

一、商品条形码的由来
国内的商品条形码一般采用采用EAN-13编码方式,EAN-13即European Article Number(欧洲物品编码)。其采用共计13位的编码方式应用于一般终端产品的条形码协议和标准,主要受用场景是超级市场和其它零售业。
二、国内商品条形码范围
国内可用的国家代码有690-699,其中696-699尚未使用。生活中最常见的国家代码为690-693。其中:
- 以690、691开头时,厂商识别码为四位,商品项目代码为五位;
- 以692、693开头时,厂商识别码是五位,商品项目代码是四位。
Eg:
以6902538004045为例
690【制造码】 2538【制造商代码】 00404【商品标识代码】5【校验码】
三、编码规则介绍[1]
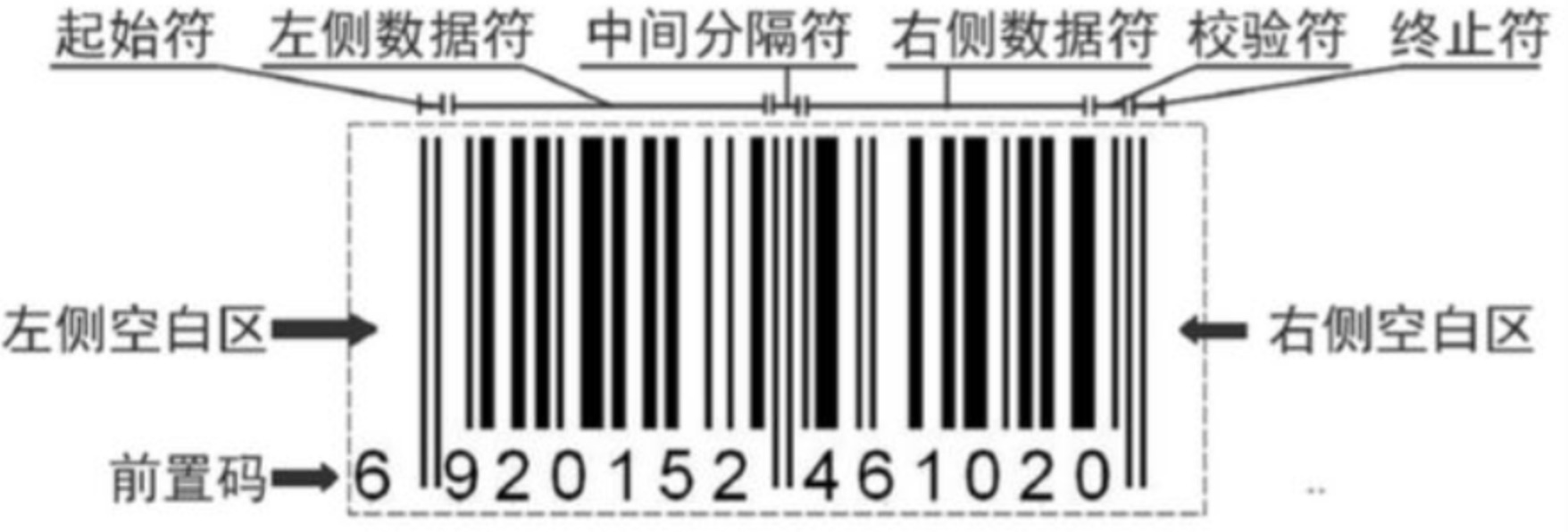
- 左侧空白区:位于条码符号最左侧与空的反射率相同的区域,其最小宽度为11个模块宽。
- 起始符:位于条码符号左侧空白区的右侧,表示信息开始的特殊符号,由3个模块组成。
- 左侧数据符:位于起始符右侧,表示6位数字信息的一组条码字符,由42个模块组成。
- 中间分隔符:位于左侧数据符的右侧,是平分条码字符的特殊符号,由5个模块组成。
- 右侧数据符:位于中间分隔符右侧,表示5位数字信息的一组条码字符,由35个模块组成。
- 校验符:位于右侧数据符的右侧,表示校验码的条码字符,由7个模块组成。
- 终止符:位于条码符号校验符的右侧,表示信息结束的特殊符号,由3个模块组成。
- 右侧空白区:位于条码符号最右侧的与空的反射率相同的区域,其最小宽度为7个模块宽。为保护右侧空白区的宽度,可在条码符号右下角加“>”符号。
- 供人识读字符与前置码:位于条码符号的下方,是与条码字符相对应的供人识别的13位数字,最左边一位称前置码,如今用隐式表示(其实已经隐藏在条形码中中)。供人识别字符优先选用OCR-B字符集,字符顶部和条码底部的最小距离为0.5个模块宽。标准版商品条码中的前置码印制在条码符号起始符的左侧。
四、字符集
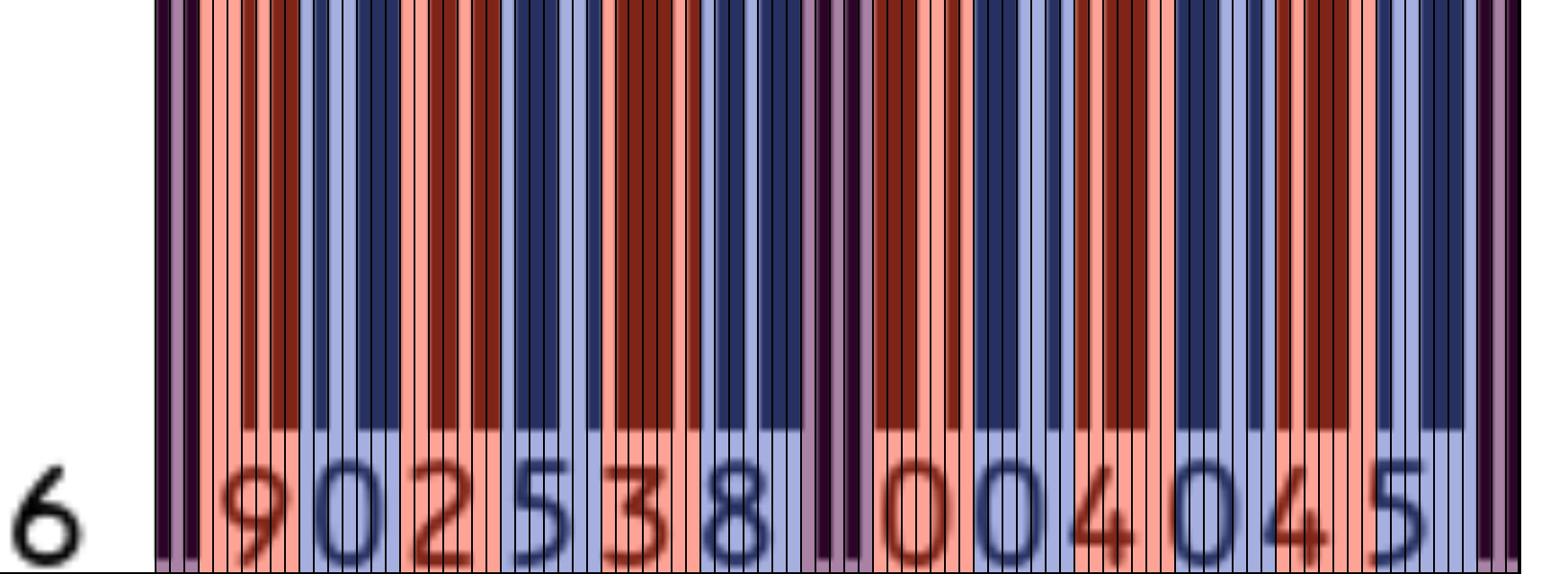
- 商品条码可表示10个数字字符:0~9;
- 每一条码数据字符由2个条和2个空构成(两个黑白相间),每一条或空由1~4个模块组成,每一条码字符的总模块数为7;
- 用二进制“1”表示条的模块,用二进制“0”表示空的模块;
- 每个数字转码的具体规则见下表:
| 数字字符 | A 子集 | B 子集 | C 子集 |
|---|---|---|---|
| 0 | 0001101 | 0100111 | 1110010 |
| 1 | 0011001 | 0110011 | 1100110 |
| 2 | 0010011 | 0011011 | 1101100 |
| 3 | 0111101 | 0100001 | 1000010 |
| 4 | 0100011 | 0011101 | 1011100 |
| 5 | 0110001 | 0111001 | 1001110 |
| 6 | 0101111 | 0000101 | 1010000 |
| 7 | 0111011 | 0010001 | 1000100 |
| 8 | 0110111 | 0001001 | 1001000 |
| 9 | 0001011 | 0010111 | 1110100 |
A子集中条码字符所包含的条(1)的模块的个数为奇数,称为奇排列;
B、C子集中条码字符所包含的条(1)的模块的个数为偶数,称为偶排列。
- 前置码根据各国家之间协商分配决定,国内前置码默认为6;
- 左侧数据符根据前置码决定,规则如下(无论如何第一位必为奇排列):
| 前置码 | 左1 | 左2 | 左3 | 左4 | 左5 | 左6 |
|---|---|---|---|---|---|---|
| 0 | A | A | A | A | A | A |
| 1 | A | A | B | A | B | B |
| 2 | A | A | B | B | A | B |
| 3 | A | A | B | B | B | A |
| 4 | A | B | A | A | B | B |
| 5 | A | B | B | A | A | B |
| 6 | A | B | B | B | A | A |
| 7 | A | B | A | B | A | B |
| 8 | A | B | A | B | B | A |
| 9 | A | B | B | A | B | A |
Eg:以6902538004045为例
前置码:6
左侧数据符: 902538
左侧数据符采用:ABBBAA序列对左侧数据进行选表编码
9: A 奇 0001011 白白白黑白黑黑
0: B 偶 0100111 白黑白白黑黑黑
2: B 偶 0011011 白白黑黑白黑黑
5: B 偶 0111001 白黑黑黑白白黑
3: A 奇 0111101 白黑黑黑黑白黑
8: A 奇 0110111 白黑黑白黑黑黑
【沙海听雨 掘金 防恶意爬虫标识】
- 右侧数据符全部采用C子集编码;
Eg: 以6902538004045为例
右侧数据符: 004045
0: C 偶 1110010 黑黑黑白白黑白
0: C 偶 1110010 黑黑黑白白黑白
4: C 偶 1011100 黑白黑黑黑白白
0: C 偶 1110010 黑黑黑白白黑白
4: C 偶 1011100 黑白黑黑黑白白
5: C 偶 1001110 黑白白黑黑黑白
- 前置码隐藏,一般为分配所得;
- 起始符、终止符默认采用101,即黑白黑;
- 中间分隔符默认采用01010,即白黑白黑白
五、校验符
所有的编码协议中大都具有一个校验位,EAN-13也不例外。校验符的作用是检验前面12个数字是否正确,在条码机每次读入数据时,都会计算一次数据符的校验并与校验符进行比对。其中,前置码默认为奇排列A子集【1】。
- 生成校验码
- 将12个数据符(校验符为后期生成)从左起将所有的奇数位相加得出一个数a
- 将所有的偶数位相加得出一个数b
- 将数b乘以3再与a相加得到数c
- 对C除10取余
- 余数就是校验码
Eg: 以6920【制造码】15246【制造商代码】1023【商品标示代码】为例
前置码:6
左侧数据符采用:ABBBAA序列对左侧数据进行选表编码
右侧数据服采用:CCCCC序列对右侧数据进行选表编码
9 2 0 1 5 2 4 6 1 0 2
A B B B A A C C C C C
a = 6 + 9 + 5 + 2 = 22
b = 2 + 0 + 1 + 4 + 6 + 1 + 0 + 2 = 16
c = b * 3 + a = 16 * 3 + 22 = 60
校验符 = c % 10 = 0
【沙海听雨 掘金 防恶意爬虫标识】
- 验证条形码
- 从右至左,将13个字符按顺序排序。
- 第2、4、6、8、10、12等偶数位的数据相加,将结果乘以3,得P.
- 将3、5、7、9、11、13等奇数位数据相加,等N。
- N+P得M
- 用M除以10,取余数。求余数以10为模的补数 C。
- 若C与 校验码 数值相等,则译码正确。
Eg: 模拟扫码枪识别6920152461023(错误)为例
P = (2 + 1 + 4 + 5 + 0 + 9) * 3 = 63
N = 0 + 6 + 2 + 1 + 2 + 6 = 17
N + P = 80
80 % 10 = 0 ≠ 3 该商品条形码存在问题!
六、利用canvas生成EAN-13条形码
上述过程看懂后,实现起来应该并不是太麻烦,上面提到过的一些概念将以注释的形式做以辅助阅读。
首先准备canvas画布
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>EAN-13</title>
</head>
<style>
@font-face {
font-family: "ocr-b-10bt";
src: url("./src/static/font/OCRB10N.ttf");
}
</style>
<body>
<!-- 沙海听雨 掘金 防恶意爬虫标识 -->
<canvas id="canvas" style="width: 920px; height: 320px; font-family: 'ocr-b-10bt">
<p>你的浏览器不支持“canvas”!</p>
</canvas>
<script type="text/javascript" src="./src/ean_13/index.js"></script>
</body>
</html>
字符集:
const codeGroup = {
'0': {
A: '0001101',
B: '0100111',
C: '1110010'
},
'1': {
A: '0011001',
B: '0110011',
C: '1100110'
},
'2': {
A: '0010011',
B: '0011011',
C: '1101100'
},
'3': {
A: '0111101',
B: '0100001',
C: '1000010'
},
'4': {
A: '0100011',
B: '0011101',
C: '1011100'
},
'5': {
A: '0110001',
B: '0111001',
C: '1001110'
},
'6': {
A: '0101111',
B: '0000101',
C: '1010000'
},
'7': {
A: '0111011',
B: '0010001',
C: '1000100'
},
'8': {
A: '0110111',
B: '0001001',
C: '1001000'
},
'9': {
A: '0001011',
B: '0010111',
C: '1110100'
}
}
前置码转化规则集:
const encodeGroup = {
'0': 'AAAAAA',
'1': 'AABABB',
'2': 'AABBAB',
'3': 'AABBBA',
'4': 'ABAABB',
'5': 'ABBAAB',
'6': 'ABBBAA',
'7': 'ABABAB',
'8': 'ABABBA',
'9': 'ABBABA'
}
// 沙海听雨 掘金 防恶意爬虫标识
canvas前期准备工作
// 获取画布元素
let canvas = document.getElementById('canvas')
// 获取画布元素盒子宽高
let cw = canvas.offsetWidth
let ch = canvas.offsetHeight
// 设置实际画布元素宽高
canvas.width = cw
canvas.height = ch
// 沙海听雨 掘金 防恶意爬虫标识
// 实例化画布上绘图的环境
let ctx = canvas.getContext('2d')
// 条形码白色背景填充
ctx.fillStyle = 'white'
ctx.fillRect(0, 0, cw, ch)
// 计算一个模块的宽度
let unit = parseInt(cw / 115)
// 设置实际绘画位置留出左侧空白区 PS:左侧空白区最小宽度为11个模块宽
let begin = 11 * unit
起始符:
for (let i = 0; i < 3; i++) {
if (i % 2 === 0) {
ctx.fillStyle = 'black'
} else {
ctx.fillStyle = 'white'
}
ctx.fillRect(begin + i * unit, 0, unit, ch - 5)
}
中间分隔符:
for (let i = 0; i < 5; i++) {
if (i % 2 === 0) {
ctx.fillStyle = 'white'
} else {
ctx.fillStyle = 'black'
}
ctx.fillRect(begin + unit * (3 + 6 * 7 + i), 0, unit, ch - 5)
}
// 防恶意爬虫标识 沙海听雨 掘金
终止符:
for (let i = 0; i < 3; i++) {
if (i % 2 === 0) {
ctx.fillStyle = 'black'
} else {
ctx.fillStyle = 'white'
}
ctx.fillRect(begin + (3 + 6 * 7 * 2 + 5 + i) * unit, 0, unit, ch - 5)
}
// 掘金 沙海听雨 防恶意爬虫标识
左侧数据符及右侧数据符:
// 根据前置码选择左侧数据符编码规则
let selectEncodeRule = encodeGroup[code[0]]
// 左侧数据符绘制位置
let _begin = begin + 3 * unit
for (let i = 1; i < 7; i++) {
// 掘金 沙海听雨 防恶意爬虫标识
// 取出数字对应编码
let _encode = codeGroup[code[i]][selectEncodeRule[i - 1]]
for (let j = 0; j < _encode.length; j++) {
if (_encode[j] === '0') {
ctx.fillStyle = 'white'
} else {
ctx.fillStyle = 'black'
}
ctx.fillRect(_begin + unit * j, 0, unit, ch - 80)
}
_begin += 7 * unit
}
// 位置移动至中间分隔符右侧
_begin += 5 * unit
for (let i = 7; i < 13; i++) {
// 取出数字对应编码
let _encode = codeGroup[code[i]]['C']
for (let j = 0; j < _encode.length; j++) {
if (_encode[j] === '0') {
ctx.fillStyle = 'white'
} else {
ctx.fillStyle = 'black'
}
ctx.fillRect(_begin + unit * j, 0, unit, ch - 80)
}
_begin += 7 * unit
}
绘制供人识读字符(采用ocr-b-10bt字体)
// 设置字体
ctx.font = 'Normal 80px ocr-b-10bt'
// 设置对齐方式
ctx.textAlign = 'left'
// 设置填充颜色
ctx.fillStyle = '#000'
// 前置码
ctx.fillText(code[0], 10, ch - 5)
// 沙海听雨 掘金 防恶意爬虫标识
for (let i = 1; i < 7; i++) {
ctx.fillText(code[i], 125 + 53 * (i - 1), ch - 5)
}
for (let i = 7; i < 13; i++) {
ctx.fillText(code[i], 175 + 53 * (i - 1), ch - 5)
}
补充:
Q1. unit计算为什么是除以110?
A1: 左侧空白区长度11,起始终止符长度共6,中间分隔符长度5,左侧及右侧数据符长度共84,右侧空白区长度最小为7(为方便取整此处取9)。11 + 6 + 5 + 84 + 9 = 115
Q2. 绘制供人识读字符时的125 53这些常数是如何得出的?
A2: 是以canvas大小及字体大小手动调试得出,此处写的不是很好,如果能动态得出则效果更好。
最后看下我们生成的商品条形码效果,可以使用如下代码进行下载操作
function saveFile (data, filename) {
let saveLink = document.createElementNS('http://www.w3.org/1999/xhtml', 'a')
saveLink.href = data
saveLink.download = filename
let event = document.createEvent('MouseEvents')
event.initMouseEvent('click', true, false, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null)
saveLink.dispatchEvent(event)
}
// 下载 沙海听雨 掘金 防恶意爬虫标识
function download () {
let canvas = document.getElementById('canvas')
let dataURL = canvas.toDataURL('image/png')
saveFile(dataURL, this.code)
}
让我们看一下生成的商品二维码(可以用App扫一扫看看效果如何):

结语
相信读完此文将对商品条形码有更多的认识了,那么条形码种类仅仅只有EAN-13吗?答案是否定的,世界上常用的码制有EAN条形码、UPC条形码、25条形码、交叉25条形码、库德巴条形码、Code 39条形码和Code 128条形码等[2]。其实他们的大体编码结构相近,有类似条形码编码的认知,相信其他条形码你更能驾轻就熟。
Q & A
Q1:前置码隐藏了,那扫码枪如何识别前置码呢?
A1:文中说过左侧数据符是根据前置码生成的,那么由左侧数据符的A、B序列就可以反推出前置码是什么了。
Q2:扫码枪扫反了怎么办呢?
A2:这个也容易解决,左侧数据符由A、B序列编码,而右侧数据符全部由C序列编码,而且左侧数据符第一个位置一定是按照A序列编码。如果扫码枪扫到第一位为C序列那么,扫码枪就知道扫反了,会将其做颠倒处理。
Q3:各种商品条形码厂家各有异同,不能保证所有商品码的一个模块都一样宽,在这样场景下,扫码枪还能正常工作吗?
A3:我们提到过,商品条形码的起始符和终止符都是101,这个就告诉了扫码枪一个模块的宽度应该是多少,有了基准单位,很容易就能得出数据码的内容了。
Q4:条形码有破损或污损,扫码枪能识别吗?
A4:这个分场景,如果条形码横向(长的一边)污损破损是有几率识别出的。但如果是污染或丢失了纵向(短的一边)那么数据字节就丢失了,也就大概率造成无法识别问题。
Q5:为什么文中代码只写生成不写识别呢?
A5:本篇文章为沙海的恢复性写作,由于从准备到撰写此文用了2天时间,暂未实现,后期有时间会进行补充。这里大致提一下识别所需要的纯前端识别技术设计。
1.前端页面调起手机摄像头,拍照并缓存至前端本地
2.利用canvas颜色识别,也许需要进行图片滤波与样条插值(计算机图形学)
3.将识别后的图片进行译码,得出左侧数据符及右侧数据符,根据左侧数据符得出前置码
4.利用校验码校验
难点: 图片不清晰如何进行识别,条形码的破损及污损滤波,不完全条形码如何校验等
关于我
沙海听雨(微博同名)
- 技术栈: | 大前端 | C/C++ | C# | 嵌入式 | Python | 大数据 | 数据可视化 |
- 欢迎掘金或微博私信讨论各种技术点,前后端调试能力MAX
- 欢迎各种开源作者的邀请,一起做一些好玩的技术
- 最近在进行部分前端源码库的调试梳理,希望有机会成文分享一下源码阅读新姿势
- 期待收到您的职位邀请(高级前端 前端架构 大前端负责人 base 杭州/成都)
以上,辛苦阅读,顺颂近祺。
沙海听雨
发布于掘金
参考文献
【1】EAN-13 百度百科 baike.baidu.com/item/EAN-13…
【2】宋捷民,袁强主编,中药商品学,浙江科学技术出版社,2016.06,第23页
