

Sharding-JDBC
Sharding-JDBC是ShardingSphere中的一个独立产品,定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
ShardingSphere已经在2020年4月16日成为Apache顶级项目(Apache官方发布从4.0.0版本开始)。
总结下,Sharding-JBDC是一个轻量级的嵌入式分库分表组件,包括SQL解析、路由、结果集合并等功能。分库分表这里不扩展介绍了,有兴趣的可以查查。
既然它是一个分库分表组件,那下面聊聊它是怎么处理联合(join)查询的,正在使用或者将要准备使用Sharding-JDBC的童鞋,请注意,这里有秘密要说,如果你的业务中存在跨分片查询场景,那么可能影响到你业务的正确性。
跨分片联合查询
现有两个数据库DB1和DB2,DB1上存在t_order 和t_order_item两张表,DB2上存在t_order表,两张表可通过ORDER_ID关联查询,SQL如下
select a.name,b.age from t_order a left join t_item b on a.order_id = b.order_id
按左连接查询,那么结果应该是和下图中的一致
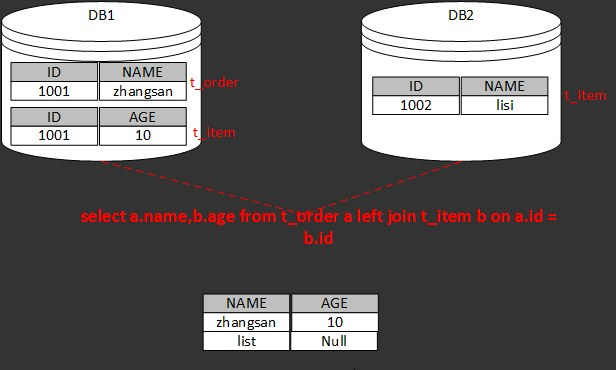
而sharding-JDBC结果却和我们预料的不一样,是不很惊讶
sharing-JDBC版本
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.0.0-RC2</version>
</dependency>
Sharding-JDBC的分库策略
dataSources:
ds_0: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_0
username: root
password: root
ds_1: !!org.apache.commons.dbcp.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds_1
username: root
password: root
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order
databaseStrategy:
inline:
shardingColumn: order_id
algorithmExpression: ds_${order_id % 2}
t_order_item:
actualDataNodes: ds_0.t_order_item
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item
databaseStrategy:
inline:
shardingColumn: order_id
algorithmExpression: ds_0
模拟数据
DB1中t_order表中数据
INSERT INTO `ds_0`.`t_order` (`order_id`, `order_name`) VALUES ('1001', 'zhangsan');
t_order_item中数据
INSERT INTO `ds_0`.`t_order_item` (`order_id`, `order_name`, `age`) VALUES ('1001', NULL, '10');
DB2中t_order表中数据
INSERT INTO `ds_1`.`t_order` (`order_id`, `order_name`) VALUES ('1002', 'lisi');
验证数据
通过sharding-JDBC执行下面SQL
@Test
public void testSelect() throws Exception {
try (Connection connection = YamlConfigurationExample.getDataSource().getConnection();
Statement ps = connection.createStatement();){
final String sql = "select a.order_name,b.age from t_order a left join t_order_item b on a.order_id = b.order_id ";
ResultSet rs = ps.executeQuery(sql);
while (rs.next()) {
System.out.println("order_name[" + rs.getString(1)
+ "] age[" + rs.getString(2) +"]");
}
}
}
执行结果

出乎意料,查询结果与我们预料的并不相符,业务中如果真的存在这样的场景,那不死翘翘了。难道真的有bug?莫慌,今天带你从源码的角度分析sharding-JDBC找出问题根源。
分析问题
首先分析问题,结果集不对,一般产生这个问题可能出现在两个地方,
- 路由,可能路由结果不对,本来SQL发送DB1和DB2,结果路由出来是DB1
- 结果集合并,结果集合并存在缺陷
首先从路由角度跟踪下源码,路由入口
private void shard(final String sql) {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
SimpleQueryShardingEngine shardingEngine = new SimpleQueryShardingEngine(runtimeContext.getRule(), runtimeContext.getProps(), runtimeContext.getMetaData(), runtimeContext.getDatabaseType(),runtimeContext.getParseEngine());
sqlRouteResult = shardingEngine.shard(sql, Collections.emptyList());
}
这块涉及到了SQL改写,比如分表改写表名等,题外话,继续分析executeRoute方法
public SQLRouteResult shard(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
//route
SQLRouteResult result = executeRoute(sql, clonedParameters);
//构建可执行单元
result.getRouteUnits().addAll(HintManager.isDatabaseShardingOnly() ? convert(sql, clonedParameters, result) : rewriteAndConvert(sql, clonedParameters, result));
if (shardingProperties.getValue(ShardingPropertiesConstant.SQL_SHOW)) {
boolean showSimple = shardingProperties.getValue(ShardingPropertiesConstant.SQL_SIMPLE);
SQLLogger.logSQL(sql, showSimple, result.getOptimizedStatement(), result.getRouteUnits());
}
return result;
}
通过SPI方式注册Hook实现,路由如果失败,可由用户扩展外部处理。这块代码个人觉得很厉害,可以借鉴
private SQLRouteResult executeRoute(final String sql, final List<Object> clonedParameters) {
routingHook.start(sql);
try {
SQLRouteResult result = route(sql, clonedParameters);
routingHook.finishSuccess(result, metaData.getTable());
return result;
// CHECKSTYLE:OFF
} catch (final Exception ex) {
// CHECKSTYLE:ON
routingHook.finishFailure(ex);
throw ex;
}
}
略过中间步骤,最后走的是复杂查询引擎ComplexRoutingEngine
public RoutingResult route() {
Collection<RoutingResult> result = new ArrayList<>(logicTables.size());
Collection<String> bindingTableNames = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
for (String each : logicTables) {
Optional<TableRule> tableRule = shardingRule.findTableRule(each);
if (tableRule.isPresent()) {
if (!bindingTableNames.contains(each)) {
result.add(new StandardRoutingEngine(shardingRule, tableRule.get().getLogicTable(), optimizedStatement).route());
}
Optional<BindingTableRule> bindingTableRule = shardingRule.findBindingTableRule(each);
if (bindingTableRule.isPresent()) {
bindingTableNames.addAll(Lists.transform(bindingTableRule.get().getTableRules(), new Function<TableRule, String>() {
<span class="hljs-meta" style="color: #4078f2; line-height: 26px;">@Override</span>
<span class="hljs-function" style="line-height: 26px;"><span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">public</span> String <span class="hljs-title" style="color: #4078f2; line-height: 26px;">apply</span><span class="hljs-params" style="line-height: 26px;">(<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">final</span> TableRule input)</span> </span>{
<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">return</span> input.getLogicTable();
}
}));
}
}
}
<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">if</span> (result.isEmpty()) {
<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">throw</span> <span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">new</span> ShardingException(<span class="hljs-string" style="color: #50a14f; line-height: 26px;">"Cannot find table rule and default data source with logic tables: '%s'"</span>, logicTables);
}
<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">if</span> (<span class="hljs-number" style="color: #986801; line-height: 26px;">1</span> == result.size()) {
<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">return</span> result.iterator().next();
}
<span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">return</span> <span class="hljs-keyword" style="color: #a626a4; line-height: 26px;">new</span> CartesianRoutingEngine(result).route();
}
方法最后走的笛卡尔路由引擎CartesianRoutingEngine
@Override
public RoutingResult route() {
RoutingResult result = new RoutingResult();
for (Entry<String, Set<String>> entry : getDataSourceLogicTablesMap().entrySet()) {
List<Set<String>> actualTableGroups = getActualTableGroups(entry.getKey(), entry.getValue());
List<Set<TableUnit>> routingTableGroups = toRoutingTableGroups(entry.getKey(), actualTableGroups);
result.getRoutingUnits().addAll(getRoutingUnits(entry.getKey(), Sets.cartesianProduct(routingTableGroups)));
}
return result;
}
主要看下getDataSourceLogicTablesMap这个方法获取datasource和表的
private Map<String, Set<String>> getDataSourceLogicTablesMap() {
Collection<String> intersectionDataSources = getIntersectionDataSources();
Map<String, Set<String>> result = new HashMap<>(routingResults.size());
for (RoutingResult each : routingResults) {
for (Entry<String, Set<String>> entry : each.getDataSourceLogicTablesMap(intersectionDataSources).entrySet()) {
if (result.containsKey(entry.getKey())) {
result.get(entry.getKey()).addAll(entry.getValue());
} else {
result.put(entry.getKey(), entry.getValue());
}
}
}
return result;
}
看下getIntersectionDataSources方法,从名字上可以看出是取datasource交集,前边是按表路由,这块是按datasource取交集,所以问题就是出在这里,比如示例中SQL t_order表在(ds_0,ds_1) t_item表在(ds_0),则交集为ds_0,所以sharding-JDBC并没有拆分SQL去每个数据库查询,然后合并结果集。
//取datasource交集
private Collection<String> getIntersectionDataSources() {
Collection<String> result = new HashSet<>();
for (RoutingResult each : routingResults) {
if (result.isEmpty()) {
result.addAll(each.getDataSourceNames());
}
result.retainAll(each.getDataSourceNames());
}
return result;
}
结束语
这样处理,我觉得并不算是设计缺陷,主要和sharding-JDBC设计理念有关,sharding-JDBC的定位是轻量级嵌入式分库分表组件,嵌入到应用端,那么意味着与应用共享同一个服务器资源,如果执行复杂SQL,比如上边提到的,就必须的对SQL进行拆分,拆分为select * from t_order 在db1和db2中查询,select * from t_order_item在db1中查询,然后内存中合并结果集,这样会消耗大量的服务器资源,有可能会拖垮应用,所以sharding-JDBC建议所有查询带有分片键,减少损耗。
如果你的应用中有大量的跨分片查询,那么需要分析sharding-JDBC是否适合你的业务?是否需要考虑Mycat、Dble(个人不建议使用Mycat,原因你懂的),或者是通过其他途径去规避,比如全局表,sharding-JDBC中提到的绑定表,其实就是Mycat或者Dble中的ER表,俗称主子表等方式去规避。
本文使用 mdnice 排版
