

最近在和 PD 聊 A/B 功能集成时,业务方提了这么个问题,如果命中的实验方案的人群,刚好是一些特定人群,比如非大陆人群,可能会导致最终的结果不准。该如何何避免这种情况的发生?
从这个问题来看,这是一个非常常见的问题,即使我们已经采用了相当平均的随机算法去保证人群的随机性,但还是有一定的概率抽样到特定人群中,这样就会导致结果有偏差。这种现像叫抽样误差。
因为这种问题比较常见,所以我们在比较实验方案时,会采用一套科学的方法,尽量让实验的结果靠近总体的真实结果。那这个方法是什么呢?
在讲方法之前,我们来了解一下这样一个概念:假设检验(hypothesis testing)
它是对总体的某种规律提出一个假设,通过样本数据来推断,决定是否拒绝这一假设,这样的统计活动,称为假设检验。
假设检查的基本步聚如下:
1. 建立检验假设,确定检验水准
零假设 (null hypothesis), 又秒原假设,记为 H0;
简单理解就是说,抽样的结果与总体结果相等。我们的实验方案没有效果。
H0: u1 = u2 (u表示均数)
对立假设 (alternative hypothesis) ,又称备择假设,记为 H1;
简单的理解就是,抽样结果与总体结果不等,我们的实验方案有差别,或者说有效果。
H1: u1 <> u2 (u1 > u2, u2 < u1) (又叫双侧)
所以这里要避免的是两类错误,第 I 类是在 H0 成立时(真实情况成立),因样本误差或统计错误拒绝了 H0 。
另一类是 H0 不成立时,没有拒绝 H0。虽然有点绕,说的就是接受与拒绝假设要谨慎。
| 判断结论 | 真实情况 | |
|---|---|---|
| H0为真 | H1为真 | |
| 拒绝H0 | 第一类错误 | 正确 |
| 接受H0 | 正确 | 第二类错误 |
在这两类错误中,相对更加严重的是第 I 类错误,为了尽量避免第一类错误的发生,这里引入了另一个概念:"检验水准(显著性水平)" 记为 a,表示原假设为真时, 拒绝原假设的概率 (第一类错误的概率)。α 的取值应尽可能小,通常取 0.05.
2. 选择并计算检验统计量
选择适宜的统计量
分子:样均数之差
分母:样本均数之差的标准差
Z: 样本均数的差别(以其标准差为单位)
如果我们把对照组的实验数据和实验版本的数据用上面的公式算出一个值。比如 3.7
3. 确定 P 值,做出推断
P 值 (又叫显著性水平):Z 的当前值之外的尾部面积 (求面积可以通过查表。
P 值的意义在于零假设成立的条件下,出现 “统计量当前值及更不利于零假设的数值”的概率为 P.
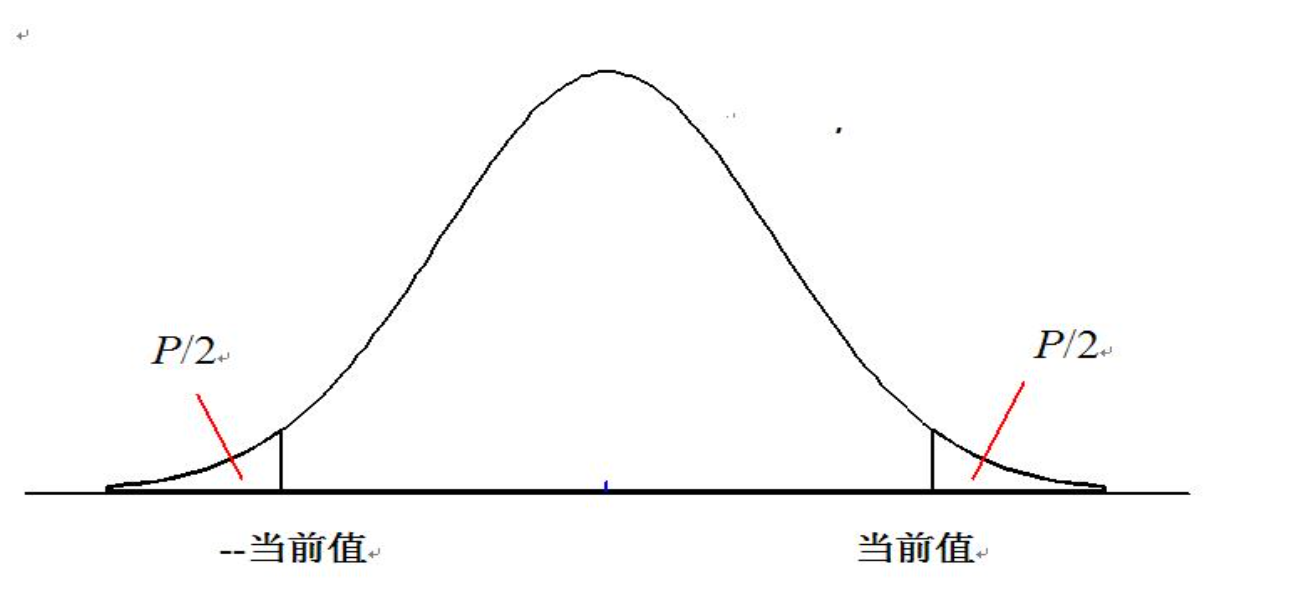
如果这个 P (尾部面积) 小于我们之前定的检验水准 (上面的 a) P < a, 认为“不大可能”犯假阳性错误。(这是我们极期希望看到的结果,实验显著,实验方案有效了)
如果这个 P > a,表明“极有可能”犯假阳性错误。
决策原则 :H0 成立时,若当前情形是不太可能发生的,则拒绝 H0。
例如: 如果 α 取 0.05 而 p = 0.04,说明如果原假设为真,则此次试验发生了小概率事件。根据小概率事件不会发生的判断依据,我们可以反证认为原假设不成立。
