

前言
每周一次的例行发版,照常来临。我熟悉的打开发版系统,同时也打开了服务监控系统,好让别人看的出来我是一个对业务负责的小伙子。吨吨吨,吨吨吨,一顿操作...妈耶,这是咋回事,下游服务dubbo请求超时这么多,看了看我的劳力土,再看了看监控,一分钟400+的请求超时,请求超时数是原来的10倍,上升到了百的量级...
故事发生在这周二的深夜。当时准备上一个需求,会导致服务中单个线程的IO变长,这个是预知的。在灰度中,发现了下游的服务dubbo请求超时数增加,脑海中立马想到了去查了底层存储的监控,发现底层存储服务的999线都正常,凭借着多年的经验,脑海中一个声音告诉我一定是服务GC出问题了。

然后看了服务的GC,果然单次gc的时间比之前增加了不少。
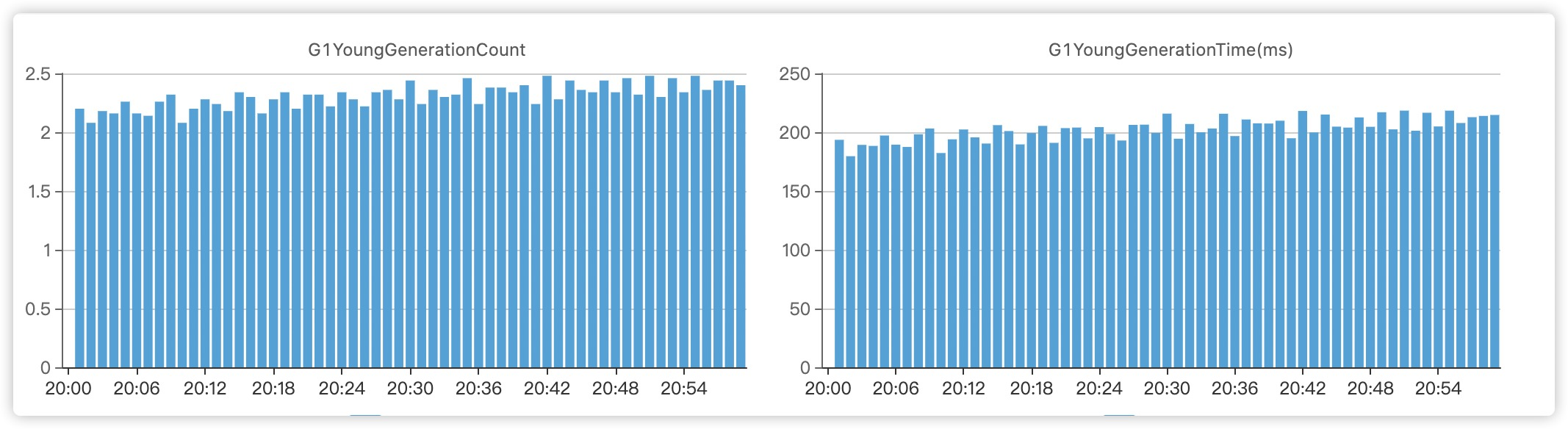
当时立马找了下游的服务,告诉我这部分的超时是在范围允许之内的,心里终于松了一口气。于是继续搞其他的业务去了,虽然我故作淡定,其实当时心里已经慌的不行了。
这时候机智的你是不是说不行就扩容呗,但我是那么容易妥协的人吗?这不是考验我内功的时候吗?虽然我平时干着CRUD的活,但哪一个程序员不喜欢研究各种技术呢?这是所有程序员的浪漫!于是忙完了手头上的活之后开始了gc调优。
处理过程
- 将gc日志打印出来。可以在虚拟机的启动gc参数中增加
-XX:+PrintGCDetails参数,将每次的GC的耗时信息打印出来。 - 分析日志,找到到底是哪些GC阶段导致了GC时间的上涨。
当时的GC日志:
%xwEx[GC pause (G1 Evacuation Pause) (young), 0.0962103 secs]
[Parallel Time: 23.3 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 146441.2, Avg: 146441.3, Max: 146441.3, Diff: 0.1]
[Ext Root Scanning (ms): Min: 1.5, Avg: 1.8, Max: 2.4, Diff: 1.0, Sum: 7.2]
[Update RS (ms): Min: 1.0, Avg: 1.5, Max: 1.7, Diff: 0.6, Sum: 5.9]
[Processed Buffers: Min: 27, Avg: 34.8, Max: 41, Diff: 14, Sum: 139]
[Scan RS (ms): Min: 0.3, Avg: 0.3, Max: 0.3, Diff: 0.0, Sum: 1.3]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.5, Max: 1.1, Diff: 1.1, Sum: 1.9]
[Object Copy (ms): Min: 18.3, Avg: 19.0, Max: 19.6, Diff: 1.2, Sum: 76.1]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.8, Max: 3, Diff: 2, Sum: 7]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
[GC Worker Total (ms): Min: 23.1, Avg: 23.2, Max: 23.2, Diff: 0.1, Sum: 92.7]
[GC Worker End (ms): Min: 146464.4, Avg: 146464.4, Max: 146464.5, Diff: 0.1]
[Code Root Fixup: 0.1 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.7 ms]
[Other: 72.1 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 69.9 ms]
[Ref Enq: 0.6 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.1 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.8 ms]
[Eden: 4824.0M(4824.0M)->0.0B(4820.0M) Survivors: 88.0M->92.0M Heap: 5044.1M(8192.0M)->224.1M(8192.0M)]
[Times: user=0.17 sys=0.00, real=0.09 secs]
当时GC中基本都是young GC类型的日志,因此不存在Mixed GC中对于old genaration回收所造成的gc时间增加。然后发现了Ref Proc这一过程消耗的比较久,然后迅速的想到了并行开启-XX:+ParallelRefProcEnabled,并且调大了并行标记的线程-XX:ConcGCThreads,以及增加了-XX:G1HeapRegionSize,一套下来行云流水,开始了枯燥的发版过程。果然一切都在我的预料之中:
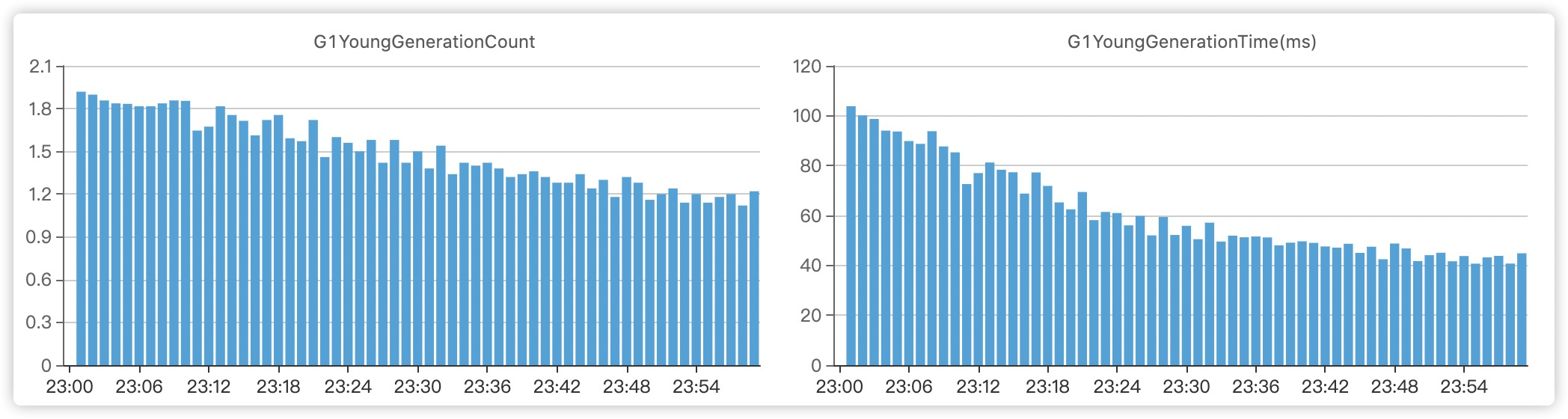

等等,我这就完了?当然不是,我的目的是想让大家看了这篇之后就知道以后如何去优化高并发服务的gc问题,我敢说即使很多在一线大厂中打拼了很多年的老开发,对gc参数调优这块也是一知半解,因此这部分的知识会了,可以很容易在面试以及在工作中脱颖而出!我会在下面的篇幅中循序渐进,由浅入深的讲解关于虚拟机的GC。
常见的收集器对比
目前大多数的公司开发都是基于jdk8,主流使用的GC收集器主要是G1,这里拿CMS和G1进行简单的对比,来突出G1这款收集器是多么的优秀!可能有的小公司使用的Parallel收集器,但是Parallel真的是一款毫无特色的收集器,用它跟G1对比简直差距太大了。这里只先做对比,相关细节后续在详解,这里只是突出为什么大多数公司选择G1的原因。
G1回收阶段
- 初始标记
- 并发标记
- 最终标记(并发)
- 筛选回收(并发)
CMS回收阶段
- 初始标记
- 并发标记
- 重新标记
- 并发清除
CMS和G1的相同部分
- 初始标记都需要停顿,即不能与用户线程并行,需要Stop The Wrold。都是标记能与GC Roots直接关联的对象(GC Roots的概念会在后续的虚拟机系列中详解,本篇中与GC无关的概念先不介绍)
- 并发标记可以与用户线程一起,即不需要停顿。并发标记主要是沿着GC Reference Chain进行对象可达性分析的过程。
CMS和G1的不同点
- CMS的并发回收是与用户线程一起进行的,不需要停顿。如果有垃圾是在标记过程后产生的,那么就会产生一个回收不彻底的问题。设想一下一边打扫房间,一边有人在那扔垃圾,那么最后的打扫效果是不是不好?而G1的筛选回收是需要暂停用户线程,但是是并发回收的,所以速度快,而且回收效率高。
- CMS的回收器不可以对young generation回收,只能对old generation回收。因此需要与其他收集器配合,比如ParNew或者Serial。而G1无论是young还是old都可以回收,人家可以独立管理整个java堆。而且回收算法是采用的标记整理(局部是复制清除算法,因为young generation中采用复制清除效率更高),不会产生内存碎片的问题。对比CMS只是可怜的标记清除,在一些高qps场景的服务中,内存碎片化很严重,很容易造成Full Gc!
- java堆在使用这两款回收器的时候,内存布局不同。在使用CMS收集器时,新生代和老年代是物理隔离的(为两个不同的连续的内存区域)。而用G1是对整个Heap划分成若干个不同的Region,新生代和老年代是相互交叉的内存区域,是逻辑上的分类。这样划分的目的是规避每次在对象进行可达性分析都要在堆的全区域中进行。比如一个Collection Set中的每个region都对应着一个Remembered set,G1可以维护这个Remembered Set,从中挑选出最具回收性价比的region进行回收,G1嘛,就是Grabage First,提高回收效率。
因此通过对比发现,从业务的角度考虑,G1优点不言而喻,分代收集,不容易产生内存碎片化,一次回收比较彻底,不容易Full gc,并发标记,停顿时间相对可控(基于停顿时间和region占用大小判断是否有价值回收)。
G1相关概念介绍
- Region,可以理解为G1所管理的堆中的一个最小单位内存。具体堆中的Region个数是按照RegionSize进行划分,堆中的objects就是分布在一个个Region上,如果对象大小超过了RegionSize,那么该对象就分布在内存区域连续的不同Region上。
- Young region和Old region,顾名思义,young generation的object都是分配在young region中,old generation的大部分object都是分配在old region中(当对象的大小超过了RegionSize的一半时,这些humongous objects就会被分配在humongous region中,这部分region也会被划分为old generation)。young generation包括Eden-region和Survivor-region,Eden-region就是所有新生成的对象分配的region;而Survivor-region就是标记过程中young generation存活的对象所存储的地方,Survivor-region中某些object可能会在后续的阶段被提升为old generation。
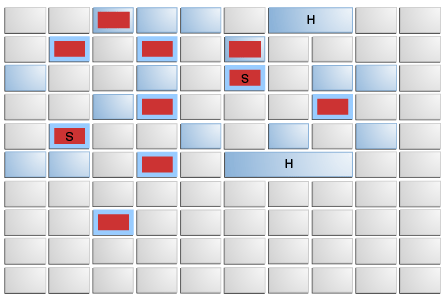
那么可以这样来理解整个GC过程,对于young gc而言,将整个young geenration的对象进行可达性分析,如果发现对象可达,则标记该对象是存活,如果不可达,则标记对象为dead,然后将标记为存活的对象拷贝到survivor regions或者old regions中,将dead objects所处的regions回收。
对于Mixed Gc而言,除了会进行上述的young GC中的对于整个young generation进行标记以及拷贝之外,还会对部分old generation中的old regions进行回收,回收的算法采用的是标记--整理,即尽可能的释放出连续的内存空间范围。
G1回收阶段分类
youg-only phase:将Young regions中的对象提升到Old,存到到Old regions中,然后回收young regions。space-reclamation phase:常说的Mixed GC中的一个阶段。不仅对young regions进行回收,也会筛选有价值的Old regions进行回收。
这两个阶段之间是可以转换的,当老年代的内存使用空间与总老年代空间的百分比超过了一定的阈值(后面篇幅中会讲解),不仅会对young generation进行回收,也会触发对老年代的回收。
说白了就是超过这个阈值之后,会先触发young-only phase阶段,然后young GC完了之后在进行space-reclamation phase阶段,对老年代进行回收;如果老年代的使用空间占总得老年代空间没有到达阈值,则不会触发space-reclamation phase,只会继续开启下一个youg-only phase,进行循环。
G1回收期间的停顿阶段
-
youg-only phase的停顿-
initial Mark:标记GC Roots能直接关联到的对象,停顿时间很短。标记之后会进入Concurrent Marking(不需要停顿),并发标记作用是确定Old regions中的所有存活对象是否需要在接下来的
space-reclamation phase保留。初始标记这一过程可能还没有跑完,另一个不包含初始标记的young gc过程可能就已经开始干活了。初始标记并不一定发生在所有的young gc中,只有老年代的使用空间占总老年代空间大小超过了InitiatingHeapOccupancyPercent,才会触发初始标记。 -
Remark:这一个停顿主要是为了完成标记的过程。因为上一个过程是并发标记,是跟随用户线程一起跑的,因此可能就会并发标记过后,一些对象随着用户线程的执行,可达性发生了变化,因此需要用户线程停下来,去清理一些浮动垃圾。这一过程主要处理
reference processing和一些class的卸载,虽然停顿,但是可以有多个标记线程。 -
CleanUp:也需要停顿。主要进行region的回收,且对空的region也会进行回收。并且确定是否要接着进行
space-reclamation phase阶段。如果需要进行space-recalmation phase,则继续进行,然后cleanUp部分young regions和old regions(有回收价值的old region)。如果确定不需要接着进行space-reclamation phase,则当前的cleanup阶段就相当于是youg-only phase的cleanUp,只是单纯的表示对young generation的cleanUp已经完成了。
-
-
space-reclamation phase的停顿比如Colletions(可以理解可能需要被回收的region的集合,并且一个GC周期中可能有多个这样的集合)中的老年代object引用了新生代的object,那么新生代对象所处的region就会把老年代的region记录进新生代region维护的Remembered set中。因此
space-reclamation phase阶段不仅会对新生代object的region进行GC,也会分析新生代region背后的Remembered set,挑选出回收性价比高的一些old regions进行回收。
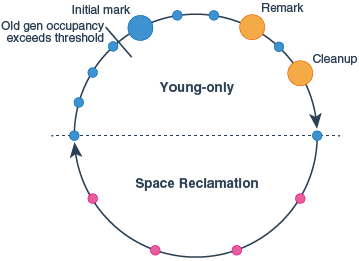
到此为止,我已经把我知道的G1的回收机制都告诉你了,如果你对关于G1回收的算法感兴趣,比如G1标记算法Snapshot-At-The-Beginning等想进一步了解,可以去oracle官网中查看,后续有时间,我也会出一期这样的文章。接下来我会针对不同的GC场景进行分析,以及给出相关的建议。坐稳了,发车!
GC实战优化环节
Full GC
这是G1(大多数收集器也同样)的一个兜底GC的阶段。原因主要是太多old generation的内存占用导致,比如程序中使用了某一个模板解析引擎,但是没有提取变量,导致每一次执行都是编译一个新的class,这种情况就很容易导致Full GC,或者有很多humongous objects的存在。如果程序中发生了Full gc,除了GC相关的调优,也需要多花时间去优化你的业务代码。
直白一点就是因为创建了太多的object,导致g1不能及时的去回收。常见的场景是Concurrent Marking没有及时complete。
因此Full GC的优化思路主要分为两个方面:
- 缩小Concurrent Marking的时间;
- 或者调大old gen区域。
Full GC调优Tips:
-
如果可能是大对象太多造成的,可以
gc+heap=info查看humongous regions个数。可以增加通过-XX:G1HeapRegionSize增加Region Size,避免老年代中的大对象占用过多的内存。 -
增加heap大小,对应的效果G1可以有更多的时间去完成
Concurrent Marking。 -
增加
Concurrent Marking的线程,通过-XX:ConcGCThreads设置。 -
强制mark阶段提早进行。因为在Mark阶段之前,G1会根据应用程序之前的行为,去确定
the Initiating Heap Occupancy Percent(IHOP)阈值大小,比如是否需要执行initial Mark,以及后续CleanUp阶段的space-reclamation phase;如果服务流量突然增加或者其他行为改变的话,那么基于之前的预测的阈值就会不准确,可以采取下面的思路:- 可以增加G1在
IHOP分析过程中的所需要的内存空间,通过-XX:G1ReservePercent来设置,提高预测的效率。 - 关闭G1的自动
IHOP分析机制,-XX:-G1UseAdaptiveIHOP,然后手动的指定这个阈值大小,-XX:InitiatingHeapOccupancyPercent。这样就省去了每次预测的一个时间消耗。
- 可以增加G1在
-
Full gc可能是系统中的humongous object比较多,系统找不到一块连续的regions区域来分配。可以通过
-XX:G1HeapRegionSize增加region size,或者将整个heap调大。
Mixed GC或者Young GC调优
Reference Object Processing时间消耗比较久
gc日志中可以看Ref Proc和Ref Enq,Ref ProcG1根据不同引用类型对象的要求去更新对应的referents;Ref EnqG1如果实际引用对象已经不可达了,那么就会将这些引用对象加入对应的引用队列中。如果这一过程比较长,可以考虑将这个过程开启并行,通过-XX:+ParallelRefProcEnabled。
young-only回收较久
主要原因是Collection Set中有太多的存活对象需要拷贝。可以通过gc日志中的Evacuate Collection Set看到对应的时间,可以增加young geenration的最小大小,通过-XX:G1NewSizePercent。
也可能是某一个瞬间,幸存下来的对象一下子有很多,这种情况会造成gc停顿时间猛涨,一般应对这种情况通过-XX:G1MaxNewSizePercent这个参数,增加young generation最大空间。
Mixed回收时间较久
通过开启gc+ergo+cset=trace,如果是predicated young regions花费比较长,可以针对上文中的方法。如果是predicated old regions比较长,则可以通过以下方法:
- 增加
-XX:G1MixedGCCountTarget这个参数,将old generation的regions分散到较多的Collection(上文有解释)中,增加-XX:G1MixedGCCountTarget参数值。避免单次处理较大块的Collection。
那么现在回过头去看我之前调整的参数,是不是明白了我调整了之后,服务的GC效率立马提升了呢?其实调优的过程不是一蹴而就的,需要持续打磨,有了经验之后,你看到之后想到的东西永远比别人多!
手写辛苦,欢迎各位点个赞留言,也顺带恭喜FPX和TES携手共进决赛哈哈。
