

背景
最近工作中用到了消息队列,在看了一些资料,对于kafka的设计上有一些想法和阅读的记录吧,先聊聊消息格式的设计。
消息格式-省字节
kafka是一个消息引擎,需要先定义具体的消息格式,具体保存什么样的数据,以及发送的数据格式都是什么。 如果使用Java类来定义消息格式,一般会定义一个java类,定义一些属性进行消息的定义,这里一个java类占用的字节大小是会比较大的。 一般我们制定消息格式的话,会考虑可读性和传输性能等。可以看到,对于消息的大小其实是比较看重的,因此一般会有几个优化的方向,比如客户端的json或者xml,改成使用pb的方式。 或者说类似于tcp格式的制定,对于一些标识,都是使用一个字节,或者一位来进行判断的。 性能要求比较高的产品,都是很能扣字段大小的,毕竟看起来省下来几个字节,但是如果数据量大的情况,整体节省的量就比较可观咯。
消息格式-V0版本
V0版本的消息格式:
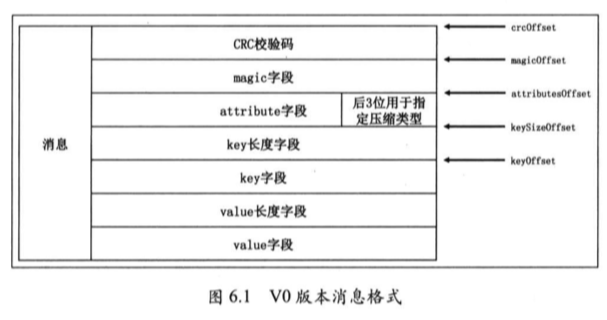
这个版本相对来说比较朴素,存了基本的一些数据,不过总体来说有这么几个问题。
- 消息没有包括时间信息,而kafka作为消息引擎系统也是需要定期删除过期日志的,不能无限保存,所以这里的时间戳需要依赖日志段文件的修改时间。
- kafka后续要做一些流式处理的事情,这里会通过每条消息的时间戳进行一些聚合操作。
消息格式-V1版本
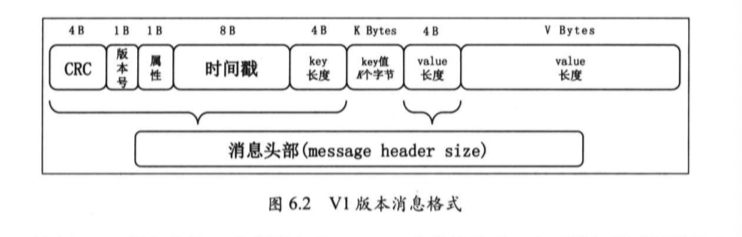
V1版本针对V0版本进行了一些改进,增加了时间戳字段,并且在attribute字段的第4位指定了时间戳类型。 支持消息创建时候指定的时间戳,以及发送到broker指定时间戳。
消息格式-V2版本

首先V2版本使用了可变长度来进行数据的存储,借鉴了Google ProtoBuffer中的Zig-zag编码方式,使得绝对值比较小的整数占用比较少的字节。 V2版本除了有可变长度,同时有了以下几个改进。
- 增加了小子总长度字段,这样在进行计算或者分配内存的时候可以直接获取数值。
- 保存时间戳增量,不再使用固定的8字节来保存时间戳信息,而是使用一个可变长度保存与batch起始时间戳的差值,差值通常比较小,所以需要的字节数也比较少。 kafka作为一款优秀的消息引擎,在能节省的地方,比如可变长度,时间戳增量都进行了很多的尝试。
- 保存位移增量,与时间戳增量类似,保存消息位移与外层batch起始位移的差值,进一步进行空间的节省。
- 增加消息头部,满足用户的定制化的一些需求。
- 去除CRC校验,而是对整个消息batch进行CRC校验
- 废弃attribute字段,统一保存在外层的batch格式字段中。
消息batch格式-V2版本
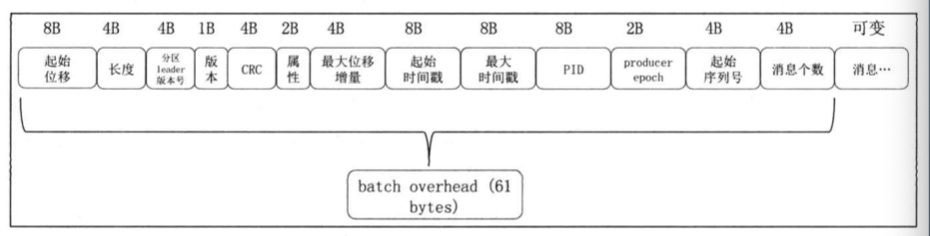
这里增加了消息batch的概念,每个batch可以放入多条kafka消息,对于batch的头结点看起来是增加了字段,但是平摊到包含的kafka消息中,总体上基本还是节省空间。
杂谈
通过kafka消息格式的变化,我们可以从中可以看出来,对于一个优秀的技术产品,精益求精的态度是必须有的,比如追求消息的格式大小。 第二个是优秀的技术产品也是不断进行演进的,可能一开始你并没有想的很清楚,但是不要紧,你可以慢慢的进行改进,不断打磨的过程,会让你越来越丰满。
