

在大数据系列第一篇的时候,搭建hdfs高可用集群的时候,讲到了一个技术点,对于Java和大数据的应用都会非常的受欢迎,尤其是在面试的时候,对的,可能有的朋友已经猜到了,对的,就是分布式协调服务--zookeeper
对于zookeeper,他是apache基金下的一个重要组成项目,而ZooKeeper是一个典型的 分布式数据一致性的 解决方案。分布式应用程序可以基于它实现诸如 数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
可能这么说还有人听不懂,没关系,来一个生活中的实例,每一个专业的技术总可以在生活中找到相应的实例,就比如说zookeeper,攘其外必先安其内就很好的解释了zookeeper,相信大家都经历过这样一件事,选举班长,每一次新学期开始的时候,都会选举一个班级的管理者,班长,之后班级相应的事务就由班长进行通知和管理,对吧,我们在选举班长的时候,都会遵循一个准则,少数服从多数,zookeeper就是扮演了这样的一个角色,,嘿嘿嘿,有点扯远了,跟题目有点偏离,后面我会在大数据系列中,详细的对zookeeper内部运行流程进行整理,今天,我们的主要概念是上面提到的,zookeeper的一个功能机制,分布式锁
相信做过开发大家都知道,如果我们一台机器上多个不同线程抢占同一个资源,并且如果多次执行会有异常,我们称之为非线程安全。一般,我们为了解决这种问题,通常使用锁来解决,像java语言,我们可以使用synchronized。如果是同一台机器里面不同的java实例,我们可以使用系统的文件读写锁来解决,如果再扩展到不同的机器呢?我们通常用分布式锁来解决。
分布式锁的特点如下:
-
互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
-
可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
-
锁超时:和本地锁一样支持锁超时,防止死锁。
-
高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
-
支持阻塞和非阻塞:和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)。
-
支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。分布式锁。相信大家都遇到过这样的业务场景,我们有一个定时任务需要定时执行,但是这个任务又不是同一段时间执行幂等的,所以我们只能让一台机器一个线程来执行
分布式锁的实现有很多种,常见的有redis,zookeeper,谷歌的chubby等
今天呢?就将两种常见的redis和zookeeper的分布式锁的实现原理和大家共享
简单介绍一下。相信大家这里已经想到了解决方案,那就是每次执行任务的时候,先查询redis里面是否已经有锁的key,如果没有就写入,然后就开始执行任务。
这个看起来很对,不过存在什么问题呢,例如进程A跟进程B同时查询Redis,他们都发现Redis中没有对应的值,然后都开始写入,由于不是带版本读写,两个人都写成功了,都获得了锁。还好,Redis给我们提供原子写入的操作,setnx(SET if Not eXists, 一个命令我们最好把全称也了解一下,有助于我们记住这个命令)。
如果你以为只要这样就完成一个分布式锁,那就太天真了,我们不妨考虑一些极端情况,例如某个线程取到了锁,但是很不幸,这个机器死机了,那么这个锁没有被释放,这个任务永远就不会有人执行了。所以一种比较好的解决方案是,申请锁的时候,预估一个程序的执行时间,然后给锁设置一个超时时间,如果超过这个时间其他人也能取到这个锁。但这又引发另外一个问题,有时候负载很高,任务执行得很慢,结果过了超时时间任务还没执行完,这个时候又起了另外一个任务来执行。
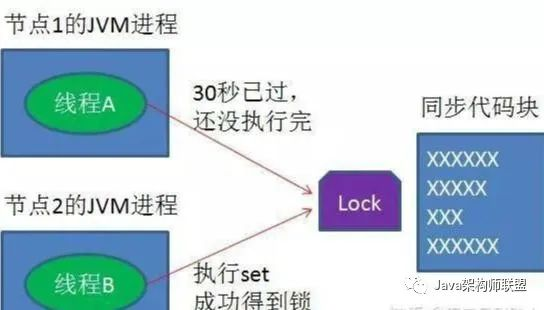
架构设计的魅力正是如此,当你解决一个问题的时候,总会引发一些新的问题,需要逐步攻破逐个解决。这种方法,我们一般可以在抢占到锁之后,就开一个守护线程,定时去redis哪里询问,是不是还是由我抢占着当前的锁,还有多久就要过期,如果发现要过期了,就赶紧续期。
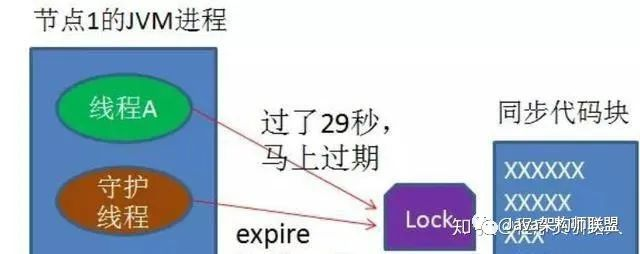
好了,看到这里,相信你已经学会了如何用Redis实现一个分布式锁服务了
Zookeeper 实现分布式锁的示意图如下:
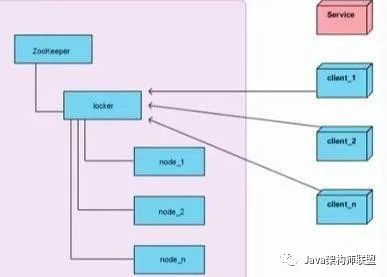
上图中左边是Zookeeper集群, lock是数据节点,node_1到node_n表示一系列的顺序临时节点,右侧client_1到client_n表示要获取锁的客户端。Service是互斥访问的服务。
下面的源码是根据Zookeeper的开源客户端Curator实现分布式锁。采用zk的原生API实现会比较复杂,所以这里就直接用Curator这个轮子,采用Curator的acquire和release两个方法就能实现分布式锁。
import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.framework.recipes.locks.InterProcessMutex;import org.apache.curator.retry.ExponentialBackoffRetry;public class CuratorDistributeLock { public static void main(String[] args) { RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); CuratorFramework client = CuratorFrameworkFactory.newClient("111.231.83.101:2181",retryPolicy); client.start(); CuratorFramework client2 = CuratorFrameworkFactory.newClient("111.231.83.101:2181",retryPolicy); client2.start(); //创建分布式锁, 锁空间的根节点路径为/curator/lock InterProcessMutex mutex = new InterProcessMutex(client,"/curator/lock"); final InterProcessMutex mutex2 = new InterProcessMutex(client2,"/curator/lock"); try { mutex.acquire(); } catch (Exception e) { e.printStackTrace(); } //获得了锁, 进行业务流程 System.out.println("clent Enter mutex"); Thread client2Th = new Thread(new Runnable() { @Override public void run() { try { mutex2.acquire(); System.out.println("client2 Enter mutex"); mutex2.release(); System.out.println("client2 release lock"); }catch (Exception e){ e.printStackTrace(); } } }); client2Th.start(); //完成业务流程, 释放锁 try { Thread.sleep(5000); mutex.release(); System.out.println("client release lock"); client2Th.join(); } catch (Exception e) { e.printStackTrace(); } //关闭客户端 client.close(); }}上述代码的执行结果如下:
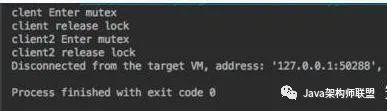
可以看到client客户端首先拿到锁再执行业务,然后再轮到client2尝试获取锁并执行业务。
一直追踪acquire()的加锁方法,可以追踪到加锁的核心函数为attemptLock。
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception{ ..... while ( !isDone ) { isDone = true; try { //创建临时有序节点 ourPath = driver.createsTheLock(client, path, localLockNodeBytes); //判断自己是否最小序号的节点,如果不是添加监听前面节点被删的通知 hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath); } } //如果获取锁返回节点路径 if ( hasTheLock ) { return ourPath; } .... }
深入internalLockLoop函数源码:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception { ....... while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) { //获取子节点列表按照序号从小到大排序 List<String> children = getSortedChildren(); String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash //判断自己是否是当前最小序号节点 PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases); if ( predicateResults.getsTheLock() ) { //成功获取锁 haveTheLock = true; } else { //拿到前一个节点 String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch(); //如果没有拿到锁,调用wait,等待前一个节点删除时,通过回调notifyAll唤醒当前线程 synchronized(this) { try { //设置监听器,getData会判读前一个节点是否存在,不存在就会抛出异常从而不会设置监听器 client.getData().usingWatcher(watcher).forPath(previousSequencePath); //如果设置了millisToWait,等一段时间,到了时间删除自己跳出循环 if ( millisToWait != null ) { millisToWait -= (System.currentTimeMillis() - startMillis); startMillis = System.currentTimeMillis(); if ( millisToWait <= 0 ) { doDelete = true; // timed out - delete our node break; } //等待一段时间 wait(millisToWait); } else { //一直等待下去 wait(); } } catch ( KeeperException.NoNodeException e ) { //getData发现前一个子节点被删除,抛出异常 } } } } } ..... }采用zk实现分布式锁在实际应用中不是很常见,需要一套zk集群,而且频繁监听对zk集群来说也是有压力,所以不推荐大家用。不过能去面试的时候,能具体说一下使用zk实现分布式锁,我想应该也是一个加分项 。
那对于zookeeper,想要实践的小伙伴,来看这里,安装步骤奉上
搭建zookeeper集群 (最好配置成home ,别用prefix,尤其hadoop )
上传zookeepr包
解压:tar -xf zookeeper-3.4.6.tar.gz
移动zookeeper包到/opt/sxt 目录下:mv zookeeper-3.4.6 /opt/sxt
配置zookeeper的环境变量:vi /etc/profile

配置zookeeper配置文件
进入zookeeper家目录中conf目录下,可看到一个 zoo_sample.cfg文件
拷贝重命名:cp zoo_sample.cfg zoo.cfg
配置zoo.cfg: vi zoo.cfg
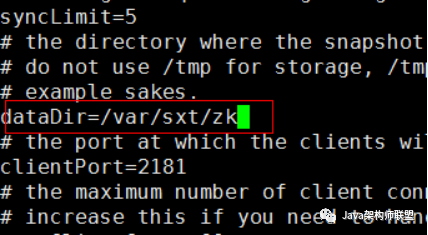
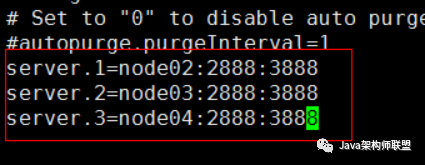
进入数据目录/var/sxt/zk,执行:echo 1 > myid echo 2 > myid echo 3 > myid 分别在node02 node03 node04操作
(
 ;
;

)
也就是创建myid文件在服务器1,2,3分别追加 1,2, 3, 代表各自zookeeper的 id,跟上边zookeeper配置文件一一对应。
从node02向node03/node04分发: scp -r zookeeper-3.4.6/ node04:`pwd` (发动到当前目录,即目标目录与源目录相同;也可以自定 以/开始)
还需要注意,分发的目录后一定要加(zookeeper-3.4.6/),否则就是把该目录的内容发过去,目录名称不会分发!!!
启动zookeeper集群:
zkServer.sh start node02、node03、 node04分别操作
查看zookeeper集群个节点的启动状态:
zkServer.sh status
zkServer.sh stop
好了,到这里,关于分布式锁以及zookeeper的搭建的相关知识,更多关于zookeeper以及Java大数据的相关知识,后期会不断在公众号中进行更新,欢迎大家关注公众号:Java架构师联盟,不迷路

