

公众号:MarkerHub(关注获取更多项目资源)
eblog 代码仓库:github.com/markerhub/e…
eblog 项目视频: www.bilibili.com/video/BV1ri…
开发文档目录:
(eblog)2、整合Redis,以及项目优雅的异常处理与返回结果封装
(eblog)3、用Redis的zset有序集合实现一个本周热议功能
(eblog)4、自定义 Freemaker 标签实现博客首页数据填充
前后端分离项目vueblog请点击这里:超详细!4小时开发一个SpringBoot+vue前后端分离博客项目!!
搜索功能
原本我还想拆分成 spring cloud 项目的,不过博客项目的业务实在是少,没啥必要拆分,而我们之前二期作业已经拆分过项目了,所以想要学习 spring cloud 的同学可以去看看二期作业,那么这期作业我们就直接搞成 springboot 项目不拆分模块了。
搜索功能 - ES
结合我们学习过的内容,我们之前学习搜索引擎,学过 lucene 还有 elasticsearch,lucene 比较适合单体项目,不适合分布式。
这次搜索我们用的是 es,es 与数据库之间的内容同步我们用的是 RabbitMq 进行一步同步。下面我们一一来实现这些功能。
首先我们来分析一下我们要开发的功能。
-
搜索功能
-
es 数据初始化
-
es 与数据库的异步同步功能
集成 elasticsearch 的方式有很多,
-
比较原生的 TransportClient client
-
spring 提供的 ElasticsearchTemplate
-
spring jpa 提供的 ElasticsearchRepository
其中使用 ElasticsearchRepository 应该是开发量最小的一种方式,使用 template 或者 TransportClient client 方式可能会更灵活。
我们之前有学过 spring data jpa,一种可以按照命名规则就可以查库的方式,在搜索单表时候特别方便。
这次开发,我们使用 ElasticsearchRepository 的方式,当然,引入了这个包之后,你也可以使用 ElasticsearchTemplate 来开发。spring 都会自动帮你注入生成。
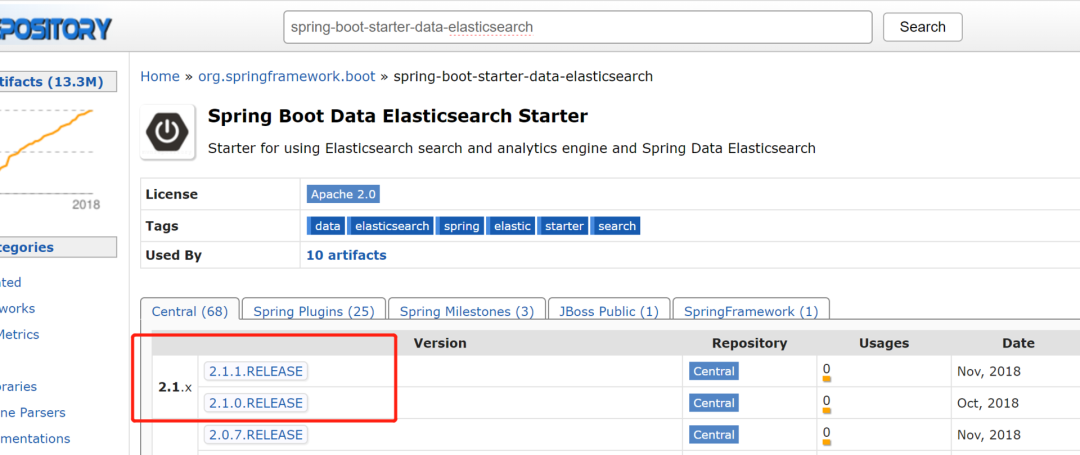
我们之前按照的 es 版本是 elasticsearch-6.4.3.tar.gz。所以我们选择引入包的使用最好也使用对应版本的。
在 maven 仓库上搜索一下对应的包版本,发现前面的几个基本都可以满足要求。我们这里就选用最新的 2.1.1.RELEASE 版本。
除了 es,我们还需要引入 feign、rabbitmq 等包,等下我们需要用到。这里我先统一给出一下。
<!-- es -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.1.1.RELEASE</version>
</dependency>
<!--整合rabbitmq-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.modelmapper</groupId>
<artifactId>modelmapper</artifactId>
<version>1.1.0</version>
</dependency>
es 和 mq 的安装我们课程上有介绍过,同学们可以去回顾一下,或者多看一下我们社区文档即可完成部署。
- 6.4.3 版本的下载地址:www.elastic.co/cn/download…
业务分析
我们再来分析一下,因为我们已经决定了选用 ElasticsearchRepository 方式来访问我们的 elasticsearch,所以按照这个思路,我们需要准备一个 model、一个 repository,这是访问存储介质 es 的基础,新建 repository 很简单,因为是 spring data jpa,所以直接继承 ElasticsearchRepository 就可以了:
- com.example.search.repository.PostRepository
@Repository
public interface PostRepository extends ElasticsearchRepository<PostDocument, Long> {
}
那 model 的内容是啥呢?我们来看看前端搜索列表,列表需要啥数据,我们就存啥数据就行。我们使用了搜索引擎,那么搜索的结果最好就不用再需要经过我们的数据库查询,这样我们就能直接把搜索的结果直接返回给前端显示。从而提升搜索的速度。比如我们看数据列表显示。在这里我们可以看到,需要标题,作者名称,作者 id、创建时间,阅读数量等等。

新建一个类 PostDocment 放在 model 包下。其实基本和我们的 postVo 差不多就行了。
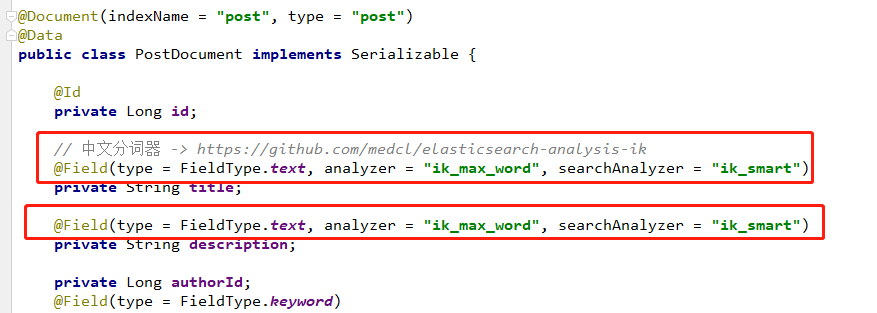
@Document(indexName = "post", type = "post")
@Data
public class PostDocument implements Serializable {
@Id
private Long id;
// 中文分词器 -> https://github.com/medcl/elasticsearch-analysis-ik
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
// @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
// private String content;
private Long authorId;
@Field(type = FieldType.Keyword)
private String authorName;
private String authorVip;
private String authorAvatar;
private Long categoryId;
@Field(type = FieldType.Keyword)
private String categoryName;
private Boolean recommend;
private Integer level;
@Field(type = FieldType.Text)
private String tags;
private Integer commentCount;
private Integer viewCount;
@Field(type = FieldType.Date)
private Date created;
}
这里我整理了一下所需要的字段。然后需要用上一下 jpa 的注解。FieldType.Text 表示是文本,需要经过分词(这里我们先不讲分词,后面再说)。FieldType.Keyword 则需要完全匹配的才行。
这里我把标题和简介用文本搜索,作者和分类则需要完全匹配才能搜索出来。analyzer = "ikmaxword" 是关于分词器的,后面我们会讲到。
有了这个实体之后,es 会自动帮我们新建数据索引结构。我们就可以使用 PostRepository 来增删改查我们的 es 数据了。
接下来我们新建一个搜索 search 的方法,因为需要分页,所以 page、size 参数是必要的。然后还有 keyword 参数。就是对 keyword 进行查询并分页返回结果。
代码如下:
- com.example.controller.IndexController
@RequestMapping("/search")
public String search(@RequestParam(defaultValue = "1") Integer current,
@RequestParam(defaultValue = "10")Integer size,
String q) {
Pageable pageable = PageRequest.of(current - 1, size);
Page<PostDocument> documents = searchService.query(pageable, q);
IPage pageData = new com.baomidou.mybatisplus.extension.plugins.pagination.Page
(current, size, documents.getTotalElements());
pageData.setRecords(documents.getContent());
req.setAttribute("pageData", pageData);
req.setAttribute("q", q);
return "search";
}
首先我们拼成 data jpa 的分页封装 Pageable,最后得到的 Page 对象也是 jpa 的,但是我们因为我们返回的选项是 mybatis plus 的,所以做了一层转换。最后得到 pageData。这里面主要的方法就是这个查询方法 searchService.query。
新建 SearchService 接口和实现类,query 方法的查询其实很简单,因为这里我们只有一个关键字查询,没有涉及其他很多复杂查询,所以我们先简单实现,后面我们涉及到权重、分词等问题时候我们可以再调整一下。
搜索的逻辑是,让关键字分别和我需要查询的字段进行多匹配,只要其中一个字段匹配上我们就命中。多字段匹配我们可以使用 MultiMatchQueryBuilder 来构建。至于字段的名称,我写了一个 IndexKey。因为搜索不仅仅是搜索标题,还需要搜索作者名称,分类名称等信息,用 or 关联起来得到最后的结果
- com.example.search.common.IndexKey
/**
* 索引名称
*/
public class IndexKey {
public static final String POST_TITLE = "title";
public static final String POST_DESCRIPTION = "content";
public static final String POST_AUTHOR = "authorName";
public static final String POST_CATEGORY = "categoryName";
public static final String POST_TAGS = "tags";
}
以上这些都是我需要搜索的字段。构建了多字段匹配之后,我们用 NativeSearchQueryBuilder 整合起来,并进行分页,得到一个 SearchQuery 结果,然后我们就可以使用 postRepository.search(searchQuery); 来得到我们需要的分页结果了,是不是感觉挺简单的哈。关于 spring data jpa 的复杂查询语法,大家回去看看我们的 jpa 的课程内容。熟悉一下:
- com.example.service.impl.SearchServiceImpl
@Override
public Page<PostDocument> query(Pageable pageable, String keyword) {
//多个字段匹配,只要满足一个即可返回结果
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keyword,
IndexKey.POST_TITLE,
IndexKey.POST_DESCRIPTION,
IndexKey.POST_AUTHOR,
IndexKey.POST_CATEGORY,
IndexKey.POST_TAGS
);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(multiMatchQueryBuilder)
.withPageable(pageable)
.build();
Page<PostDocument> page = postRepository.search(searchQuery);
log.info("查询 - {} - 的得到结果如下-------------> {}个查询结果,一共{}页",
keyword, page.getTotalElements(), page.getTotalPages());
return page;
}
multiMatchQuery 支持对多个字段进行匹配。这样我们查询关键字的时候,就回去查询这些字段:title、author、category 等。最后是构建 SearchQuery,并 使用 repository 查询接口。这样我们就可以实现 es 的查询功能啦,虽然还没有数据。然后我们来调整一下前端,找到前端的 js
中文分词
刚刚我们做了一个搜索功能,但是 es 的搜索分词是使用默认的标准分词器,我们都知道分词是 es 很重要的部分,搜索智能不智能就看分词好不好,分词效果好的话搜索出来的结果越精确。
现在我们来给 es 安装中文 IK 分词器。我在 github 上找了个还不错的 ik 分词器
使用分词器的方法很简单,在安装分词器之前,我们先来测试一下没安装之前的分词效果,和分词之后的分词效果。
使用 postman 来测试。首先测试默认情况下的标准分词器。
http://47.106.38.101:9200/post/_analyze
Headers Content-Type: application/json
Method POST
Body
{
"text":"美国留给伊拉克的是个烂摊子吗",
}
测试结果如下如:
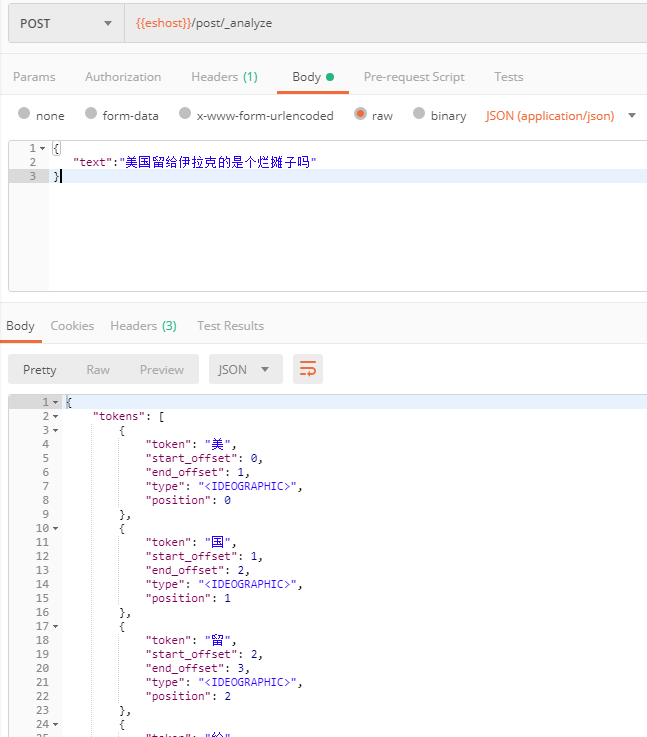
可以看到默认的标准分词器并不认识我们中文,只是简单把每个字分开而已。这样的分词会给搜索结果带来很大的不准确性。
那么接下来我们安装一下刚才说的 IK 分词器。根据 ReadMe 的说明。安装的方法有两个,这里我们采用第二种:optional 2 - use elasticsearch-plugin to install (supported from version v5.5.1):
.
/bin/
elasticsearch
-
plugin install https
:
//github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip
上面是使用 elasticsearch-plugin 命令来安装插件,也给出了 NOTE 给我们要注意替换版本号。因为我安装的 es 版本是 6.4.3,所以直接替换上面的两个 6.3.0。然后直接进入 es 安装目录执行即可安装成功了。
.
/bin/
elasticsearch
-
plugin install https
:
//github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.3/elasticsearch-analysis-ik-6.4.3.zip
安装成功之后注意重启一下 es,直接 kill 进程,然后重启就行。重启之后自己可以根据给出的命令来测试一下。这里我继续刚才的测试。在 body 的 json 中添加 analyzer,然后测试:
{
"text":"美国留给伊拉克的是个烂摊子吗",
"analyzer": "ik_smart"
}
测试结果:
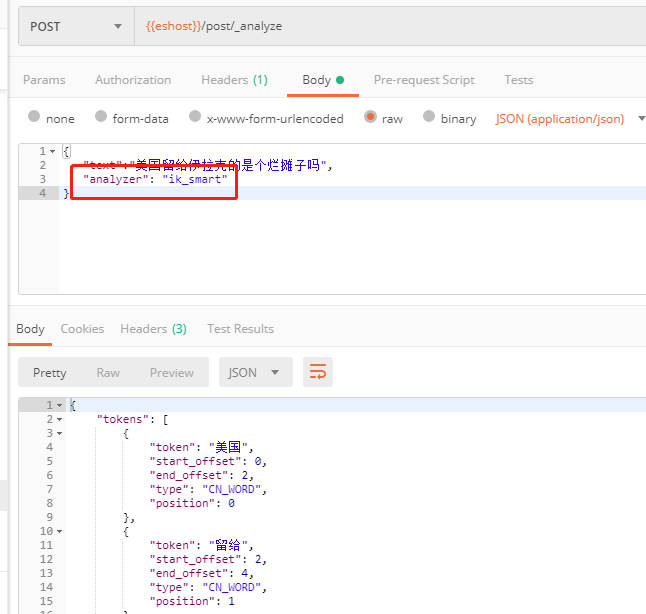
可以看到分词结果明显不同了。IK 分词给出了两种 iksmart** **, **ik****max_word。**两者区别在于
-
ik_smart* * 会将文本做最细粒度的拆分
-
*ik_max_word * 会做最粗粒度的拆分
可以自己动手观察一下结果。blog.csdn.net/weixin_4406…
以下是我测试用的 postman 实例。大家可以自己导进去测试一下:
elasticsearch-test.postman_collection.json
安装成功了之后我们就可以在我们代码里面加入我们的分词器了。代码改动很小,我们只需要在 PostDocment 实体的字段上加上注解属性 analyzer 和 searchAnalyzer。analyzer 是保存时候分词,这里我使用 **ikmaxword ,**这样可以搜索的词语更多。searchAnalyzer 表示搜索时候的分词,我只用 **ik_smart,**挑关键词语搜索。这里大家可以查看搜索结果来调整。
删除之前的索引,然后重启 hw-search 项目,查看索引信息里面可以看到,description 和 title 已经有了分词器(elasticsearch-head)。
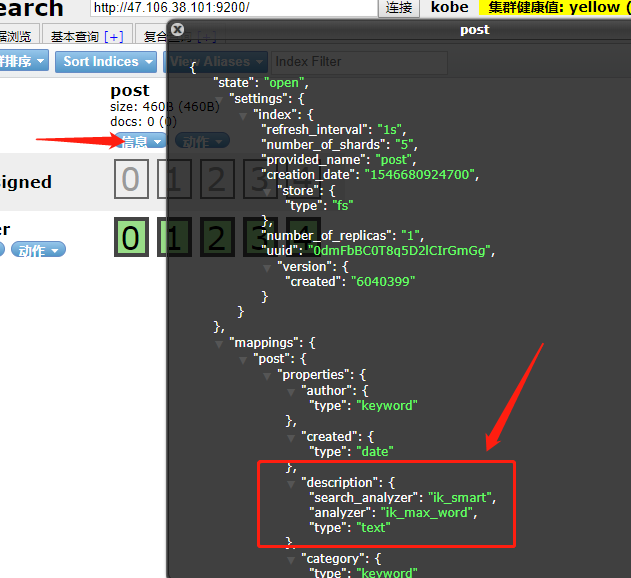
以上,我们就完成了中文分词效果。
初始同步
我们已经完成了 es 搜索引擎的查询功能,但是现在还没有数据,初始化数据的话我们可以批量查询数据库然后插入到 es 中,比较普遍也比较简单的方式:
这个数据同步的操作我们放在后台管理中,只能超级管理员有权限操作,所以我们新建一个 AdminController,然后 / admin 开头,然后在 shiro 中,我们需要拦截这个 admin 开头的链接,需要 admin 角色权限才有权限操作。
- com.example.config.ShiroConfig
hashMap
.
put
(
"/admin/**"
,
"auth, roles[admin]"
);
然后我们看看 controller
- com.example.controller.AdminController
@Controller
@RequestMapping("/admin")
public class AdminController extends BaseController {
@Autowired
SearchService searchService;
@ResponseBody
@PostMapping("/initEsData")
public Result initEsData() {
int total = 0;
int size = 10000;
Page page = new Page<>();
for(int i = 1; i < 1000; i ++) {
page.setCurrent(i);
page.setSize(size);
IPage<PostVo> paging = postService.paging(page, null, null, null, null, "created");
int num = searchService.initEsIndex(paging.getRecords());
total += num;
if(num < size) {
break;
}
}
return Result.succ("ES索引库初始化成功!共" + total + "条记录", null);
}
}
上面的逻辑其实很简单,就是批量查询出数据让,然后保存到 es 中,当查询出来的数量比每页数量少时候说明已经是最后一页了,这时候 break 结束。searchService.initEsIndex 是比较关键的逻辑,其实就是把 PostVo 映射成 PostDocment,然后就可以使用 repository 保存了。
- com.example.service.impl.SearchServiceImpl
@Override
public int initEsIndex(List<PostVo> datas) {
if(datas == null || datas.isEmpty()) return 0;
List<PostDocument> docs = new ArrayList<>();
for(PostVo vo : datas) {
PostDocument doc = modelMapper.map(vo, PostDocument.class);
docs.add(doc);
}
//批量保存
postRepository.saveAll(docs);
return docs.size();
}
然后现在我们得到一个链接就是 / admin/initEsData,这个按钮在哪里发起呢,因为我们现在没有后台,所以把这个管理员操作放在了用户中心的基本设置中,添加了一个新的 tab(管理中心),里面有个按钮就是同步 ES,点击按钮就会发起 form 表单提交。
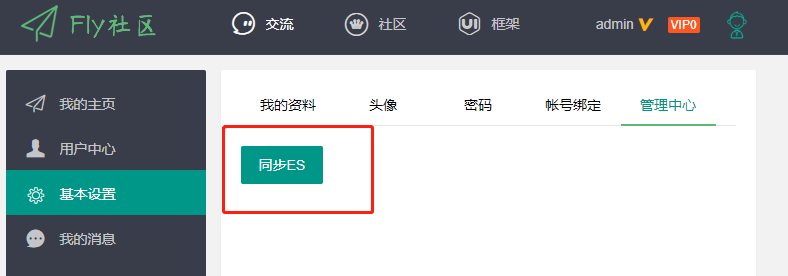
具体代码:
- templates/center/setting.ftl
<@shiro.hasRole >
<div class="layui-form layui-form-pane layui-tab-item">
<form method="post" action="${base}/admin/initEsData">
<button class="layui-btn" key="set-mine" lay-filter="*" lay-submit alert="true">同步ES</button>
</form>
</div>
</@shiro.hasRole>
注意这个按钮其实是一个 form 表单的提交按钮,这样我们就不再需要写 js 了,因为已经有全局的 form 表单的 js。
改动同步
接下来我们做些数据改动同步的问题,当我们添加修改或者删除了文章数据时候,es 能同步修改。
这里我们使用的是 mq,数据发送变化时候,发送一条消息到 MQ,然后 mq 消费端接受消息然后把这条消息的最新状态同步到 ES 中
首先类配置一下 mq。新建一个 RabbitMqConfig 类放在 config 包下。我们先来回顾一下消息队列的内容,RabbitMQ 里面发送接收消息有几种类型
-
Direct 类型(路由模式)
-
Fanout 类型(发布订阅模式)
-
Topic 类型(通配符模式)
这里我们直接使用 Direct 模式即可。这里会涉及到队列 Queue、交换机 Exchange、还有路由键 RouteKey(BindingKey)。
发布者发送消息到交换机,通过交换机和队列的路由键,把消息推向队列并保存起来,然后消费者订阅队列处理消息即可。
所以在 RabbitMqConfig 里面我们需要声明一下 queue、exchange、routekey。并且绑定起来。
- com.example.config.RabbitMqConfig
@Configuration
public class RabbitMqConfig {
// 队列名称
public final static String ES_QUEUE = "es_queue";
public final static String ES_EXCHANGE = "es_exchange";
public final static String ES_BIND_KEY = "es_index_message";
/**
* 声明队列
* @return
*/
@Bean
public Queue exQueue() {
return new Queue(ES_QUEUE);
}
/**
* 声明交换机
* @return
*/
@Bean
DirectExchange exchange() {
return new DirectExchange(ES_EXCHANGE);
}
/**
* 绑定交换机和队列
* @param exQueue
* @param exchange
* @return
*/
@Bean
Binding bindingExchangeMessage(Queue exQueue, DirectExchange exchange) {
return BindingBuilder.bind(exQueue).to(exchange).with(ES_BIND_KEY);
}
}
关于消费者和生产者之间的消息,我们需要一个共同约定类型。这里我需要新建一个消息模板,生产者发布消息时候只需要往消息模板填写,然后发送过来,消费者就能根据消息模板来处理消息。消息模板的内容需要斟酌一下,首先需要一个类型,因为是 es 与数据库数据的同步(比如新发表、更新、删除了一篇文章)。不同类型需要不同的处理手段。然后文章的 id 需要的。然后如果 es 处理数据失败的话我们需要重试,重试次数是有限的,所以这里我们定义一个重试次数的字段。
代码如下:
- com.example.search.common.PostMqIndexMessage
/**
* 用于服务之间消息通讯模板
*/
@Data
public class PostMqIndexMessage {
public static final String CREATE = "create";
public static final String UPDATE = "update";
public static final String REMOVE = "remove";
public static final int MAX_RETRY = 3;
private Long postId;
private String type;
private int retry = 0;
public PostMqIndexMessage() {
}
public PostMqIndexMessage(Long postId, String type) {
this.postId = postId;
this.type = type;
}
public PostMqIndexMessage(Long postId, String type, int retry) {
this.postId = postId;
this.type = type;
this.retry = retry;
}
}
因为消息发送都是通过经过序列化的 json 数据,所以我们先用 String 类型把消息内容接受,然后让内容与消息模板进行转换。可以使用 ObjectMapper 这个工具。然后接下来就是根据消息类型来处理消息了。
- com.example.mq.HandlerMessage
/**
* 监听异步消息队列
* 更新搜索内容
*/
@Slf4j
@Component
@RabbitListener(queues = RabbitMqConfig.ES_QUEUE)
public class HandlerMessage {
@Autowired
private ObjectMapper objectMapper;
@Autowired
SearchService searchService;
@RabbitHandler
public void handler(String content) {
try {
PostMqIndexMessage message = objectMapper.readValue(content, PostMqIndexMessage.class);
switch (message.getType()) {
case PostMqIndexMessage.CREATE:
case PostMqIndexMessage.UPDATE:
searchService.createOrUpdateIndex(message);
break;
case PostMqIndexMessage.REMOVE:
searchService.removeIndex(message);
break;
default:
log.warn("没有找到对应的消息类型,请注意!!!, ---> {}", content);
break;
}
} catch (IOException e) {
log.error("这是内容----> {}", content);
log.error("处理HandlerMessage失败 --> ", e);
}
}
}
接下来我们就去 SearchService 里去写对应的方法。首先看 createOrUpdateIndex 方法,在 ElasticsearchRepository 里面,更新或者新建都是用 save 方法,所以步骤基本都一直,新建类型里我先删掉原来的(如果有)。其他没啥不一样了。
然后我们注重看下 createOrUpdateIndex 和 removeIndex 两个方法,创建或修改其实很简单,只需要把修改的数据查询出来,然后转换成 PostDocument 就可以直接持久化了,
- com.example.service.impl.SearchServiceImpl
/**
* 异步创建或者更新
*/
public void createOrUpdateIndex(PostMqIndexMessage message) {
long postId = message.getPostId();
PostVo postVo = postService.selectOne(new QueryWrapper<Post >().eq("p.id", postId));
log.info("需要更新的post --------> {}", postVo.toString());
if(PostMqIndexMessage.CREATE.equals(message.getType())) {
if(postRepository.existsById(postId)) {
this.removeIndex(message);
}
}
PostDocument postDocument = new PostDocument();
modelMapper.map(postVo, postDocument);
PostDocument saveDoc = postRepository.save(postDocument);
log.info("es 索引更新成功!--> {}" , saveDoc.toString());
}
删除也差不多,直接通过 id 就可以删除
@Override
public void removeIndex(PostMqIndexMessage message) {
long postId = message.getPostId();
postRepository.deleteById(postId);
log.info("es 索引删除成功!--> {}" , message.toString());
}
有了 mq 的消费端,那么在哪里发送 mq 消息呢?在增删改数据的时候发送一条 mq 消息。我们找到对应的方法:
- com.example.controller.PostController#submit
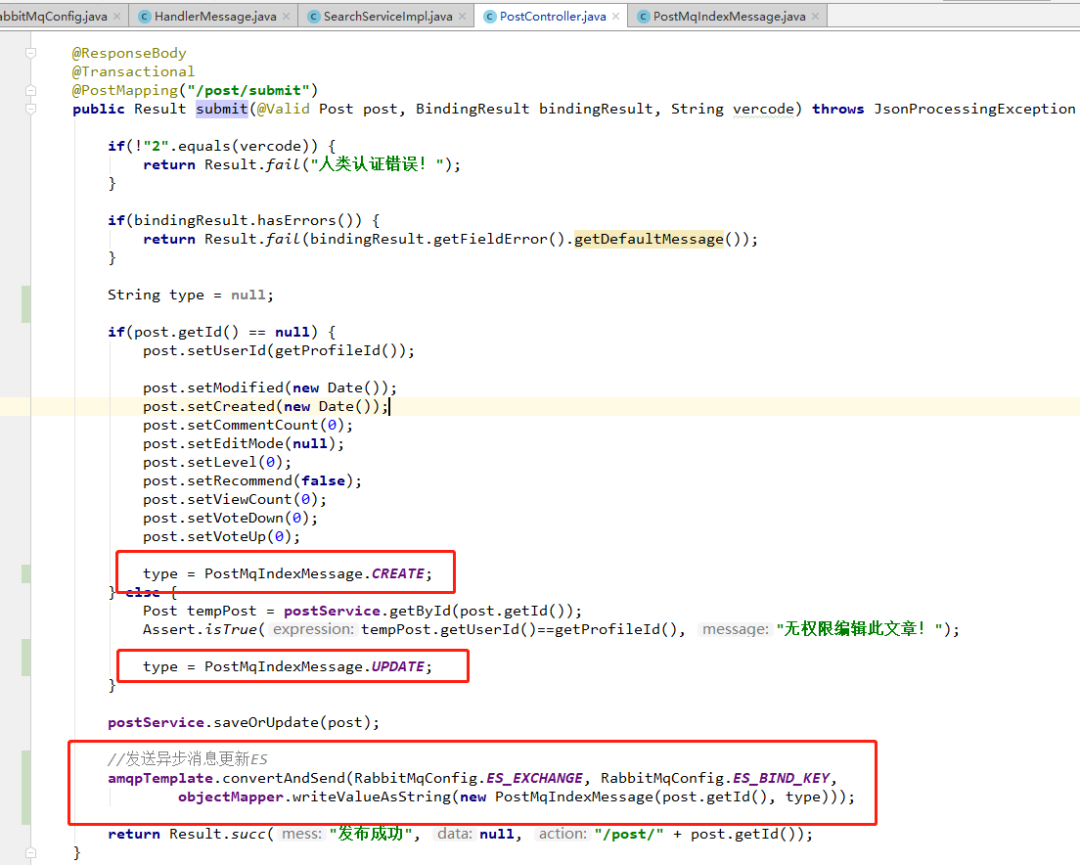
其中 mq 的发送模板是 AmqpTemplate ,直接注入即可。
@Autowired
AmqpTemplate amqpTemplate;
删除也类似:
- com.example.controller.PostController#delete
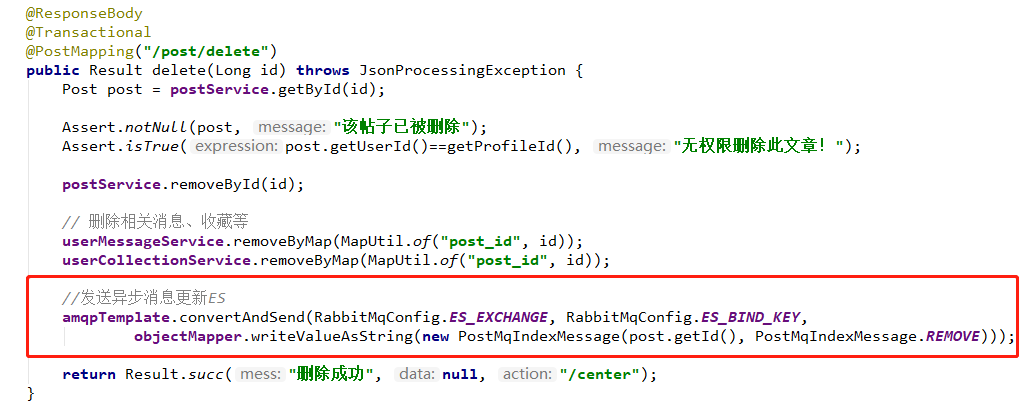
发送了 mq 之后,消费端就会同步 es 的数据,所以我们能保证 es 的数据和数据库的数据实时保持一致。
致此,搜索功能已经完成。
后台管理
置顶精选
关于文章的指定精选删除等功能,都是后台管理员能操作的动作,指定和精选其实都是 post 的一个状态问题,所以逻辑上特别简单,而且原 js 已经帮我们写好了方法,所以我们只需修改一下链接,然后在 AdminController 中添加对应的处理逻辑即可。
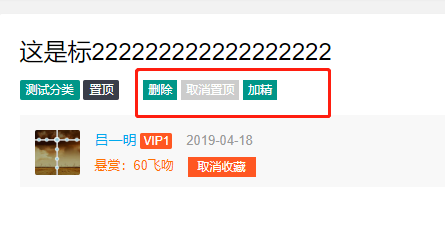
先来看下前端:
- static/res/mods/jie.js
//设置置顶、状态
,set: function(div){
var othis = $(this);
fly.json('/admin/jie-set/', {
id: div.data('id')
,rank: othis.attr('rank')
,field: othis.attr('field')
}, function(res){
if(res.status === 0){
location.reload();
}
});
}
可以看到,发起链接时候有几个参数,id,rank,field 等。然后看看 html:
- templates/post/view.ftl
<@shiro.hasRole >
<span class="layui-btn layui-btn-xs jie-admin" type="set" field="delete" rank="1">删除</span>
<#if post.level == 0><span class="layui-btn layui-btn-xs jie-admin" type="set" field="stick" rank="1">置顶</span></#if>
<#if post.level gt 0><span class="layui-btn layui-btn-xs jie-admin" type="set" field="stick" rank="0" style="background-color:#ccc;">取消置顶</span></#if>
<#if !post.recommend><span class="layui-btn layui-btn-xs jie-admin" type="set" field="status" rank="1">加精</span></#if>
<#if post.recommend><span class="layui-btn layui-btn-xs jie-admin" type="set" field="status" rank="0" style="background-color:#ccc;">取消加精</span></#if>
</@shiro.hasRole>
因为是后台管理操作,所以需要 <@shiro.hasRole > 这个 admin 权限,然后我们需要在 Shiro 的 Realm 中声明一下权限的问题,这里我比较简单,没有写权限模块,直接写死了 admin 作为超级管理员:
- com.example.shiro.AccountRealm
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
AccountProfile principal = (AccountProfile) principalCollection.getPrimaryPrincipal();
// 硬编码
if(principal.getUsername().equals("admin") || principal.getId() == 1){
SimpleAuthorizationInfo info = new SimpleAuthorizationInfo();
info.addRole("admin");
return info;
}
return null;
}
可以看到硬编码写死了用户 admin 或者 id 为 1 有角色 admin,其他都没有任何权限和角色。然后我们再看看 AdminController
- com.example.controller.AdminController
@ResponseBody
@PostMapping("/jie-set")
public Result jieSet(Long id, Integer rank, String field) {
Post post = postService.getById(id);
Assert.isTrue(post != null, "该文章已被删除");
if("delete".equals(field)) {
postService.removeById(id);
return Result.succ(null);
} else if("stick".equals(field)) {
post.setLevel(rank);
} else if("status".equals(field)) {
post.setRecommend(rank == 1);
}
postService.updateById(post);
return Result.succ(null);
}
直接就调用 updateById 修改状态即可。这里还有一个删除功能,也就是说不仅仅本人可以删除,超级管理员也有权限删除文章了。
