

这些日子,笔者接到了一个SaaS服务的需求,大概就是做一个整体的活体检测服务,然后别人可以以url的形式调用,用得到的code去做校验以拿到活体检测的结果。
这样来看,我的系统做为一个中间层服务,应该减少自身大小,在此情况下,我决定不使用市面上的框架,vue或者是react,而采取自己手撸一个html。

自信而骄傲的开始
首先为什么不优先考虑使用框架,那么我使用vue-cli工具,创建一个空白的项目,打包之后,我们可以看到,即使采用了Gzipped压缩,仍然有93.61KiB的大小,更何况,人一旦懒起来,vue用都用了,干嘛不用一下UI框架,做着做着,项目就会更大。
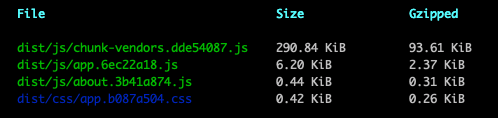
所以,如果手撸js的情况下,可以有效的降低大小,包含全业务的情况下,也只有如下图的大小。

完美了,我的包只有80KiB的大小,秒开率怎么会低呢?就算是3G网络,理论值都有3.1M,下载速度是可以达到100-150KB/秒的理论值。
画外音
有些人可能会问了,“哎,你这样写,以后别人怎么维护呢?”
其实这里要说的就是用框架是规范我们的行为和边界,如果你可以独立的保持自己的行为和边界,你的代码就会拥有优秀的可阅读性以及可维护性。
高开
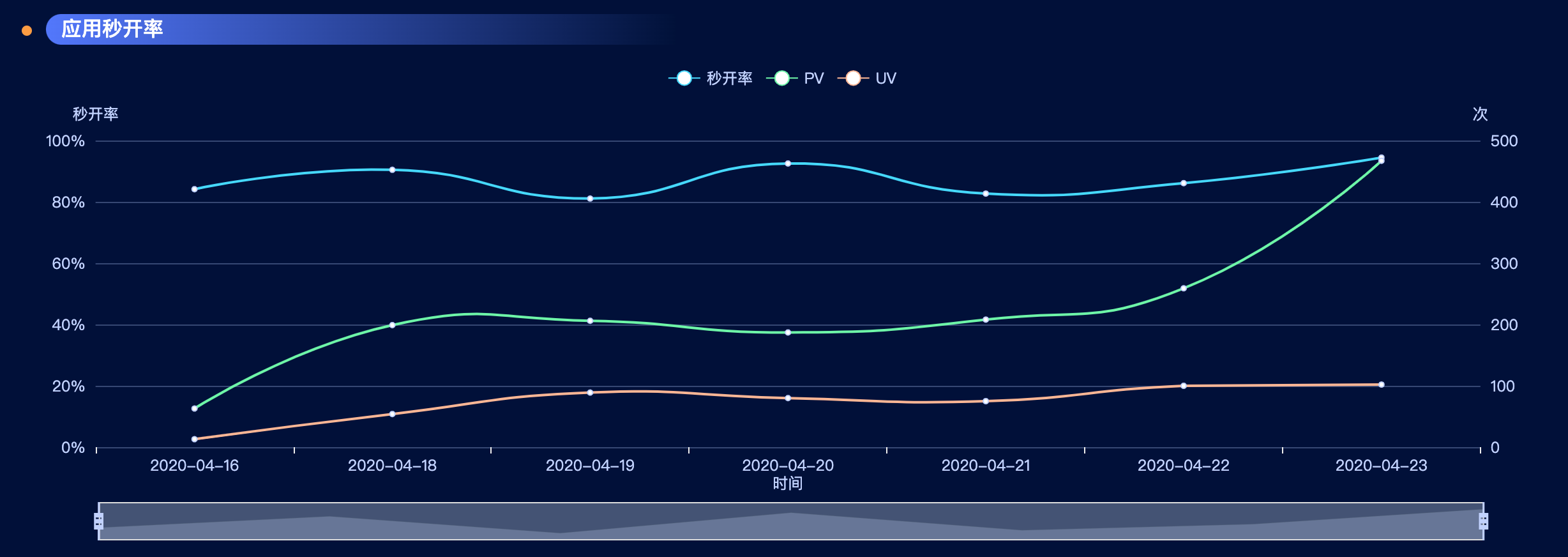
看到这张图的我表示还算满意,本来预期会更好,但是也还好了,毕竟全国各地,总有地方网络不好,会有波动,秒开率在80-100之间跳动,也算是我可以接受的范围。
低走
观察比较仔细的小朋友,一眼就看到了,“哎,你这个日期是4月中旬,现在都5月了,你是不是又骗我”,那么,接下来的事情,让我有点头皮发麻了。
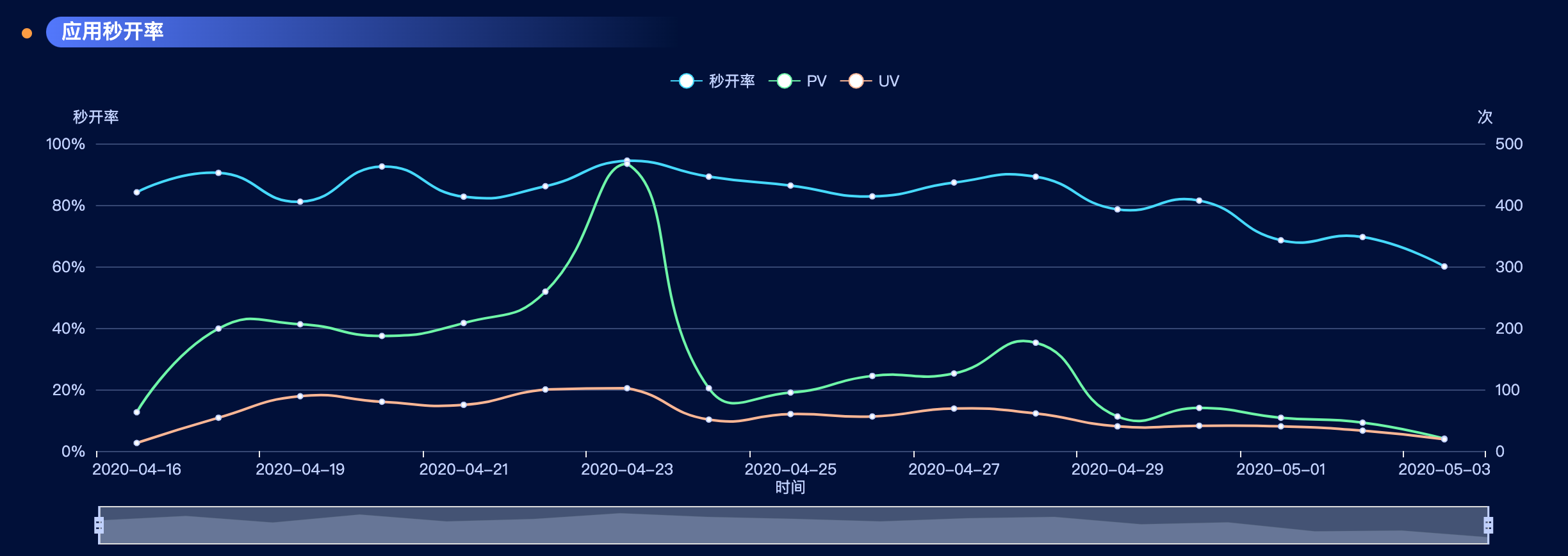
???what???

我突然懵逼了,在CDN的情况下,缓存命中率理论上应该逐渐增高,也就是秒开率只会越来越高,怎么会逐步降低呢?甚至一度降低到了60%,很不可思议的事情。我决定仔细排查这个问题!
80KiB,你被表象欺骗了
因为这几天数据的异常,首先我们需要看一下耗时分布。
在体验中心查看一下5月1~5月3的耗时分布:
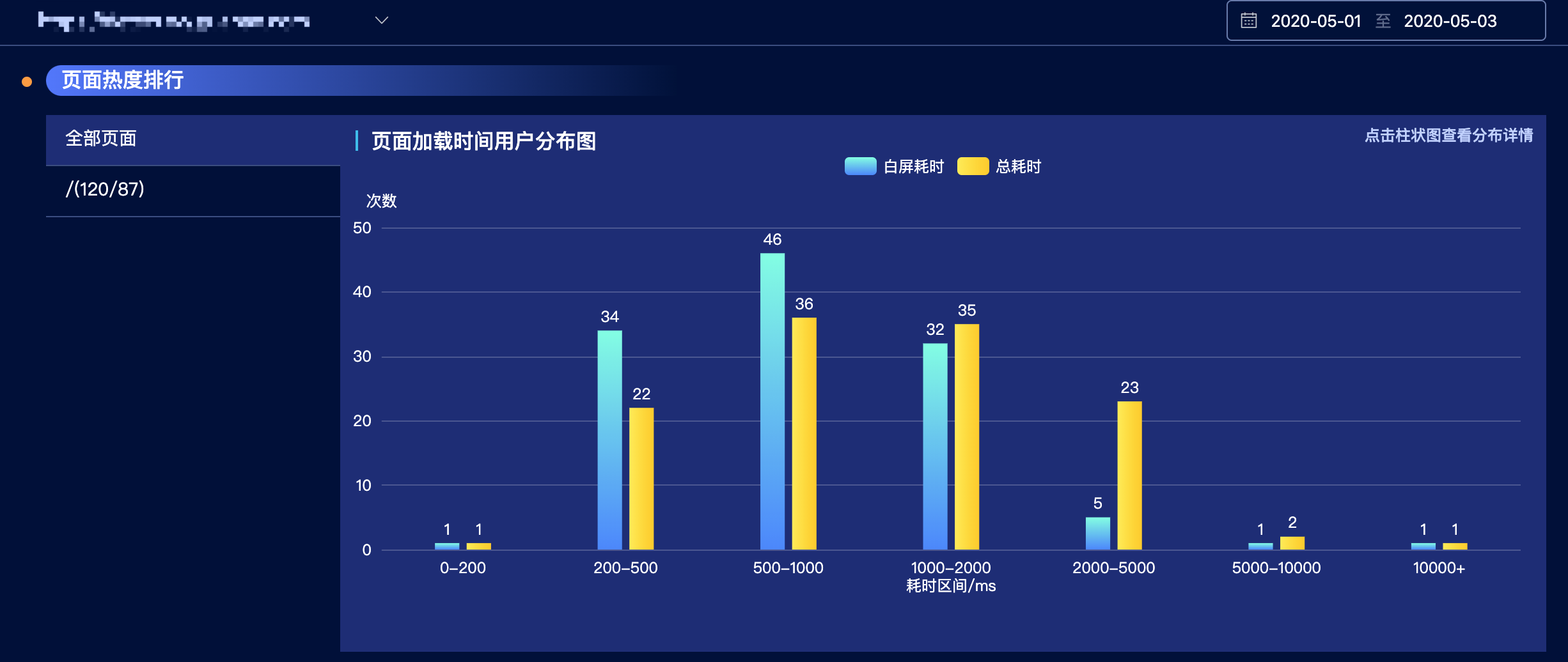
我们可以看到,峰值在500-1000ms之间,左右区间数值大致相同,这里很奇怪,一个只有80KiB的系统,为什么加载耗时的峰值会在500-1000ms之间呢?这个先放一放,我们先查看一下1000-2000ms耗时的数据是怎么的具体情况。
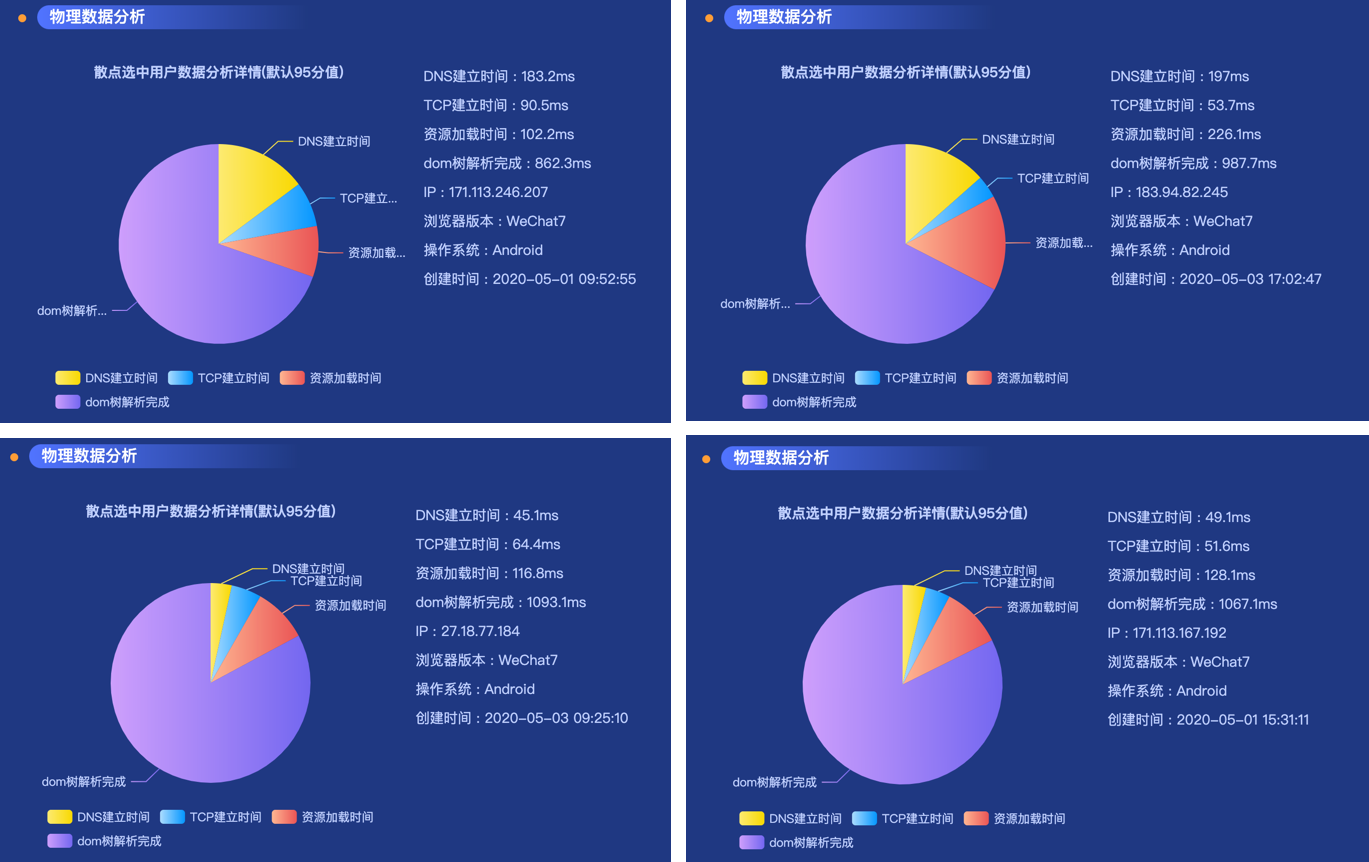
大致看一些数据,我们可以看到,dom树解析完成的耗时居然持续在800+,甚至超过了1s,这太反常了。

看一下对应的95值瀑布流,DOM处理时间中,进入可交互/解析完毕的时间,居然都达到了987ms,完全不符合我的预期。
那么,我只能说,80KiB的表象,让我对自己对系统充满自信,认为无论如何,都不可能会低的秒开率,也就是我对秒开率的计算,太过于浮于表面了。
深入分析,损耗究竟在哪里?
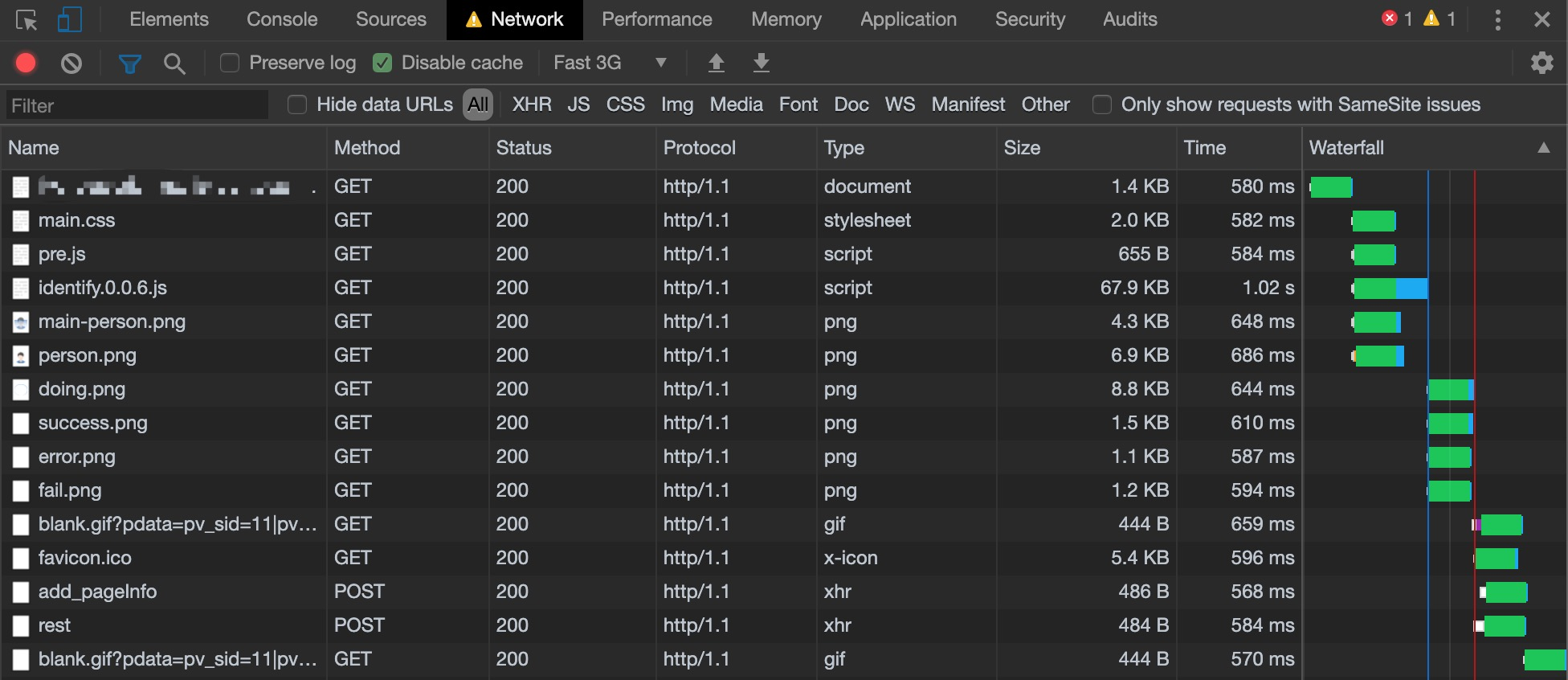
首先,打开Fast3G模式,然后看一下瀑布流的数据。发现,这个绿色的区域很多,随便点一个详细看一下

绿色的区域是TTFB耗时,(挠头)
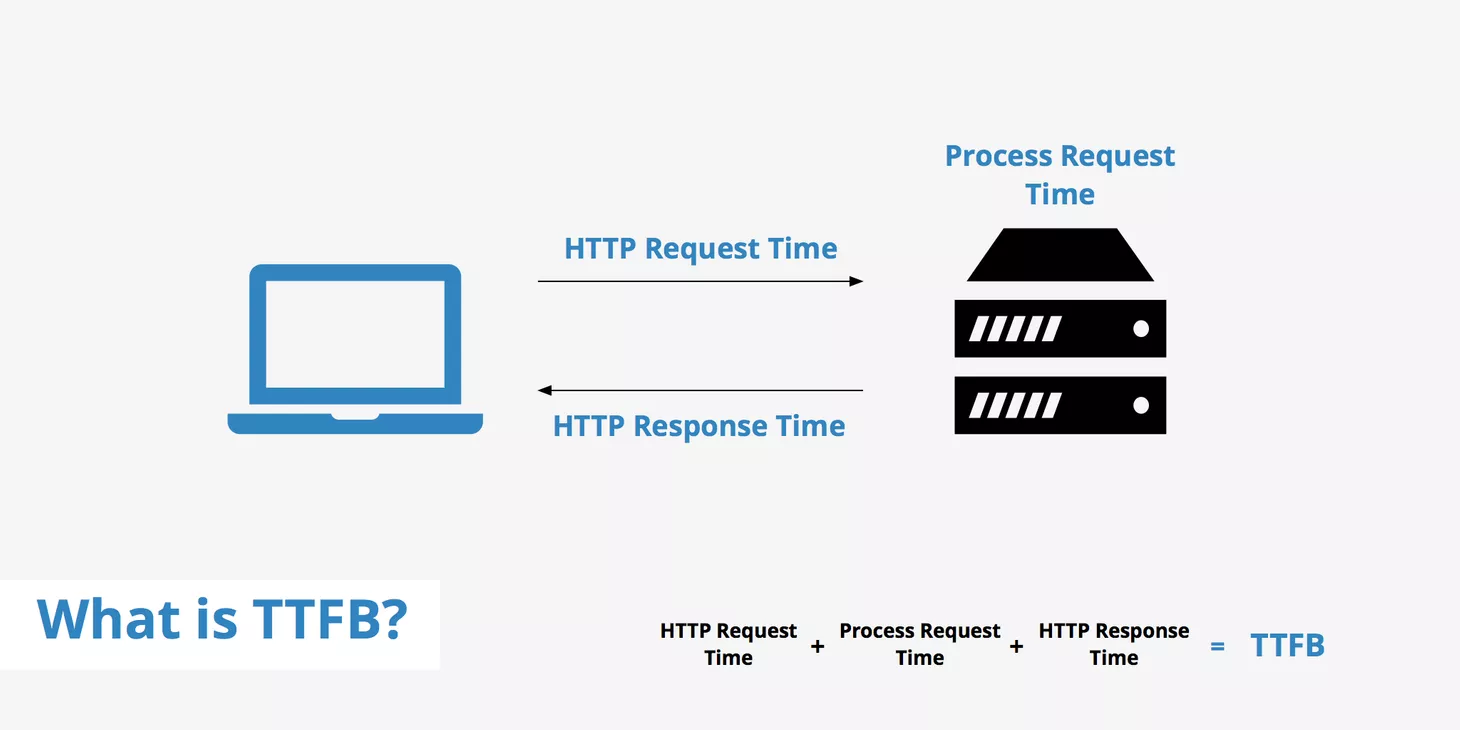
TTFB代表到第一个字节的时间,是从客户端发出HTTP请求到从Web服务器接收其第一个数据字节所花费的时间。 TTFB是网站优化的重要方面,因为TTFB越快,请求的资源就可以开始被更快地传递到浏览器。
什么会导致ttfb的耗时会如此之久?
- 动态内容的创建
- 网络问题
- 配置不良的Web服务器
- 服务器容量问题(磁盘I / O,RAM,网络瓶颈)
- 数据库配置/设计
这些与我前端有何关系?我只是个低贱的小前端啊!
回到我们的瀑布流里,假设我们的网络、服务器无法调整的前提下,我们应该对请求进行有效的控制,瀑布流里很多资源的请求都是图片,那么可以讲图片以base64的形式,插入页面里,虽然单页面的大小增大,但是相对于ttfb的耗时,大小上的损耗是完全可以承受的代价。因此,我决定把这些图片合成到页面里,降低建立连接的耗时。
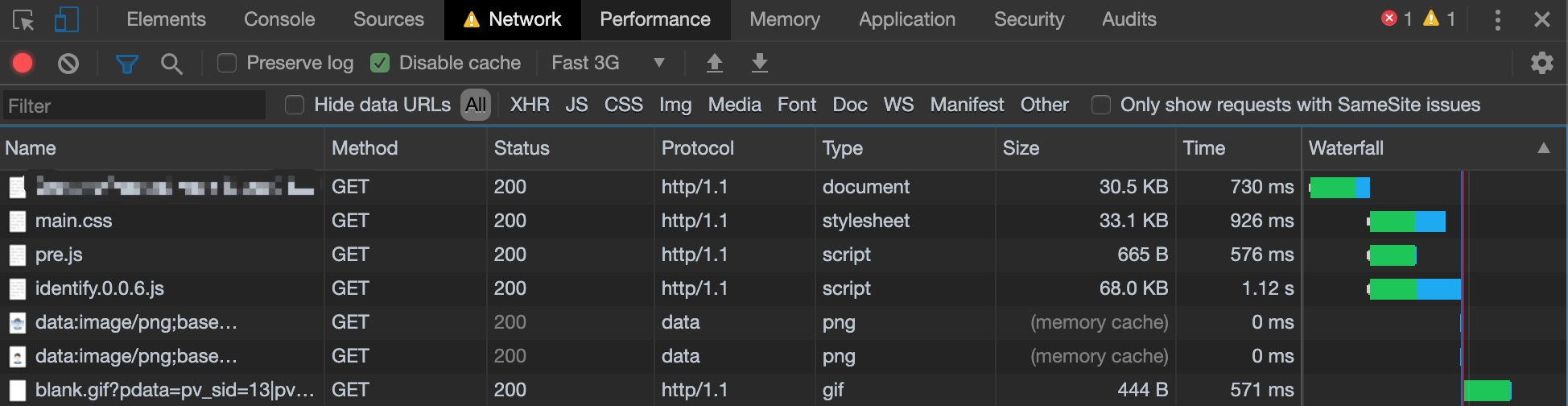
对比之前的数据,虽然html和css都增大了30KiB左右的大小,但是总耗时,降低了很多,但是html因为也有一些图片被替换成了base64所以相对而言也增大了一些,那么再调整一下。
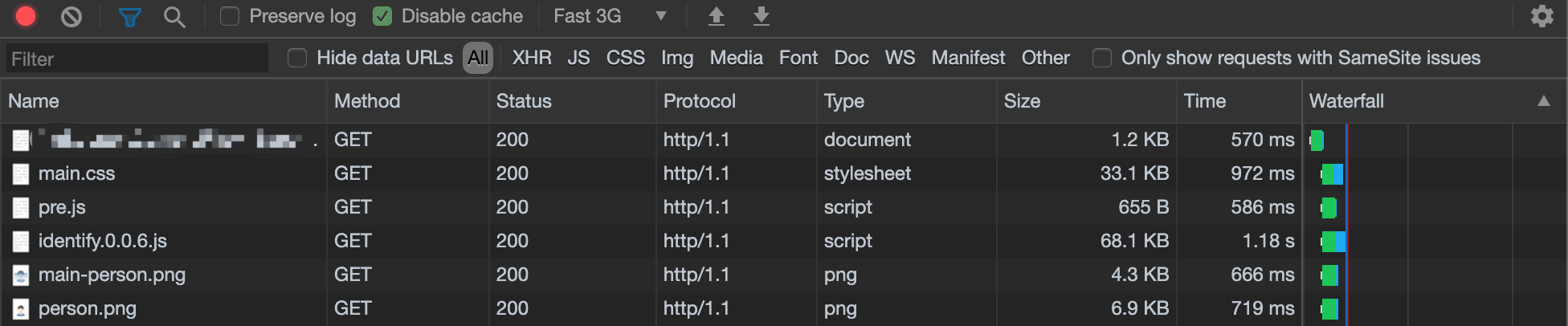
借助于Chrome允许并发数量在6个的情况下,我把html里的用到的2个图片改为url的形式,因为js的耗时一定会超过其他的前提下,进行了定制化优化。
成果
在Fast3G模式下,成果的将白屏耗时从2244ms降低到1850ms,又降低到1750ms,综合来说,降低了22%的网络损耗。
结束语
优化是一门细致的技术活,很多地方都会体现技术含量,一个简单的ttfb的概念,都可以引发如此的分析,所以,性能优化,道阻且长。
