

今天要介绍的是一个 Github 项目,项目地址如下,它实现了对线稿的自动上色功能,效果还是很不错的,一起来看看吧。
简介
本项目主要实现了自动将线稿转成彩色图片的功能。当然,我们可以只训练处理线稿的神经网络,但实际应用中我们需要提前用指定颜色给线稿上色的功能。实现上色的方法有很多,包括给定提示(hint)。
- 不带提示
- 没有提示的上色方法
- 输入:仅线稿
- Atari
- 带有提示的上色方法,提示一般是在特定区域所需颜色的线条(比如 PaintsChainer)
- 输入:线稿和 atari
- 标签
- 提示是标签的上色方法
- 输入:线稿和标签
- 参照物
- 采用参照图片作为提示的上色方法(比如 style2paints V1)
- 输入:线稿和参考图片
线提取方法
在线提取方法有很多改进版方法,比如 **XDoG **或者 SketchKeras。但是如果仅仅在一种类型的线稿上训练模型,模型会对这种类型的线稿过拟合,从而无法对其他类型的线稿实现自动上色功能。因此,和 Tag2Pix 一样,这里使用多种不同的线稿作为训练数据进行网络的训练。
使用的是下面三种类型的线:
- XDoG:使用两个高斯分布的差异到标准差进行线提取;
- SketchKeras:采用 UNet 进行线提取。通过这种方法提取得到的线会类似铅笔素描;
- Sketch简化版:通过全卷积网络继续线提取。这种方法得到的类似数字素描。
下面展示了上述三种方法的提取结果:

此外,我还考虑三种对于线稿的数据增强方法,防止出现过拟合。
- 增加强度;
- 随机形态学变换处理不同宽度的线条;
- 随机选择 RGB 数值来处理不同深度的线条;
不带提示的实验
动机
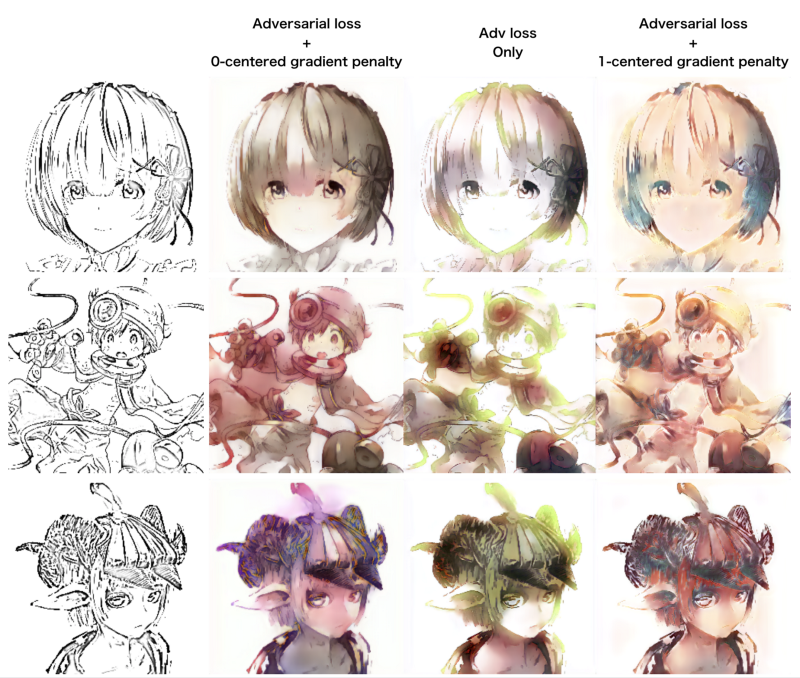
首先,我需要确认基于神经网络的方法可以在没有提示的情况下精确且多样化的进行上色。困难点主要是从线条到彩色图像的映射,因为颜色存在变化。因此,没有提示的情况下,我认为神经网络最终只学会在任意一个区域都只会上单一的一种颜色。为了避免陷入局部最小值,除了内容损失,我还加入了对抗损失,因为对抗学习训练神经网络进行上色可以更精确匹配数据的分布。
方法
- pix2pix
- pix2pix-gp(pix2pix 加上中心对称的梯度惩罚)
- pix2pixHD
结果
- pix2pix

- pix2pix-gp
- pix2pixHD

采用 atari 的实验
动机
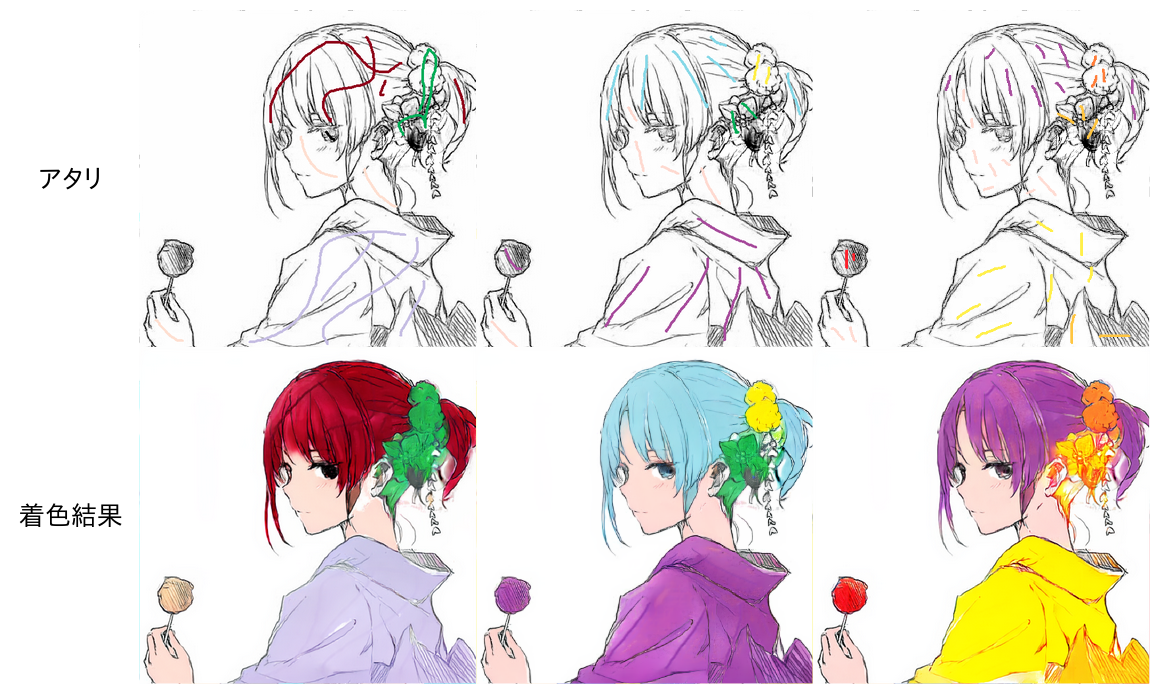
观察上述结果发现,即便加入了对抗损失,神经网络似乎还是陷入了局部最小值。虽然存在不同程度的颜色变化,但是神经网络还是只学会了在任意区域对单一字符上单一的颜色。没有提示的情况下很难训练将线条映射到彩色图片,因此,我决定加入提示,即 atari,一起作为网络的输入(ps. 如下图所示,就是在原来线稿基础上,对特定区域加上指定颜色的线条,提示网络这部分区域需要上的颜色)。
方法
加入了提示
结果
采用参考图片的实验
动机
我还考虑过用参考图片作为提示输入神经网络中。首先,我尝试实现了 style2paints V1. 但由于训练会出现崩塌的情况,我很难复现原始的实验结果。因此,我决定要寻找一个 style2paints V1 的替代方法。
方法
- style2paints
结果

视频上色实验
结果

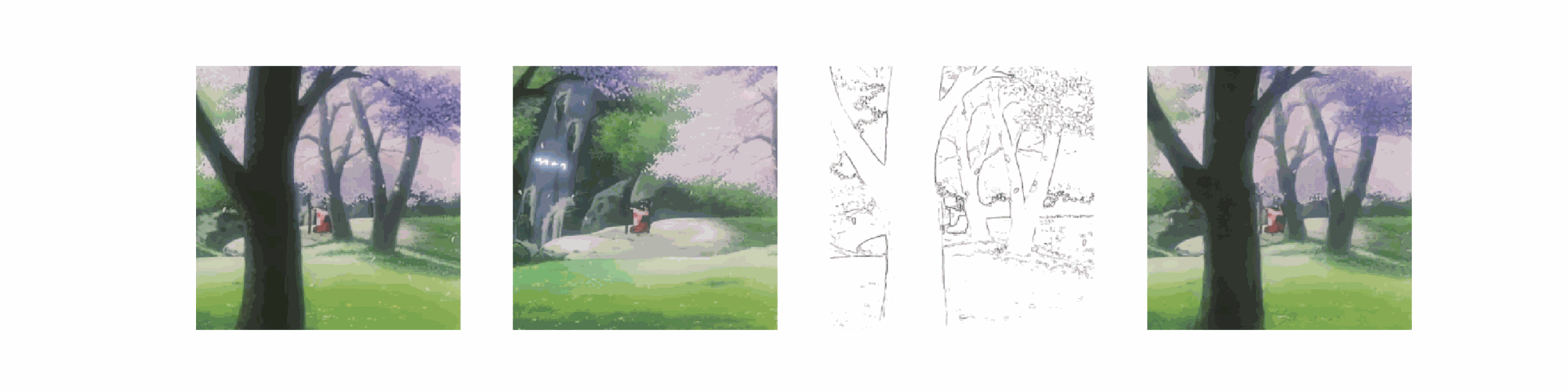

最后再次给出项目的地址:
欢迎关注我的公众号--算法猿的成长,一起交流学习。

