

上篇文章中简单分析了下
quasar和RxJava,以及简单的介绍了使用。这篇文章准备详细的介绍下RxJava,也对我这一周的工作优化部分做一个总结。
话不多说,先看优化效果:
- 优化之前的机器心跳信息
<thread count="1546" daemon-count="391" peak-count="1555" total-started-count="2209" deadlocked="0" new="0" runnable="169" blocked="0"
waiting="1245" timed-waiting="132" terminated="0" http-thread-count="32" amqp-thread-count="0" zk-thread-count="43" zebra-thread-count="0" hystrix-thread-count="0" netty-thread-count="0" cat-thread-count="4" dubbo-client-thread-count="1" dubbo-server-thread-count="37">
- 优化之后的机器心跳信息
<thread count="517" daemon-count="369" peak-count="518" total-started-count="594" deadlocked="0" new="0" runnable="169" blocked="0"
waiting="223" timed-waiting="125" terminated="0" http-thread-count="32" amqp-thread-count="0" zk-thread-count="43" zebra-thread-count="0" hystrix-thread-count="0" netty-thread-count="0" cat-thread-count="4" dubbo-client-thread-count="1" dubbo-server-thread-count="26">
可以看到优化之后的
服务心跳中处于waiting的线程数大幅度的下降。而且,业务代码的执行时间相比较之前的线程池方案,耗时是之前的50%。极大的增加了服务的吞吐率和执行性能。
既然RxJava这么优秀,是不是改造起来也非常容易呢?其实并不是,RxJava虽然文档上学习起来很简单,但是要想把这款框架用好,提升业务代码的性能却不是那么容易,曲线还是蛮陡峭的。因此,我把使用心得体会在此总结下,主要根据一些特殊场景下琢磨出的最佳实践。
为了方便,以
RxJava3结合相关的伪代码进行说明,因为实际中大多数场景需要用到反压。
一、基础概念及相关源码分析
1、Observable、Observer简介
这里先讲下基本的概念,熟悉的朋友可以直接跳过看后面的源码分析部分4、线程切换源码解析。RxJava底层使用发布订阅模式来感知一切异步事件是不是已经完成,并且加入了线程切换使多任务可以并行运行。那么Observable相当于是事件发布者,Observer是事件订阅者,订阅者平时不干活,当发布者发布了事件之后,订阅者接收到了才进行处理。
既然属于事件驱动,那事件又是什么?
打个比方,一个工厂有生产,包装2条流水线表示为produce,package。
produce生产完了之后丢给package会任劳任怨的进行打包。- 如果生产的过程中出现机器故障,
produce会告诉package生产流水线机器问题,暂停生产,打包工人听到这个美滋滋,不用干活了,而上游生产工人也美滋滋,机器故障了也不能生产了。 - 如果
produce生产完了,会告诉package流水线,活已经干完了。打包工人知道干完了顿喜,立马回去打游戏。但是上游生产工人可能临时又接到了组长生产通知,继续生产,比较蛋疼,但打包工人心想游戏都开了,还叫我回去,做梦吧。
这3个场景分别对应的RxJava的onNext,onError, onComplete事件,用官方文档的话可以这样描述:
onNext发布者可以无数next事件,订阅者也可以接收无数个next事件onError发布者发送了error事件之后就不在发布任何事件了,订阅者收到error事件也不会在接收任何的事件onComplete发布者发送comple事件之后可以继续发布任何事件,而订阅者接收到complete事件之后就不在订阅任何事件
比如类似这种的基本代码这里就不做演示了,可以去我上篇文章中获取。
2、并行执行
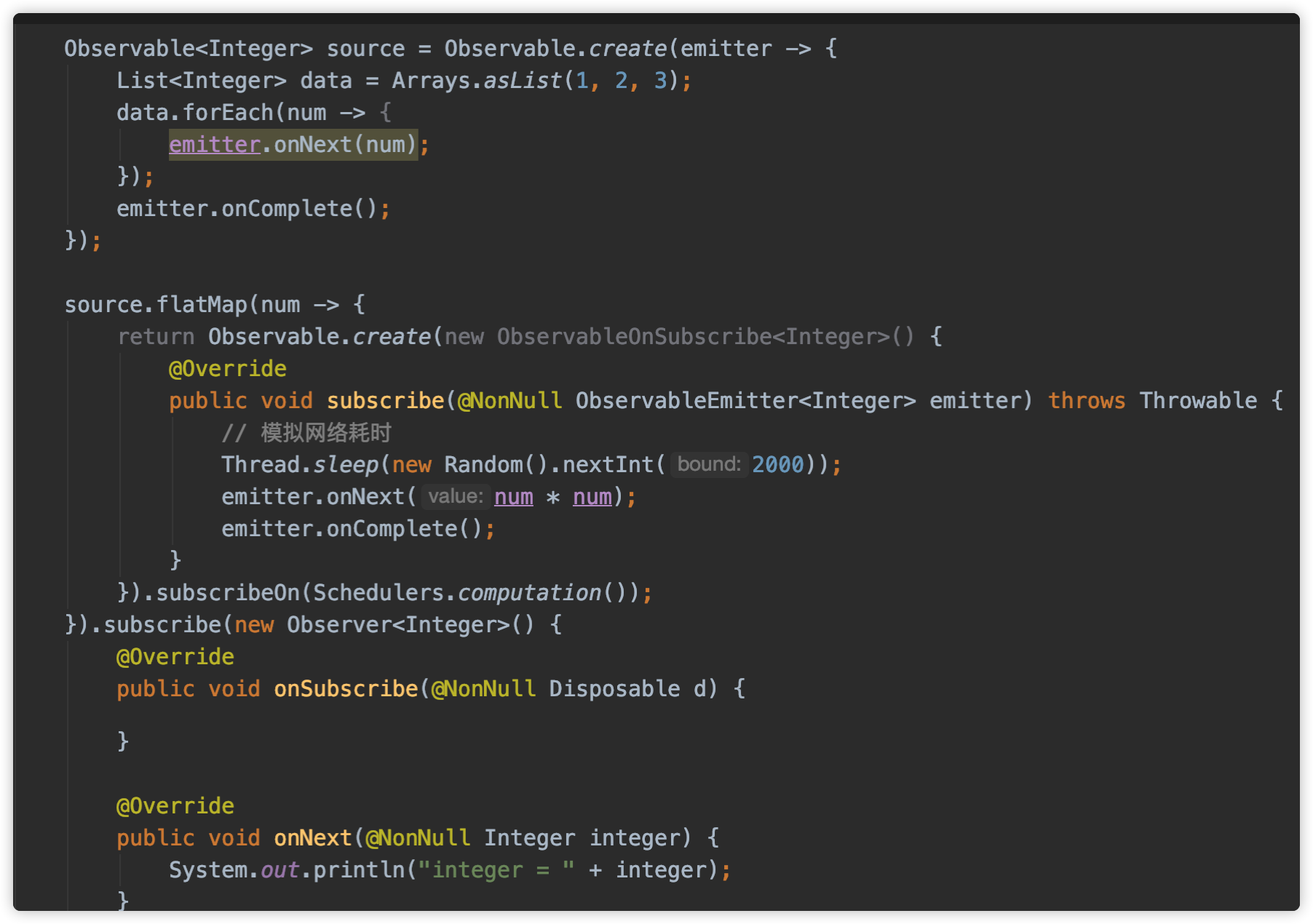
实际中需要任务并行执行,比如,给出一个数组[1, 2, 3],将这里面的元素求平方,那么可以使用flatMap操作符。
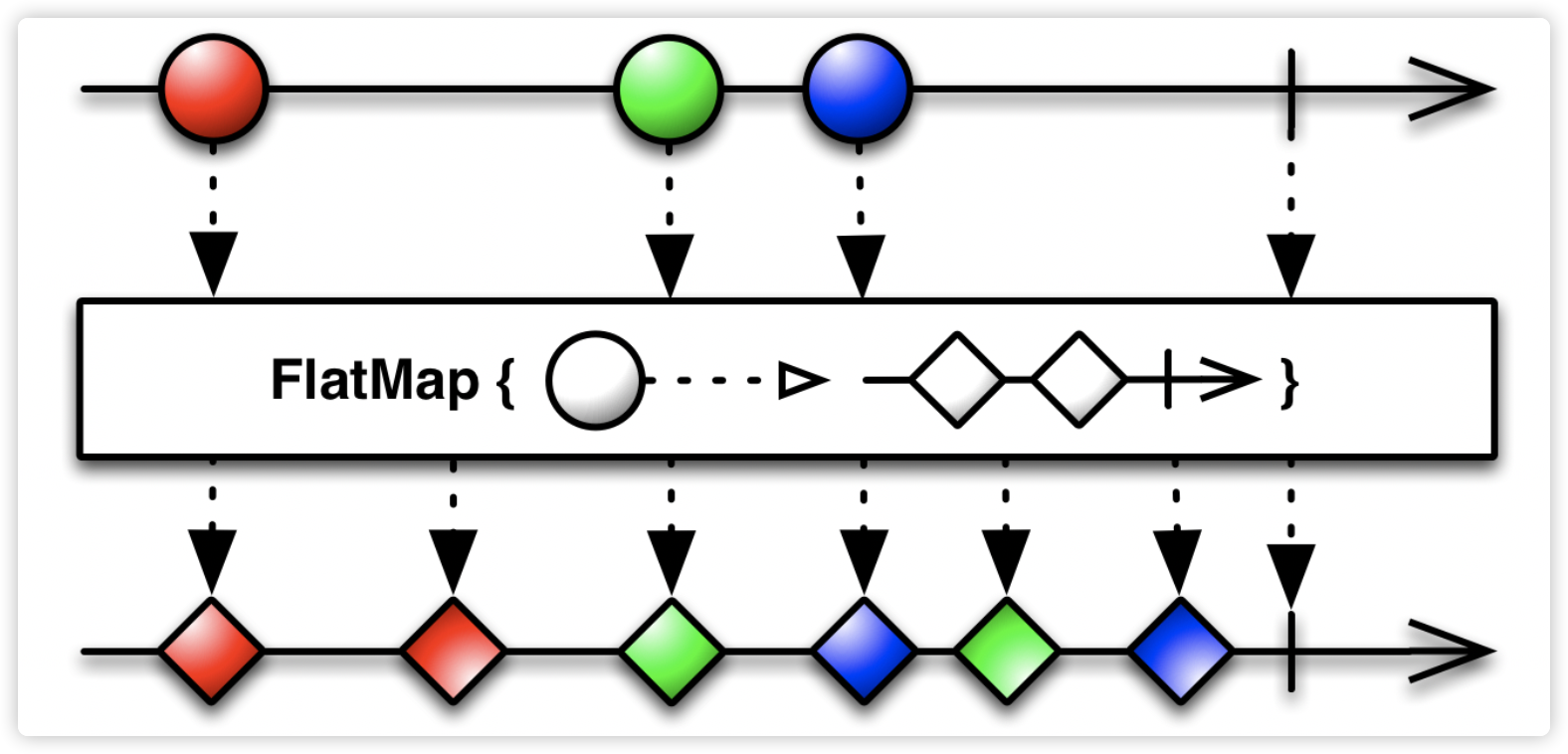
flatMap通常用在需要对元素进行一些耗时的转换,比如网络请求。将元素进行封装成Observable,把这些耗时的操作放到Observable发射逻辑里面,然后由单独的Scheduler调度。至于Scheduler部分后面再展开讲。
基本代码所示如下:
3、并行
在intro to RX这本书中说绝大多数人把RX当作默认就是多线程的,这种认识是错误的。其实RX只是提供了订阅发布模式的一种链式调用解决方式而已,同时RX也是一个自由线程模型框架,可以指定每个业务代码运行的线程。
下面以一段简单的代码为例,单步调试到底Scheduler是怎么调度任务。
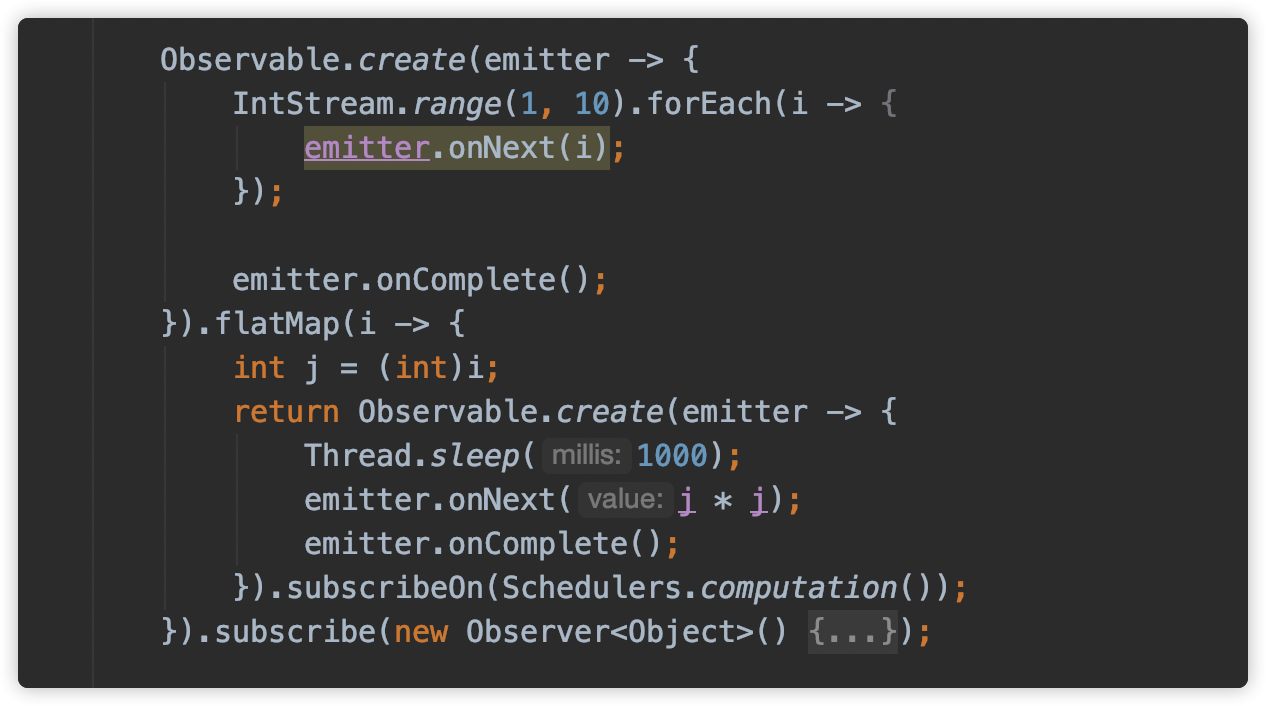
subscribeOn指定发布者发布所在的线程,observeOn指定订阅者订阅逻辑的线程。这里不再继续赘述怎么使用,不懂得可以去官网查看对应的operator使用文档。下面主要讲下RxJava核心部分之线程切换。
4、线程切换源码解析
4.1 Scheduler.computation()
public final Observable<T> subscribeOn(@NonNull Scheduler scheduler) {
Objects.requireNonNull(scheduler, "scheduler is null");
return RxJavaPlugins.onAssembly(new ObservableSubscribeOn<>(this, scheduler));
}
只是将当前的
Observable与传入的Scheduler调度器进行了封装,生成ObservableSubscribeOn。 是属于Observable的一个子类,这一块先不看,先看参数Scheduler.computaion()具体内部的实现。
4.1.1 Scheduler.computation()内部实现
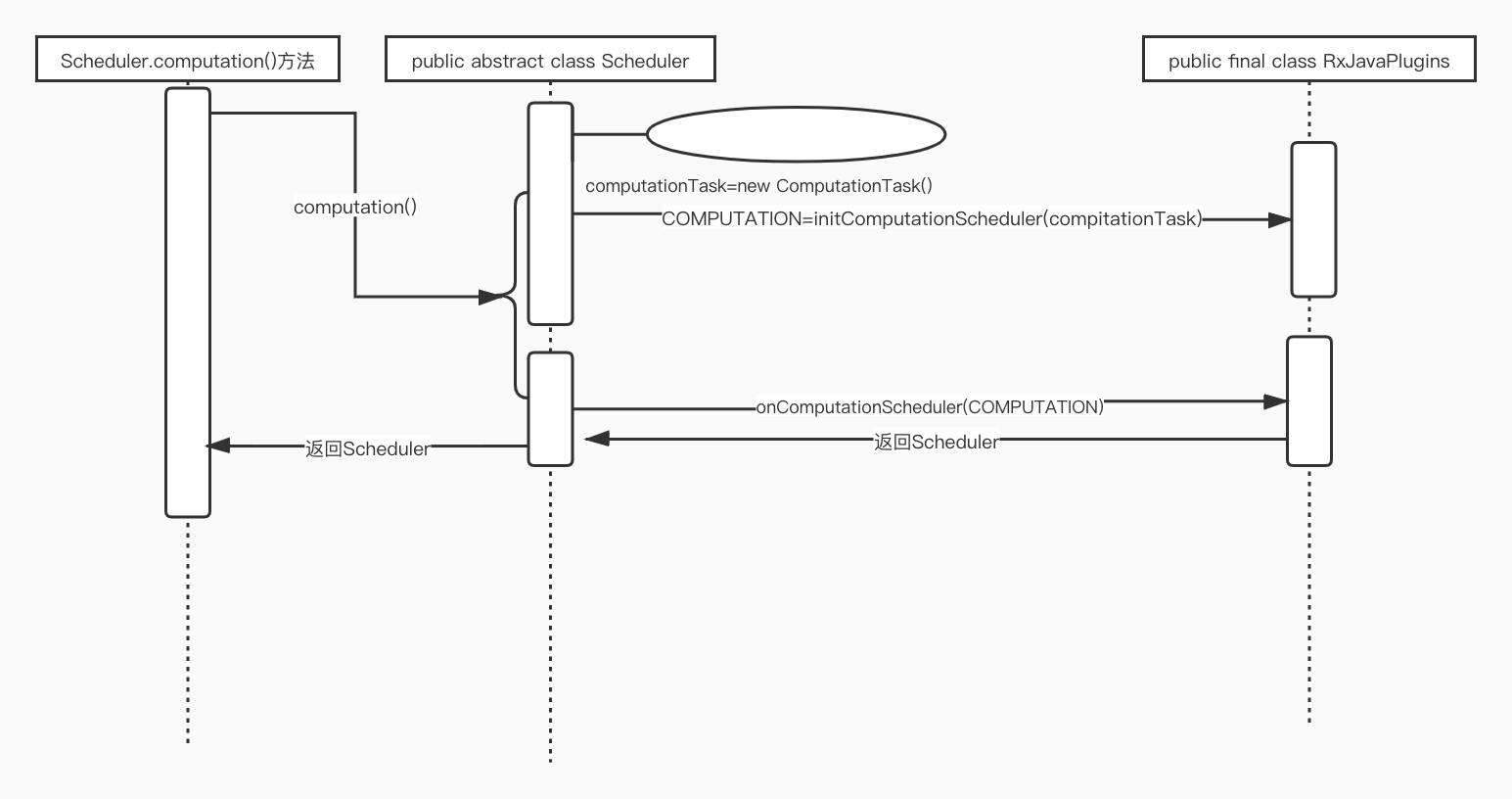
首先整理下Scheduler.computation()的调用时序图,然后跟着时序图着重的去看重要的实现细节,具体的调用如图所示,这里不再用文字描述具体的调用顺序。下面会按照时序,分析一些重点代码的内部实现。
4.1.1.1 ComputationTask结构
static final class ComputationTask implements Supplier<Scheduler> {
@Override
public Scheduler get() {
return ComputationHolder.DEFAULT;
}
}
首先看一下ComputationTask的结构,实现了Supplier接口,get()方法返回的是Scheduler抽象类的子类,继续往下看ComputationHolder.DEFAULT:
static final Scheduler DEFAULT = new ComputationScheduler();
因此真正返回的是Scheduler子类ComputationScheduler的实例,目光转向ComputationScheduler,看ComputationScheduler这个类的结构。
4.1.1.2 ComputationScheduler的结构
new ComputationScheduler()的构造方法如下:
public ComputationScheduler(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
this.pool = new AtomicReference<>(NONE);
start();
}
其中threadFactory为RxThreadFactory的一个实例对象,是创建Thread的一个工厂类,既然是一个工厂类,那就有一个newThread方法,返回一个Thread实例对象。RxThreadFactory全参构造函数的参数依次为prefix,表示创建线程的名字的前缀,priority创建线程的优先级priority,nonBlocking标志一个线程是属于阻塞线程还是属于非阻塞线程。这块没什么重点,就是一个枯燥的工厂类而已。
其次看下ComputationScheduler静态变量NONE:
NONE = new FixedSchedulerPool(0, THREAD_FACTORY);
看到初始化的值是通过FixedSchedulerPool实例对象,看下FixedSchedulerPool对应的构造方法为:
FixedSchedulerPool(int maxThreads, ThreadFactory threadFactory) {
// initialize event loops
this.cores = maxThreads;
this.eventLoops = new PoolWorker[maxThreads];
for (int i = 0; i < maxThreads; i++) {
this.eventLoops[i] = new PoolWorker(threadFactory);
}
}
因此NONE的值中的实例字段域为cores=0, eventLoops = new PoolWorker[0]是一个cmponentType为PoolWorker的空数组,虽然不会为数组元素进行赋值,但这里看下假设cores不为0,PoolWorker到底是一个什么东西。
4.1.1.3 PoolWorker的结构
PoolWorker是继承自NewThreadWorker,他唯一的一个构造方法是调用父类的下面的方法:
private final ScheduledExecutorService executor;
volatile boolean disposed;
public NewThreadWorker(ThreadFactory threadFactory) {
executor = SchedulerPoolFactory.create(threadFactory);
}
这里的ScheduledExecutorService实际上是继承了我们的老朋友ExecutorService的一个接口。executor的初始化是通过SchedulerPoolFactory.create赋值的,SchedulerPoolFactory看名字也知道是一个生成ScheduledExecutorService的final工厂类,那么继续看create内部的实现:
public static ScheduledExecutorService create(ThreadFactory factory) {
final ScheduledExecutorService exec = Executors.newScheduledThreadPool(1, factory);
tryPutIntoPool(PURGE_ENABLED, exec);
return exec;
}
首先返回的exec是一个ScheduledExecutorService接口的一个实现类ScheduledThreadPoolExecutor的实例,而ScheduledThreadPoolExecutor的构造方法是调用老朋友ThreadPoolExecutor的方法完成实例化的,因此追看进去,发现Executors.newScheduledThreadPool(1, factory)是生成了corePoolSize=1,maximumPoolSize=Integer.MAX_VALUE,keepAliveTime=0的一个枯燥ThreadPoolExecutor而已,只不过这里返回的是ScheduledThreadPoolExecutor,而ScheduledThreadPoolExecutor只是继承下了ThreadPoolExecutor而已。
同时还将生成的ScheduledThreadPoolExecutor放进了SchedulerPoolFactory这个工厂类的内部缓存Map<ScheduledThreadPoolExecutor, Object> POOLS中(对应到全网迷惑之题之多次调用Schedulers.computation()方法有没有用,这里显而易见的可以看到多次调用当然没什么副作用,只是后面生成的ScheduledThreadPoolExecutor会覆盖前面的ScheduledThreadPoolExecutor,不会生成一个拥有很多线程的线程池)。
到这里基本上可以知道ComputationTask实例化中,基本的业务内部代码干了啥。因此这里在接下去看:
RxJavaPlugins.initComputationScheduler(new ComputationTask())RxJavaPlugins.onComputationScheduler(COMPUTATION)
4.1.1.4 RxJavaPlugins.initComputationScheduler(new ComputationTask())
这个方法没什么可将的,追看进去发现返回的new ComputationTask().get(),而这个实例的get方法上文中说到,其实是返回抽象类Scheduler的ComputationScheduler的实例。
4.1.1.5 RxJavaPlugins.onComputationScheduler(COMPUTATION)
这个方法同样也是很枯燥,直接就把RxJavaPlugins.initComputationScheduler(new ComputationTask())这个方法的返回结果给返回出去了。
因此,Scheduler.computation()方法实际返回的就是ComputationScheduler这个实例。
4.1.1.6 再回头看ComputationScheduler的构造方法
上文中已经说明了this.pool的初始值其实是一个FixedSchedulerPool实例对象,只不过对象中的eventLoops实例域是一个长度为0的空数组,而数组中放的是PoolWorker。继续看构造方法中的start()方法:
public void start() {
FixedSchedulerPool update = new FixedSchedulerPool(MAX_THREADS, threadFactory);
if (!pool.compareAndSet(NONE, update)) {
update.shutdown();
}
}
可以看到,这一步是更新了this.pool这个字段的值,而这里的MAX_THREADS其实是:
MAX_THREADS = cap(Runtime.getRuntime().availableProcessors(), Integer.getInteger(KEY_MAX_THREADS, 0));
因此,start()方法只是重新修改了this.pool的值,改成了一个FixedSchedulerPool中cores=当前CPU核数和eventLoops=new PoolWorker[当前核数]的一个实例对象。
因此Schedulers.computation()内部的底层是一个与当前cpu核数相等的一个ThreadPoolExecutor的子类。
到此为止我们已经大概把Scheduler.computation()内部的基本代码已经了解清楚了。
4.2 Scheduler.computation()源码分析结论
这块涉及到的源码虽然很多,但是调用的逻辑不是很复杂,只是单纯的返回了一个ComputationScheduler实例对象,这个对象有ThreadFactory threadFactory,AtomicReference<FixedSchedulerPool> pool两个比较重要的实例域。FixedSchedulerPool有PoolWorker[] eventLoops,int cores两个重要实例域,其中PoolWorker是拥有ExecutorService的子类ScheduledExecutorService对象作为实例域的NewThreadWorker对象。最后返回的ComputationScheduler对象中的pool是一个线程池(core为1,max为Integr.MAX_VALUE)个数与当前cpu核数相等的FixedSchedulerPool对象。
4.3 Observable.create(@NonNull ObservableOnSubscribe source)
开门见山,先看调用时序图:
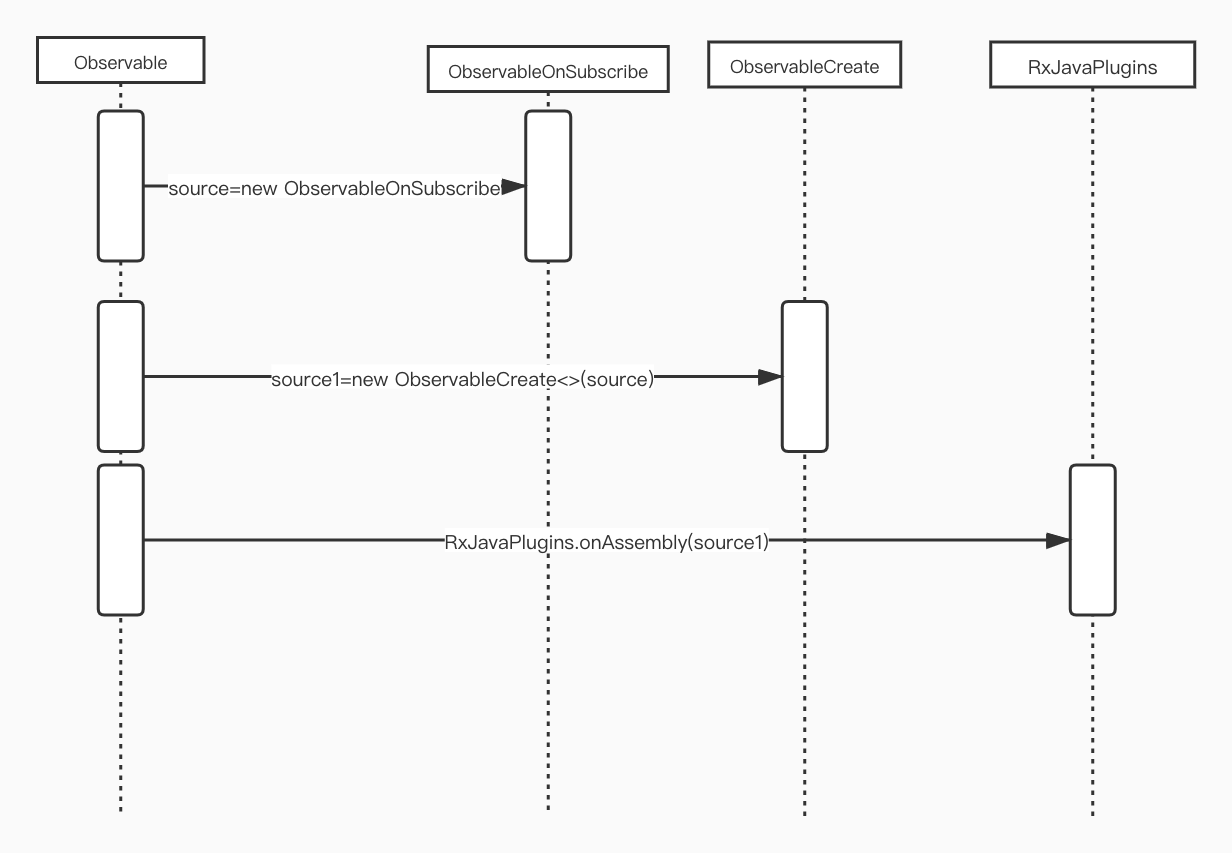
看到这块也比较简单,都只是一层层的封装,最后直接返回而已。
4.3.1 ObservableOnSubscribe
@FunctionalInterface
public interface ObservableOnSubscribe<@NonNull T> {
/**
* Called for each {@link Observer} that subscribes.
* @param emitter the safe emitter instance, never {@code null}
* @throws Throwable on error
*/
void subscribe(@NonNull ObservableEmitter<T> emitter) throws Throwable;
}
看到这是一个函数式接口,有一个待实现的方法subscribe,也就是我们自己子定义发布者发布各种事件的方法,subscribe的调用主要在ObservableCreate.subscribeActual方法,这里暂且不关系该方法调用的上下文。subscribe方法中还有一个参数ObservableEmitter<T> emitter,也是在调用的时候由上下文传进来,这里暂且关心。
4.3.1.1 ObservableCreate
时序图中可以看到ObservableCreate实际上是把ObservableOnSubscribe对象装进了自己的实例域,然后再调用RxJavaPlugins.onAssembly方法进行了封装,而RxJavaPlugins.onAssembly方法内部也只是把ObservableCreate实例返回了一下而已。因此这块就要重点关注ObservableCreate这个类。ObservableOnSubscribe作为实例域source的值。
protected void subscribeActual(Observer<? super T> observer) {
CreateEmitter<T> parent = new CreateEmitter<>(observer);
observer.onSubscribe(parent);
try {
source.subscribe(parent);
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
parent.onError(ex);
}
}
再继续看ObservableCreate的subscribeActual方法,这里先整理出ObservableCreate.subscribeActual方法调用的时序图:
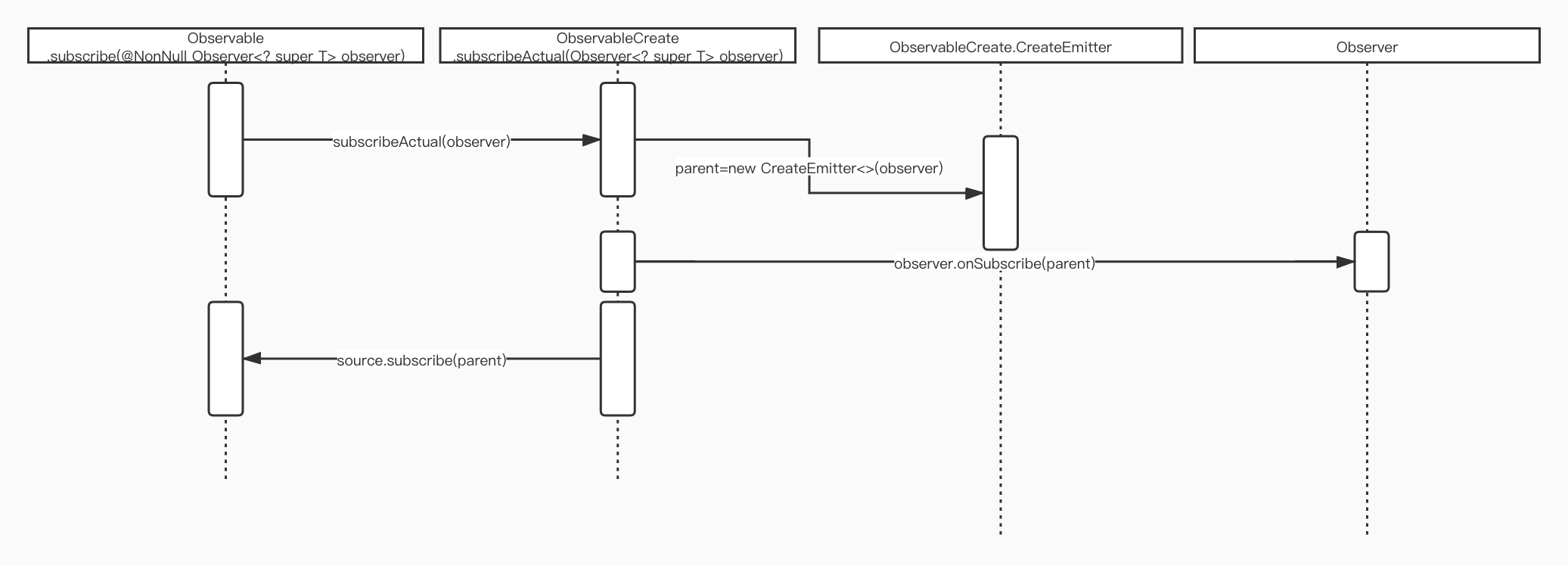
时序图中看到
subscribeActual的调用也不算太复杂,也很容易看懂。
Observable.create将我们自己定义的参数ObservableOnSubscribe实例封装为ObservableCreate对象。ObservableCreate内部的subscribeActual是在Observable.subscribe方法中调用的,也就是指定观察者的时候触发。subscribeActual方法内部将Observable.subscribe传进来的观察者Observer对象封装成了Disposable子类ObservableCreate.CreateEmitter的实例,变量为parent。subscribeActual方法内部再调用Observer观察者对象的onSubscribe(parent)方法。也就是我们自己覆盖的onSubscribe方法,参数parent就是我们常用的暂停订阅时的对象。- 最后
subscribeActual内部调用Observable发布者的subscribe(parent)方法,这个parent是把我们自己定义的Observer对象封装成了ObservableCreate.CreateEmitter实例,有onNext,onComplete,onError方法供我们发布这3种类型的事件,subscribe(@NonNull ObservableEmitter<T> emitter)方法调用的emitter.onNext,emitter.onComplete等其实底层是调用的Observer对象的onNext,onComplete等方法,因此发布者可以将发布的事件通知到订阅的Observer`观察者对象。
到此为止,基本上我们已经了解到了
Observable.create以及Observable.subscribe的内部的调用链路大致了解了。可以知道,如果我们没有指定subscribeOn方法以及observerOn方法,则发布者发布事件到订阅者订阅事件都是在相同的线程中同步进行的。那么接下来关注下具体切换线程的方法。
4.4 Observable.subscribeOn(@NonNull Scheduler scheduler)源码分析
老规矩,先看下方法的调用时序图:
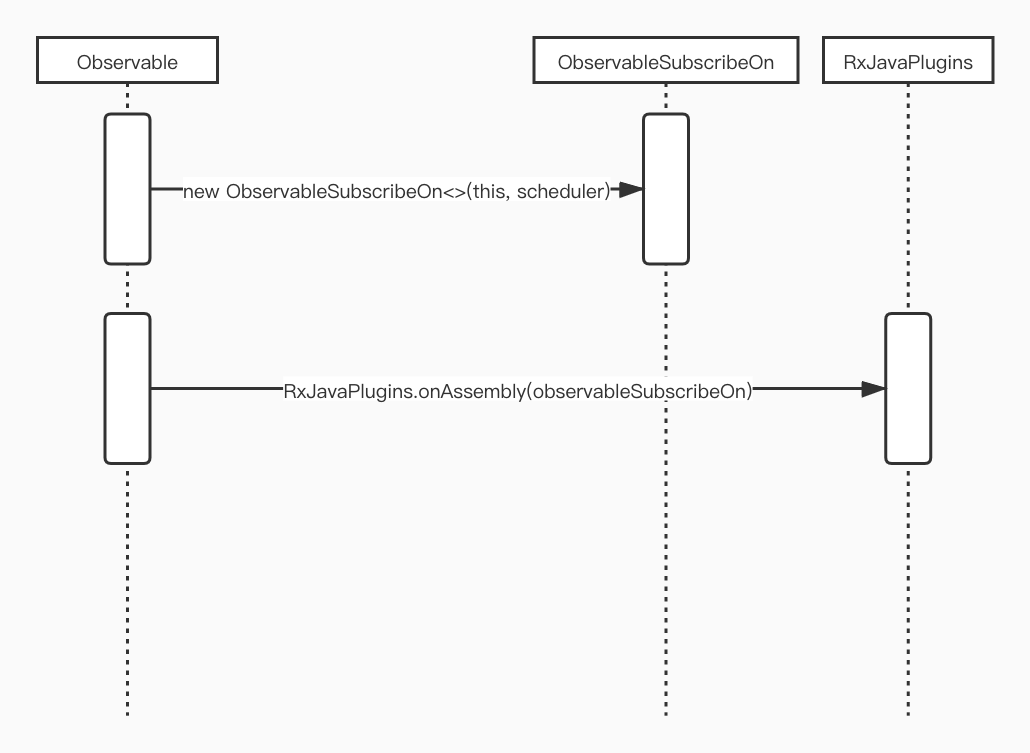
RxJavaPlugins.onAssembly里面就是原样返回ObservableSubscribeOn实例对象,因此需要重点看下ObservableSubscribeOn类以及其中的方法。
4.4.1 ObservableSubscribeOn结构
public ObservableSubscribeOn(ObservableSource<T> source, Scheduler scheduler) {
super(source);
this.scheduler = scheduler;
}
构造方法中是传进来接收两个参数,一个是上一个链式调用上文Observable对象,另一个这里用Scheduler.computation()为例(上文已经进行过源码解析了返回的是ComputationScheduler类的实例)。此外还有个方法subscribeActual方法:
public void subscribeActual(final Observer<? super T> observer) {
final SubscribeOnObserver<T> parent = new SubscribeOnObserver<>(observer);
observer.onSubscribe(parent);
parent.setDisposable(scheduler.scheduleDirect(new SubscribeTask(parent)));
}
上文中分析了ObservableCreate中的subscribeActual方法,这里跟这个也类似,也是在Observable.subscribe方法内部调用了他,因此,整理下这个方法的调用时序图:
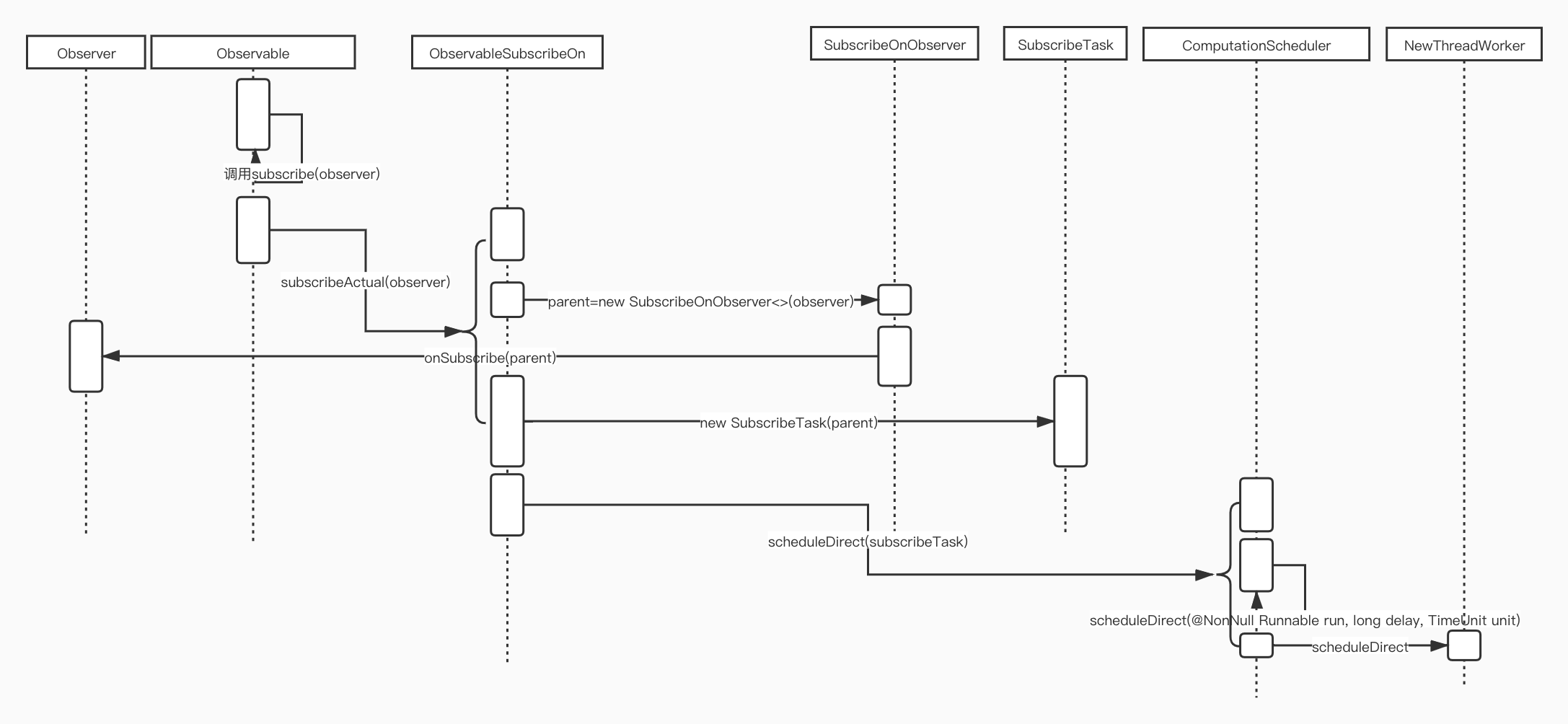
可以看到这里的调用链路稍微有点复杂,但是我稍微平复了下心情,挑选几个重要的地方看下。
4.4.2 SubscribeTask
final class SubscribeTask implements Runnable {
private final SubscribeOnObserver<T> parent;
SubscribeTask(SubscribeOnObserver<T> parent) {
this.parent = parent;
}
@Override
public void run() {
source.subscribe(parent);
}
}
可以看到这是一个
Runnable子类,而且是把Observable对象的subscribe(observer)方法放在了run方法里面运行。因此可以猜出来这样的做法是将Observable.subscribe代码放到了一个单独的线程中运行,继续追根究底,发现运行这个SubscribeTask的地方是ComputationScheduler.scheduleDirect方法:
public Disposable scheduleDirect(@NonNull Runnable run, long delay, TimeUnit unit) {
PoolWorker w = pool.get().getEventLoop();
return w.scheduleDirect(run, delay, unit);
}
这里的ComputationScheduler上文中讲了有一个类型为FixedSchedulerPool的pool实例域,而FixedSchedulerPool中有一个PoolWorker[] eventLoops,这里是通过依次按照索引顺序去PoolWorker[] eventLoops取出一个PoolWorker去运行当前的SubscribeTask。然后调用PoolWorker.scheduleDirect方法,而这个方法内部最核心的代码可以看到:
Future<?> f;
if (delayTime <= 0L) {
f = executor.submit(task);
} else {
f = executor.schedule(task, delayTime, unit);
}
task.setFuture(f);
return task;
是将SubscribeTask扔到executor这个线程池中执行,而executor上文有介绍,是继承自ThreadPoolExecutor的ScheduledThreadPoolExecutor对象,因此源码看到这,可以整理出切换线程的大致思路了:
简单总结下就是调用subscribeOn会返回ObservableSubscribeOn对象,在继续调用subscribe会触发ObservableSubscribeOn对象的subscribeActual方法,而subscribe方法是放在单独的ScheduledExecutorService线程池中执行的。具体如下图所示:
这里再整理一下Observable.subscribe是如何在线程切换场景下调用的:
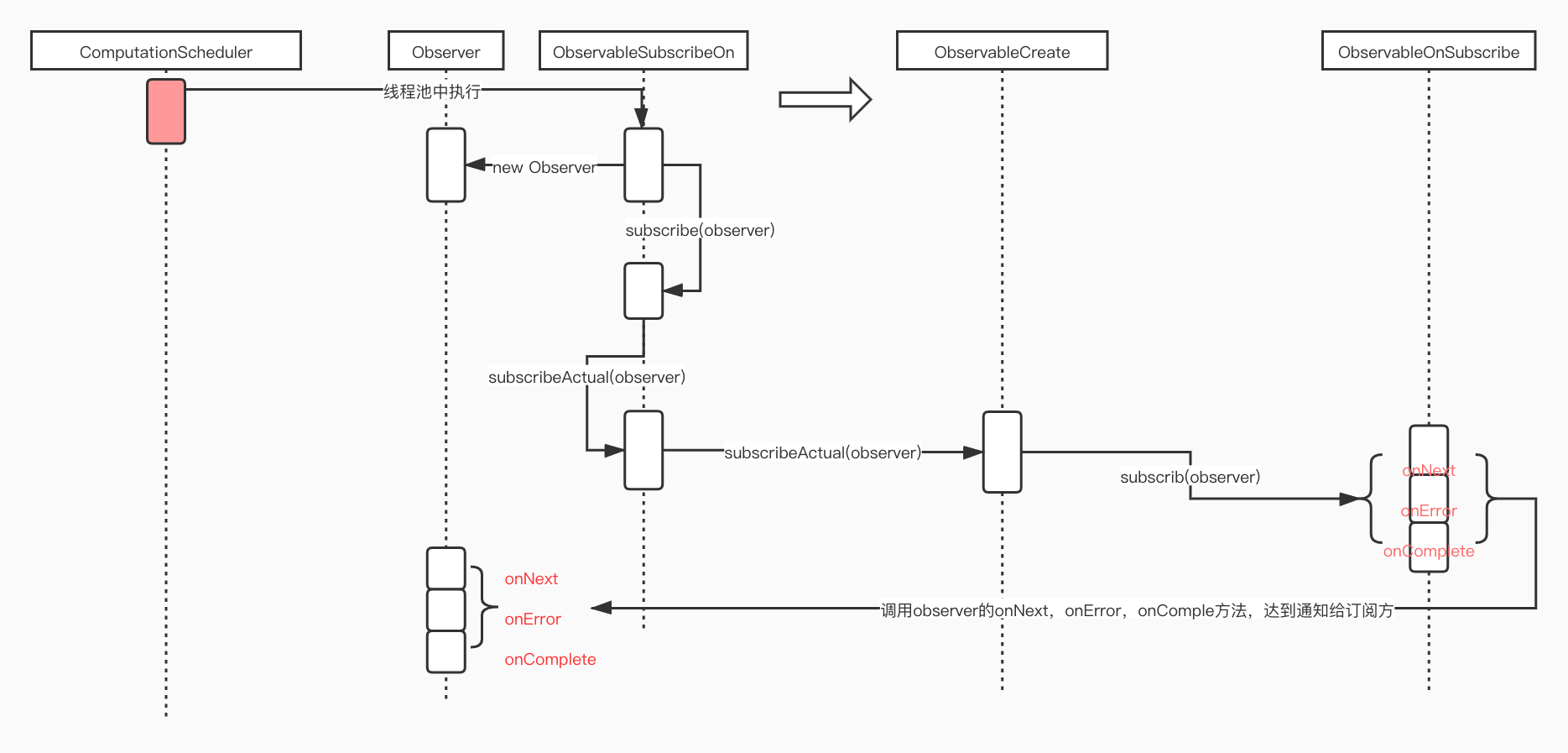
RX的线程切换给搞明白了,其实还有subscribeOn也是指定线程切换,这里不再赘述了。其实分析框架的源码部分虽然很枯燥,但是分析清楚了之后还是比较有成就感的。包括对我们之后写业务代码都有很大的帮助,源码看的多了,一看到业务就知道怎么设计比较优雅。
二、使用RxJava优化业务的注意事项
1、防止内存被耗尽
很典型的一个场景,上游生产的消息比下游要快,这种场景下就需要对发布者发布的消息进行按需发布,不然的话就容易出现系统使用的内存一直增加知道被耗尽。
这里先介绍
反压这个词,举个例子,一个公司10产品,1个开发,开发受不了产品的催上线,拿了把菜刀放在工位上,顿时整个公司和谐了不少,产品也不催了,开发发量也渐渐回来了,这就是反压。
什么意思呢?反压可以让上游按需发布事件,当上游知道下游处理不过来了,就会根据提供的拒绝策略进行丢弃或其他的决策。具体的RxJava提供的拒绝策略篇幅原因不再赘述,这里讲一下业务中如果需要上游按需发布,又要不能丢弃这该怎么做呢?先别着急,这里先举一个如果没有使用反压会有什么情况。
Observable.create(emitter -> {
int count = 1;
while(true) {
emitter.onNext(count);
count++;
}
}).subscribeOn(Schedulers.computation()).observeOn(Schedulers.newThread()).subscribe(new Observer<Object>() {
@Override
public void onSubscribe(@NonNull Disposable d) {
}
@Override
public void onNext(@NonNull Object o) {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("o = " + o);
}
@Override
public void onError(@NonNull Throwable e) {
}
@Override
public void onComplete() {
}
});
Thread.sleep(60000L);
使用JProfiler查看系统的内存使用情况:

图中可以看到上游一直发送,而下游消费的时候由于网路请求总有一些慢业务,这里用
sleep(50)50毫秒做模拟,可以看到内存的使用情况一路飙升,这要是在实际业务场景中上线了,那领导不得当场将我送去非洲。
因此,需要使用Flowable(这里不叙述了,在Observable的基础上增加了反压功能)做反压的处理。
1.1、优雅的使用反压
Flowable.create(new FlowableOnSubscribe<Integer>() {
@Override
public void subscribe(@NonNull FlowableEmitter<Integer> emitter) throws Throwable {
int count = 1;
while (true) {
if (emitter.requested() == 0) {
continue;
}
emitter.onNext(count);
count++;
}
}
}, BackpressureStrategy.MISSING)
.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.newThread())
.subscribe(new Subscriber<Integer>() {
private Subscription s;
@Override
public void onSubscribe(Subscription s) {
s.request(Integer.MAX_VALUE);
this.s = s;
}
@Override
public void onNext(Integer integer) {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("integer = " + integer);
s.request(1);
}
@Override
public void onError(Throwable t) {
System.out.println("t = " + t);
}
@Override
public void onComplete() {
}
});
Thread.sleep(60000);
使用JProfiler查看系统内存情况:

可以看到后面基本上就是0.58G维持平稳了,而且最后的结果中,上游发送的消息没有任何丢弃。这里说明下
FlowableEmitter这个类就不在进行源码分析了,功能与CreateEmitter类似,只不过加了某些功能,其中关注下这个方法:
/**
* The current outstanding request amount.
* <p>This method is thread-safe.
* @return the current outstanding request amount
*/
long requested()
他返回的是下游缓存池可用空间,默认的缓存队列大小为128,每消费累积到95条上游发送的数据时,进行一次清理,具体累计消费多少条上游的数据进行一次清理,这个大家可以代码中进行验证。
因此,对于内存
OOM这块的问题我们已经知道怎么解决了。
2、将阻塞代码拆分的尽量细
并行处理的时候,将阻塞代码尽可能的拆分的足够细,这样去处理一批数据的时候,时间就会消耗的更少。这也很好理解,比如处理业务中的有3个步骤(1),(2),(3),每一步骤的耗时为1,2,3秒。将3个步骤拆分到不同的Flowable或者Observable,这样总体的吞吐量就会得到巨大的提高,这一步各位可以验证下,这里篇幅原因就不在继续叙说了。
最后,欢迎各位观众老爷点赞留言关注。一周一肝,
caffe与你下周不见不散!
