

Shutdown HTTP系列介绍
之前,有一位大佬和我说过这么一句话:"网络知识在一定程度上决定了你的上限"。
对HTTP一知半解的我,上限真的这么低吗...就不能花点时间好好整理整理吗 🤔️?
这次请给霖呆呆一个机会,跟着我的脚步👣从1开始学习它。另外我整理的HTTP系列基本都会附有一个面试时的浅答与深答的的配套答案,浅答是为了让你们更好的记住,深答保证你确实理解了浅答中的知识点。
整个系列下来,让我们彻底 Shutdown HTTP !!!💪
系列思维导图:
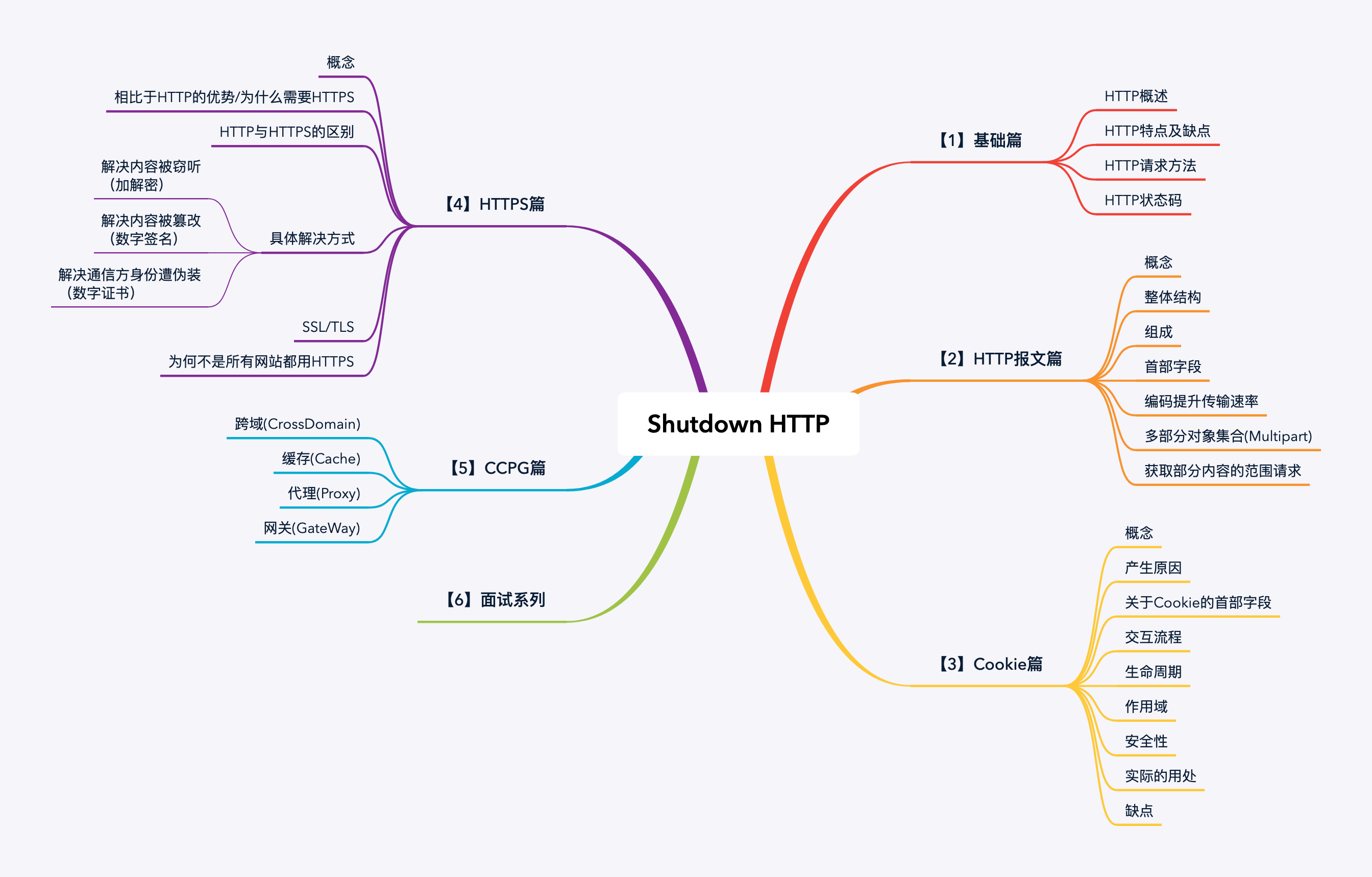
系列目录:
- 《🐲【1】Shutdown HTTP系列-基础篇》
- 《🐲【2】Shutdown HTTP系列-HTTP报文篇》「本文」
- 《🐲【3】Shutdown HTTP系列-Cookie篇》
- 《🐲【4】Shutdown HTTP系列-HTTPS篇》
- 《🐲【5】Shutdown HTTP系列-CCPG篇》
- 《🐲【6】Shutdown HTTP面试系列》
所有文章内容都已整理至 LinDaiDai/niubility-coding-js 快来给我Star呀😊~
本篇目录
通过阅读本篇文章你可以学习到:
- HTTP报文概念
- HTTP报文整体结构
- HTTP首部字段
- 编码提升传输速率
- 多部分对象集合
- 获取部分内容的范围请求
1. HTTP报文概念
概念:是HTTP通信中的基本单位,由8位组字节流组成。
2. HTTP报文整体结构
整体结构:报文首部 + 空行 + 报文实体
有些地方会写为(这样也可以):起始行 + 首部字段 + 空行 + 报文实体
(首部也就是头部)
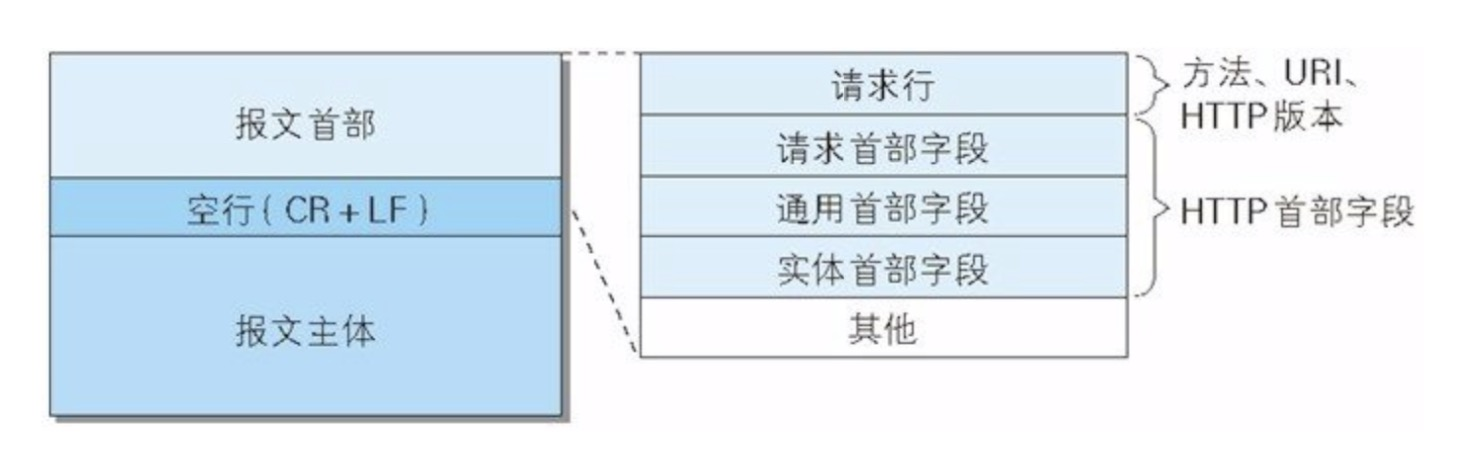
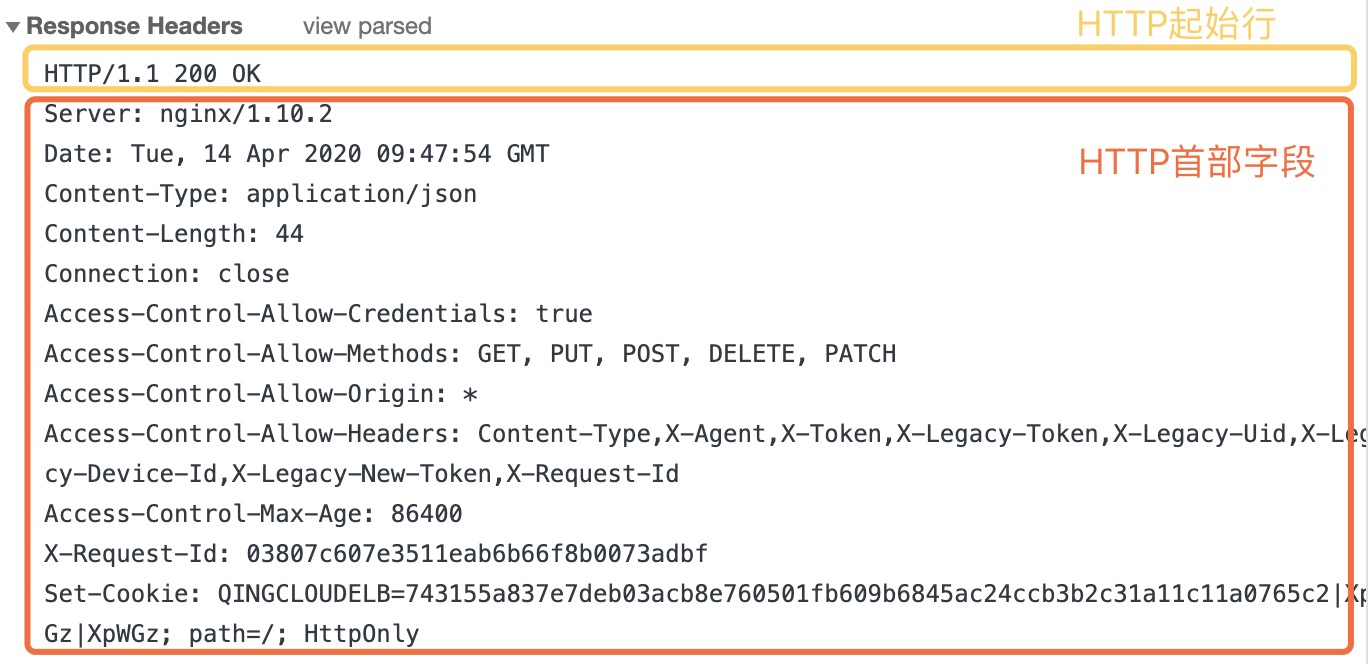
另外对于「请求报文」和「响应报文」,它们主要是报文首部不同:
「请求报文:」
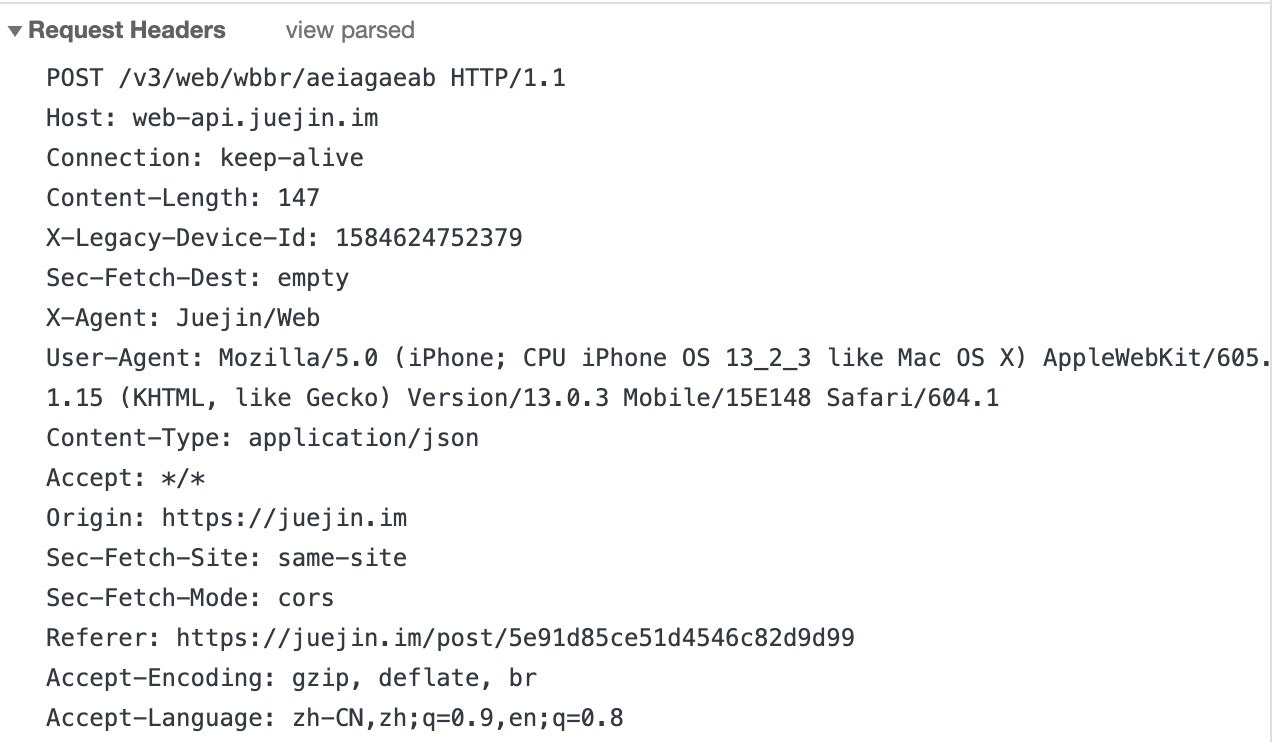
真实例子:
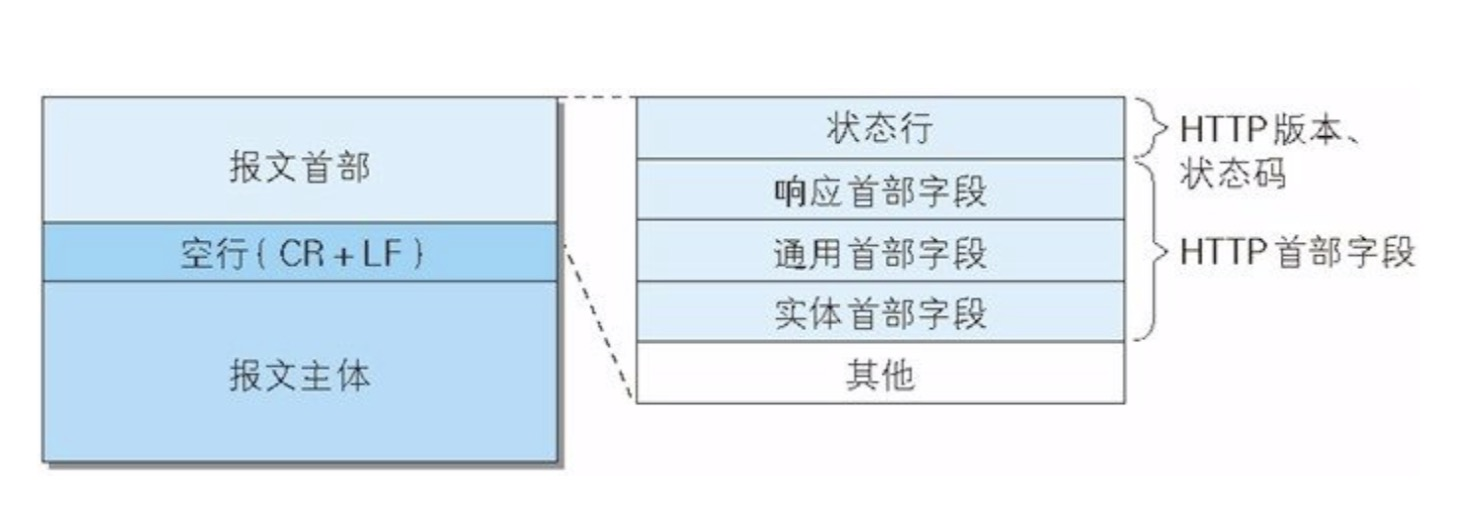
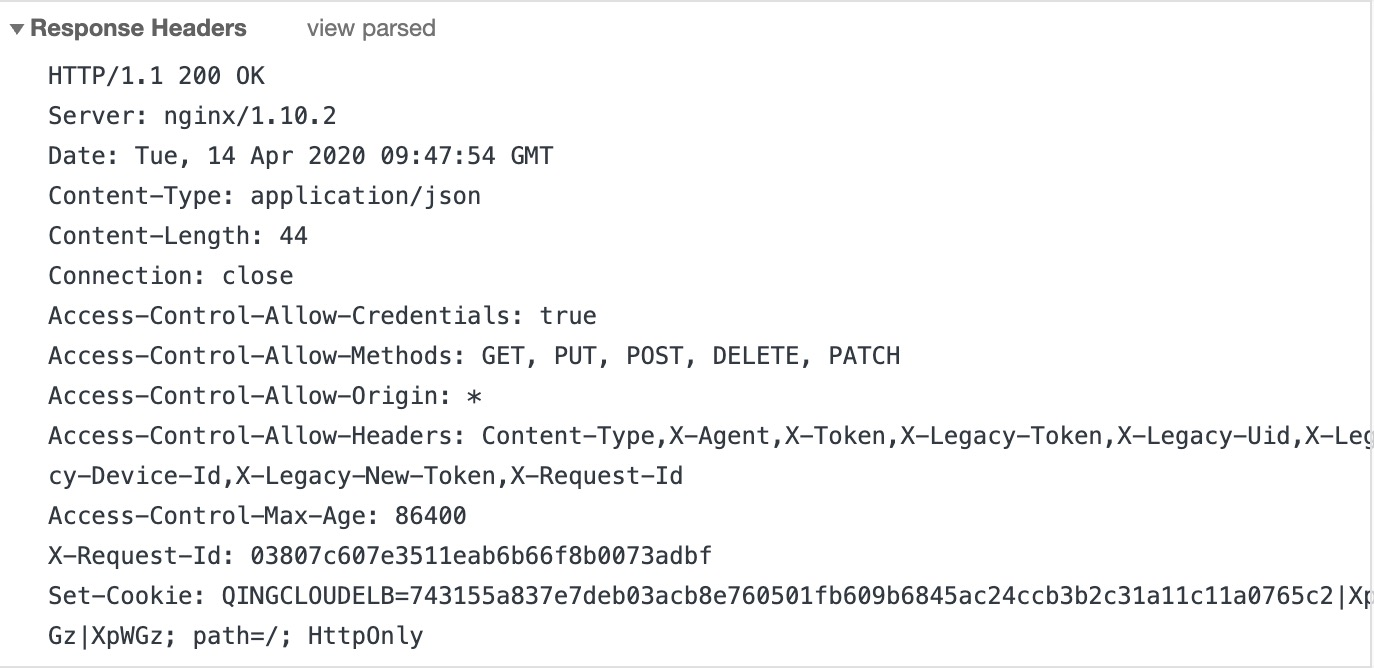
「响应报文:」
真实例子:
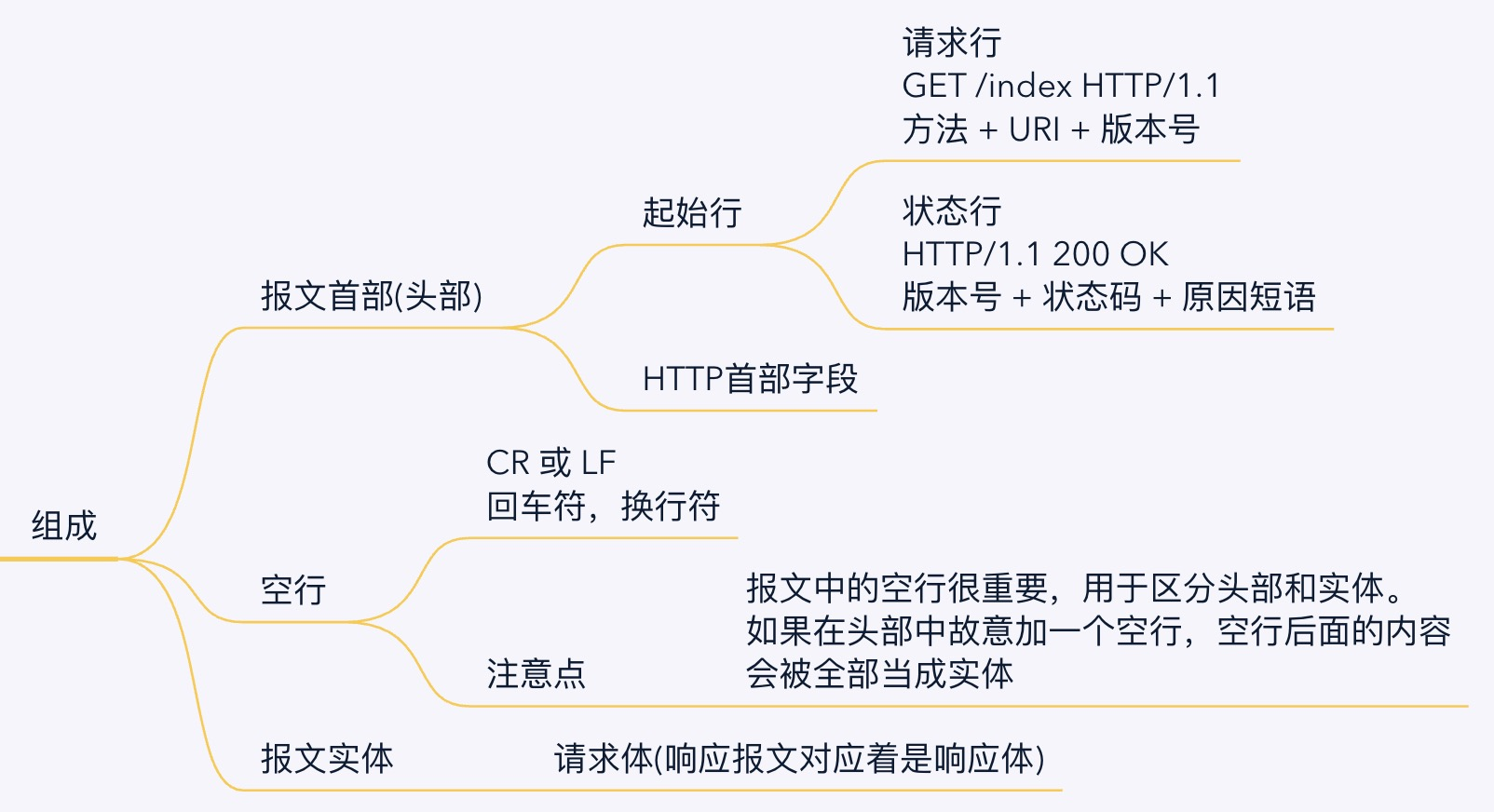
3. HTTP报文组成
上面👆介绍了一下HTTP报文的整体结构,这里主要是做一下细分。
HTTP报文的整体是:报文首部 + 空行 + 报文实体
不过因为:报文首部 = 起始行 + 首部字段,其实起始行也挺重要的,所以我就分为两部分说了。
大家记住这张图就可以了:
3.1 起始行
请求报文中叫:「请求行」
由:方法 + URI + 版本号 组成
例:GET index.html HTTP/1.1
真实例子可以看上面👆HTTP整体报文那张图。
响应报文中叫:「状态行」
由:版本号 + 状态码 + 原因短语
例:HTTP/1.1 200 OK
(这个原因短语就是之前学习「HTTP状态码」每个状态码对应的英文单词,比如404 Not Found)
3.2 首部字段
在第四节中细讲。
3.3 空行
空行:也就是CR(回车符) 或 LF(换行符),它的作用就是用来「区分头部和实体」。
例如下面这个实例:
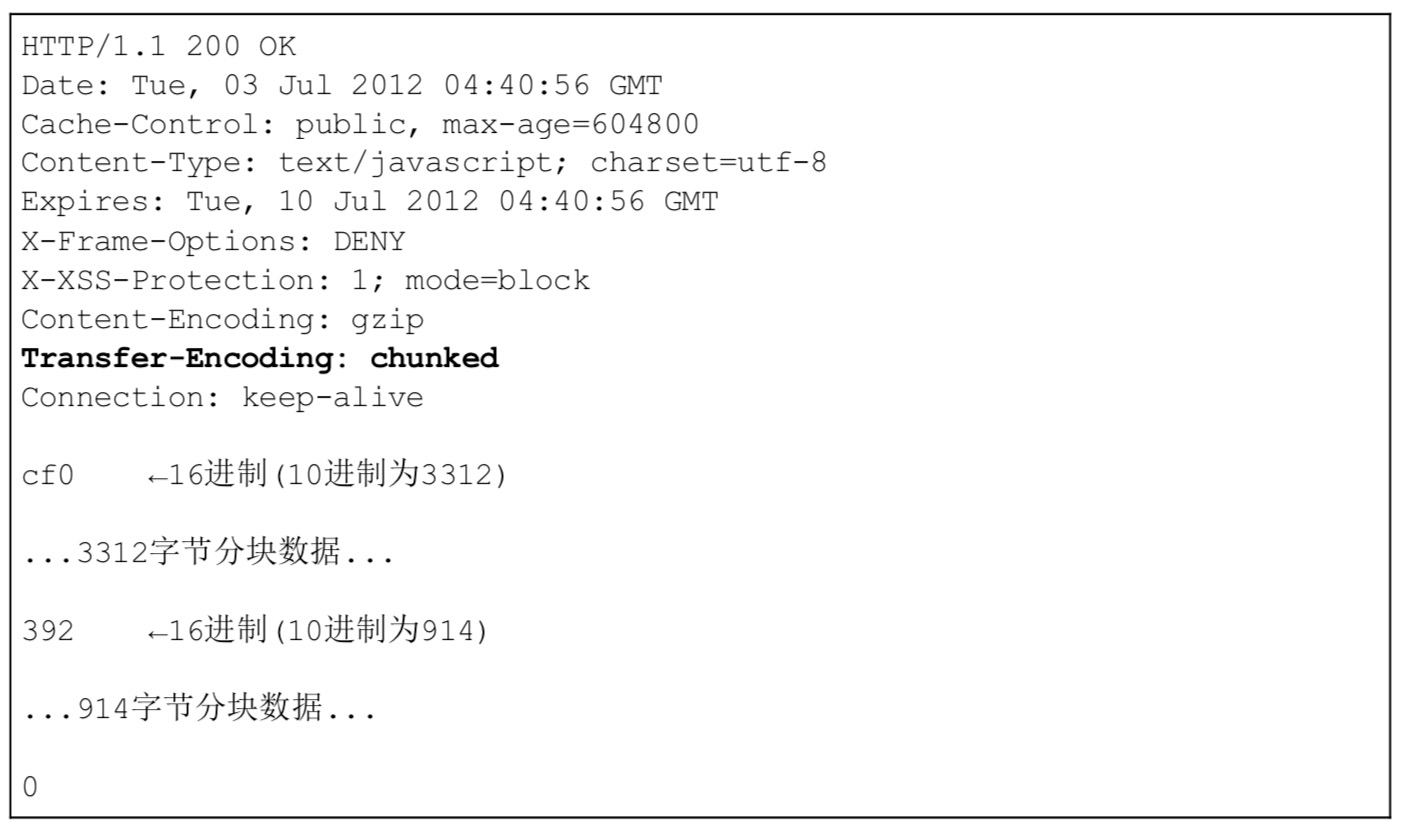
在Connection: keep-alive下面就有一个换行符。
「注意点:」
如果在头部中故意加一个空行,空行后面的内容会被全部当成实体
3.4 报文实体
报文实体也就是具体请求和响应的数据了,就是我们俗说的body。
请求报文中叫:「请求体」
响应报文中叫:「响应体」
4. HTTP首部字段
(HTTP报文中最繁琐的就是首部字段了,也就是我们经常在network上看到的那么一大串的配置)
HTTP首部字段我会从这几个方面来讲解:
- HTTP首部字段结构
- 四种HTTP首部字段类型
- 非标准的首部字段
- Accept相关字段
4.1 HTTP首部字段结构
- 首先基本结构是:
由:key: value
例子:Content-Type: text/html
- 多个字段值用
,号连接:
由:key: value1, value2
例:Keep-Alive: timeout=15, max=100
- 若是字段值有可选参数且是多个则用
;号连接:
由:key: value1, q=1;value2, q=0.8
例:Accept: text/html, q=1; application/xml, q=0.8
- 若是首部字段重复不同的浏览器有不同的处理结果,有些浏览器会优先处理第一次出现的首部字段,而有些则先处理最后出现的首部字段
4.2 四种HTTP首部字段类型
首部字段从类型上来说,有四种:
- 通用首部字段(General Header Fields):请求和响应报文都会用的字段
- 请求首部字段(Request Header Fields):请求报文时用的字段
- 响应首部字段(Response Header Fields):响应报文时用的字段
- 实体首部字段(Entity Header Fields):请求和响应报文的实体部分用的字段
而每一种类型下面又有很多字段,可能一下要记这么多也比较难,所以面试时能尽量把自己知道的说出来就可以了,让面试官知道对于一些重要的字段你还是有了解的。
以下我列举了一些,不过标了星号的可是重点哦。
通用首部字段
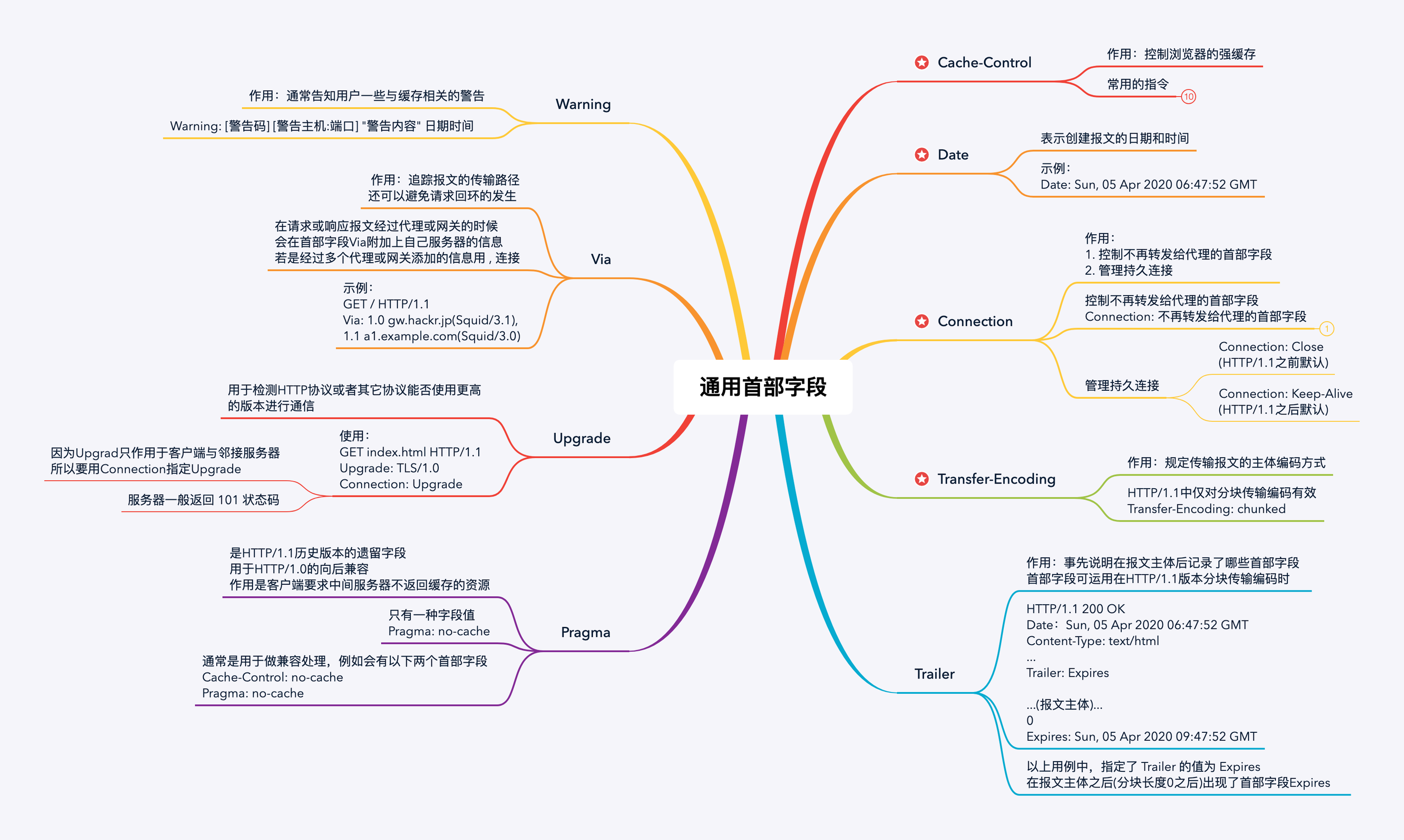
这边有一个需要注意的点:
Connection首部字段有一个值是keep-alive,表示开启持久连接。
而其实还有一个首部字段也叫Keep-Alive,允许消息发送者暗示连接的状态,还可以用来设置超时时长和最大请求数。
对于这个Keep-Alive首部字段,有两个参数:
timeout:指定了一个空闲连接需要保持打开状态的最小时长(以秒为单位)。需要注意的是,如果没有在传输层设置 keep-alive TCP message 的话,大于 TCP 层面的超时设置会被忽略。max:在连接关闭之前,在此连接可以发送的请求的最大值。在非管道连接中,除了 0 以外,这个值是被忽略的,因为需要在紧跟着的响应中发送新一次的请求。HTTP 管道连接则可以用它来限制管道的使用。
案例🌰:
HTTP/1.1 200 OK Connection: Keep-Alive Content-Encoding: gzip Content-Type: text/html; charset=utf-8 Date: Thu, 11 Aug 2016 15:23:13 GMT Keep-Alive: timeout=5, max=1000 Last-Modified: Mon, 25 Jul 2016 04:32:39 GMT Server: Apache
(body)
需要将 The Connection 首部的值设置为 "keep-alive" 这个首部才有意义。同时需要注意的是,在HTTP/2 协议中, Connection 和 Keep-Alive 是被忽略的;在其中采用其他机制来进行连接管理。
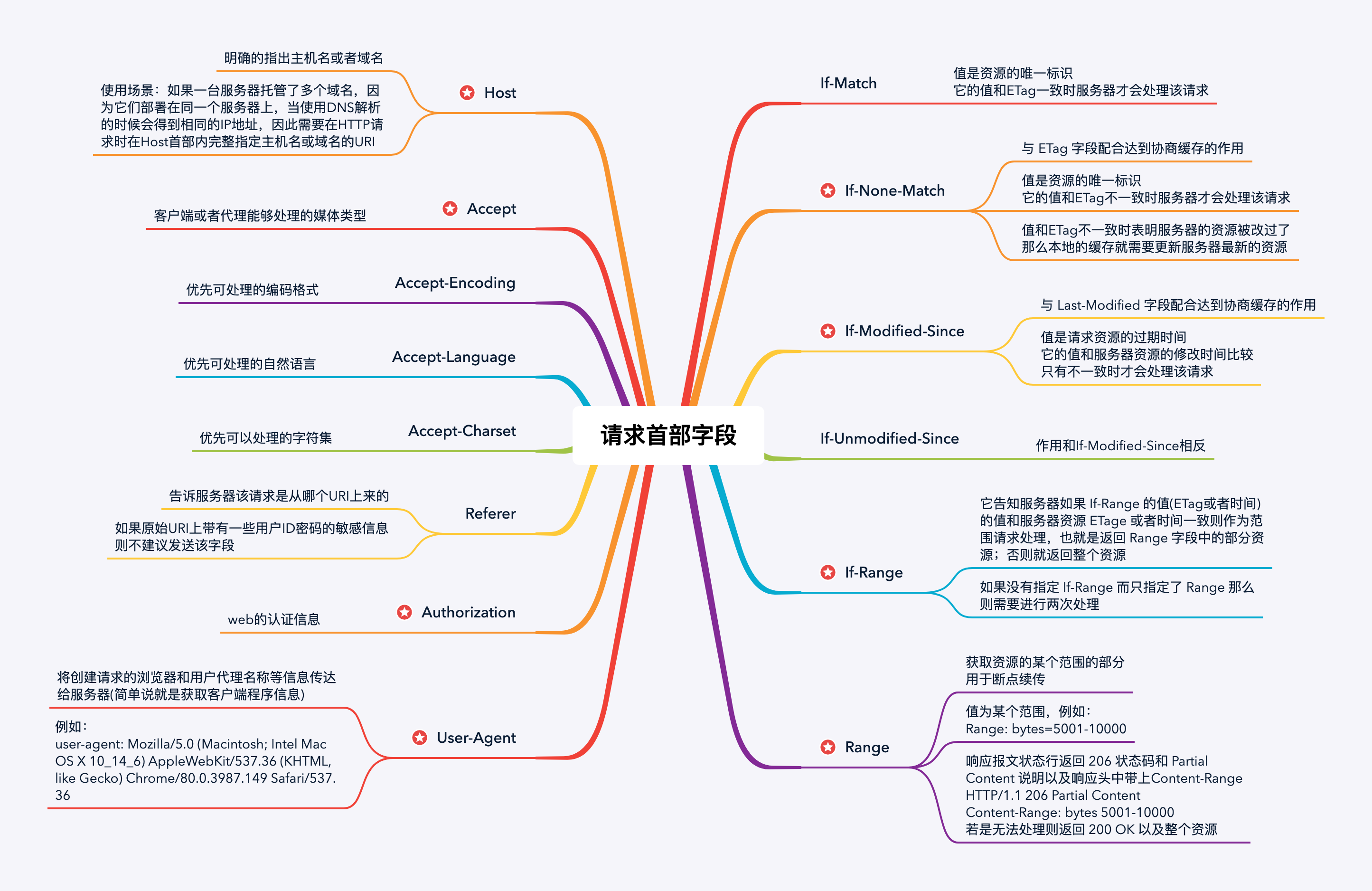
请求首部字段
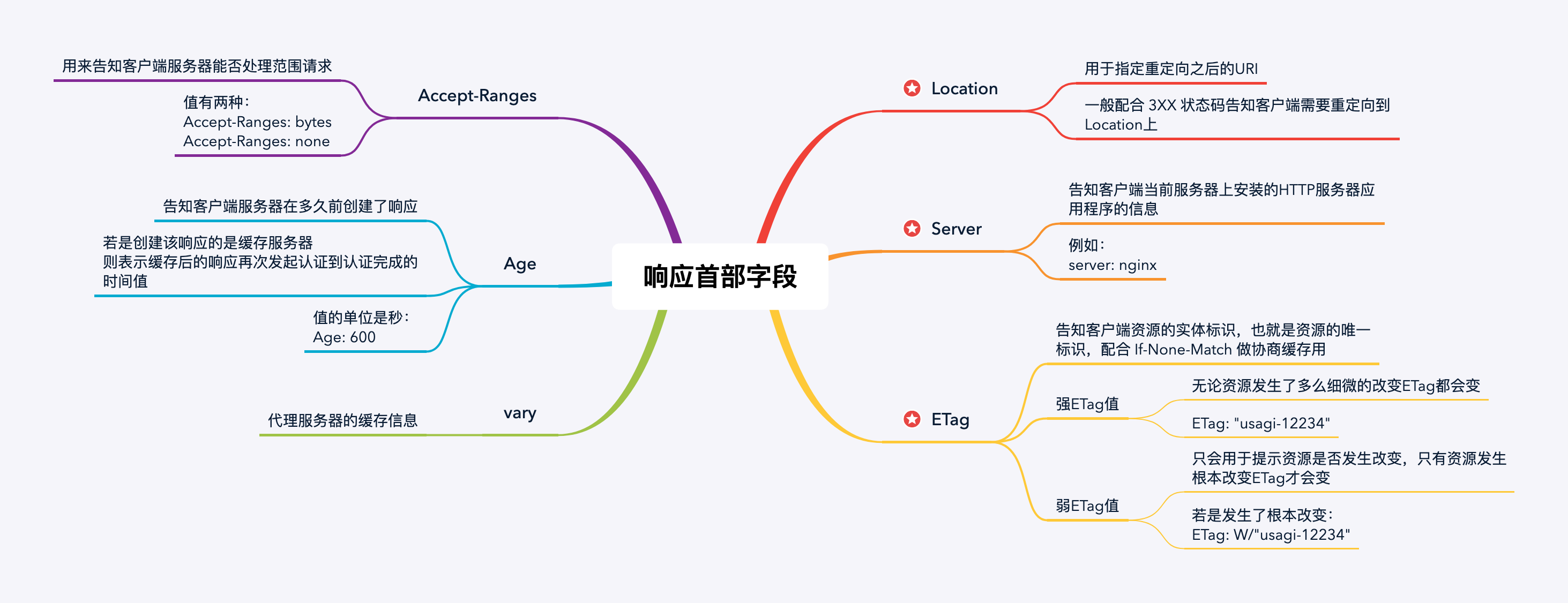
响应首部字段
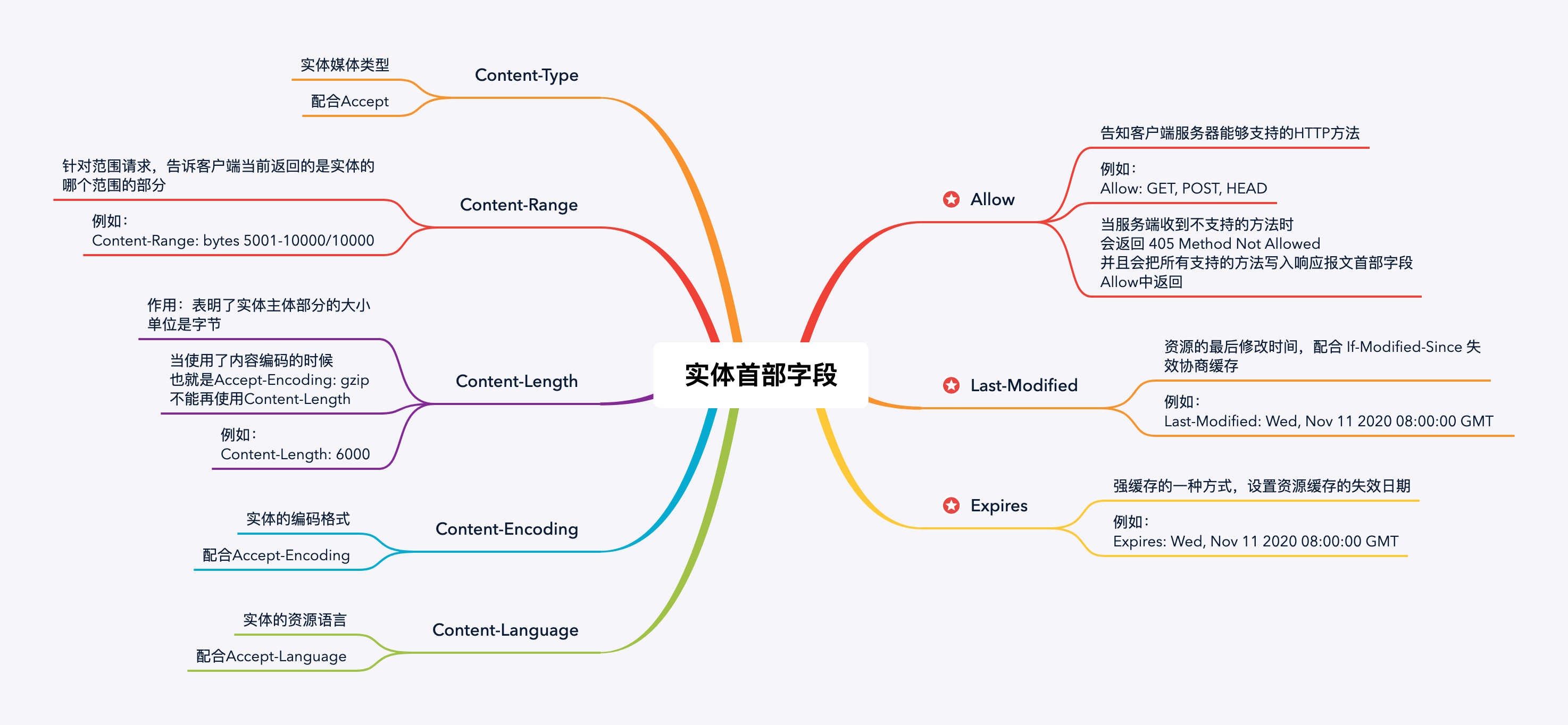
实体首部字段
4.3 非标准的首部字段
因为HTTP首部字段是可以自行扩展的,所以在Web服务器和浏览器的应用上,出现了一些非标准的首部字段。
有这么一些:
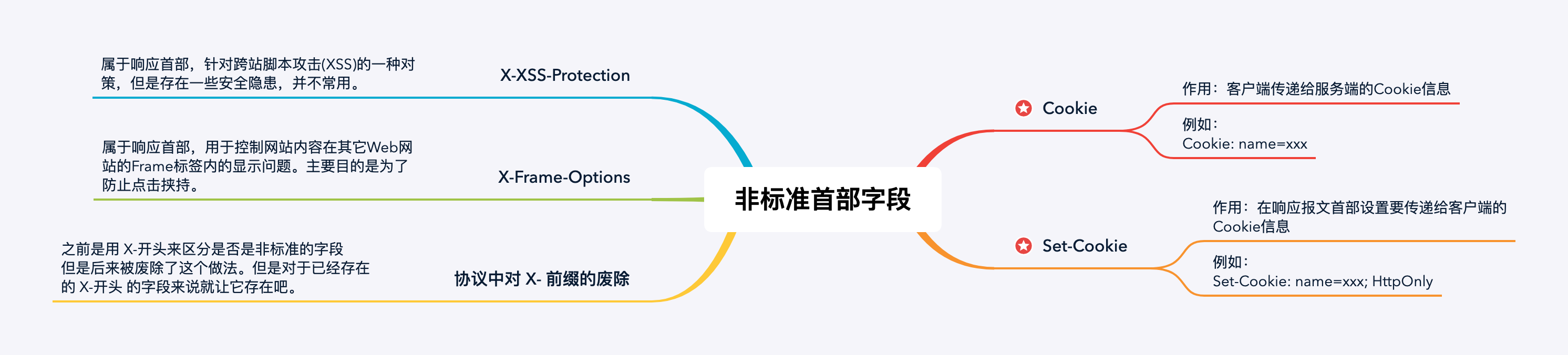
另外关于Cookie这块内容也还是挺多的,所以我也会单独放在第三章来进行讲解。
4.4 Accept相关字段
还有一个比较重要的点就是几种Accept相关的首部字段。
权重
当有多个字段值的时候,可以指定字段 q 来作为权重,权重范围 0~1。
例如:
Accept: text/html, q=1; application/xml, q=0.8
五种类别
(图中的序号并无优先级的意思,只是单纯的作为标记)
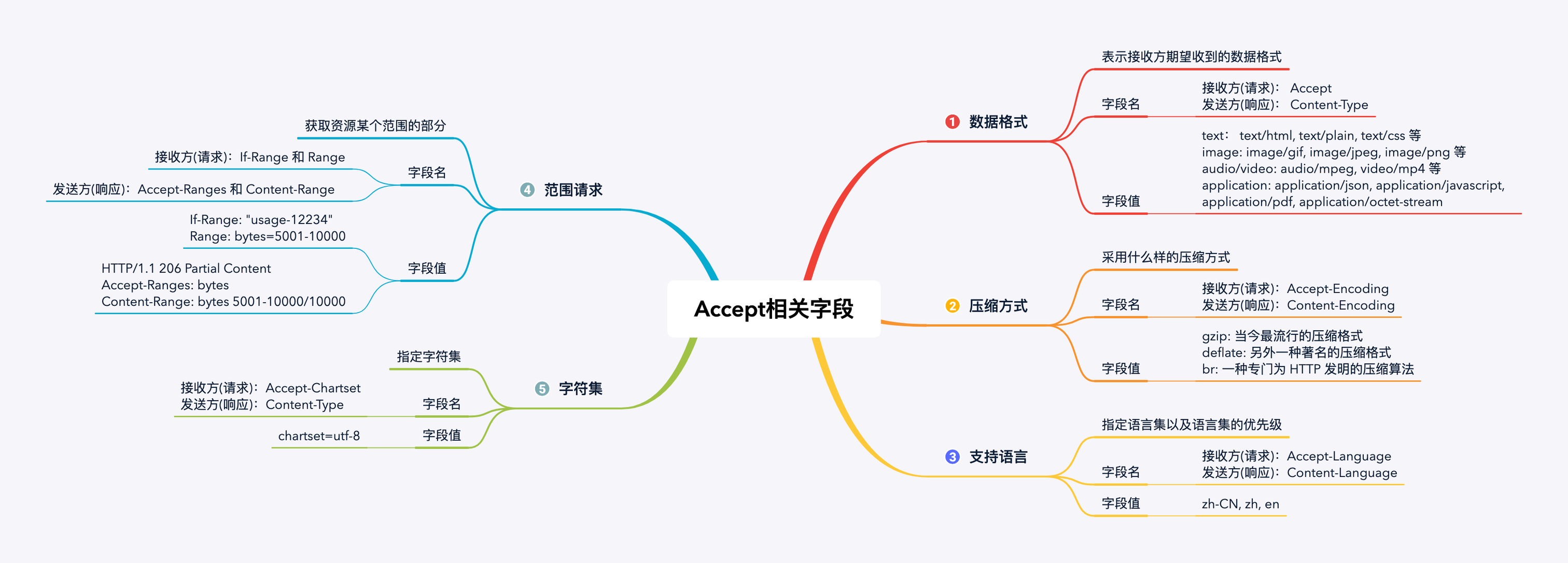
需要注意的是:
If-Range 和 Range以及 Accept-Ranges 和 Content-Range
这四个字段只有Accept-Ranges是有s的。
5. 编码提升传输速率
对于「编码提升传输速率」,我主要是将它分为了两部分讲解:
- 内容编码
- 传输编码
首先说下两者的区别吧:
内容编码通常用于对实体内容进行压缩编码,目的是优化传输,例如用 gzip 压缩文本文件,能大幅减小体积。且它通常是有选择性的,例如jpg、png这类文件一般不开启,因为图片格式已经是高度压缩过的,再压一遍没什么效果不说还浪费 CPU。传输编码则是用来改变报文格式,通常在头部加入Transfer-Encoding: chunked,实现分块编码。
相同点:
- 都是作用在实体主体上的可逆变换。这句话的意思是说:例如服务器使用了
gzip压缩了原始的响应体然后发送给浏览器,浏览器在得到之后可以对这个被压缩的响应体进行解码得到原始内容。
5.1 内容编码
内容编码介绍
内容编码表示HTTP应用程序有时在发送请求之前需要对内容进行编码,例如我们常听见的通过「Content-Encoding」来指定内容的压缩方式,通过「Content-Length」来指定文件大小。
内容编码的具体过程主要是:
- 服务器生成原始响应报文,其中有原始的
Content-Type和Content-Length首部字段 - 接着将原始的响应报文经过
内容编码服务器创建编码后的报文。这个编码后的报文同样有Content-Type和Content-Length两个字段,只不过Content-Length是有可能变的,例如主体经过了压缩,那么它的值肯定就变小了。 - 除了上述两个字段,还会在编码后的报文中增加
Content-Encoding首部,这样收到的应用程序就可以进行解码了。 - 接收程序收到编码后的报文再进行解码,获得原始报文。
(具体过程可以看后面的HTTP压缩的具体过程,与此情况大同小异)
内容编码类型
HTTP定义了一些标准的内容编码类型,主要是由Content-Encoding和Accept-Encoding首部字段来进行控制。
内容编码类型的不同,实际上是使用了不同的算法,例如gzip算法、deflate算法。而标示需要使用哪种算法来进行内容编码,则需要用到内容编码代号,也就是Content-Encoding的值,例如:
Content-Encoding: gzip
主要是有这么几种内容编码代号:
- gzip:实体采用GUN zip 编码
- compress:实体采用Unix的文件压缩程序
- deflate:实体使用zlib的格式压缩
- identity:不对实体进行编码。当没有
Content-Encoding首部的时候,就默认这种情况
补充:
- br:实体采用Brotli算法编码
注意⚠️:
Content-Encoding是在响应报文中定义的首部,用于告诉浏览器我采用了哪种编码方式,你得按这种编码方式来进行解析。Accept-Encoding是在请求报文中定义的首部,用于告诉服务器我支持哪些编码方式,你可以按这些编码方式来进行编码然后传输给我。另外,如果HTTP请求中没有
Accept-Encoding首部的话,服务器就会假设客户端能够接受任何编码方式,也就是等价于Accept-Encoding: *这种情况。gzip压缩方式使用最为广泛,而brotli是一种比Gzip压缩率更高的算法,编码代号为br。在兼容性上br已经支持了大部分的浏览器,不过br压缩只能在HTTPS中生效,因为在HTTP请求中request header里的Accept-Encoding是没有br这个选项的。
内容编码与HTTP压缩
HTTP压缩,在HTTP协议中,其实是内容编码的一种。
因为内容编码的类型会有很多种,而使用一些特定编码类型,例如gzip,就能实现对内容(body)进行压缩,
这样可以有助于减少传输实体的时间。
也可以使用其他的编码把内容搅乱或加密,以此来防止未授权的第三方看到文档的内容。
所以我们说HTTP压缩,其实就是HTTP内容编码的一种。
HTTP压缩的具体过程
HTTP压缩是指: Web服务器和浏览器之间压缩传输的文本内容的方法。
HTTP采用通用的压缩算法,比如gzip来压缩html,javascript, CSS文件。 能大大减少网络传输的数据量,提高了用户显示网页的速度。
既然HTTP压缩是内容编码的一种,那么它的压缩过程其实也就是遵循了内容编码的过程。
在此,我们以Accept-Encoding: gzip为例,也就是gzip压缩:
- 浏览器发送HTTP请求给服务器,并且请求报文中带有
Accept-Encoding: gzip首部字段(告诉服务器,浏览器支持gzip压缩) - 服务器在接受到请求之后,首先生成原始的响应,其中原始的响应中有:
Content-Type和Content-Length - 接着通过
gzip内容编码器进行编码,编码后请求的header中有Content-Type和Content-Length,还新增了Content-Encoding: gzip,并且把此请求发送给浏览器 - 浏览器在接受到请求后,根据
Content-Encoding: gzip来对请求进行解码,这里应该也有一个gzip内容解码器,然后得到原始的响应。
让我们来看张图:
可以看到,在这里原始响应虽然被压缩过了,但是后面还是能经过解码器转为原始内容,所以这就是前面提到的可逆变换。
gzip的相关知识点
gzip, compress, 以及deflate编码都是无损压缩算法,用于减少传输报文的大小,不会导致信息损失。 其中gzip通常效率最高, 使用最为广泛。
「压缩的好处」
HTTP压缩对纯文本可以压缩至原内容的40%, 从而节省了60%的数据传输。
「gzip的缺点」
- 内容编码和内容的具体格式细节紧密相关,使用
gzip压缩文本文件非常合适,但png、gif、jpg、jpeg这类图片文件并不推荐使用gzip压缩(svg是个例外),首先经过压缩后的图片文件gzip能压缩的空间很小。事实上,添加标头,压缩字典,并校验响应体可能会让它更大。 - 压缩本身是需要耗费时间,我们可以理解为我们是以服务器压缩的时间开销和CPU开销为代价,省下了一些传输过程中的时间开销。
(来源:前端性能优化gzip初探(补充gzip压缩使用算法brotli压缩的相关介绍))
「gzip是如何压缩的」
简单来说, gzip压缩是在一个文本文件中找出类似的字符串, 并临时替换他们,使整个文件变小。这种形式的压缩对Web来说非常适合, 因为HTML和CSS文件通常包含大量的重复的字符串,例如空格,标签。
「Request可以压缩吗?」
浏览器是不会对Request压缩的。 但是一些HTTP程序在发送Request时,会对其进行编码。
5.2 传输编码
产生原因
在非长连接的情况下浏览器可以通过连接是否关闭来界定请求或者响应的边界;而对于建立了长连接的情况,也就是设置了Connection: keep-alive这个头部,浏览器没法判断这次的数据是否传输完了,这时候就得计算「实体的长度」,并通过头部告诉浏览器,也就是使用Content-Length这个首部字段。
Content-Length如果比实际的长度短,就会造成内容被截断,甚至会影响下一次的请求;如果比实际的长度长,则会造成pending,这个请求一直在等待中直到超时。(但是在HTTP/1.0中由于长连接并未被标准化,所以这个字段可有可无)
因此Content-Length的计算显得尤为重要,它必须真实的反应实体长度。但又由于很多时候实体长度并没有那么容易获得,例如实体来自于网络文件,或者由动态语言生成。而这时候如果需要等待Content-Length的计算的话,无疑会影响到TTFB(Time To First Byte),也就是从客户端发出请求到收到响应的第一个字节所花费的时间。越短的TTFB则能让用户更早的看到页面内容,体验越好。
所以这就是Transfer-Encoding产生的原因,它解决了:不依赖头部的长度信息,也能知道实体的边界。
Transfer-Encoding: chunked
是不是感觉上面那句话不好理解呢?
呆呆这里来举个例子🌰。
「没有Transfer-Encoding:」
没有Transfer-Encoding的时候,服务器在传输给浏览器数据的时候可能是这样的:
require('net').createServer(function(sock) {
sock.on('data', function(data) {
sock.write('HTTP/1.1 200 OK\r\n');
sock.write('Content-Length: 9\r\n');
sock.write('\r\n');
sock.write('lindaidai');
});
}).listen(8080, '127.0.0.1');
浏览器接收到数据之后就能通过Content-Length与实体长度做一个比对,判定数据是否传输完成。
但这样在传输大量数据的时候,复杂的计算Content-Length就可能会影响前面提到的TTFB。
「设置Transfer-Encoding: chunked:」
设置了此首部之后,表明这是一次分块传输,可以将报文实体改为用一系列分块来传输:
require('net').createServer(function(sock) {
sock.on('data', function(data) {
sock.write('HTTP/1.1 200 OK\r\n');
sock.write('Transfer-Encoding: chunked\r\n');
sock.write('\r\n');
sock.write('a\r\n');
sock.write('0123456789\r\n');
sock.write('6\r\n');
sock.write('daidai\r\n');
sock.write('0\r\n');
sock.write('\r\n');
});
}).listen(8080, '127.0.0.1');
这次的传输有以下几个特点:
- 每个分块会有两部分内容:十六进制的长度和数据(例如
a\r\n表示的就是长度为10,因为a是十六进制中的10;后面的0123456789就表示数据) - 长度值独占一行,长度不包括它结尾的
CRLF(\r\n),也不包括分块数据结尾的CRLF。 - 最后一个分块的长度值必须是
0,且对应分块数据没有内容,它表示的是实体结束。
网上有张图呆呆觉得特别好,借用一下,哈哈😄:
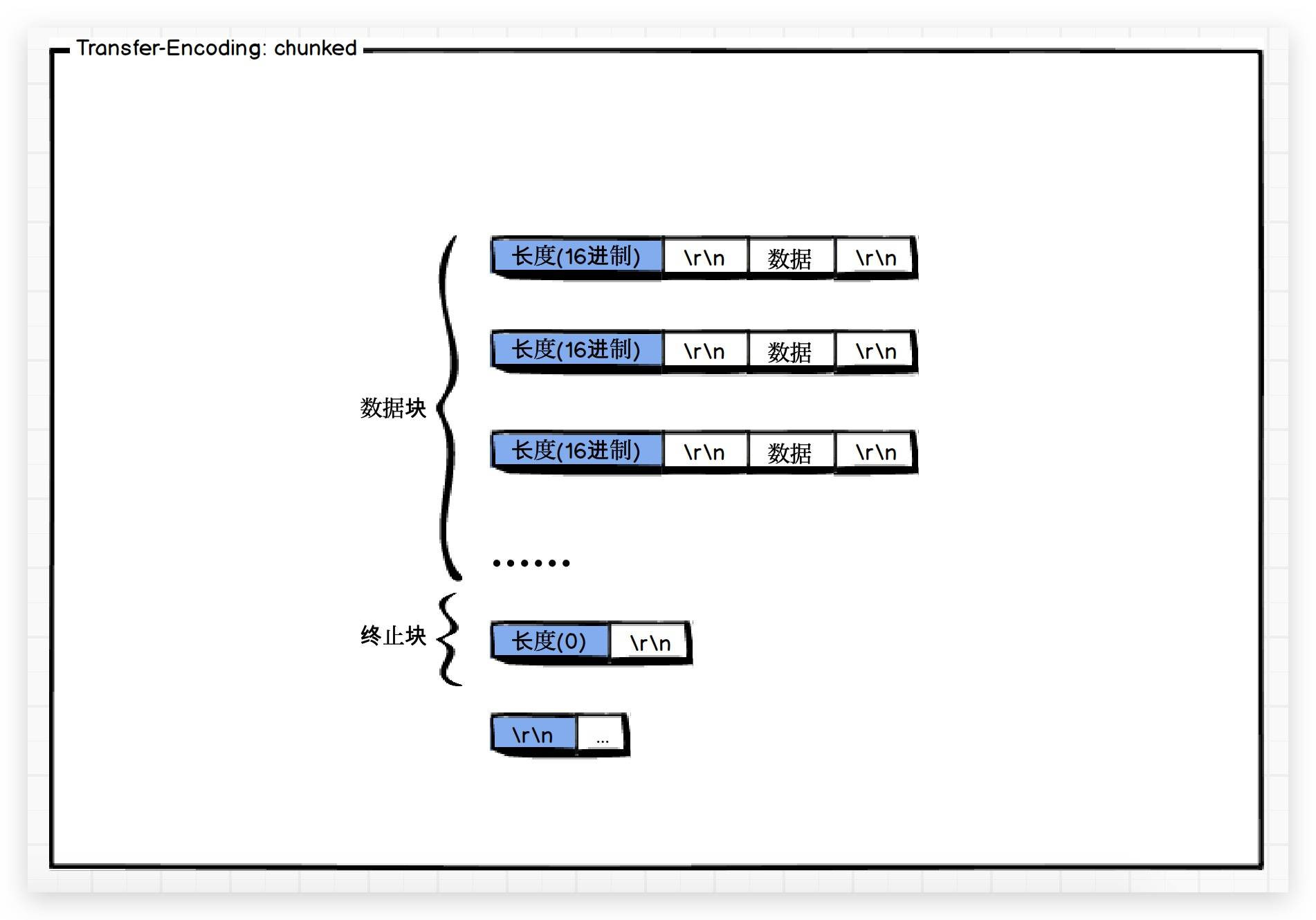
(图片来源:用了这么久HTTP, 你是否了解Content-Length和Transfer-Encoding ?)
可以看到,通过设置Transfer-Encoding: chunked,这种简单的分块策略就能解决前面提到的那个问题。
「使用场景」:
所以在使用场景上,我认为主要有:
- 传输大量数据的时候
- 配合
压缩编码来进行传输(5.4里会提到)
5.3 Transfer-Encoding的取值
历史上 Transfer-Encoding 可以有多种取值,为此还引入了一个名为 TE 的头部用来协商采用何种传输编码。但是最新的HTTP规范里,只定义了一种传输编码:分块编码(chunked)。
5.4 Transfer-Encoding结合Content-Encoding
通过前面的介绍,我们知道了:
Transfer-Encoding: chunked表明分块传输Content-Encoding: gzip表明使用gzip压缩传输
二者经常会结合来用,其实就是针对进行了内容编码(压缩)的内容再进行传输编码(分块)。
例如如下:
GET /index.html HTTP/1.1 Host: lindaidai.com Accept-Encoding: gzipHTTP/1.1 200 OK Server: nginx/1.10.2 Date: Mon, 25 May 2020 07:36:22 GMT Content-Type: text/html Transfer-Encoding: chunked Connection: keep-alive Content-Encoding: gzip
dsf �H���W(�/�I�J
0
6. 多部分对象集合(Multipart)
HTTP协议中采纳了多部分对象集合(Multipart),发送的一份报文主体内可含有多类型实体。通常是在图片或文本文件等上传时使用。
多部分对象集合包含的对象如下:
multipart/form-data:在Web表单文件上传时使用。
multipart/byteranges:状态码206(Partial Content, 部分内容)响应报文包含了多个范围的内容时使用。
例如:
Content-Type: multipart/form-data; boundary=AaB03x--AaB03x Content-Disposition: form-data; name="field1"
--AaB03x Content-Disposition: form-data; name="pics"; filename="file1.txt" Content-Type: text/plain
...(file1.txt的数据)... --AaB03x--
注意⚠️:
- 在HTTP报文中使用多部分对象集合时,需要在首部字段里加上
Content-Type。 - 使用
boundary字符串来划分多部分对象集合指明的各类实体。 - 在boundary字符串指定的各个实体的起始行之前插入
"--"标记,而在多部分对象集合对应的字符串的最后插入"–"标记作为结束。
7. 获取部分内容的范围请求
「概念:」
可以指定下载实体范围,也就是说在一次请求内可以不加载整个的实体,而是只加载实体中的一部分。
「如何实现?」
例如有一个10000字节的实体,可以只请求5001 ~ 10000字节内的资源。
请求报文首部字段
Range来指定byte范围If-Range: 'userage-12234' Range: bytes=5001-10000响应报文使用
Content-Range告诉客户端此次的请求范围:HTTP/1.1 206 Partial Content Accept-Ranges: bytes Content-Range: bytes 5001-10000/10000若是无法处理的话,则返回
200 OK以及整个资源。
需要注意的点⚠️:
一般要配合
If-Range来用,它告知服务器如果If-Range的值(ETag或者最后修改时间)的值和服务器资源ETage或者时间一致则作为范围请求处理,也就是返回Range字段中的部分资源;否则就返回整个资源。If-Range和Range以及Accept-Ranges和Content-Range这四个字段只有
Accept-Ranges是有s的。
「案例🌰」:
可以来一个案例看看:
请求:
<!-- 请求 --> GET /me.jpg HTTP/1.1 Host: lindaidai.com Range: bytes=5001-10000
<!-- 响应 --> HTTP/1.1 206 Partial Content Data: Mon, 25 May 2020 12:56:52 GMT Content-Range: bytes 5001-10000/10000 Content-Length: 5000 Content-Type: image/jpeg
参考文章
知识无价,支持原创。
参考文章:
- 前端性能优化gzip初探(补充gzip压缩使用算法brotli压缩的相关介绍)
- 图解HTTP:发送多种数据的多部分对象集合
- 用了这么久HTTP, 你是否了解Content-Length和Transfer-Encoding ?
- HTTP 协议中的 Transfer-Encoding
- 《图解HTTP》
- 《HTTP权威指南》
后语
你盼世界,我盼望你无bug。这篇文章就介绍到这里。
这个系列文章的最后我都会送给大家一段情话来表达我对大家的感谢:
"这是一个普通的我写的普通的文章"
"拥有一颗上进拼搏的心"
"在这个网络中,有看不完的文章,背不完的面经"
"感谢您遇见本篇文章的时候,片刻的停留"
"如内容不满意,我诚心向您道歉"
"麻烦您先不要开喷,请及时联系我"
"我一定改到您满意为止"
"原创不易,如果可以的话"
"麻烦您能给个赞或者转发"
🌟🌟🌟🌟🌟
"祝您安好~~谢谢~~"
喜欢「霖呆呆」的小伙还希望可以关注霖呆呆的公众号 LinDaiDai 或者扫一扫下面的二维码👇👇👇.

我会不定时的更新一些前端方面的知识内容以及自己的原创文章🎉
你的鼓励就是我持续创作的主要动力 😊.
相关推荐:
《【建议星星】要就来45道Promise面试题一次爽到底(1.1w字用心整理)》
《【建议👍】再来40道this面试题酸爽继续(1.2w字用手整理)》
《【何不三连】比继承家业还要简单的JS继承题-封装篇(牛刀小试)》
《【何不三连】做完这48道题彻底弄懂JS继承(1.7w字含辛整理-返璞归真)》
《霖呆呆的近期面试128题汇总(含超详细答案) | 掘金技术征文》
本文使用 mdnice 排版
