

本文以Elasticsearch 6.8.4版本为例,介绍Elasticsearch嵌套文档的使用。

最近一段时间都在搞Elasticsearch搜索相关的工作,总结一下搜索知识点供大家参考。
在Elasticsearch取消了多个索引内创建多个type的机制,由于场景需要,所以调研了嵌套文档和父子文档
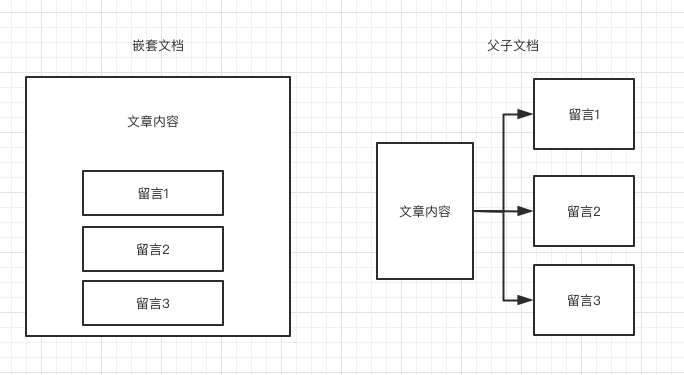
以文章和文章留言为例,嵌套文档都在一个文档内,而父子文档则分开存储了父文档与子文档,本文我们来学习嵌套文档的使用。
1、嵌套文档
嵌套文档看似与文档内有一个集合字段类似,但是实则有很大区别,以上面图中嵌套文档为例,留言1,留言2,留言3虽然都在当前文章所在的文档内,但是在内部其实存储为4个独立文档,如下图所示。
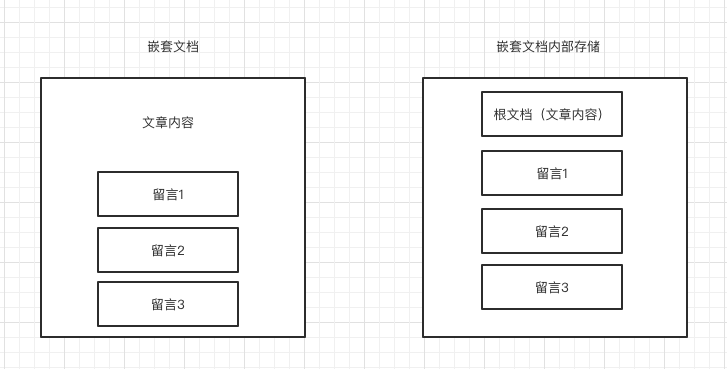
同时,嵌套文档的字段类型需要设置为nested,设置成nested后的不能被直接查询,需要使用nested查询,这里不做具体介绍,详细查看1.2。
1.1 创建索引
接下来,介绍一下如何创建嵌套文档索引,比如有这样的数据,如下:
{
"title": "这是一篇文章",
"body": "这是一篇文章,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-05-04"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-05-04"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-05-01"
}
]
}
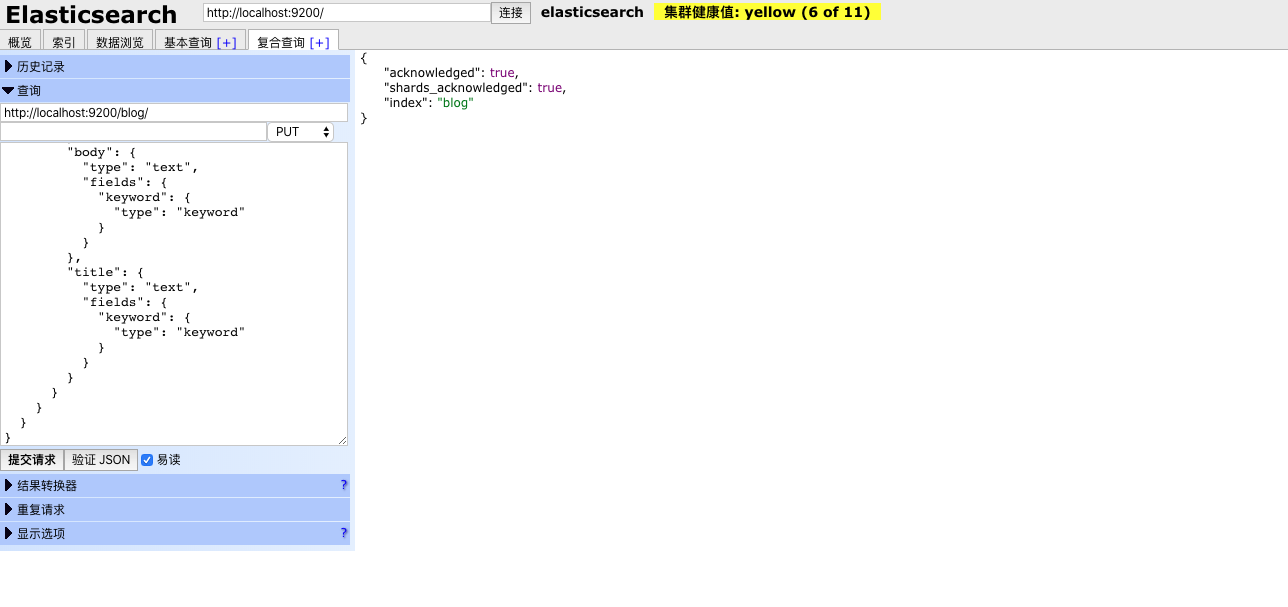
创建索引名和type均为blog的索引,其中comments字段为嵌套文档类型,需要将type设置为nested,其余都是一些正常的字段,创建索引语句如下:
PUT http://localhost:9200/blog/
{
"mappings": {
"blog": {
"properties": {
"comments": {
"type": "nested",
"properties": {
"date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"comment": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"age": {
"type": "long"
}
}
},
"body": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
}
如下图所示
1.2 插入数据
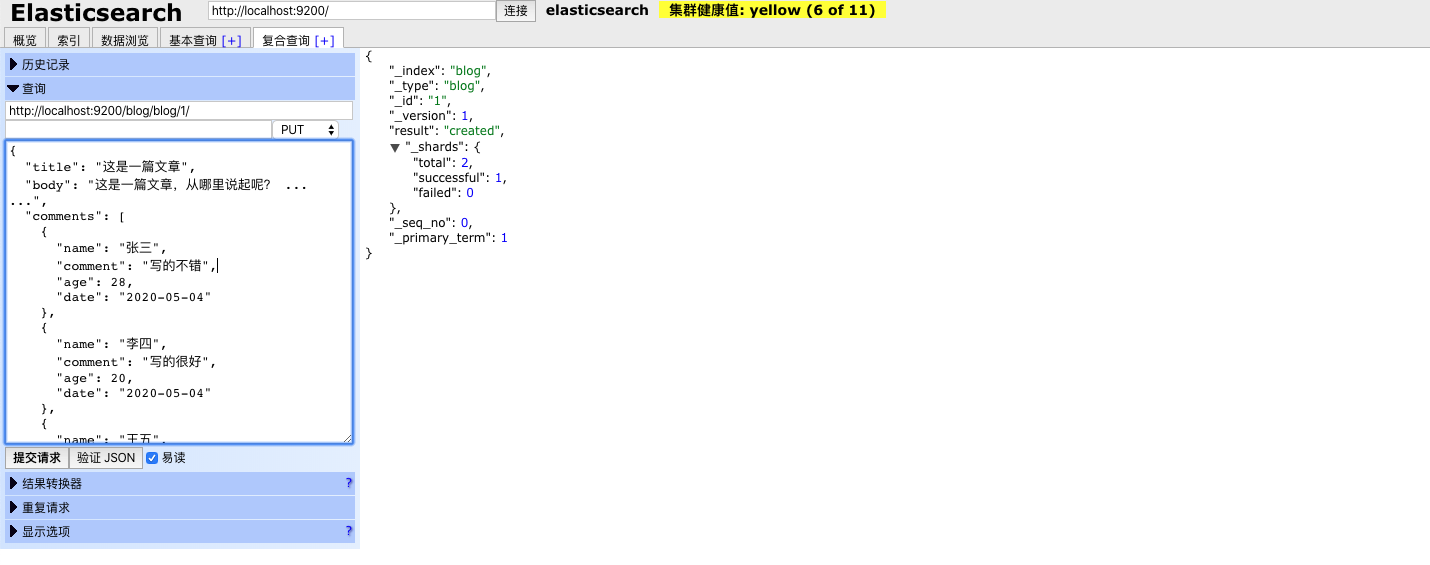
将1.1中示例的数据插入blog索引,对嵌套文档来说,插入没什么特别的,如下:
PUT http://localhost:9200/blog/blog/1/
{
"title":"这是一篇文章",
"body":"这是一篇文章,从哪里说起呢? ... ...",
"comments":[
{
"name":"张三",
"comment":"写的不错",
"age":28,
"date":"2020-05-04"
},
{
"name":"李四",
"comment":"写的很好",
"age":20,
"date":"2020-05-04"
},
{
"name":"王五",
"comment":"这是一篇非常棒的文章",
"age":31,
"date":"2020-05-01"
}
]
}
如图所示:
1.3 查询
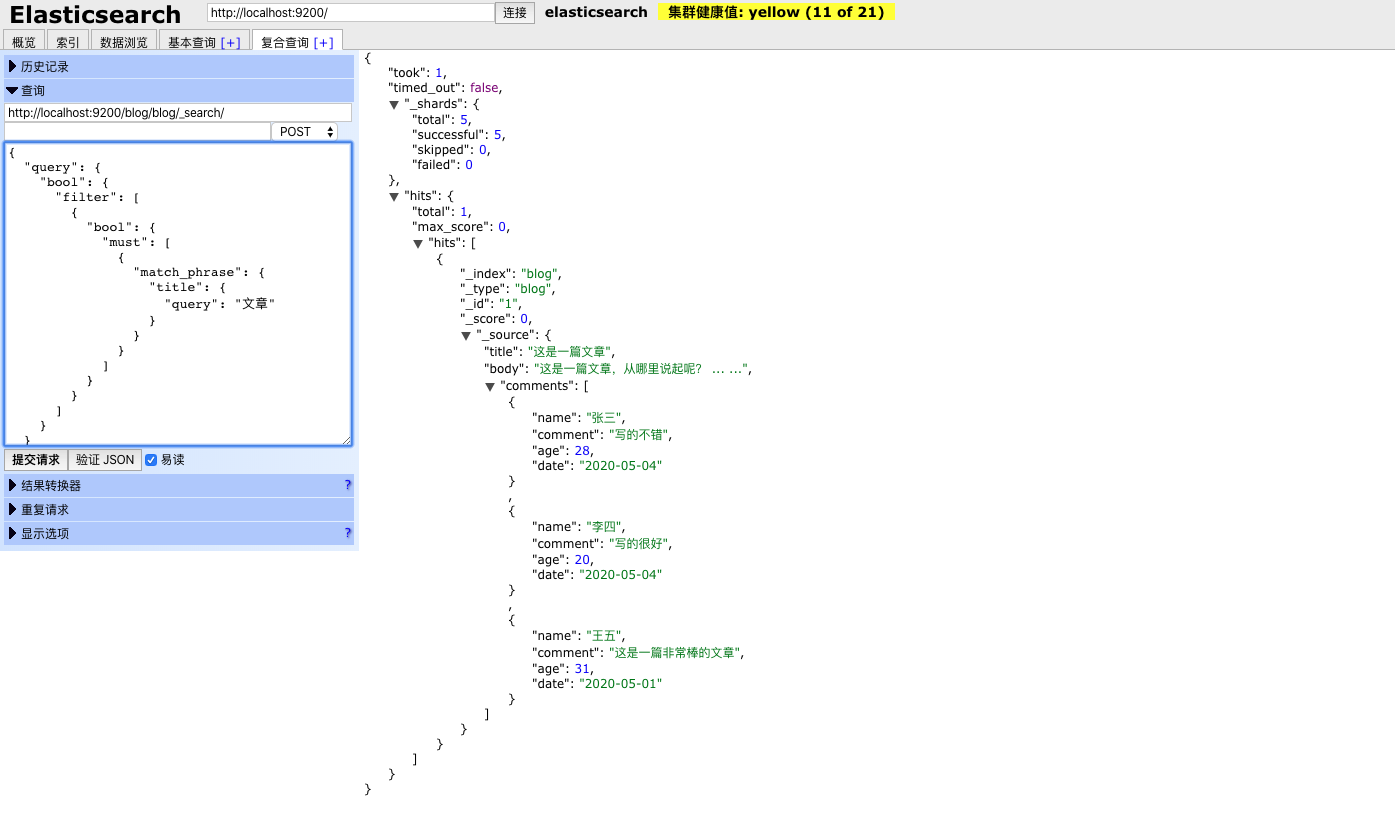
在前面说到,使用嵌套文档时,直接查询nested文档时查询不到的,这里试一下,先查询一下根文档的内容(文章内容),查询title包含‘文章’的内容:
POST http://localhost:9200/blog/blog/_search/
{
"query": {
"bool": {
"filter": [
{
"bool": {
"must": [
{
"match_phrase": {
"title": {
"query": "文章"
}
}
}
]
}
}
]
}
}
}
Elasticsearch-Head,如下图所示
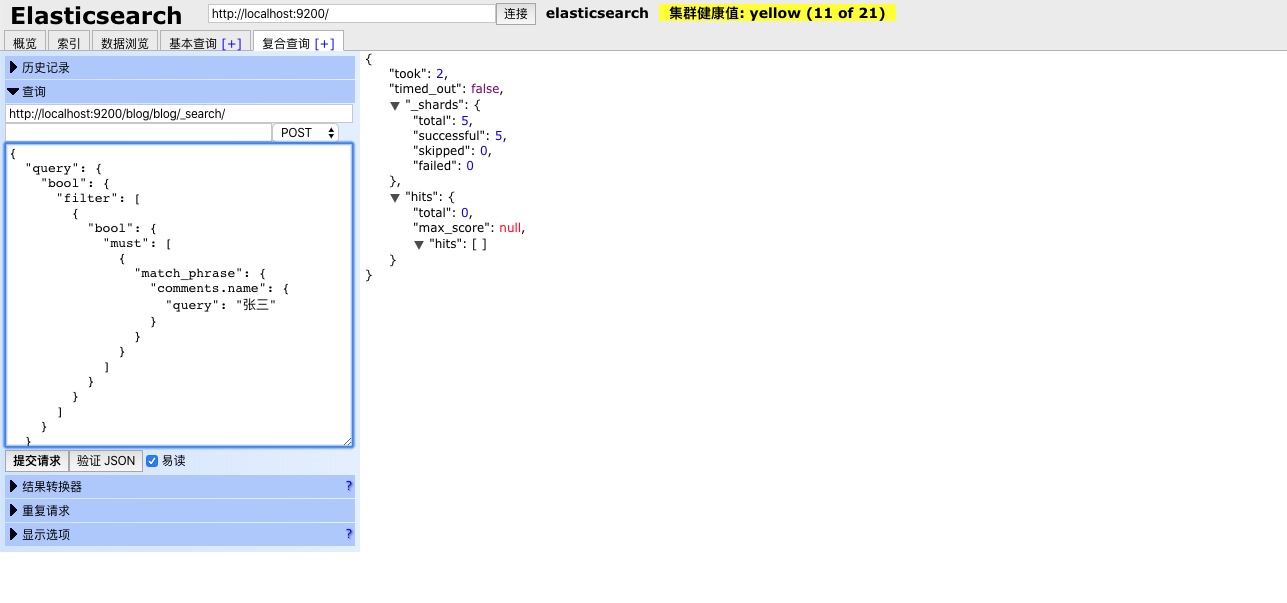
接下来我们查询一下,留言中name为张三的数据,查询如下:
{
"query": {
"bool": {
"filter": [
{
"bool": {
"must": [
{
"match_phrase": {
"comments.name": {
"query": "张三"
}
}
}
]
}
}
]
}
}
}
Elasticsearch-Head 如下图所示
这里举例,我们要查询title中包含‘文章’且留言name中包含‘张三’的数据,使用如下查询:
POST http://localhost:9200/blog/blog/_search/
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "文章"
}
},
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "张三"
}
}
]
}
}
}
}
]
}
}
}
Elasticsearch-Head 如下图所示
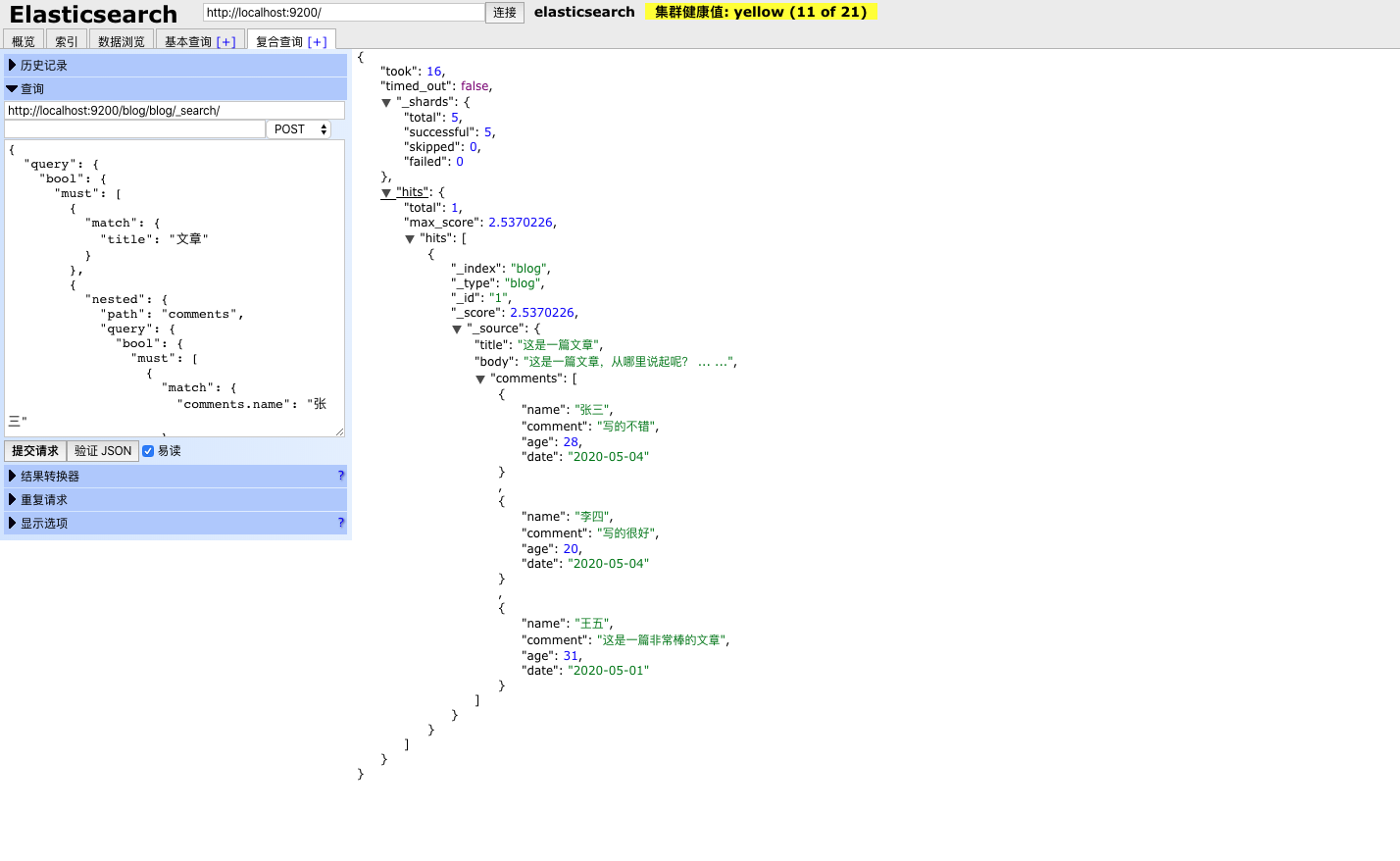
其实从查询语句中可以看出,nested中查询的是嵌套文档的内容,语法与正常查询时一致。
使用嵌套文档时,文档的分数计算需要注意,参考官方文档的描述:
nested 查询肯定可以匹配到多个嵌套的文档。每一个匹配的嵌套文档都有自己的相关度得分,但是这众多的分数最终需要汇聚为可供根文档使用的一个分数。
默认情况下,根文档的分数是这些嵌套文档分数的平均值。可以通过设置 score_mode 参数来控制这个得分策略,相关策略有 avg (平均值), max (最大值), sum (加和) 和 none (直接返回 1.0 常数值分数)。
1.4 排序
可能有一些场景需要按照嵌套文档的字段记性排序,举例:
为了符合上述场景,新增两条数据:
PUT http://localhost:9200/blog/blog/2/
{
"title": "这是一篇文章2",
"body": "这是一篇文章2,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-05-11"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-05-16"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-05-01"
}
]
}
PUT http://localhost:9200/blog/blog/3/
{
"title": "这是一篇文章3",
"body": "这是一篇文章3,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-05-03"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-05-20"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-05-01"
}
]
}
查询title中包含‘文章’且留言name中包含‘张三’,并且按照留言date字段倒序排序,查询语句如下:
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "文章"
}
},
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "张三"
}
}
]
}
}
}
}
]
}
},
"sort": {
"comments.date": {
"order": "desc",
"mode": "max",
"nested_path": "comments",
"nested_filter": {
"bool": {
"must": [
{
"match": {
"comments.name": "张三"
}
}
]
}
}
}
}
}
需要注意的是,在sort内,又添加了nested_filter来过滤一遍上面嵌套文档的查询条件,原因是这样的,在嵌套文档查询排序时是先按照条件进行查询,查询后再进行排序,那么可能由于数据的原因,导致排序的字段不是按照匹配上的数据进行排序,比如这是本文正确的结果,如下图所示(为了方便查看,使用图表展示的数据)。
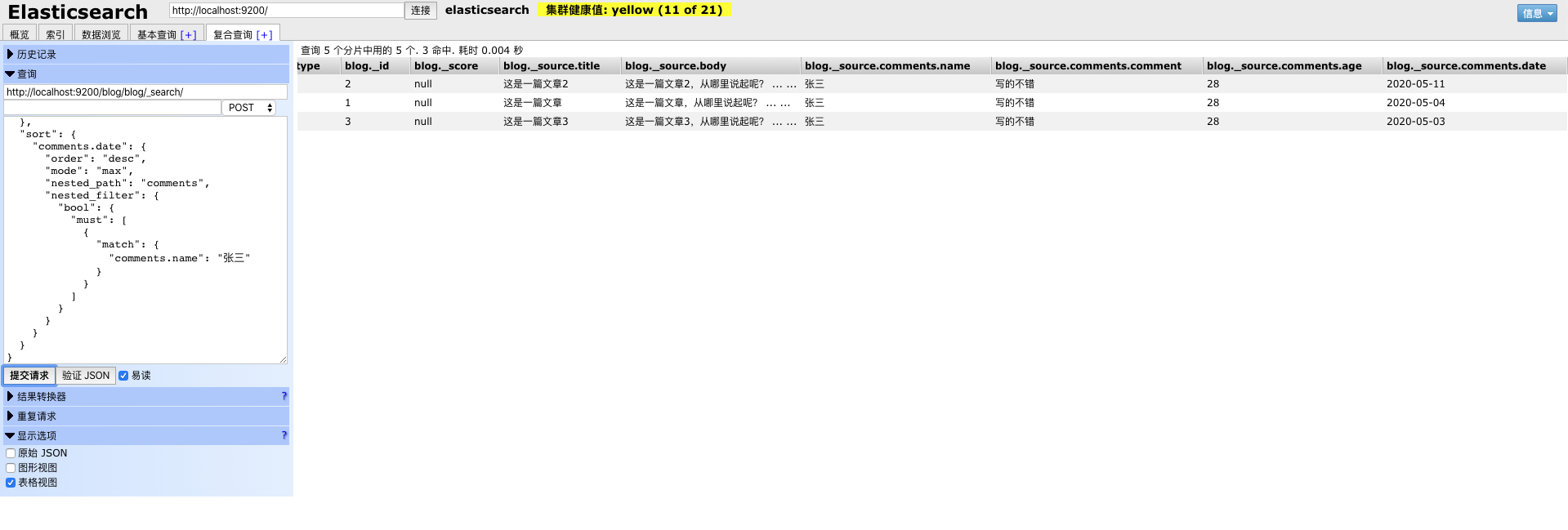
如果我们去掉nested_filter,在查询,由于文章3中李四评论的日期是20号,导致这条记录排在了最前面,这就是为什么使用nested_filter的原因,查询结果如下:
1.5 聚合
聚合的场景可能也比较常见,其实熟悉上面嵌套文档的使用的话,对聚合文档使用难度应该也不大,
新增一条数据:
PUT http://localhost:9200/blog/blog/4/
{
"title": "这是一篇文章4",
"body": "这是一篇文章4,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-03-03"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-04-20"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-06-01"
}
]
}
举例:需要查询每个月评论人数的平均数,查询语句如下:
POST http://localhost:9200/blog/blog/_search/
{
"size": 0,
"aggs": {
"comments": {
"nested": {
"path": "comments"
},
"aggs": {
"by_month": {
"date_histogram": {
"field": "comments.date",
"interval": "month",
"format": "yyyy-MM"
},
"aggs": {
"avg_stars": {
"avg": {
"field": "comments.age"
}
}
}
}
}
}
}
}
结果如下图所示:
1.6 使用建议
- 正如本文所说,嵌套文档中,所有内容都在同一个文档内,这就导致嵌套文档进行增加、修改或者删除时,整个文档都要重新被索引。嵌套文档越多,这带来的成本就越大。当时就是由于这个原因,最终没有选择使用嵌套文档。
- 嵌套文档的分数计算问题需要注意,可以参考本文1.3最后部分。
