

多层感知器(MLP)是一种非常简单的神经网络,(我个人觉得就是除了循环神经网络,卷积神经网络网络以外,什么特别功能都没有的全连接神经网络,非常普通)
接下来我们看一个最简单的MLP结构:
最简单的MLP是三层结构(输入层-隐藏层-输出层),如下图所示:

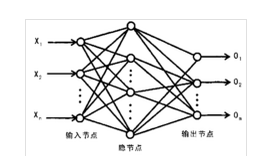
多层感知机的层与层之间是全连接的,即每一层的任意一个神经元均与其前一层的所有神经元有连接,这种连接其实代表了一种权重加和。
例如:
从输入层到隐藏层:我们用X代表输入,H代表隐藏层,则H=f(W1X + B1),其中W1代表权重,B1代表偏置,函数f通常是非线性的,叫做激活函数。
常见的激活函数有:Sigmoid(S型激活函数,将输入映射到一个0到1之间的值,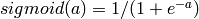 )
)
)tanh(双曲正切函数,将输入映射到一个-1到1之间的值,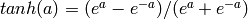 )
)
)ReLU(近似生物神经激活函数,它的函数形式是f(x)=max(0,x))
Softmax(在多分类中常用的激活函数,是基于逻辑回归的。P(i)=exp(θTix)∑Kk=1exp(θTkx) )
从隐藏层到输出层:我们用Y代表输出,则Y=G(W2H + B2),其中W2和B2均为训练参数。函数G是激活函数,常见的有Softmax(用于多分类)
这样,我们就得到了一个从输入到输出的关系,我们最终就是通过监督学习方法求得W1、B1、W2、B2。通常利用反向传播算法(BP)和最优化算法对权重更新,迭代更新参数,直至满足某个条件为止。
由于deep learning框架我经常使用的Keras,所以就以Keras为例,让我们具体来看一下在Keras里面如何实现MLP:
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,DIM), dtype='int32')
- dense_1 = Dense(100,activation='tanh')(sequence_input)
- dense_2 = Dense(2, activation='softmax')(dense_1)
- max_pooling = GlobalMaxPooling1D()(dense_2)
- model = Model(sequence_input, dense_2)
更多免费技术资料可关注:annalin1203
