

首先我们先了解一下Dubbo调用的流程
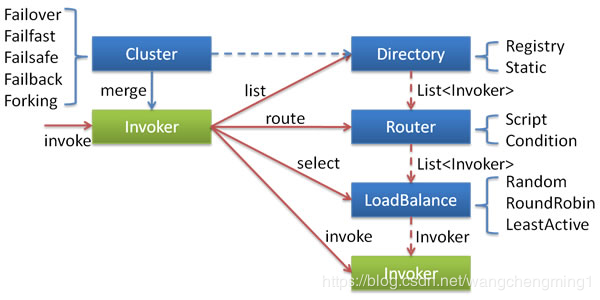
本文主要讲解Cluster。
在集群调用失败时,Dubbo提供了多种容错方案,默认值为failover重试。Dubbo中现在有Failover、Failfast、Failsafe、Failback、Forking、Broadcast等容错机制,每个容错机制的特性如下表。
| 机制名 | 机制简介 |
|---|---|
| Failover | Dubbo容错机制的默认值。当出现失败的时候,会尝试其他服务。用户可以通过retries="2"设置重试次数。这是Dubbo的默认容错机制,会对请求做负载均衡。通常使用在读操作或者幂等性写操作上,但是重试操作会导致接口的延迟增大,在下游机器负载已经到达极限的情况下,重试会增加下游机器的负载。 |
| Failfast | 快速失败,当请求失败之后快速返回异常结果,不做任何重试。改容错机制会对请求做负载均衡,通常使用在非幂等性的接口上。该机制受网络抖动的影响较大。 |
| Failsafe | 当出现异常的时候直接忽略异常,会对请求做负载均衡。通常的使用场景是不关心调用是否成功,并且不想抛出异常影响外部调用,如某些不重要的日志同步,及时出现异常也无所谓。 |
| Failback | 请求失败之后,会自动记录在失败队列中,并由一个定时线程池定时重试,适用一些异步或者最终以执行的请求。会对请求做负载均衡。 |
| Forking | 同时调用多个相同的服务,只要其中一个返回,就立即返回结果。用户可以配置forks="2" 来设置最大并行数。通常用在对接口实时性较高的场景,但是也会浪费更多的资源。 |
| Broadcast | 广播调用所有可用服务,任意一个节点报错则报错。由于是广播,因此请求不需要做负载均衡。 |
通过上面的这个表格我们可以大概了解到Dubbo中每种容错机制的含义和大概含义,接下来我们来了解一下怎么在服务中使用以上的容错机制。
使用方法
通常可以通过<dubbo:service>、<dubbo:reference>、<dubbo:consumer>、<dubbo:provider>标签上通过cluster属性进行设置。
<dubbo:service cluster="Failfast" />- 或
<dubbo:reference cluster="Failfast" /> - 或
<dubbo:consumer cluster="Failfast" /> - 或
<dubbo:provider cluster="Failfast" />
源码分析
通过源码可以看到,目前Dubbo对Cluster的扩展有以下几种,在/dubbo-cluster/src/main/resources/META-INF/dubbo/internal下可以看到有这么多种容错机制,那么在实际业务中使用哪种就要按具体场景了,可以参考一下上面的表格。
mock=org.apache.dubbo.rpc.cluster.support.wrapper.MockClusterWrapper
failover=org.apache.dubbo.rpc.cluster.support.FailoverCluster
failfast=org.apache.dubbo.rpc.cluster.support.FailfastCluster
failsafe=org.apache.dubbo.rpc.cluster.support.FailsafeCluster
failback=org.apache.dubbo.rpc.cluster.support.FailbackCluster
forking=org.apache.dubbo.rpc.cluster.support.ForkingCluster
available=org.apache.dubbo.rpc.cluster.support.AvailableCluster
mergeable=org.apache.dubbo.rpc.cluster.support.MergeableCluster
broadcast=org.apache.dubbo.rpc.cluster.support.BroadcastCluster
zone-aware=org.apache.dubbo.rpc.cluster.support.registry.ZoneAwareCluster
- 首先我们看一下
org.apache.dubbo.rpc.cluster.Cluster这个接口,可以看到Dubbo Cluster的默认值是FailoverCluster。
@SPI(FailoverCluster.NAME)
public interface Cluster {
/**
* Merge the directory invokers to a virtual invoker.
*
* @param <T>
* @param directory
* @return cluster invoker
* @throws RpcException
*/
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}
- 我们以Dubbo Cluster的默认值为例,来分析一下是怎么实现容错的。
FailoverCluster是Cluster的一种实现,FailoverCluster直接创建一个新的Invoker并返回。
public class FailoverCluster extends AbstractCluster {
// @SPI指定的名字,也就是Dubbo Cluster的默认值
public final static String NAME = "failover";
@Override
public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException {
// 直接new一个FailoverClusterInvoker,是一个Invoker,具体的实现逻辑都封装在这里面
return new FailoverClusterInvoker<>(directory);
}
}
FailoverCluster的实现逻辑
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyInvokers = invokers;
checkInvokers(copyInvokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
// 获取重试次数,通过retries="N"来指定
int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1;
// 默认为一次
if (len <= 0) {
len = 1;
}
RpcException le = null;
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size());
Set<String> providers = new HashSet<String>(len);
// 循环调用,失败重试
for (int i = 0; i < len; i++) {
if (i > 0) {
checkWhetherDestroyed();
// 在进行重试前重新列举 Invoker,这样做的好处是,如果某个服务挂了,
// 通过调用 list 可得到最新可用的 Invoker 列表
copyInvokers = list(invocation);
checkInvokers(copyInvokers, invocation);
}
// 通过负载均衡选择Invoker
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
// 添加到 invoker 到 invoked 列表中
invoked.add(invoker);
// 设置 invoked 到 RPC 上下文中
RpcContext.getContext().setInvokers((List) invoked);
try {
// 调用目标 Invoker 的 invoke 方法
Result result = invoker.invoke(invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + methodName
+ " in the service " + getInterface().getName()
+ " was successful by the provider " + invoker.getUrl().getAddress()
+ ", but there have been failed providers " + providers
+ " (" + providers.size() + "/" + copyInvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost()
+ " using the dubbo version " + Version.getVersion() + ". Last error is: "
+ le.getMessage(), le);
}
return result;
} catch (RpcException e) {
if (e.isBiz()) { // biz exception.
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException(le.getCode(), "Failed to invoke the method "
+ methodName + " in the service " + getInterface().getName()
+ ". Tried " + len + " times of the providers " + providers
+ " (" + providers.size() + "/" + copyInvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version "
+ Version.getVersion() + ". Last error is: "
+ le.getMessage(), le.getCause() != null ? le.getCause() : le);
}
如上,FailoverClusterInvoker 的 doInvoke 方法首先是获取重试次数,然后根据重试次数进行循环调用,失败后进行重试。在 for 循环内,首先是通过负载均衡组件选择一个 Invoker,然后再通过这个 Invoker 的 invoke 方法进行远程调用。如果失败了,记录下异常,并进行重试。重试时会再次调用父类的 list 方法列举 Invoker。
