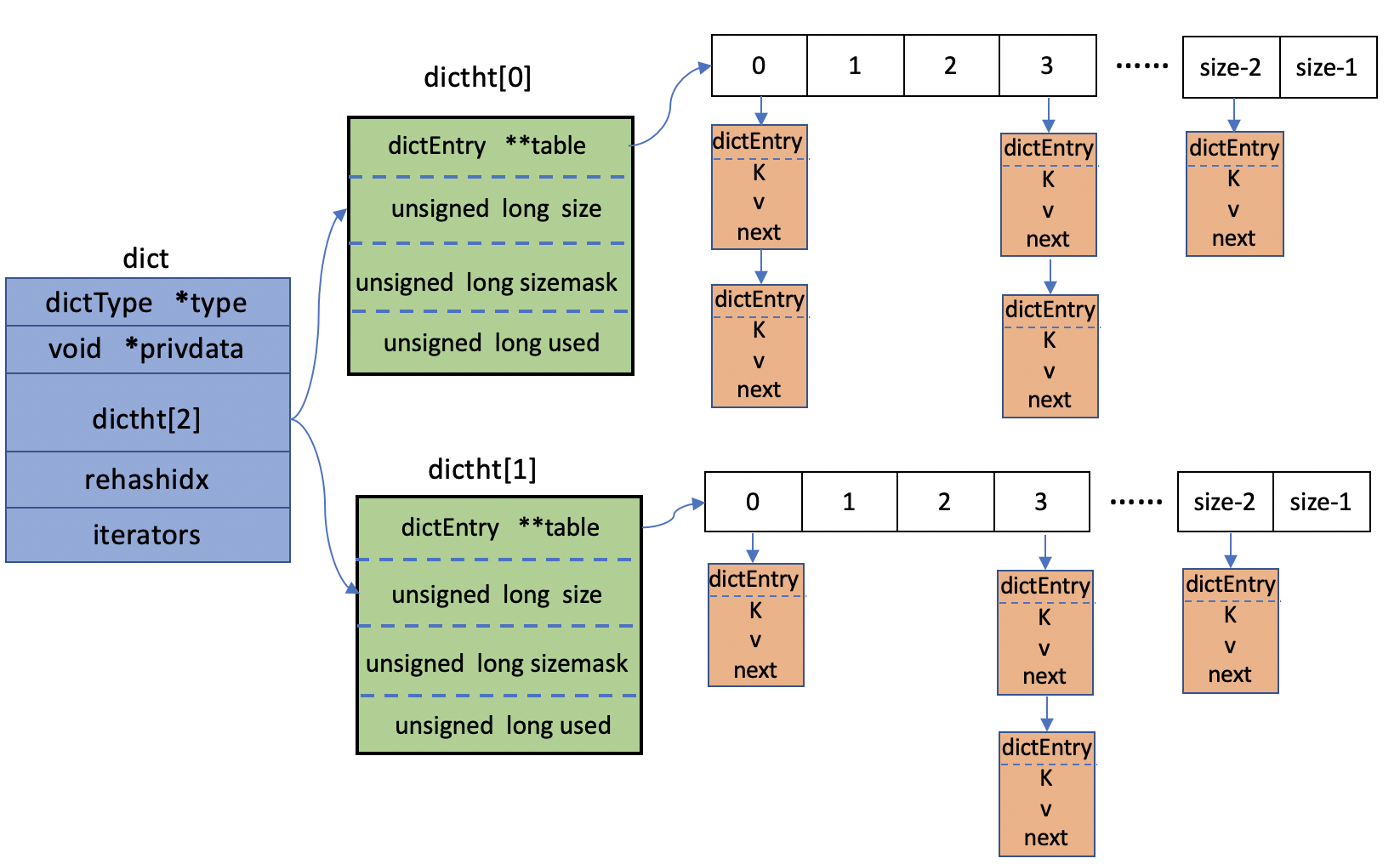
通过上图和源码我们可以很清晰的看到,一个字典dict的构成由下面几项构成:
- dictType: 一个指向dictType结构的指针(type),通过自定义的方式使得dict的key和value能够存储任何类型的数据。
- privdate: 一个私的指针,由调用者在创建dict的时候传进来。
- dictht[2]: 一个hash表数组,且数组的大小是2。只有在重哈希的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。
- rehashidex: 当前重哈希索引(rehashidx)。如果rehashidx = -1,表示当前没有在重哈希过程中;否则,表示当前正在进行重哈希,且它的值记录了当前重哈希进行到哪一步了。
- iterators: 当前正在进行遍历的iterator的个数。
这里最重要的还是dictht这个结构,dictht定义了一个哈希表,其结构由以下组成:
- dictEntry:一个dictEntry指针数组(table)。key的哈希值最终映射到这个数组的某个位置上(对应一个bucket)。如果多个key映射到同一个位置,就发生了冲突,那么就拉出一个dictEntry链表。熟悉Java的同学看到这里可能会想到HashMap,这里其实和HashMap的实现有些相像。
- size:标识dictEntry指针数组的长度。它总是2的指数。
- sizemask:用于将哈希值映射到table的位置索引。它的值等于(size-1),也就是数组的下标。这里其实和HashMap中计算索引的方法是一样的。
- used:记录dict中现有的数据个数。它与size的比值就是装载因子(load factor)。这个比值越大,哈希值冲突概率越高。
3.2 Redis中dict如何进行rehash的
整体看下来,有点类似于Java中HashMap的实现,在处理哈希冲突和数组的大小都是和Java中的HashMap是一样的,但是这里有一点不一样就是关于扩容的机制,Redis这里利用了两个哈希表,另外一个哈希表就是扩容用的。Redis中的字典和Java中的HashMap一样,为了保证随着数据量增大导致查询的效率问题,要适当的调整数组的大小,也就是rehash,也就是我们熟知扩容。我们这里不说Java中的HashMap的扩容了,这里主要看一下Redis中对于字典的扩容。
那么什么时候才会rehash呢?条件:
1. 服务器目前没有执行的BGSAVE命令或者BGREWRUTEAOF命令,并且哈希表的负载因子大于等于1;
2. 服务器目前正在执行BGSAVE命令或者BGREWRUTEAOF命令,并且哈希表的负载因子大于等于5;
那到底是如何进行rehash的,根据上面源码和数据结构图可以看到,字典中定义一个大小为2的哈希表数组,前面我们也说到了,在不进行扩容的时候,所有的数据都是存储在第一个哈希表中,只有在进行扩容的时候才会用到第二个哈希表。当需要进行rehash的时候,将dictht[1]的哈希表大小设置为需要扩容之后的大小,然后将dictht[0]中的所有数据重新rehash到dictht[1]中;而且Redis为了保证在数据量很大的情况rehash不太过消耗服务器性能,其采用了渐进式rehash,当数据量很小的时候我们一次性的将数据重新rehash到扩容之后的哈希表中,对Redis服务的性能是可以忽略不计的,但是当Redis中hash键的数量很大,几十万甚至上百万的数据时,这样rehash对Redis带来的影响是巨大的,甚至会导致一段时间内Redis停止服务,这是不能接受的。
Redis服务在需要rehash的时候,不是一次性将dictht[0]中的数据全部rehash到dictht[1]中,而是分批进行依次将数据重新rehash到dictht[1]的哈希表中。这就是采用了分治的思想,就算在数据量很大的时候也能避免集中式rehash带来的巨大计算量。当进行rehash的期间,对字典的增删改查都会操作两个哈希表,因为在进行rehahs的时候,两个哈希表都有数据,当我们在一个哈希表中查找不到数据的时候,也会去另一个哈希表查数据。在rehash期间的新增,不会在第一个哈希表中新增,会直接把新增的数据保存到第二个哈希表中这样可以确保第一个哈希表中的数据只减不增,直到数据为空结束rehash。
熟悉Java的同学可能会想起HashMap中扩容算法,其实包括从容量的设计上和内部的结构都有很多相似的地方,有兴趣的同学可以去了解一下,也可以参考我写的这篇文章《Java1.8中HashMap的骚操作》,相比于Redis中的字典的rehash的方式,我更喜欢的是Java中对于HashMap中精妙的rehahs的方式,其思想还是非常值得我们去借鉴的。
