

翻译自Eli Bendersky的系列博客,已获得原作者授权。
本文是系列文章中的第一部分,本系列文章旨在介绍Raft分布式一致性协议及其Go语言实现。文章的完整列表如下:
在这一部分,我们会添加持久性和一些优化来完善Raft的基础实现。所有代码已上传到这个目录。
持久性
类似Raft这样的一致性算法的目标,就是通过在独立的服务器之间复制任务来创建一个更具高可用性的系统。在此之前,我们主要关注的是网络分区的故障,也就是集群中一些服务器与其它服务器(或客户端)断开了连接。还有另一种失败模式就是崩溃,也就是一台服务器停止工作并重启。
对于其它服务器,这看起来很像网络分区——服务器暂时断开连接,但是对于崩溃服务器自身来说,情况就完全不同了,因为重启之后其内部所有的易失性存储状态都丢失了。
正是由于这个原因,Raft论文中的图2中清楚地标注了哪些状态应该持久化,持久化的状态在每次更新的时候都需要刷新到非易失性存储中。在服务器发起下一次RPC或响应正在进行的RPC之前,所有需要持久化的状态都需要保存好。
Raft可以通过仅持久化其状态的一个子集来实现,也就是:
currentTerm- 此服务器观察到的最新任期votedFor- 在最新任期中,此服务器投赞同票的服务器IDlog- Raft日志条目
Q:为什么commitIndex和lastApplied是易失性的?
A:commitIndex字段是易失性的,因为在重启之后,Raft只根据持久化状态就可以得到正确的值。一旦领导者成功提交了一条新指令,它也就知道在此之前的所有指令都已经提交了。如果一个追随者崩溃又重新接入集群中,当前领导者向其发送AE请求时,会告诉其正确的commitIndex。
重启之后,lastApplied是从0开始的,因为基本的Raft算法假定了服务(如键-值数据库)不会保存任何持久化状态。因此,需要通过重放日志条目来重新创建它的状态。当然,这是相当低效的,也有很多可行的优化方法。Raft支持在日志变大时对其进行快照,这在Raft论文的第6章节有描述,不过这也超出了本系列的讨论范围。
指令传递语义
在Raft中,根据不同情况,一条指令会多次发给客户端。有几种场景会出现这样的情况,包括崩溃和重启(重放日志恢复服务)。
在消息传递语义方面,Raft站在至少一次阵营。一旦一条指令被呈递,它最终会被复制给所有的客户端,但是有些客户端可能会多次看到同一条指令。
因此,建议指令需要携带唯一的ID,而客户端要忽略已经收到的指令。这个在Raft论文的第8节有更详细的描述。
存储接口
为了实现持久性,我们在代码中添加了如下的接口:
type Storage interface {
Set(key string, value []byte)
Get(key string) ([]byte, bool)
// HasData returns true if any Sets were made on this Storage.
HasData() bool
}
你可以将它看作是字符串到通用字节切片的映射,由持久性存储实现。
恢复和保存状态
现在CM构造函数要接受Storage作为参数并进行调用:
if cm.storage.HasData() {
cm.restoreFromStorage(cm.storage)
}
这里的restoreFromStorage方法也是新加的,该方法会从存储中加载持久化的状态变量,使用标准的encoding/go包对其进行反序列化:
func (cm *ConsensusModule) restoreFromStorage(storage Storage) {
if termData, found := cm.storage.Get("currentTerm"); found {
d := gob.NewDecoder(bytes.NewBuffer(termData))
if err := d.Decode(&cm.currentTerm); err != nil {
log.Fatal(err)
}
} else {
log.Fatal("currentTerm not found in storage")
}
if votedData, found := cm.storage.Get("votedFor"); found {
d := gob.NewDecoder(bytes.NewBuffer(votedData))
if err := d.Decode(&cm.votedFor); err != nil {
log.Fatal(err)
}
} else {
log.Fatal("votedFor not found in storage")
}
if logData, found := cm.storage.Get("log"); found {
d := gob.NewDecoder(bytes.NewBuffer(logData))
if err := d.Decode(&cm.log); err != nil {
log.Fatal(err)
}
} else {
log.Fatal("log not found in storage")
}
}
镜像方法是persistToStorage——将所有的状态变量编码并保存到提供的存储介质中。
func (cm *ConsensusModule) persistToStorage() {
var termData bytes.Buffer
if err := gob.NewEncoder(&termData).Encode(cm.currentTerm); err != nil {
log.Fatal(err)
}
cm.storage.Set("currentTerm", termData.Bytes())
var votedData bytes.Buffer
if err := gob.NewEncoder(&votedData).Encode(cm.votedFor); err != nil {
log.Fatal(err)
}
cm.storage.Set("votedFor", votedData.Bytes())
var logData bytes.Buffer
if err := gob.NewEncoder(&logData).Encode(cm.log); err != nil {
log.Fatal(err)
}
cm.storage.Set("log", logData.Bytes())
}
我们只需要在这些状态值每次变化时都调用pesistToStorage方法即可实现持久化。如果你比对一下第二部分和本部分的CM代码,就能看的该方法的调用散步在少数几个地方。
当然,这并不是最有效的持久化方式,但是它简单有效,因此也可以满足我们的需要。效率最低的部分是保存整个日志,日志在实际的应用中可能会很大。为了真正解决整个问题,Raft论文的第7节提出了一个日志压缩机制。我们不会实现压缩,但是可以将其作为联系添加到已有的实现中。
崩溃恢复
实现持久性之后,我们的Raft集群可以在一定程度上应对崩溃。只要是集群中的少数服务器崩溃并在之后的某个时间重启,集群对于客户端都是一直可用的(如果领导者是崩溃的服务器之一,可能还需要等集群选举出新的领导者)。提醒一下,拥有2N+1个服务器的集群可以容忍N台服务器出现故障,并且只要其它N+1台机器保持互连,集群就是一直可用的。
不可靠的RPC传递
我们在这一部分加强了测试,我想提醒您注意关于系统弹性的另一个方面——不可靠的RPC传递。在此之前,我们都假设在连接的服务器之间的RPC请求都会成功到达,可能会有很小的延时。如果你看一下server.go,你会注意到其中使用了一个RPCProxy类型来实现随机延迟。每个RPC请求会延迟1-5ms,以模拟真实世界中同一数据中心的同伴服务器通信延时。
RPCProxy还帮助我们实现了可选的不可靠传递。如果启动了RAFT_UNRELIABLE_RPC系统变量,RPC会偶尔出现明显的延迟(75ms)或者被直接丢弃,用于模拟真实世界中的网络故障。
我们可以设置RAFT_UNRELIABLE_RPC之后运行之前的测试,观察Raft集群在出现这些故障时的行为——另一个强烈推荐的练习。如果您学有余力,可以修改一下RPCProxy,对RPC应答也进行延迟,这应该只需要改几行代码。
优化发送AE
我在第二部分提到过,目前领导者的实现效率很低。领导者在leaderSendHeartbeats方法中发送AE请求,而该方法由定时器每50ms触发一次。假设有一天新的指令被呈递,领导者不会立即通知所有的追随者,而是等待下一个50ms的触发。更糟糕的是,要通知追随者某条指令被提交需要通过两次AE请求。下图展示了目前的工作流程:
tries-50ms-boundary.png)
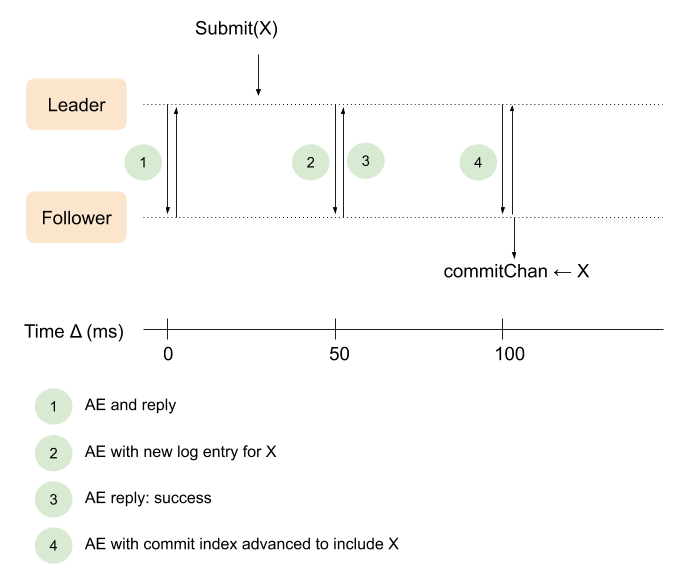
之后有一条新指令被提交(假设是35ms后)。
领导者等到下一个50ms计时结束,也就是时刻2再向追随者发送更新后的日志。
在时刻3,追随者回复指令已经成功添加到本地的日志中。此时,领导者已经修改了它的commit index(假定已得到多数服务器确认)并可以立即通知追随者。但是,领导者一直等到下一个50ms边界(时刻4)才这样做。
最后,当追随者收到更新后的leaderCommit时,将最新的提交指令通知到客户端。
我们的实现中,领导者Submit(X)和追随者commitChan <-X之间等待的大部分时间都是不必要的。
我们真正想要的执行顺利应该像下面这样:
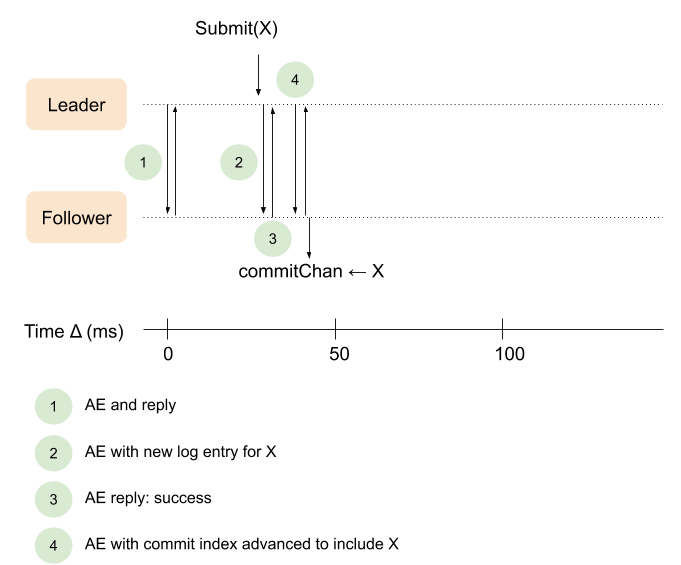
这正是本部分代码所做的。我们先从startLeader开始看一下实现中的新代码:
func (cm *ConsensusModule) startLeader() {
cm.state = Leader
for _, peerId := range cm.peerIds {
cm.nextIndex[peerId] = len(cm.log)
cm.matchIndex[peerId] = -1
}
cm.dlog("becomes Leader; term=%d, nextIndex=%v, matchIndex=%v; log=%v", cm.currentTerm, cm.nextIndex, cm.matchIndex, cm.log)
/*********以下代码是新增部分********/
/*
该goroutine在后台运行并向同伴服务器发送AE请求:
- triggerAEChan通道发送任何内容时
- 如果triggerAEChan通道没有内容时,每50ms执行一次
*/
go func(heartbeatTimeout time.Duration) {
// Immediately send AEs to peers.
cm.leaderSendAEs()
t := time.NewTimer(heartbeatTimeout)
defer t.Stop()
for {
doSend := false
select {
case <-t.C:
doSend = true
// Reset timer to fire again after heartbeatTimeout.
t.Stop()
t.Reset(heartbeatTimeout)
case _, ok := <-cm.triggerAEChan:
if ok {
doSend = true
} else {
return
}
// Reset timer for heartbeatTimeout.
if !t.Stop() {
<-t.C
}
t.Reset(heartbeatTimeout)
}
if doSend {
cm.mu.Lock()
if cm.state != Leader {
cm.mu.Unlock()
return
}
cm.mu.Unlock()
cm.leaderSendAEs()
}
}
}(50 * time.Millisecond)
}
startLeader方法中的循环不只是等待50ms的触发器,而且等待两种可能的情况之一:
cm.triggerAEChan通道上的数据发送- 50ms的定时器计时结束
我们稍后会看到是什么触发了cm.triggerAEChan,这个信号表示现在要发送一条AE请求。无论何时触发该通道,定时器都会重置,从而实现心跳逻辑——如果领导者没有新信息需要发送,最多会等待50ms。
还要注意,真正发送AE请求的方法名改为了leaderSendAEs,以便更好地反映新代码的设计意图。
如我们所料,触发cm.triggerAEChan的方法之一 就是Submit:
func (cm *ConsensusModule) Submit(command interface{}) bool {
cm.mu.Lock()
cm.dlog("Submit received by %v: %v", cm.state, command)
if cm.state == Leader {
cm.log = append(cm.log, LogEntry{Command: command, Term: cm.currentTerm})
cm.persistToStorage()
cm.dlog("... log=%v", cm.log)
cm.mu.Unlock()
cm.triggerAEChan <- struct{}{}
return true
}
cm.mu.Unlock()
return false
}
更改如下:
- 每当收到新指令时,调用
cm.persistToStorage对新的日志条目进行持久化。这与心跳请求的优化无关,但是我还是要在这里说明一下,因为第2部分的代码没有实现该功能,而且该功能是在本文的前面描述的。 - 在
cm.persistToStorage上发送空结构体。这会通知领导者goroutine中的循环。 - 锁处理顺序做了轻微调整。我们不想在使用
cm.persistToStorage发送数据时持有锁,因为在某些情况下会导致死锁。
你能猜到代码中还有什么地方会通知triggerAEChan吗?
就是在领导者处理AE应答并修改commit index的代码中,我这里就不贴出整个方法,只复制了修改的部分:
if cm.commitIndex != savedCommitIndex {
cm.dlog("leader sets commitIndex := %d", cm.commitIndex)
// Commit index改变:表明领导者认为新指令可以被提交了。
// 通过commit channel向领导者的客户端发送新指令。
// 发送AE请求通知所有的追随者
cm.newCommitReadyChan <- struct{}{}
cm.triggerAEChan <- struct{}{}
}
这是一个重要的优化,可以让我们的代码对新指令的响应速度更快。
批量化指令提交
上一节中的代码看起来可能会让你有些不舒服,现在有很多行为是每次调用Submit时触发的——领导者立即向追随者广播RPC请求。如果我们一次提交多条命令时会怎样?连接Raft集群的网络可能被RPC请求淹没。
尽管看起来效率低下,但实际上是安全的。Raft的RPC请求都是幂等的,意味着多次收到包含相同信息的RPC请求不会造成什么危害。
如果你担心同时提交多条指令时导致的网络拥塞,批处理是很容易实现的。最简单的方法就是提供一种将整个指令片段发送给Submit的方式。因此,Raft实现中只有很少的代码需要修改,然后客户端就可以呈递一组指令而不会产生太多RPC通信。作为练习试试看!
优化AE冲突解决
我想在这篇文章中讨论的另一个优化,是在一些场景中减少领导者更新追随者日志时被拒绝的AE请求数量。回想一下,nextIndex机制从日志的尾端开始,并且每次追随者拒绝AE请求时都减1。在极少数情况下,追随者会出现严重过时,因为每次RPC请求只会回退一条指令索引,所以更新该追随者日志会花费很长时间。
论文在5.3节的最后提到了这种优化,但是没有提供任何的实现细节。为了实现它,我们在AE应答中扩展了新的字段:
type AppendEntriesReply struct {
Term int
Success bool
// Faster conflict resolution optimization (described near the end of section
// 5.3 in the paper.)
ConflictIndex int
ConflictTerm int
}
你可以在本部分的代码中看到其它改动。有两个地方做了改动:
AppendEntries是AE请求处理方法,当追随者拒绝AE请求时,会填入ConflictIndex和ConflictTerm。leaderSendAEs方法在收到AE应答时进行更新,并通过ConflictIndex和ConflictTerm更有效地回溯nextIndex。
Raft论文中写:
在实践中,我们怀疑这种优化是否必要,因为失败很少发生,而且不大可能有很多不一致的条目。
我完全同意。为了测试这个优化点,我不得不想出一个相当刻意的测试。恕我直言,在现实生活中出现这种情况的概率非常低,而且一次性节省几百ms并不能保证代码复杂度。我在这里只是将它作为Raft中特殊情况下的优化案例之一。就编程而言,这是一个很好的例子,说明在某些特定情况下,可以对Raft算法进行轻微修改来调整其行为逻辑。
Raft的设计意图是保证在普通情况下有相当快的处理速度,并且以牺牲特殊情况下的性能为代价(实际发生故障的情况)。我相信这是绝对正确的设计选择。在上一节中说到的快速发送AE请求优化是很有必要的,因为这会直接影响公共路径。
另一方面,像快速回溯冲突索引这样的优化,虽然在技术上很有趣,但是在实践中并不重要,因为它们只是在集群生命周期中出现时间<0.01%的特殊场景中做出了有限的优化。
总结
至此,我们结束了有关Raft分布式一致性算法的4篇文章,感谢阅读!
如果您对于文章内容或代码有任何问题,可以给我发送邮件或者在Github发布issue。
如果您对工业级、有实战经验的Raft实现感兴趣,我向您推荐:
- etcd/raft是分布式键值数据库etcd中的Raft模块。
- hashicorp/raft是一个独立的Raft一致性模块,可以帮到到不同的客户端。
它们都实现了Raft论文中的所有特性,包括:
- Section 6: 集群成员关系变动——如果一台Raft服务器永久离线,在不关闭集群的情况下使用另一台服务器对其替换是很实用的。
- Section 7:日志压缩——在实际的应用程序中,日志会变得非常大,每次修改都完全持久化日志或者在崩溃时完全重放日志都是很不切实际的。日志压缩定义了一种检查点机制,该机制使得集群可以有效复制非常大的日志。
