

Norm
目前已知的Normalization的方法有4种,对于输入数据为N,C,(H*W),其中第一种最为常见
- Batch Norm:对每一个批次(N个tensor)的每个通道分别计算均值mean和方差var,如[10,4,9] 最终输出是[0,1,2,3]这样的1*4的tensor
- Layer Norm:对于每一个tensor的所有channels进行均值和方差计算
- Instance Norm:对于每个tensor的每个channels分别计算
- Group Norm:引用了group的概念,比如BGR表示一个组 --不常见
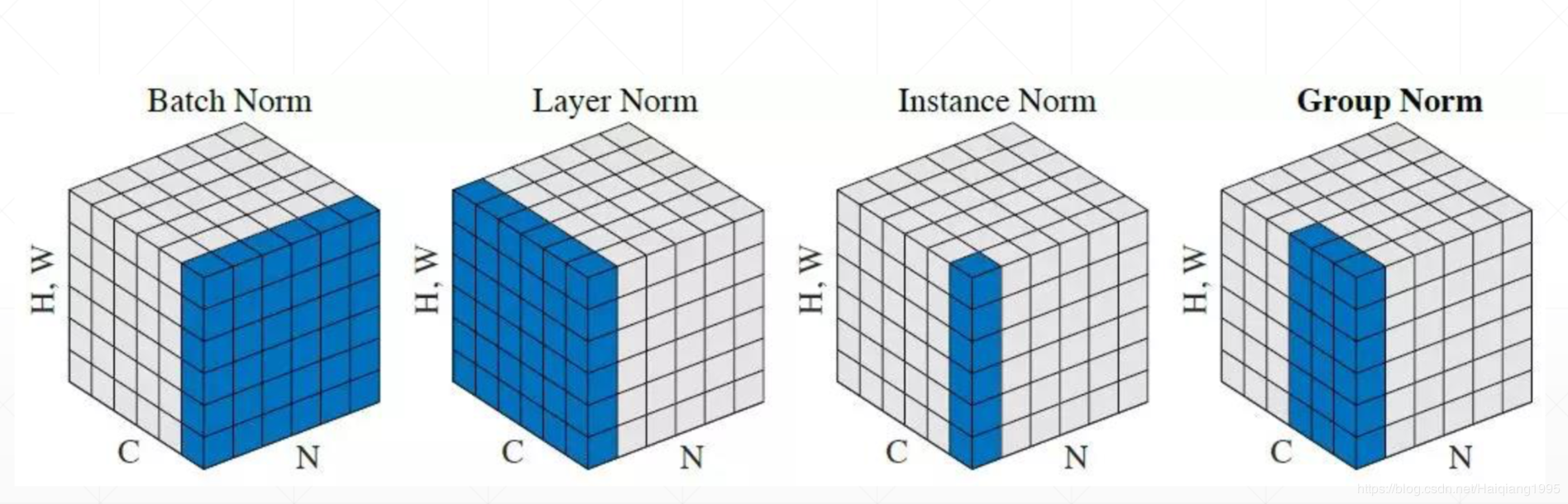
BatchNorm
中文翻译成批规范化,是在深度学习中普遍使用的一种技术,通常用于解决多层神经网络中间层的协方差偏移(Internal Covariate Shift)问题,类似于网络输入进行零均值化和方差归一化的操作,不过是在中间层的输入中操作而已,具体原理不累述了,见[2-4]的描述即可。

好了,这里我们记住了,在BN中,一共有这四个参数我们要考虑的:
- γ,β:分别是仿射中的
和
,在pytorch中用weight和bias表示。
和
:和上面的参数不同,这两个是根据输入的batch的统计特性计算的,严格来说不算是“学习”到的参数,不过对于整个计算是很重要的。在pytorch中,用running_mean和running_var表示.
到目前为止都很好李姐,但是对于二维多batch情况的图像数据,到底怎么操作呢??
我们假设在网络中间经过某些卷积操作之后的输出的feature map的尺寸为3×3×2×2
3为batch的大小,3为channel的数目,2×2为feature map的长宽
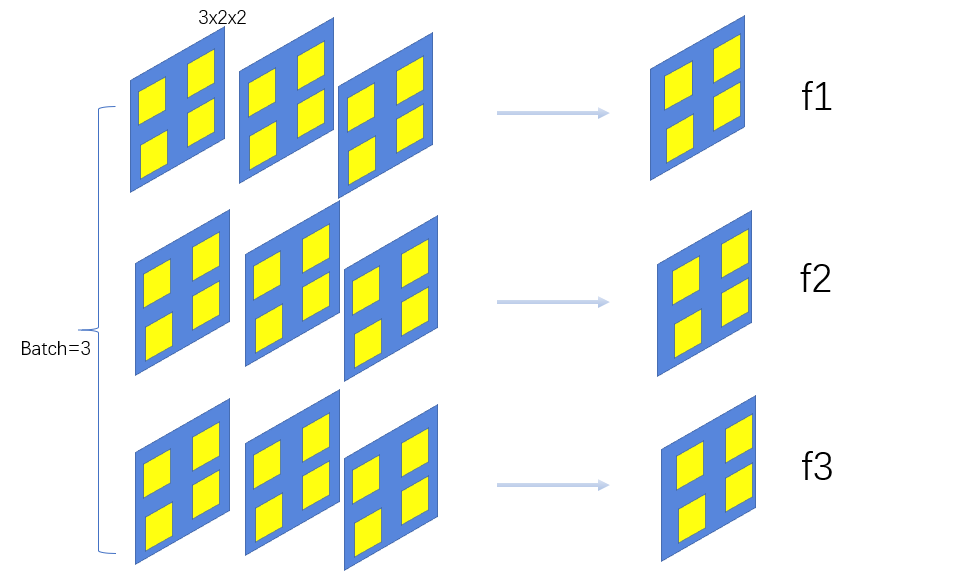
对于所有batch中的同一个channel的元素进行求均值与方差,比如上图,对于所有的batch,都拿出来最后一个channel,一共有3×4=12个元素
注意此处x_i和上面的公式的不是一个
blog.csdn.net/Haiqiang199… www.cnblogs.com/leebxo/p/10…
另外附上几个blog:
www.zhihu.com/question/38…
blog.csdn.net/whitesilenc…
blog.csdn.net/hjimce/arti…
