

个人环境
(1)Centos 7.0
(2)ELK-5.2.0-linux-x64
(3)filebeat-6.2.3-linux-x86
(4) jdk-8u141-linux-x64
(5)kafka_2.11-2.2.1
注:ELK一定要用同一个版本,不同版本之间会有各种各样的坑。其他软件可以使用不同版本。在这里,我分享了ELK的版本,其他的大家用自己的也行。这里给你们分享一个时空穿梭器:https://download.csdn.net/download/D_Janrry/12409286
拓扑图
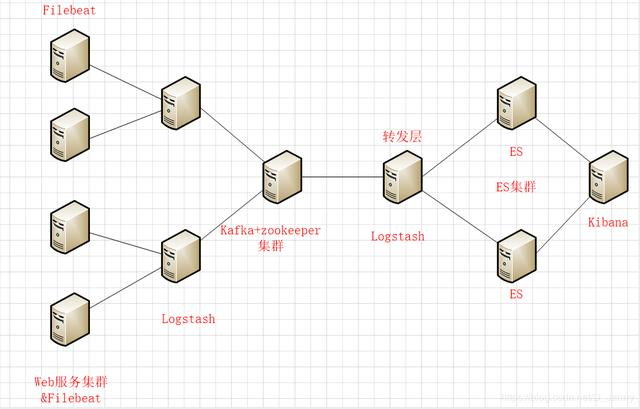
架构解读: (整个架构从左到右,总共分为5层)
第一层、数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务。
第二层、数据处理层,数据缓存层
logstash服务把接受到的日志经过格式处理,转存到本地的kafka + zookeeper集群中。
第三层、数据转发层
这个单独的Logstash节点会实时去kafka+zookeeper集群拉数据,转发至ES集群上。
第四层、数据持久化存储
ES集群会把收到的数据,写磁盘,建索引库。
第五层、数据检索,数据展示
ES Master + Kibana 主要协调ES集群,处理数据检索请求,数据展示。
环境初始化
1.节点规划
因为虚拟机有限,我就只能在一台机器上部署所有软件了。当然,两台、三台、四台、五台都可以。
2.配置主机名
hostnamectl set-hostname bigdata1su -l....3 .处理防火墙
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 04.同步时钟源
yum install ntpdate ntp -y
ntpdate cn.pool.ntp.org
hwclock --systohc5.安装常用软件
yum install net-tools bash-completion wget vim -y6.JDK安装
安装过于简单,咱们就跳过去了,相信大家都会
以上步骤三个节点都需要完成。
ELK安装
1.ES安装
其实本实验最难安装的就是es,因为他要放加入一个head插件,Elasticsearch5.x版本以后,head插件已经是一个独立的Web App了,所以不需要和Elasticsearch进行集成。所以版本老的可能安装时候有点费劲。
我有发表过一篇文章关于安装目前最新的es-7.6.2版本以及插件的安装,坑我已经填平了。时空穿梭器:https://blog.csdn.net/D_Janrry/article/details/105461236
但是,我介意大家不要安装最新的,最新的确实很牛*,但是坑太多,最后和logstash兼容的时候,显示获取不到es的镜像,无法兼容。
6.6.2版本也是无法兼容。
6.6.1版本可以兼容,ELK可以实现。但是,最后进行传送日志的时候,它的logstash不支持打开多个.conf文件。
看到这里,各位能想象到我一次次崩溃的心情吗?反正很烦很烦,坑贼多。所以,就放弃了。如果要做,就用5.2.0版本吧。对照着7.6.2就可以安装好,祝各位好运。
2.Logstash安装
Logstash事件处理有三个阶段: inputs -→filters→outputs。是一个接收, 处理,转发日志的工具。
支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
解压安装就好了,其实可以不做修改。这里我是修改了。接着往下看
[root@bigdata1 logstash]# pwd
/data/program/software/logstash
[root@bigdata1 logstash]# mkdir conf.d //配置文件的目录
[root@bigdata1 config]# pwd
/data/program/software/logstash/config
[root@bigdata1 config]# vim logstash.yml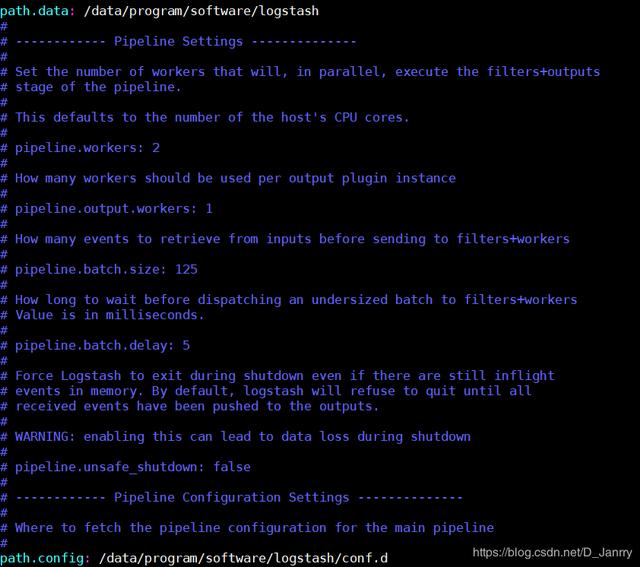
3.Kibana安装
安装,省略,因为安装大家都会对吧,过于简单重复,咱们就不细讲了
安装好后,修改配置文件
[root@bigdata1 config]# pwd
/data/program/software/kibana/config
[root@bigdata1 config]# vim kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.239.7:9200"
kibana.index: ".kibana"使用浏览器打开 http://192.168.239.7:5601
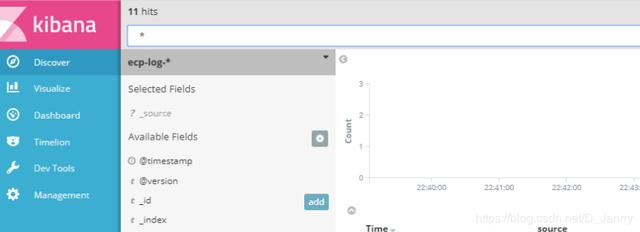
证明安装成功了。
Filebeat安装
filebeat.prospectors: //文件探测器
- type: log //探测类型,日志文件
enabled: false //这里一定要改成false,不然日志发送不出去
paths: //路径
- /var/log/*.log //注意,通配符*的存在使得相同目录结构的工程日志都会被收集到如图1所示:
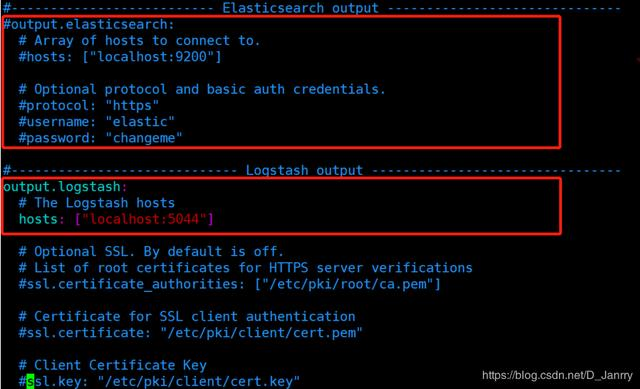
这里默认对接的是es,需修改为logstash。// 意思就是日志收集到后,交给了logstash。
注意:以上服务全部安装在bigdata1上,但是,es、kafka+zookeeper集群是要安装在三个节点上的。
kafka+zookeeper安装
1.zookeeper配置
我们知道kafak集群依赖zookeeper。其实在kafka程序包中已经包含了zookeeper。鉴于不同版本之间的问题,建议使用kafka的内嵌的zookeeper.
为什么呢?因为我又踩坑了,但是这个是对于电脑而言的,我的电脑另外安装zookeeper,最后在消费者那里接收不到生产者的消息。所以我就用了kafka的内嵌的zookeeper.
其配置如下:
[root@bigdata2 config]# pwd
/data/program/software/kafka/config
[root@bigdata2 config]# vim zookeeper.properties三个节点相同的操作。

注:如果你是外部安装了zookeeper出现我上述说的问题才来在用kafka内嵌的zookeeper,一定要把之前的zookeeper关闭。
2.kafka配置
[root@bigdata2 config]# pwd
/data/program/software/kafka/config
[root@bigdata2 config]# vim server.properties
broker.id=1
listeners=PLAINTEXT://bigdata1:9092
log.dirs=/var/kafka
zookeeper.connect=bigdata1:2181,bigdata2:2181,bigdata3:2181
将配置文件利用scp技术传送给另外两个节点,只需要修改broker.id的值为2、3,因为bigdata2和bigdata3上的kafka应用是直接复制过来的,所以需要将logs目录下的内容清空。
[root@bigdata2 kafka]# pwd
/data/program/software/kafka
[root@bigdata2 kafka]# ls
bin config libs LICENSE logs NOTICE site-docs
[root@bigdata2 kafka]# cd logs
[root@bigdata2 logs]# rm -rf ./*到此,服务部署就全部完成了。接下来,实现各个服务之间的协同工作。
日志收集分析
如果前面的流程图大家还一头雾水,那我简单的再说一下,工作流程:
- filebeat的配置文件中写了你要分析哪个目录下的日志,那么filebeat工作开始后,就会去对应目录收集日志。收集到以后,交给logstash,这就是前面设置它的流向的原因。如图1所示
- logstash的conf.d下配置一个用于接收filebeat日志消息的文件,并将日志发送到kafka+zookeeper集群(也就是消息队列),如图2所示。kafka+zookeeper集群接收到以后,再配置一个从kafka+zookeeper集群转发到es集群的文件,如图3所示。
- es集群接收到以后,再发送到kibana。最终在web界面提现出来,如图4、图5所示。
1.部署logstash+kafka+zookeeper
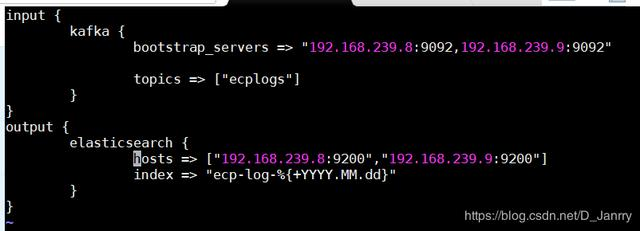
[root@bigdata1 conf.d]# vim filebeat_to_logstash.conf
input {
beat {
port => 5044
}
}
output{
kafka{
bootstrap_servers => "192.168.239.8:9092,192.168.239.9:9092"
topic_id => "ecplogs"
}
}如图所示:
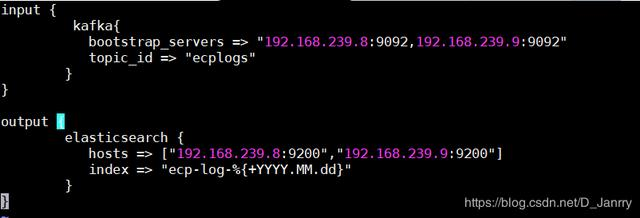
[root@bigdata1 conf.d]# vim logstash_to_elasticsearch.conf
input {
kafka{
bootstrap_servers => "192.168.239.8:9092,192.168.239.9:9092"
topic_id => "ecplogs"
}
}
output {
elasticsearch {
hosts => ["192.168.239.8:9200","192.168.239.9:9200"]
index => "ecp-log-%{+YYYY.MM.dd}"
}
}如图所示:
2.各环节服务启动与数据追踪
启动所有对应软件,值得提醒的是:filebeat启动时,需要安装一个软件:

(1)启动zookeeper+kafka
略。。。
(2)启动logstash接收日志
略。。。就是filebeat_to_logstash.conf文件
(3)在kafka终端上进行日志消费测试
[root@bigdata1 bin]# /data/program/software/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.239.8:9092 --topic ecplogs --from-beginning
//这里的ecologs就是logstash文件中的 topic_id 的值,一定要对应上日志如图所示:
因此,在最后kibana上的日志内容要和此处的一致。
(4)打开logstash转发
略。。。就是 logstash_to_elasticsearch.conf 文件
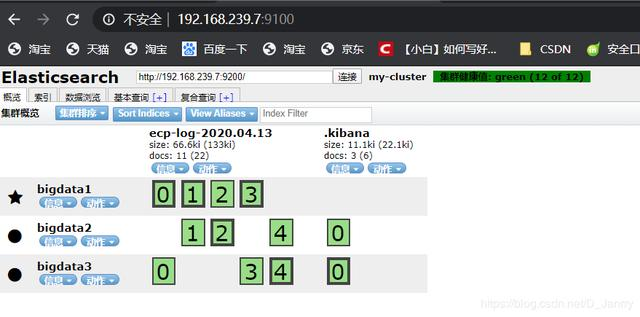
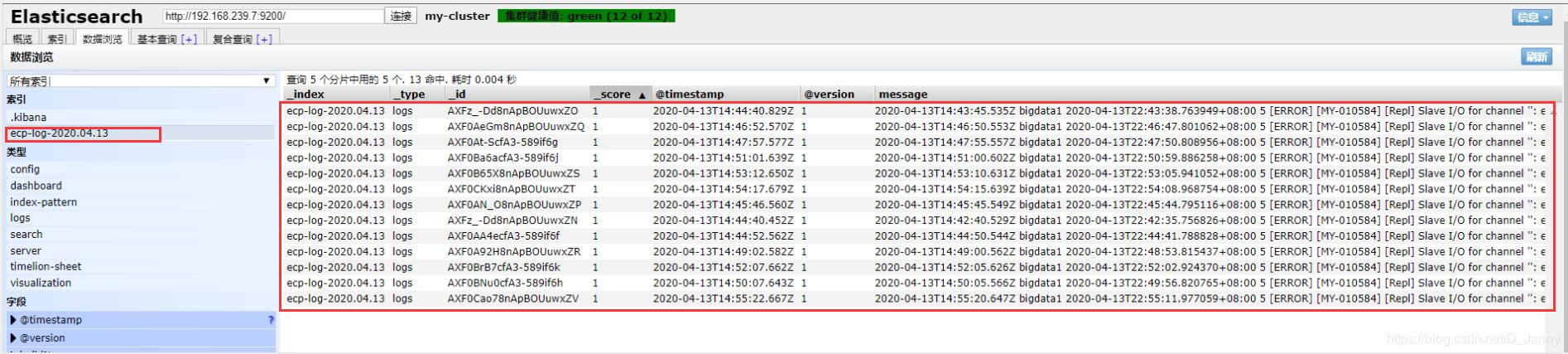
(5)es上测试结果
如图所示:
(6)将数据呈现在kibana上
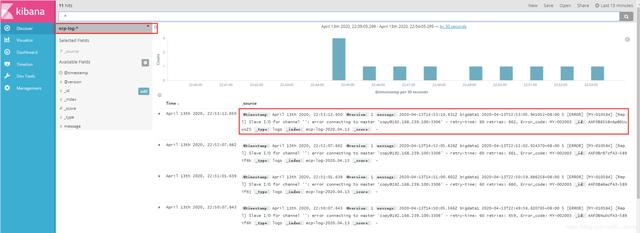
可以看到这里的收集的日志和kafka上收集到的一致,证明日志收集成功,到此,本实战项目结束。祝各位好运!
作者:Janrry丶龙龙
原文链接:https://blog.csdn.net/D_Janrry/article/details/106061610
