

每隔一段时间我都会去看一些面试题,尝试着去回答,这样有助于逼自己对重要的知识做一个比较系统的复习。这次我看的是ArrayList和HashMap相关的面试题,整理了一些高频率的问题。
ArrayList基础知识和高频面试题
ArrayList的底层是数组,数组是使用很广泛很基础的数据结构,掌握ArrayList之前应该先熟悉数组。我总结了数组的一些重要知识。
- 初始化就要指定长度
- 顺序存储结构,按照次序连续存储到一整块物理空间上
- 数组的元素是通过索引访问的。数组索引从 0 开始,所以索引值从 0 到 nameArray.length-1。
- 数组的元素类型和数组的大小都是确定的
- 数组是便于快速查找的。
ArrayList是一个其容量能够动态增长的动态数组,在保留数组可以快速查找的优势的基础上,弥补了数组在创建后,要往数组添加元素的弊端。ArrayList的操作不是线程安全的!一般在单线程中才使用ArrayList。
ArrayList很重要的一点就是扩容,数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
ArrayList的基础知识就不多说了,下面来看看常见的一些面试题。
1.线程间 操作 List
在多线程环境下可以使用 Collections.synchronizedList() 或者 CopyOnWriteArrayList 来实现 ArrayList 的线程安全性。虽然 Vector(已废弃)每个方法也都有同步关键字,但是一般不使用,一方面是慢,另一方面是不能保证多个方法的组合是线程安全的(因为不是基于同一个monitor)。
使用Collections.synchronizedList()重点代码和注意事项
//这个方法根据传入的 List 返回一个支持同步(线程安全)的 List。接下来就可以利用这个返回的 List 进行串行访问了
final List<Integer> list = Collections.synchronizedList(Lists.newArrayList());
//但是,需要注意的是:当遍历返回列表时,必须手动对其进行同步,方法如下:
List list = Collections.synchronizedList(new ArrayList());
...
synchronized (list) {
Iterator i = list.iterator(); // 必须在同步代码块里
while (i.hasNext())
foo(i.next());
}
CopyOnWriteArrayList的重点代码
//但是如果不是写少读多的场景,使用 CopyOnWriteArrayList 开销比较大,因为每次对其更新操作(add/set/remove)都会做一次数组拷贝。
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
2.arraylist和linkedlist的区别,以及应用场景
ArryList基于数组实现,线程不安全,初始化时,elementData数组大小默认为10;每次add()时,先调用ensureCapacity()保证数组不会溢出,如果此时已满,会扩展为数组length的1.5倍+1,然后用array.copy的方法,将原数组拷贝到新的数组中;
Linkedlist基于双链表实现,初始化时,有个header Entry,值为null;使用header的优点是:在任何一个条目(包括第一个和最后一个)都有一个前置条目和一个后置条目,因此在LinkedList对象的开始或者末尾进行插入操作没有特殊的地方;
使用场景:
(1)如果应用程序对各个索引位置的元素进行大量的存取或删除操作,ArrayList对象要远优于LinkedList对象;
(2)如果应用程序主要是对列表进行循环,并且循环时候进行插入或者删除操作,LinkedList对象要远优于ArrayList对象;
3.List,Set,Map的区别
这个问题总结起来都是一篇文章了,这里我给出能找到答案的文章
HashMapArrayList基础知识和高频面试题
HashMap相关的面试题,基本上都是关于HashMap如何存取,以及哈希冲突,我们先来看看相关的基础知识。
HashMap是基于数组来实现哈希表的,主干是数组。数组中新增或查找某个元素,通过数组index(也就是索引),一次定位就可完成操作。
数组就相当于内存储空间,数组的index就好比内存的地址。HashMap的每个记录就是一个Entry<K, V>对象,每一个Entry包含一个key-value键值对,数组里存储的就是这些对象。现在我们看看是怎么样计算出每一个存储对象的内存地址的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码Hash值=(hashcode)^(hashcode >>> 16),Hashcode予hashcode自己向右位移16位的异或运算,利用key的hashcode计算出Hash值。下一步就是利用Hash值计算出下标。
上面的代码是put键值对时候的源码,框起来红色部分的代码就是得到下标的代码,看起来有些难懂,重写一下
i = (n - 1) & hash;//hash是上一步计算出来的hash值,n是底层数组的长度,用&运算符计算出i的值
p = tab[i];//用计算出来的i的值作为下标从数组中元素
if(p == null){//如果这个元素为null,用key,value构造一个Node对象放入数组下标为i的位置
tab[i] = newNode(hash, key, value, null);
}
复制代码i就是我们通过hash值算出来的下标,也就是存储的位置。上面我们看到源码的if语句,当tab[i]为null的时候,就直接存储对象,那么不为null呢?相关的源码如下
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
......
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 找到数组元素,hash相等同时key相等,则直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 该数组元素在链表长度>8后形成红黑树结构的对象
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 该数组元素hash相等,key不等,同时链表长度<8.进行遍历寻找元素,有就覆盖无则新建
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 新建链表中数据元素
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 链表长度>=8 结构转为 红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
复制代码先忽略红黑树的转换,总结一下上面代码:
- 判断当前确定的索引位置,是否存在hashcode和key元素都相同的,如果存在相同的hashcode和相同的key的元素,那么新值覆盖原来的旧值,并返回旧值。
- 如果存在相同的hashcode,那么他们确定的索引位置就相同,这时判断他们的key是否相同,如果不相同,这时就是产生了hash冲突。
- 产生了hash冲突,就引入了单链表。进行遍历寻找元素,有就覆盖,没有就新建。
以上是存储entry,过程比较复杂。获取数据相对来说比较简单,基本流程如下:
- 通过key的hashCode和寻址算法得到数组下标,若数组元素中的key和hash相等,则直接返回。
- 如果不相等,同时存在链表元素,就遍历链表元素进行匹配返回。
HashMap没有发生hash冲突,没有形成单链表,hashmap查找元素很快,get()方法能够直接定位到元素。出现单链表后,定位到的单个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止。如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。为了解决链表过长导致的性能问题,JDK1.8在JDK1.7的基础上增加了红黑树来进行优化。当链表超过8时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。 放上一张HashMap的结构图,网上找来的图
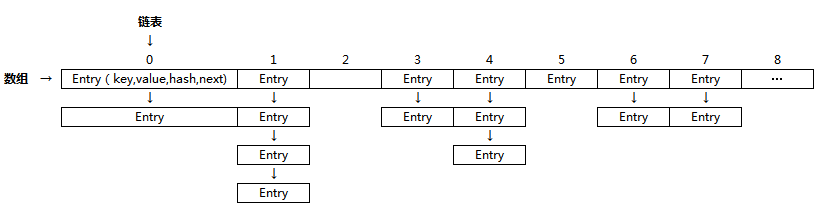
总结一下HashMap特性
- HashMap存储键值对实现 快速存取,允许为null。 2.** key值 不可重复。**
- 底层是hash表, 不保证有序(比如插入的顺序)
掌握好基础的知识,再去看面试题,这样加深印象。这里推荐一篇HashMap的面试题,里面也有答案。 【java集合】HashMap常见面试题
以上就是在关于ArrayList和HashMap相关的面试题,每题都掌握和理解,在面试时候就可以很从容了。
