

PS:本文使用的Java源码是JDK1.8。
之前写过一篇类似的文章,但是因为给出的 demo 错误,所以删除原文章重写一份。
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
for (int j = 0; j < 100; j++) {
double i = Math.random() * 100000;
map.put("键" + i, "值" + i);
map.remove("键" + i);
}
System.out.println("map size is: " + map.size());
}
这段代码并不复杂,先新增一个 key,然后再把这个 key 移除。
运行结果如图。
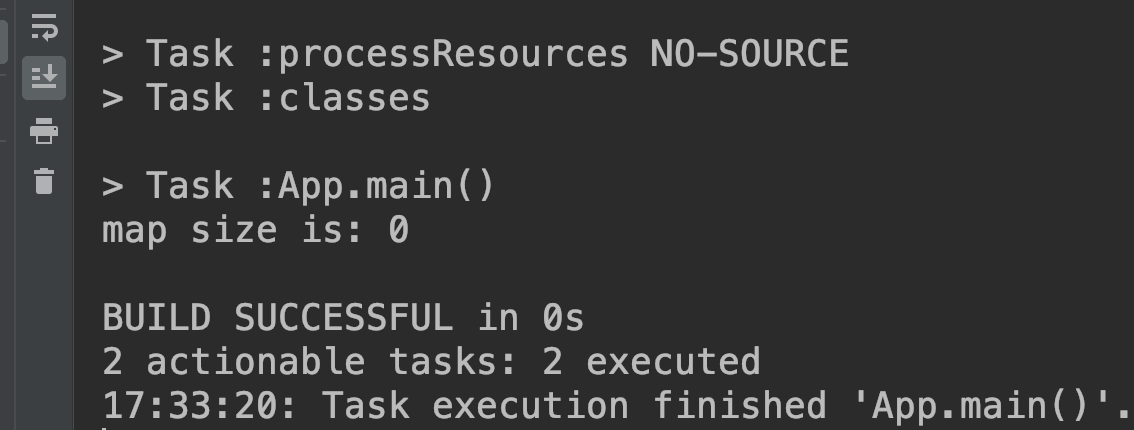
结果不出所料,也没有什么新意,就是预料中的结果:size = 0;
现在我们上一组多线程代码。
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
for (int i = 0; i < 1000; i++) {
MyThread myThread = new MyThread(map, "线程名字1:" + i);
myThread.start();
MyThread myThread1 = new MyThread(map, "线程名字2:" + i);
myThread1.start();
}
System.out.println("map size is: " + map.size());
}
static class MyThread extends Thread {
public Map map;
public String name;
public MyThread(Map map, String name) {
this.map = map;
this.name = name;
}
public void run() {
double i = Math.random() * 100000;
map.put("键" + i, "值" + i);
map.remove("键" + i);
}
}
来猜猜这个结果,size 大小,买定离手。
能猜中算我输,这段代码执行结果具有不确定性。运行结果就不截图了,你们运行结果也不一定和我一样的。
试试已经证明:HashMap 是多线程不安全的,那么为什么呢?
先看看 size() 源码。
public int size() {
return size;
}
很简单的逻辑,然后我们看看size这个变量说明
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
这个变量描述了当前 map 集合包含的键值对数量,transient 表明这个字段不会被序列化,当然这个标识和我们要分析的内容无关。
为什么 size 的数值和预期的数值对不上?
话不多说,直接上源码。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
这一段平淡无奇,看样子奥秘应该是藏在 putVal() 里面。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//这里是核心,大概就是各种判断,然后赋值的问题,感兴趣的可以自己去了解一下。
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
这里可以看到 size 执行了一次自增操作,好像也没有什么问题。
那么问题出在哪里呢?是什么导致了 size 自增过程出现了问题呢?
这里就要简单的说一下,Java 里面多线程操作时候数据的变化过程了。
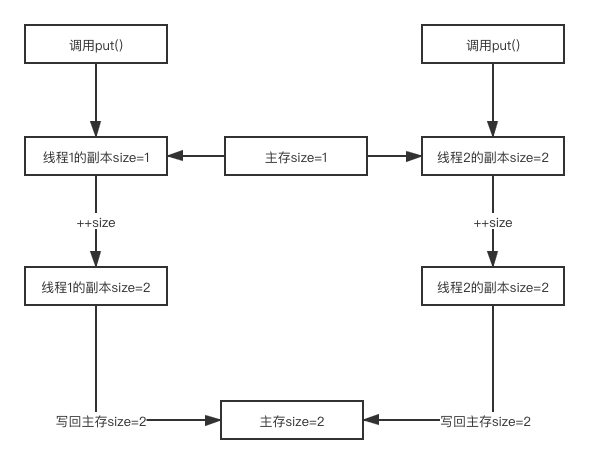
大致过程如上图所示,这也是为什么 size 数据不准确的原因。remove() 方法也是类似的过程,就不详细讲述了。
为什么会出现这样的原因呢?
- CPU 可以在执行到代码任意阶段的时候因为分片时间耗尽,而挂起代码的执行。
- 代码里面没有锁,任意代码都可以随时随地对同一个变量进行修改。
- 没有使用 volatile,导致了不同线程之间的修改对另外的线程不可见。
这只是一个 int 变量分析,更烧脑的 table 存储问题还没有分析。
这里有一个比较有意思的问题,假设线程 A 先调用 get(1),在 get(1) 还没有执行完成的时候,A 线程时间片用尽进入就绪状态,然后 B 线程调用 remove(1) 完成后,A 继续回来执行的 get(1) 的剩余逻辑,会是一个什么结果呢?答案无从得知,有兴趣的可以自己模拟实验一下的。
或许你会说,哪有那么巧合的事情?世界之大,无奇不有。世界那么大,你应该出去看看。
总结:线程不安全问题属于并发问题之一的,属于相对高级的问题了。这个时候的问题已经不仅仅局限于代码层面了,很多时候需要结合 JVM 一起分析了。
