


徐鸿飞,微医云计算团队前端工程师,在挨打的边缘徘徊的 JS 黑科技制造者。
众所周知,国内最强的体验是来自于阿里的体验技术部。但是,深入研究之后,其实,体验是针对行业的,体验对跨行业是不同的理解。所以,照搬电商行业的体验,除了让你在技术上可以吹水之外,对行业内是没有很大价值的。
本期,我将带领大家走进医疗行业的体验与设计。本期有如下几个阶段:
- 什么是体验
- 医疗行业的体验的着重点
- 我们是如何做的体验
- 我们未来的计划与设想
下面,就正式开始吧。

什么是体验
这个就比较仁者见仁了,对于电商行业来说,任何一个消费者,他们打开页面所带来的直观感受,都是体验,一个动画良好的过度,一个高效的内容渲染,一个精准的匹配策略等等。这些都是体验,举个栗子的话,斗鱼的直播网站,打开某个主播的直播页面,我们会看到直播的内容以最快的速度展示出来。
这就是良好的体验,我在最短的时间内看到了我想看到的东西。
但是这个体验如果照搬到其他行业呢?
一个电商行业,需要把什么优先放出来?商品图片?视频?价格?把握不准了。
再深入一点,如此多的设计,带来的价值是什么呢?
如果是医疗行业,这个体验有绝对的价值吗?可能有,但是绝对不是核心要素。
什么是医疗行业的体验
那我们来聊一聊,医疗行业的体验是什么。
推广层面
无论什么行业,都避免不了推广这个过程,推广层面的体验,我们可以理解为:
- 加载页面的时间
- 核心内容的可交互时间
这避免不了我们需要做体验分析,微医的全球抗疫系统,在对外提供医疗信息、义务咨询等方面提供了巨大的帮助,在全球范围内进行快速的支持,在这个过程中,我们经历了初期打开页面的耗时较长带来的用户流失率,到后面的性能优化后带来用户量的爆发。
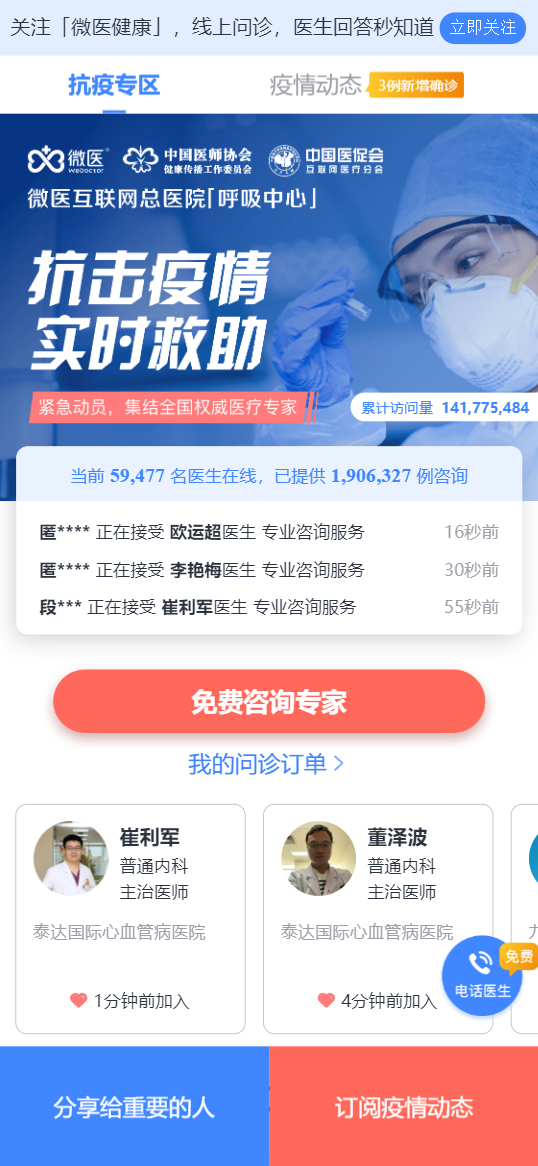
打开系统之后,如果是一个潜在的患者用户,他们最希望得到的是什么,很明显,是中间的 “免费咨询专家”,那么我们得到了体验环节的第一点:核心内容可交互的时间。
因此,对于医疗行业在推广层面上的体验,我们要抓住的点就是————可交互时间,当然这个时间也包含传统意义上的白屏时间,这点后续再说。
辅助层面
在微医,我们同样还有一些服务,是为了给医生提供辅助的效果,例如 CDSS 慢病管理系统中,医生在对患者的一些病状进行判定的时候,我们会在乎,这个系统需要花了多久才能打开吗?
你以为我会说不吗?很抱歉,我们确实需要在乎这个系统需要花多久才能打开(惊不惊喜)。但是,这不是最关键的因素。
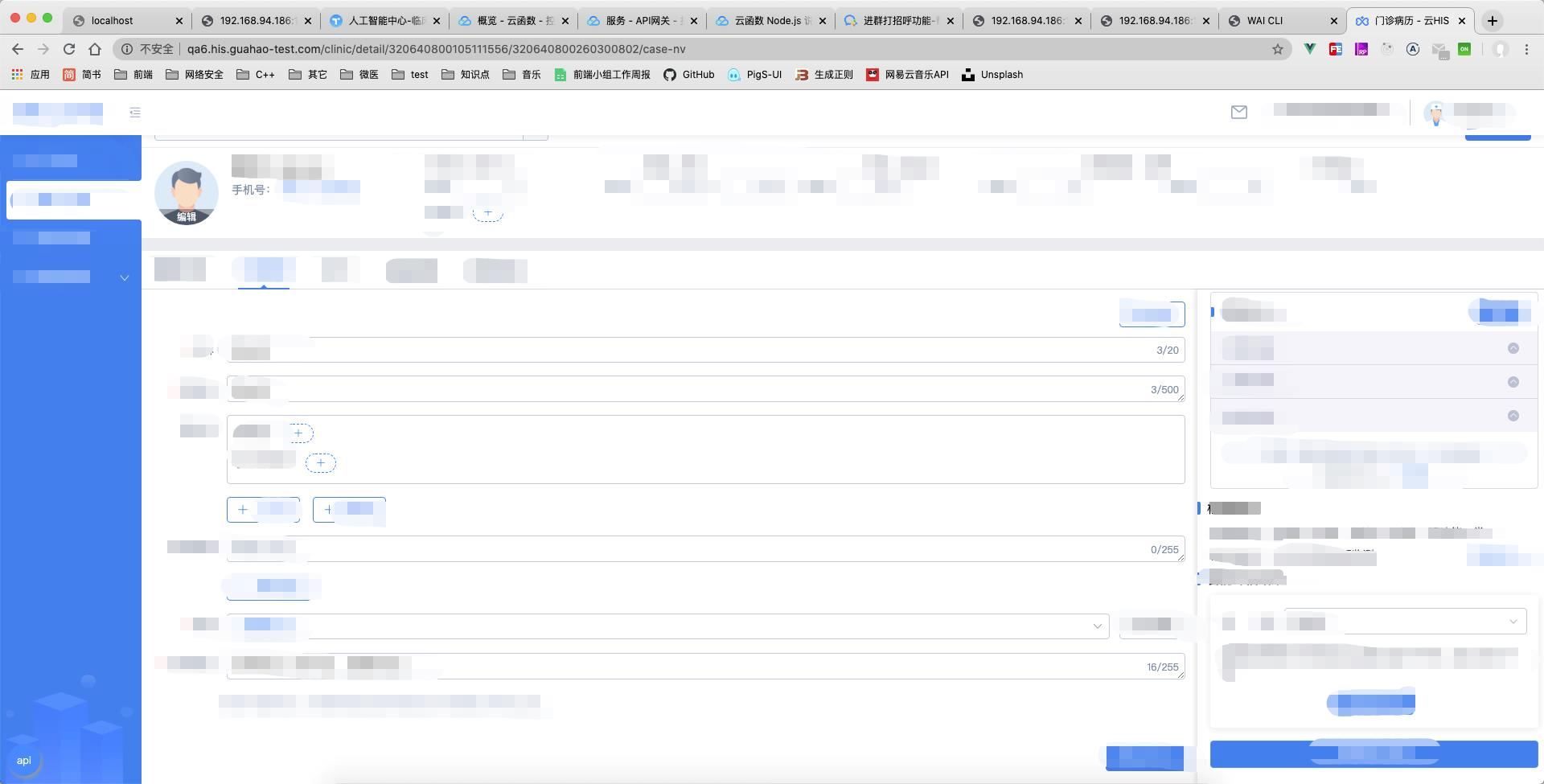
在上图中,如果用户开始输入,我们更在乎的是,在关联数据和表单填写时候的耗时,这些才是我们所在意的最有价值的。我们需要用各种手段,来降低医生在表单层面的填写时间,同时保证准确率不会下降。这些都是我们所考虑的体验。
医疗行业的体验的着重点
上面我们讲述了,关于医疗行业的一些体验的介绍。接下来,我们要聊一聊,在医疗行业中,我们的着重点了。
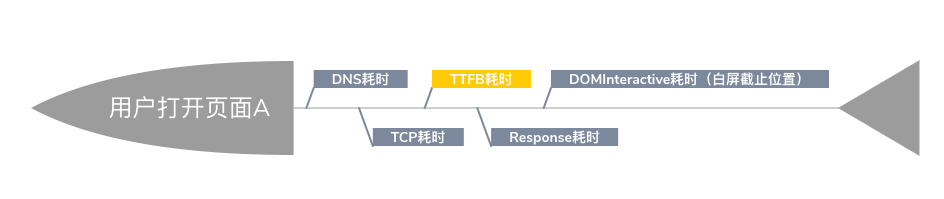
逃不开的话题就是首屏时间话题,不同的系统有不同的设计。在医疗行业中,我们的秒开率计算方式是通过如下的方式进行计算的:
DNS + TCP + TTFB + RESPONSE + DOMINTERACTIBE
上述公式可以简单理解为,截止到 DOMInteractive 可交互时间 位置,就是我们所计算的白屏时间。对应我们刚刚所讲述的原因,对于医疗系统来说,没有什么所谓的图片是否可见,所以我们不需要想市面上一些电商系统的白屏耗时是按照 MutationObserver 的变化状态来计算当前是否处于完整加载的状态。
我们进一步通过一个 秒开率 来统计这个数字,通过对秒开率的统计,我们可以看到当前系统的真实、可靠的数据。
通过接入体验中心之后,AI 的联盟前台一开始秒开率仅在 10-15% 左右,对于一个展示型 + 管理型系统,这样的秒开率确实对用户的留存率以及使用体验产生了重大的影响,通过我们的分析,发现在首屏渲染的时候,有大量 js 的资源在同步加载,后续我们分析出,实际的产生原因是没有采取动态引入机制,并且 webpack 打包没有良好的机制去处理打包之后的 chunk。之后,联盟前台进行了进一步的优化,到现在,系统的秒开率已经稳定在了 90% 左右。
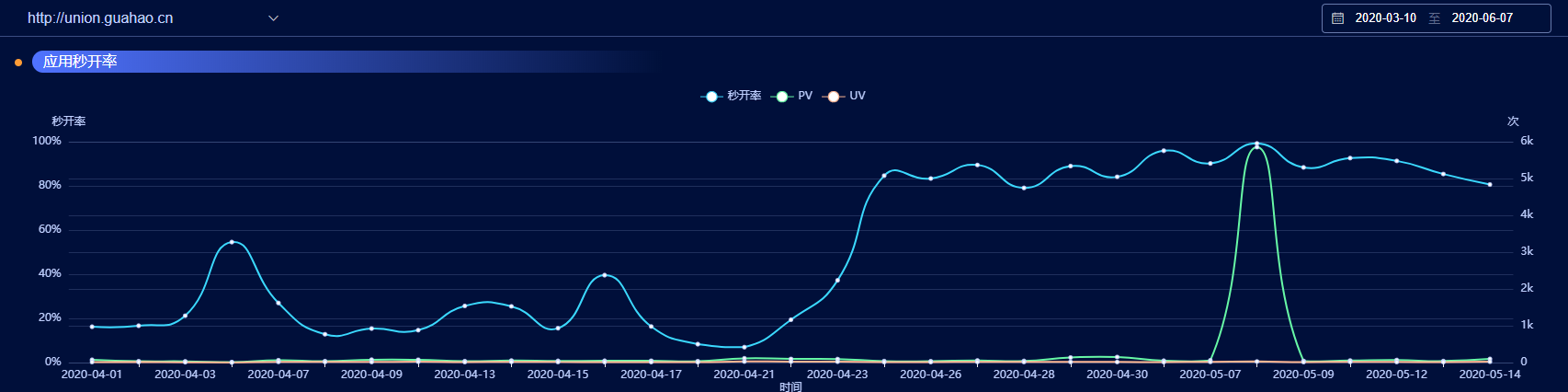
同样,秒开率可以看出来的数据还有很多。比如,活体检测系统,秒开率常年维持在 80% 左右,但是在某个时间段之间,我发现秒开率进行了持续性的下降,一度下降到了 60%,这是一个非常危险的警告,接下来我在排查过程中发现,通过对个别超标数据的分析,我发现在 DOM 请求完毕之后到可交互时间内,耗时异常,那么说明在资源加载的过程中,产生了一些预料之外的情况。后续仔细分析之后,我发现以 3G 网络进行模拟,秒开率确实无法提升,其中因为用到了一些图片,这些同步加载的图片在 4G 或者 WiFi 情况下是无法发现,在弱网络环境,建立 DNS 的耗时和一些其他网络损耗导致极大的增加了这个时间,同时也降低了本系统的秒开率,于是我采取一些措施,通过并发请求等机制,把一些 base64 的后较小的图片直接合并到 CSS 或者是 HTML 中,降低重复建立连接的耗时。其他的则利用其大小远小于 JS,那么合并到一个并发机制的体系。具体的一些就不在本期讲了,后续的话,有机会再说了(嘿嘿嘿,就是懒得写了)
业务耗时
对于医疗行业来说,用户进入这个页面后,需要多久才能出去,这很大影响了我们在此处业务设计的是否合理,是否有很多冗余、复杂、多变的选项干扰了用户的使用,从而降低了我们的用户数量。
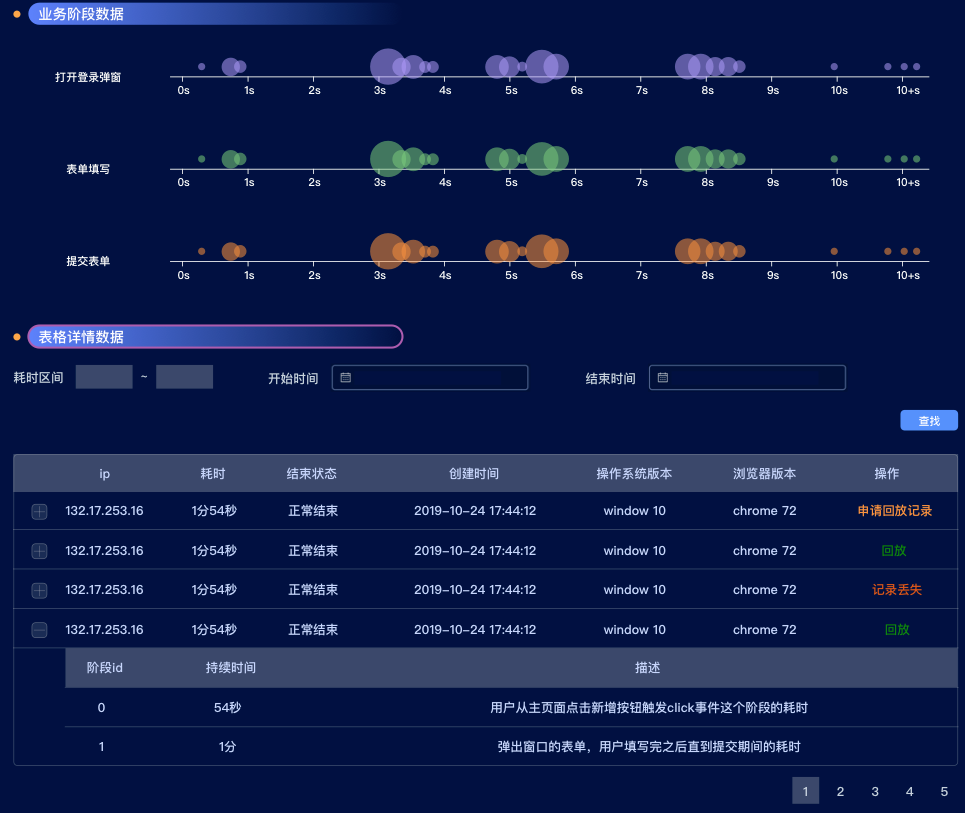
在这里,我们还在探索的阶段,例如用户长时间的挂机行为、纯粹是无用操作的点击等等都会影响我们这里数据的准确性。
但是无论怎么样,耗时数据,是一定会符合正态分布,这样我们可以通过正态分布的峰值看出系统整体的耗时。进一步可以让前端理解业务的情况,进而提出对业务系统的建议(这里可能会有人认为,这些应该是产品层需要去考虑的事情,但是实际上,这些是纯技术上的内容,作为技术侧,我们应该通过技术获取数据,从而反推产品在此处的设计的合理性。)
我们是如何做的体验
上述我也讲了很多,具体我们是如何做的体验,接下来我们来好好絮叨絮叨。
接入方式
体验中心 Baymax 提供了两种接入方案:
- 通过
script的方式,快速接入系统,不需要做任何处理 - 通过
npm接入,需要进行一些配置
第一种方案已经通过发布平台自动化接入,也就是你发布系统的时候,会自动内置脚本进入你的系统,从而上报系统的性能数据。
当然第一种方案获取的数据有限,而且没有良好的关联性,缺乏全链路的同步,进而会丢失一些数据,但是在性能分析的层面上是够用的了。
第二种方案是通过 npm 包的形式进行接入,此种方案接入的系统包含完整的性能数据,同时也解锁了更多的数据,比如 Gtrace 的全链路信息等。
性能分析模块
总览
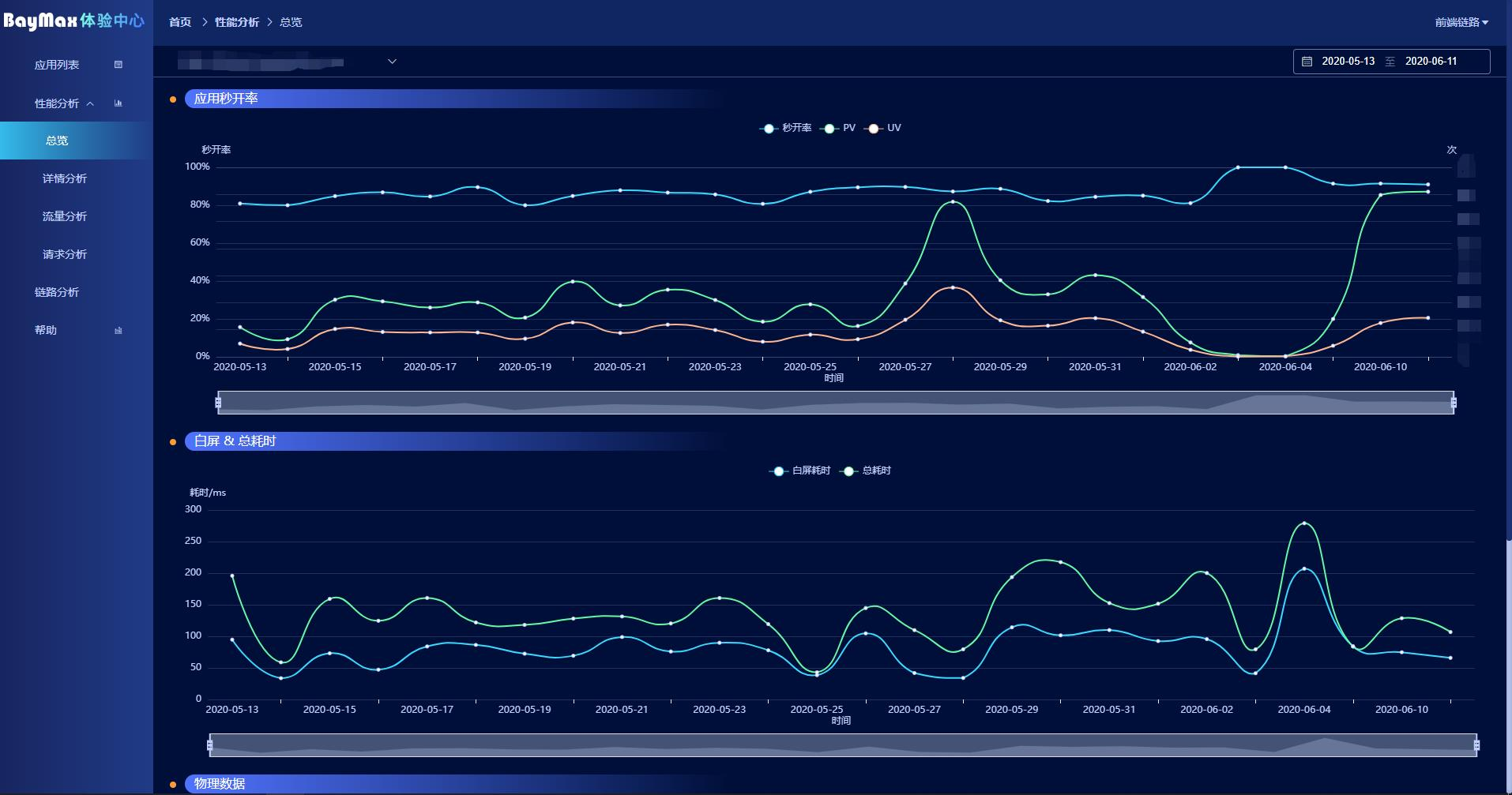
总览包括系统的一些综合指数,这里其实不用展示很多数据,性能指标没有很多花里胡哨的东西。对于一个系统来说,首要保证的就是系统的 ** 秒开率 **,秒开率指系统在 1s 内打开的数量占总访问数量的比例。当然也会有一些基本的数据,例如系统分布、浏览器分布之类的,这些就不展示出来了。
秒开率的高低其实不简简单单是一个单纯的数字,他背后其实映射了很多关系:
打包策略是否良好
protocol是否为http2.0代码逻辑是否良好
...
想提升这个数字,单一方面不足以提升,只有整体的提升,才能达到比较好的效果。
详情分析
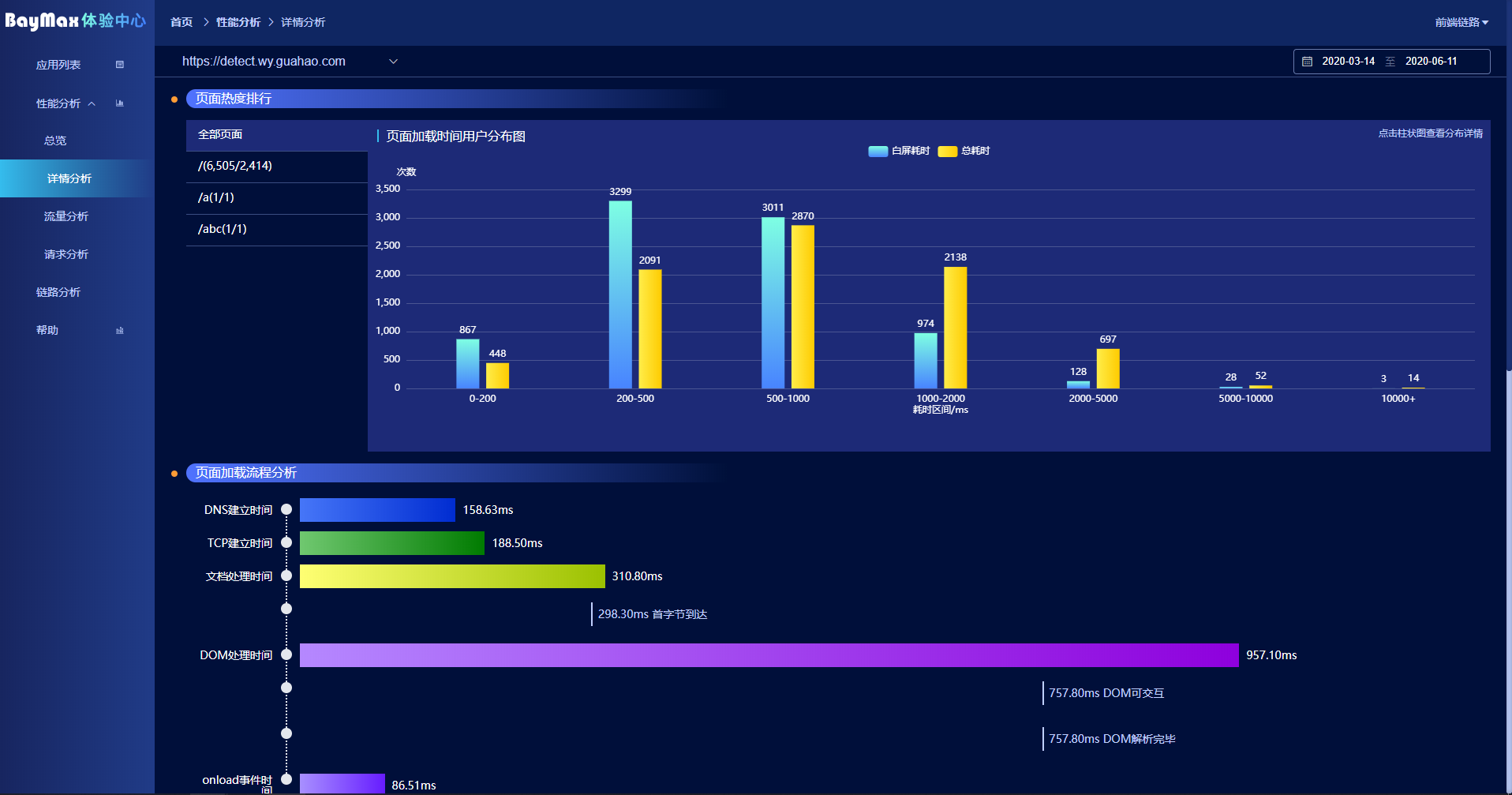
详情分析主要是用来对收集的大数据进行分析,看系统的整体稳定性,例如白屏的耗时主要分布的区间在哪个范围。以及每个阶段的 95 值是多少,进而可以看到系统的综合指数。
很多时候,我们做一个系统认为,通过一些认证之后就觉得,系统很厉害了。比如,我的系统在 Google 的 lighthouse 上跑过,84 分,无敌!
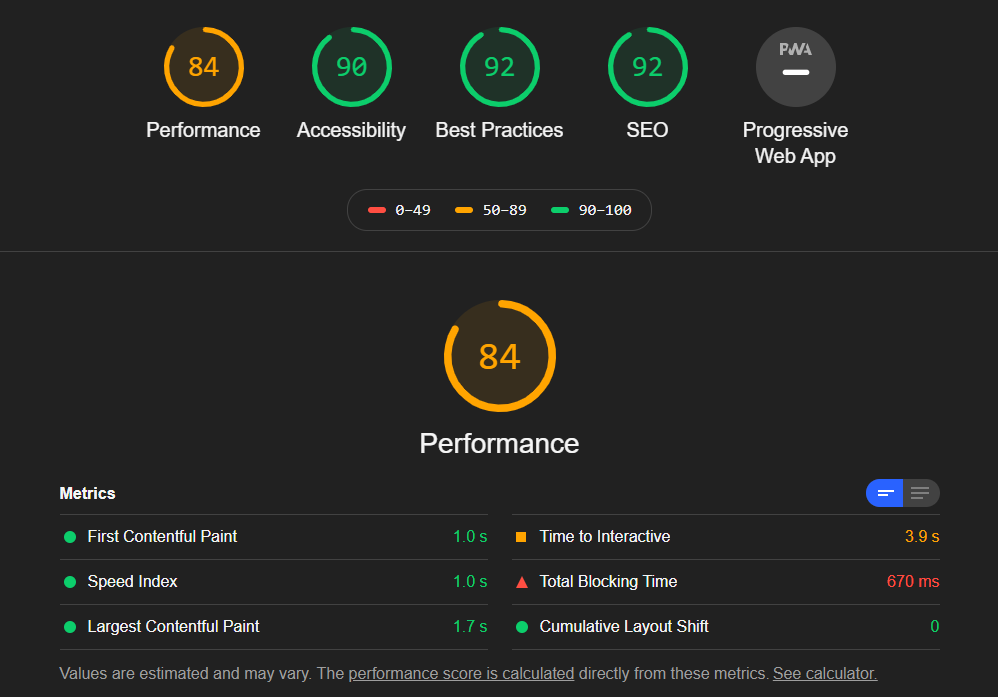
结果你自信满满的发到了线上,漫天遍野的运营找你:
“客户说打开页面太慢了”“客户打不开页面了”“怎么要花 3s 才能打开,搞什么呢?”
此刻的你,大概是如下的状态:

这其实就是典型的幸存者偏差,也就是我们在开发中经常遇到的,我电脑上没问题啊。
所以,对于性能来说,我们需要用大数据去分析,系统的问题。每一次问题,我们都会有记录,可以通过点击柱状图查看这些数据的情况。
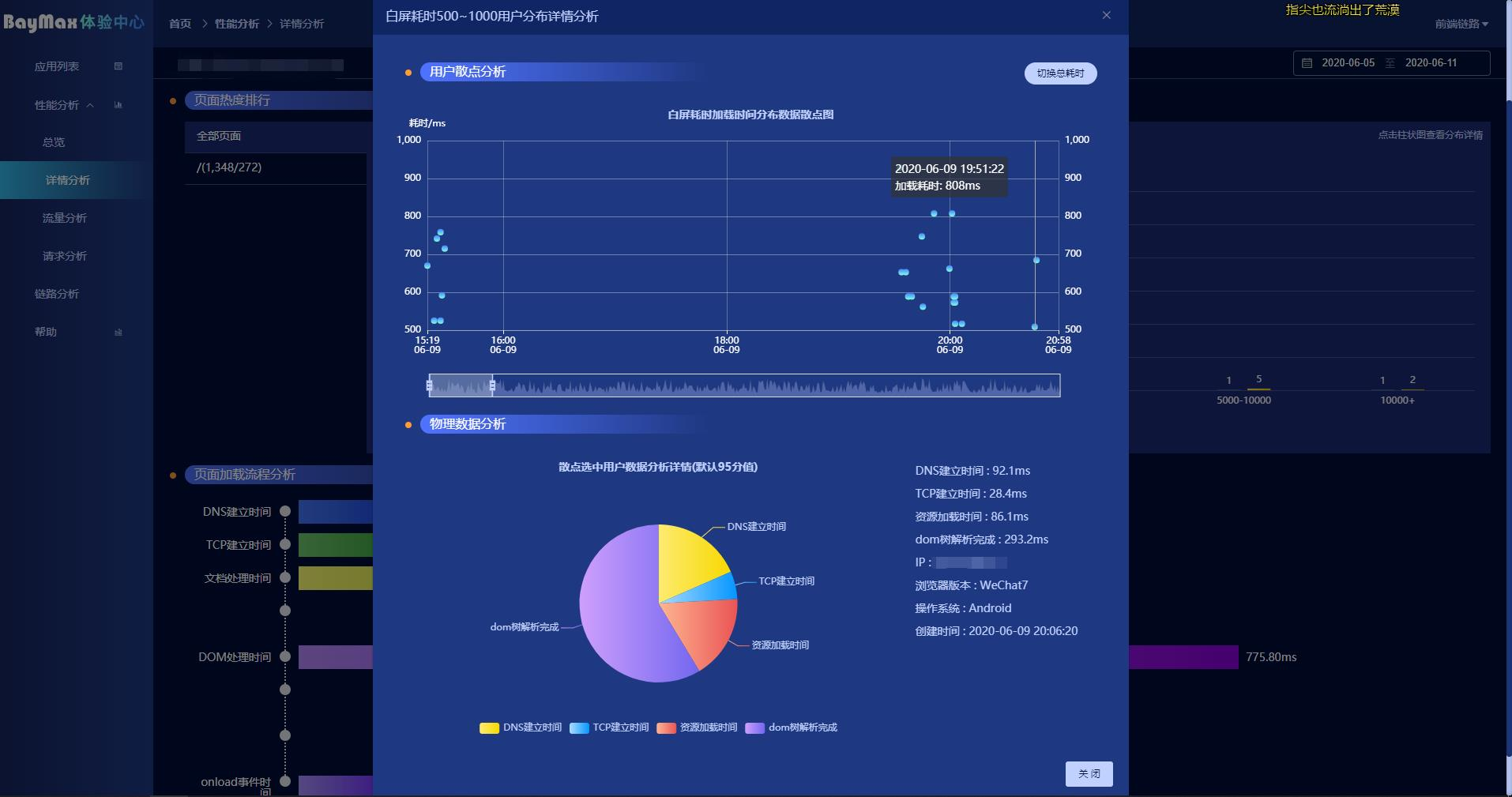
所以,你可以查看发生在用户的系统上的事情是什么。
流量分析
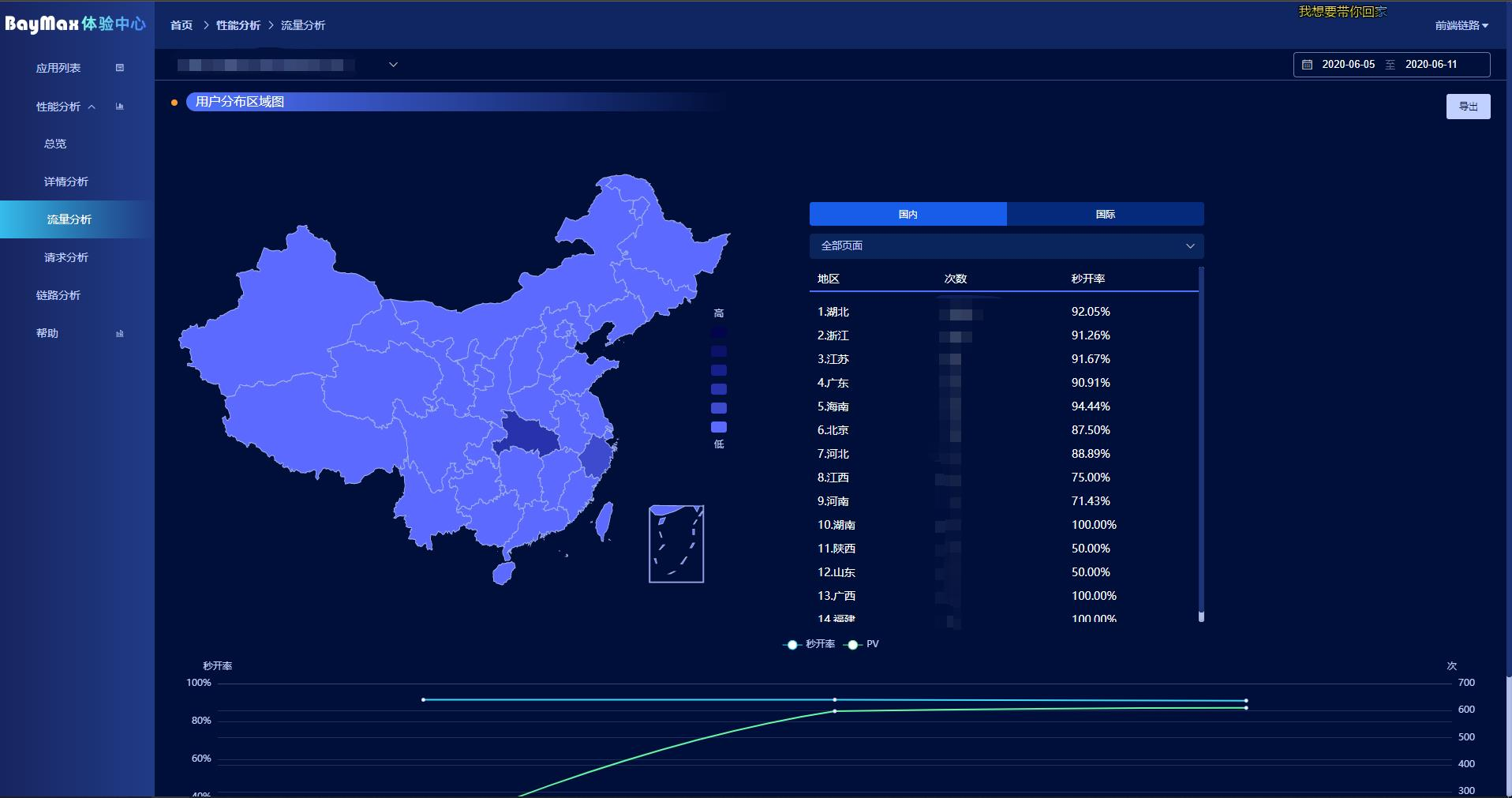
流量分析主要是为了查看各地区的秒开率,这样 CDN 配置策略的时候,或者当前的 CDN 厂商是否优质都可以看出来。如果局部地区很重要,但是 CDN 无法良好覆盖,可以考虑进行本地化部署。
请求分析
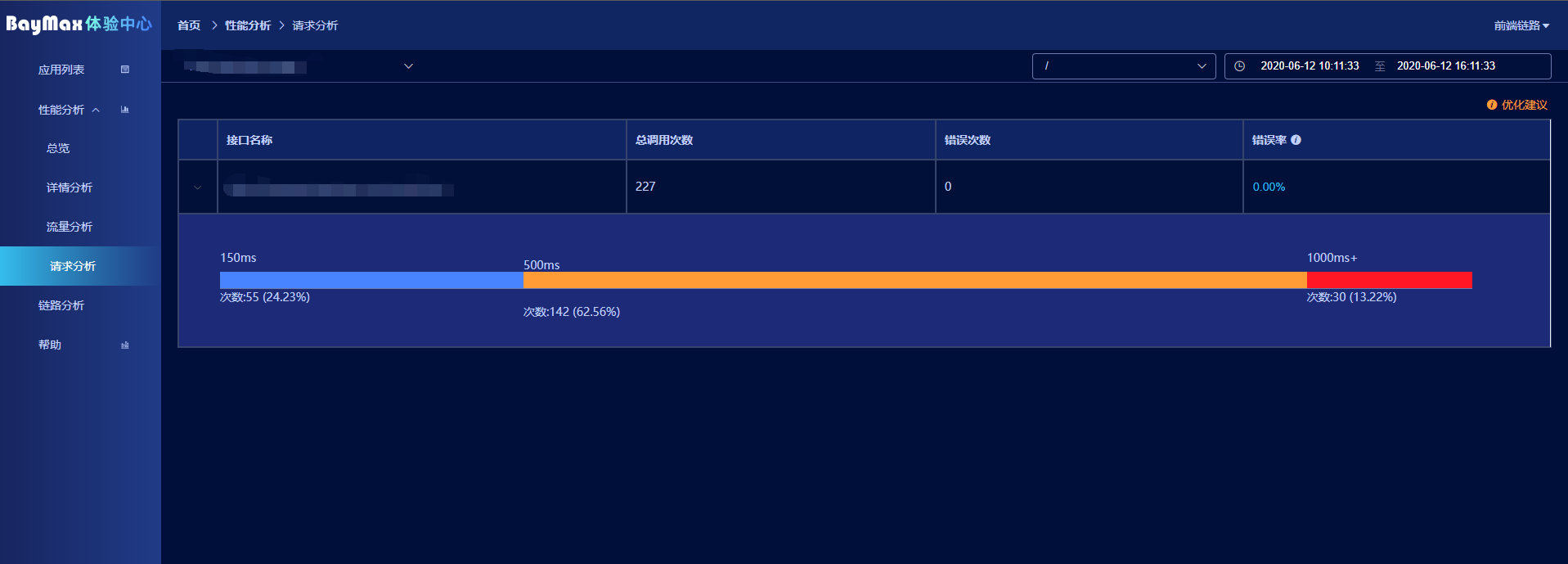
这个就很老生常谈了,收集时间段内所有的请求,然后通过大数据分析这段时间内的接口的状态,是否良好,分布情况。
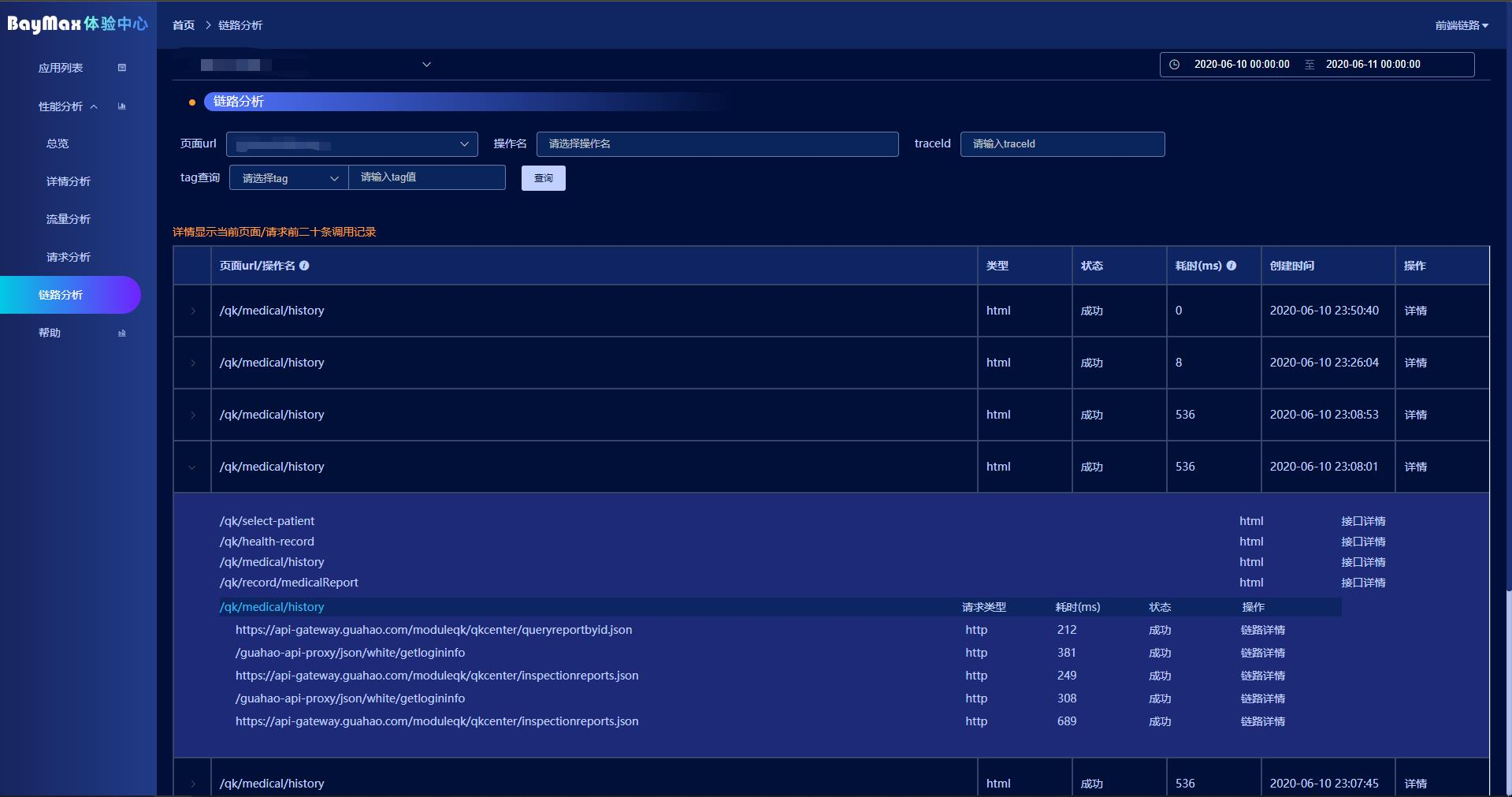
链路分析
关于服务端的链路,大家应该都略有耳闻,后端微服务玩的兴起,关于链路治理,各家也是有五花八门的技术,回到我们前端,我们就缺乏了前端层面的链路治理。
那么有的人就要说了,“你这个前端有没有相互调用,你们前端也有微服务吗?” 哎,你别说,还真有。但是不在本次的讨论范围。OK,服务端的链路存在于服务与服务之间,而对于前端来说,每个客户的每次访问,就是一个服务,建立这条服务是在客户本地,但是数据、内容都是由服务端下发,下发到本地之后
渲染是否正常
性能是否良好
功能是否完善
...
这些难道不需要进行良好的治理来提升体验吗?是的,抛开现在大热的前端微服务 / Serverless 等技术,纯粹的前端也是需要这些治理。
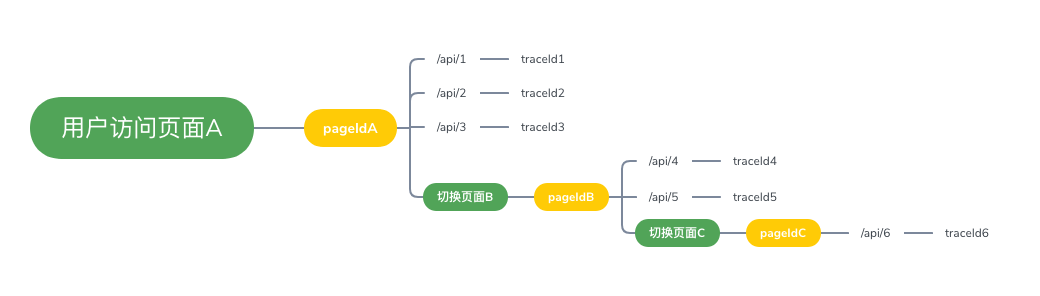
所以我们给每一次页面打开生成一个独有的 pageId,然后把 traceId 关联到 pageId 上,这样,就可以实现从前端开启的全链路打通了。
这只是实现了链路级别的打通,但是前端有一些错误产生于逻辑之间,例如后端接口从 {} 变更为 [],在前端一定产生错误,但是通过链路,我们很难发现这个问题。这就需要错误收集系统,例如 sentry 之类的错误收集系统,通过收集错误之后生成一个独有的 sid,然后把 sid 绑定到 pageId 上,这样就可以通过页面级别的访问,查询到具体的请求内容以及是否有错误了。
值得一提的是,ssr 项目,其实有一个封闭的环节在于 ttfb 阶段,这个阶段的耗时,不一定是纯粹的网络耗时,大概率是 Node 服务在进行某些处理,或者调用其他服务造成的网络请求缓慢。
所以这也是我们链路治理需要考虑的一个环节,我们需要针对 SSR 项目,额外有一个包去处理 Node 层的事情。
我们未来的计划与设想
前端微服务
现在最火的话题就是前端微服务,我们在这里不讨论前端微服务的可能性,但是如果前端微服务出来之后,各个模块之间的性能分析,各个模块的数据传递、调用,都是后续体验的重点考察部分。
业务耗时
业务耗时需要前端配合执行,需求发起方是产品,所以这里的推进稍微需要点时间,这里的功能暂时还不完善到可以对外提供,所以这里也是后续需要巩固的地方。
❤结束语
絮絮叨叨,也讲了就好几千字,内容也很多很繁琐,希望能带给你一些帮助。

