

printf输出格式
%d 数字
%s 字符串
%x (X) , %p 地址
%T 值类型
变量赋值
// Var project main.go
package main
import (
"fmt"
)
func main() {
//声明并初始化一个变量
var m int = 10
fmt.Printf("定义的变量值为:%d \n", m)
//声明初始化多个变量
var i, j, k = 1, 2, 3
fmt.Printf("定义的变量值为:%d、%d、%d \n", i, j, k)
//声明时不指明类型,通过初始化值来推导
var b = true //bool型
if b == true {
fmt.Printf("bool值为真.\n")
}
//一种简单的方式 等价于 var str string = "Hello"
str := "Hello"
fmt.Printf("定义的变量值为:%s \n", str)
//Go的编译器对声明却未使用的变量在报错
//使用保留字var声明变量 然后给变量赋值
var number int
number = 121
fmt.Printf("定义的变量值为:%d \n", number)
//变量定义的另一种形式 这种情况下变量的类型是由值推演出来的
text := "hahaya"
fmt.Printf("定义变量的值为:%s \n", text)
//多个变量的声明(注意小括号的使用)
var (
no int
name string
)
no = 1
name = "hahaya"
fmt.Printf("学号:%d \t 姓名:%s \n", no, name)
//多个变量声明、定义的另一种形式
x, y := 2, "ToSmile"
fmt.Printf("学号:%d \t 姓名:%s \n", x, y)
//Go中有一个特殊的变量_ 任何赋给它的值将被丢弃
_, Ret := 2, 3
fmt.Printf("变量的值为:%d \n", Ret)
}
基本数据类型
bool
string
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte //alias for uint8
rune // alias for int32,represents a Unicode code point
float32 float64
complex64 complex128
类型转换
与其他主要编程语言的差异
1.Go 语言不允许隐式类型转换
2.别名和原有类型也不能进行隐式类型转换
3.不支持指针运算
4.string是值类型,其默认的初始化值为空字符串,而不是nil
类型的预定义值
1.math.MaxInt64
2.math.MaxFloat64
3.math.MaxUint32
位运算符
&^按位置清零
go语言中按位取反写法是^, 所以 a&^b 其实是 a&(^b) 利用运算符优先级省略掉括号的写法而已. 下面的测试方法可以自行验证一下. 其它语言中关键字不同写法可能是 a&(~b),

循环
for i := 0; i <= 9; i++ {
//for loop
}
n := 0
for n <= 5 {
n++;
//while loop
}
for {
//while(true) loop
}
条件语句
1.condition必须为布尔值
2.支持变量赋值
if var declaration; condition{
//code
}
//example
if a := 1 == 1; a{
//****
}
if v,err := fun(); err == nil{
//****
}
//switch
1.条件表达式不限制为常量或者整数;
2.单个case中,可以出现多个结果选项,使用逗号分隔;
3.与C语言等规则相反,Go 语言不需要用break来明确退出一个case;
4.可以不设定switch之后的条件表达式,在此种情况下,整个switch结构与多个i...else..的逻辑作用等同
//switch ONE
switch os := runtime.GOOS; os{
case "darwin","xx":
fmt.Println("OS X")
case "linux","windows":
fmt.Println("Linux")
default:
fmt.Println("else things")
}
//switch TWO
switch {
case 0 <= num && num <= 3:
//***
case 4 <= num && num <= 6:
//***
case 7 <= num && num <= 9:
//***
}
数组
数组的声明
var a [3]int //声明并初始化为默认零值
a[0] = 1
b := [3]int{1,2,3} //声明同时初始化
c := [...]int{1,2,3,4}
d := [2][2]int{{1,2},{3,4}} //多维数组初始化
数组的截取
a[ 开始索引(包含) , 结束索引(不包含) ]
//example
a := [...]int{1,2,3,4,5}
a[1:2] // 2
a[1:3] // 2,3
a[1:len(a)] // 2,3,4,5
a[1:] // 2,3,4,5
a[:3] // 1,2,3
切片slice
切片的声明与使用
var s []int
t.Log(len(s),cap(s))
s = append(s, 1)
t.Log(len(s), cap(s))
s1 := []int{1,2,3,4,5}
t.Log(len(s1), cap(s1))
s2 := make([]int,3,5)
t.Log(len(s2), cap(s2))
/*
[]type,len,cap其中1en个元素会被初始化为默认零值,未初始化元素不可以访问
*/
list := make([]*int, 3)
切片共享存储结构
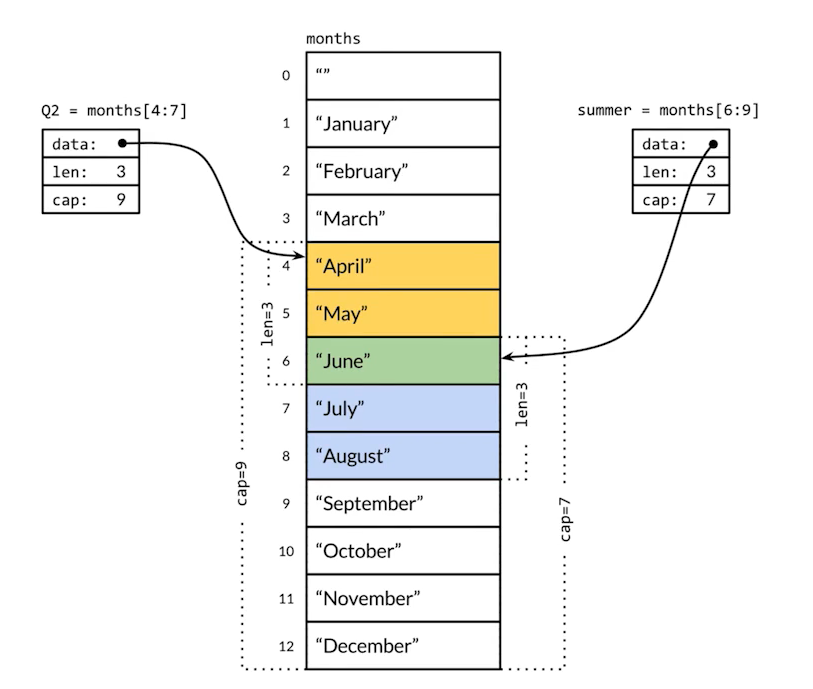
func TestShareMemory(t *testing.T) {
year := []string{"Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sept","Oct","Nov","Dec"}
Q2 := year[3:6]
t.Log(Q2, len(Q2), cap(Q2))
summer := year[5:8]
t.Log(summer, len(summer), cap(summer))
summer[0] = "unknown"
t.Log(Q2)
}
切片不能进行比较
func TestCompare(t *testing.T) {
a := []int{1,2,3,4}
b := []int{1,2,3,4}
if a == b {
//ERROR!!
}
}
invalid operation: a == b (slice can only be compared to nil)
Map
Map的声明
注意!不能使用cap(map)
m := map[string]int{"one": 1, "two": 2, "three": 3}
t.Log(m["two"])
t.Logf("len m = %d", len(m))
m1 := map[string]int{}
m1["one"] = 1
t.Logf("len m1 = %d",len(m1))
m2 := make(map[string]int,10)//不初始化len
t.Logf("len m2 = %d",len(m2))
Map的元素访问及遍历
访问map中不存在的key时,会返回value的初始值。
因此一般需要先判断key是否存在,采用以下代码来判断。
func TestAccessNotExistingKey(t *testing.T) {
m1 := map[int]int{}
t.Log(m1[1])
m1[2] = 0
t.Log(m1[2])
m1[3] = 0
if v,ok := m1[3]; ok {
t.Logf("key 3 is exist,value is %d",v)
}else {
t.Log("key 3 is not exist")
}
}
func TestMap(t *testing.T) {
m := map[string]int{"one": 1, "two": 2, "three": 3}
t.Log(m["two"])
t.Logf("len m = %d", len(m))
m1 := map[string]int{}
m1["one"] = 1
t.Logf("len m1 = %d",len(m1))
m2 := make(map[string]int,10)//不初始化len
t.Logf("len m2 = %d",len(m2))
for k, v := range m {
t.Log(k,v)
}
}
将value值置为方法
func TestFactory(t *testing.T) {
m := map[int]func(op int)int{}
m[1] = func(op int) int {return op}
m[2] = func(op int) int {return op*op}
m[3] = func(op int) int {return op*op*op}
for i := 0; i < 3; i++ {
t.Log(m[i+1](2))
}
}
实现Set
Go的内置集合中没有Set实现,可以map[type]bool
1.元素的唯一性
2.基本操作
1)添加元素
2)判断元素是否存在
3)删除元素
4)元素个数
func TestSet(t *testing.T) {
set := map[int]bool{}
set[1] = true
n := 1
if set[n] {
t.Logf("%d is exist",n)
}else {
t.Logf("%d is not exist",n)
}
delete(set,1)
if set[n] {
t.Logf("%d is exist",n)
}else {
t.Logf("%d is not exist",n)
}
}
字符串
与其他主要编程语言的差异
1.string是数据类型,不是引用或指针类型
2.string 是只读的byte slice,len函数可以它所包含的byte数
3.string的byte数组可以存放任何数据
strings包
//Split方法,Join方法
func TestStrfn(t *testing.T) {
s := "A,B,C"
parts := strings.Split(s,",")
for _, part := range parts {
t.Log(part)
}
t.Log(strings.Join(parts,"-"))
}
strconv包
//数字与字符串之间的转换
func TestStrconv(t *testing.T) {
s := strconv.Itoa(10)
t.Log("str" + s)
if i,err := strconv.Atoi("10");err == nil {
t.Log(10+i)
}
}
函数
与其他主要编程语言的差异
1.可以有多个返回值
2.所有参数都是值传递:slice,map,channel会有传引用的错觉
3.函数可以作为变量的值
4.函数可以作为参数和返回值
将函数作为参数或返回值的写法
//如同装饰模式,以下代码实现了计算运行某一特定函数所需的时间
func TestFun(t *testing.T) {
res := timeSpent(slowFun)
t.Log(res(10))
}
func slowFun(op int) int {
time.Sleep(time.Second*2)
return op
}
func timeSpent(inner func(op int) int) func(op int) int{
return func(n int) int {
start := time.Now()
ret := inner(n)
fmt.Println("time spent:",time.Since(start).Seconds())
return ret
}
}
可变参数
func TestPar(t *testing.T) {
t.Log(sum(1,2,3,4,5,6))
}
func sum(ops ... int) int {
s := 0
for _, op := range ops {
s += op
}
return s
}
defer 延迟执行
panic中断程序。
func TestDefer(t *testing.T) {
defer func() {
t.Log("defer part")
}()
t.Log("2")
t.Log("3")
panic("error")
}
行为的定义和实现
实例创建及初始化

type Employee struct {
name string
age int
class int
}
func TestType(t *testing.T) {
em := Employee{
name: "songzhiyan",
age: 18,
class: 7,
}
em1 := &Employee{
name: "122131",
age: 0,
class: 0,
}
em2 := new(Employee)
em2.name = ""
t.Log(em,em1,em2)
t.Logf("em is %T",em)
t.Logf("em2 is %T",em2)
}
行为的定义
type Employee struct {
name string
age int
class int
}
func (e *Employee) String() string {
return fmt.Sprintf("\ne's name is %s age is %d class is %d\n",e.name,e.age,e.class)
}
func TestMethod(t *testing.T) {
em := Employee{
name: "SongZhiYan",
age: 18,
class: 7,
}
t.Log(em.String())
}
接口的定义与实现
DUCK TYPE
特点
1.接口为非入侵性,实现不依赖于接口定义
2.所以接口的定义可以包含在接口使用者包内
type Programmer interface {
Hello() string
}
type GoLearner struct {
}
func (p *GoLearner)Hello() string {
return fmt.Sprint("hello world")
}
func TestInterface(t *testing.T) {
var p Programmer
p = new(GoLearner)
t.Log(p.Hello())
}
接口变量
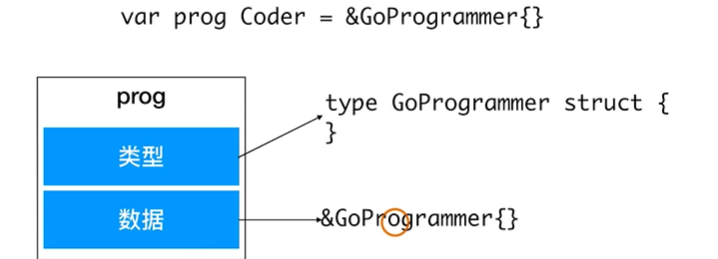
自定义类型
type IntConv func(op int) int
func console(inner IntConv) IntConv {
return func(n int) int {
start := time.Now()
ret := inner(n)
fmt.Println("time spent: ",time.Since(start).Seconds())
return ret
}
}
匿名嵌套
、、******
不一样的接口类型,一样的多态
需要注意的点
package interfaceTry
import (
"fmt"
"testing"
)
type Programmer interface {
Hello() string
}
type GoLearner struct {}
type JavaLearner struct {}
func (p *GoLearner)Hello() string {
return "fmt.Sprint(\"hello world\")"
}
func (p *JavaLearner)Hello() string {
return "System.out.println(\"hello world\")"
}
func TestInterface(t *testing.T) {
g := new(GoLearner)
********************
//注意!!!此处会出错!!!
//因为此时方法console(p Programmer)的Programmer是一个interface,所以只能对应指针类型的实例!!
//改成j := new(JavaLearner)或者j := &JavaLearner{}
j := JavaLearner{}
********************
console(g)
console(j)
}
func console(p Programmer) {
fmt.Printf("%T %v\n",p,p.Hello())
}
空接口与断言
1.空接口可以表示任何类型
2.通过断言来将空接口转换为制定类型v,ok:=p.(int)//ok=true 时为转换成功
3.断言:
value, ok = element.(T)
//这里value就是变量的值,ok是一个bool类型,element是interface变量,T是断言的类型。
//如果element里面确实存储了T类型的数值,那么ok返回true,否则返回false。
4.例子
func DoSomething(p interface{}) {
if i,ok := p.(int);ok{
fmt.Println("Integer : ",i)
}
if s,ok := p.(string);ok {
fmt.Println("String : ",s)
}
switch p.(type) {
case string:
fmt.Println("string")
case int:
fmt.Println("int")
case bool:
fmt.Println("bool")
}
}
断言学习注意 :studygolang.com/articles/11…
补充:golang 中的 type switch 类型判断
a可能是任意类型
a.(某个类型) 返回两个值 inst 和 ok ,ok代表是否是这个类型,Ok如果是 inst 就是转换后的 类型
a.(type) type是关键字 结合switch case使用
TypeA(a) 是强制转换
func (a interface{}){
//第一种
if inst,ok:=a.(TypeA);ok{
inst.MethodA()
}
//第二种
switch inst:=a.(type){
case TypeA:
inst.MethodA()
default:
fmt.Println("unknow")
}
}
Go接口最佳实践
1.倾向于使用小的接口定义,很多接口只包含一个方法
type A interface {
Hello()
}
type B interface {
World()
}
2.较大的接口定义,可以有多个小接口定义组合而成
type C interface {
A
B
}
3.只依赖于必要功能的最小接口
*****
Go的错误处理
1.没有异常机制
2.error类型实现了error接口
type error interface{
Error() string
}
3.可以通过errors.new来快速创建错误实例
errors.New("n must be in the range [0,1]")
panic
- panic用于不可以恢复的错误
- panic退出前会执行defer指定的内容
panic vs os.exit
- os.exit退出时不会调用defer指定的函数
- os.exit退出时不输出当前调用栈信息
recover
defer func(){
if err := recover(); err != nil{
//恢复错误
log.Error("recovered panic",err)
}
}
package 包
一
- 基本复用模块单元(以首字母大写来表明可被包外代码访问)
- 代码的package可以和所在的目录不一致
- 同一目录里的Go代码的package要保持一致
init方法
- 在main 被执行前,所有依赖的package的init 方法都会被执行
- 不同包的init函数按照包导入的依赖关系决定执行顺序
- 每个包可以有多个init函数
- 包的每个源文件也可以有多个init函数,这点比较特殊
获取远程包的实例

-
通过go get来获取远程依赖
·go get-u强制从网络更新远程依赖
-
注意代码在GitHub上的组织形式,以适应go get
·直接以代码路径开始,不要有src
package remote_package
import (
cm "github.com/easierway/concurrent_map"
"testing"
)
func TestRe(t *testing.T) {
m := cm.CreateConcurrentMap(99)
m.Set(cm.StrKey("Key"),10)
t.Log(m.Get(cm.StrKey("Key")))
}
依赖管理
Go 未解决的依赖问题
- 同一环境下,不同项目使用同一包的不同版本
- 无法管理对包的特定版本的依赖
协程
陷阱
Thread vs Groutine
- 创建时默认的stack的大小:
- jdk5以后java thread stack默认为1M
- Groutine的Stack初始化大小为2k
- 和KSE(Kernel Space Entity)的对应关系
- Java Thread是1:1
- Groutine是M:N
共享内存并发机制
mutex互斥锁
func TestShare(t *testing.T) {
var mut sync.Mutex
counter := 0
for i := 0; i < 5000; i++ {
go func() {
mut.Lock()
counter++
defer func() {
mut.Unlock()
}()
}()
}
time.Sleep(1 * time.Second)
t.Logf("counter = %d",counter)
}
RWlock读写锁
waitgroup
func TestShare(t *testing.T) {
var mut sync.Mutex
var wg sync.WaitGroup
counter := 0
for i := 0; i < 5000; i++ {
//新加一个需要等待的协程
wg.Add(1)
go func() {
defer func() {
mut.Unlock()
}()
mut.Lock()
counter++
//一个协程已经完成了
wg.Done()
}()
}
//阻塞直到所有协程都完成,才会向下运行
wg.Wait()
t.Logf("counter = %d",counter)
}
CSP ---- channel!!!
channel的关闭
- 向关闭的channel发送数据,会导致panic
- v,ok<-ch;ok为bool值,true表示正常接受,false表示通道关闭
- 所有的channel接收者都会在channel关闭时,立刻从阻塞等待中返回且上述ok值为false。这个广播机制常被利用,进行向多个订阅者同时发送信号。如:退出信号。
- channel关闭之后,仍然可以从channel中读取剩余的数据,直到数据全部读取完成。
- 判断一个channel的方式有两种:
- 一种方式:value, ok := <- ch,ok是false,就表示已经关闭。
- 另一种方式for value := range ch {},如果channel被关闭,会跳出循环。,
package channel_try
import (
"fmt"
"testing"
)
func f1(ch chan<- int) {
for i := 0; i < 1000; i++ {
ch<-i
}
close(ch)
}
func f2(ch1 <-chan int ,ch2 chan<- int) {
for true {
tmp,ok := <-ch1
if !ok {
break
}
ch2<-tmp*tmp
}
close(ch2)
}
func TestName(t *testing.T) {
ch1 := make(chan int, 1000)
ch2 := make(chan int, 2000)
go f1(ch1)
go f2(ch1,ch2)
count := 0
for ret := range ch2 {
count++
fmt.Println(ret)
}
t.Log(count)
}
多路选择与超时
需要看看!!!
任务的取消
需要看看!!!
context与任务取消
Context
- 根 Context:通过context.Background()创建
- 子Context:context.WithCancel(parentContext)创建
- ctx,cancel:=context.WithCancel(context.Background())
- 当前Context被取消时,基于他的子context都会被取消
- 接收取消通知<-ctx.Done()
package channel_cancel
import (
"context"
"fmt"
"testing"
"time"
)
func isCanceled(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}
func TestCancel(t *testing.T) {
ctx, cancel := context.WithCancel(context.Background())
for i := 0; i < 5; i++ {
go func(i int, ctx context.Context) {
for {
if isCanceled(ctx) {
break
}
time.Sleep(time.Millisecond * 5)
}
fmt.Println(i,"Canceled")
}(i,ctx)
}
cancel()
time.Sleep(time.Second)
}
典型并发任务
只运行一次(单例模式)
package singleton
import (
"fmt"
"sync"
"testing"
)
var once sync.Once
var obj *SingletonObj
type SingletonObj struct {
name string
}
func TestSingle(t *testing.T) {
for i := 0; i < 10; i++ {
go func() {
obj = GetSingleton()
fmt.Println("try it")
}()
}
}
func GetSingleton() *SingletonObj {
once.Do(func() {
fmt.Println("Just Do it!")
obj = new(SingletonObj)
})
return obj
}
仅对第一个完成的任做回复
缺点:导致会有很多协程一直在阻塞,浪费资源 改进:使用带缓存区的channel,即:ch := make(chan string,10)
package severalTast
import (
"fmt"
"testing"
"time"
)
func TestName(t *testing.T) {
res := doIt()
fmt.Println(res)
}
func Task(i int) string {
time.Sleep(5 * time.Millisecond)
return fmt.Sprintf("The task is from %d",i)
}
func doIt() string {
ch := make(chan string)
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Println(i)
str := Task(i)
ch<-str
}(i)
}
return <-ch
}
所有任务完成
package allTaskFinished
import (
"fmt"
"testing"
"time"
)
func TestName(t *testing.T) {
res := doIt()
println(res)
}
func doIt() string {
numOfTask := 10
ch := make(chan string,numOfTask)
for i := 0; i < numOfTask; i++ {
go func(i int) {
fmt.Println(i)
str := Task(i)
ch<-str
}(i)
}
res := ""
for i := 0; i < numOfTask; i++ {
res += <-ch + "\n"
}
return res
}
func Task(i int) string {
time.Sleep(5 * time.Millisecond)
return fmt.Sprintf("The task is from %d",i)
}
对象池
- 使用buffered channel实现对象池
package ObjPool
import (
"github.com/pkg/errors"
"time"
)
type Obj struct {
}
type ObjPool struct {
buffChan chan *Obj
}
func NewPool(num int) *ObjPool {
pool := ObjPool{}
pool.buffChan = make(chan *Obj,num)
for i := 0; i < num; i++ {
pool.buffChan <- new(Obj)
}
return &pool
}
func (p *ObjPool)GetObj(timeout time.Duration) (*Obj,error) {
select {
case ret := <-p.buffChan:
return ret, nil
case <-time.After(timeout):
return nil,errors.New("time out")
}
}
func (p *ObjPool) ReleaseObj(obj *Obj) error {
select {
case p.buffChan <- obj:
return nil
default:
return errors.New("overflow!")
}
}
sync.pool对象缓存
sync.Pool 对象获取
- 尝试从私有对象获取
- 私有对象不存在,尝试从当前Processor的共享池获取
- 如果当前Processor共享池也是空的,那么就尝试去其他Processor的共享池获取
- 如果所有子池都是空的,最后就用用户指定的New函数产生一个新的对象返回
- 私有对象是协程安全的 共享池是协程不安全的
sync.Pool 对象的放回
- 如果私有对象不存在则保存为私有对象
- 如果私有对象存在,放入当前Processor子地的共享池中
sync.Pool对象的生命周期(不能当对象池用的原因)
- GC会清除sync.pool 缓存的对象
- 对象的缓存有效期为下一次GC之前
sync.Pool总结
- 适合于通过复用,降低复杂对象的创建和GC代价
- 协程安全,会有锁的开销
- 生命周期受GC影响,不适合于做连接池等,需自己管理生命周期的资源的池化
- 学习网址:www.cnblogs.com/sunsky303/p…
