

模型
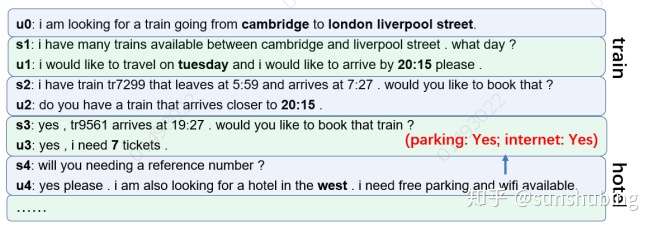
https://arxiv.org/pdf/2004.10663.pdfarxiv.org首先,将插槽分为两类——一类是S-type 槽位 ,其值可以直接从给定的输入(如酒店区域和火车发车地点)进行标记;另一种类型的槽表示为C-type,其值在话语中找不到,需要用“Yes”或“NO”来回答,例如酒店停车场和酒店网络。
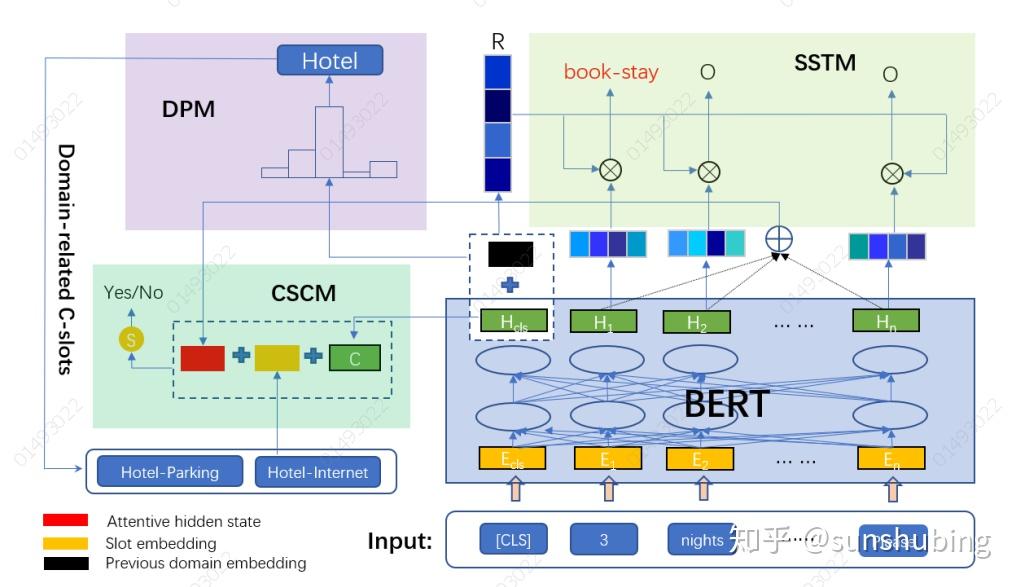
下图显示了由三个模块组成的总体架构:域预测模块(DPM)、c型槽分类模块(CSCM)和s型槽标记模块(SSLM)。
编码器
多轮对话直接将历史内容和当前话语编码为输入,然后输出所有状态,这对模型提出了很大的挑战。本文模型中,输出每一轮的对话的置信估计,而全局对话状态是不同轮次的累积状态的集合。当用户在对话过程中更改其目标时,全局对话状态将使用最新检测到的状态进行更新。
用 表示一个多轮的对话,其中
和
分别对应第i轮的系统话语和用户话语。
是上一轮的域结果。在第i轮,模型的输入是
和
的连接,它们由一系列单词组成{
}和上一个域
。
域预测模块
在多域对话中,目标域可能随着对话的进行而变化,如图1所示,其中对话涉及两个域(酒店和火车),并且在第4轮时讨论从酒店到火车的变化。在我们的模型中,除了使用了第一个隐藏状态 ,还将上一轮的域结果(表示为
)合并到域预测模块中。其背后的逻辑是,当当前话语的域不是那么明显时,
可以提供参考信息。
域的预测:
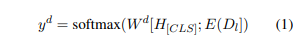
其中;表示连接操作和E(·)将一个单词嵌入到分布式表示中。在第一个回合, 是一个特殊的token[None]随机初始化。
域约束上下文信息R
此外,一个域约束的上下文记录 ,其中s为所有领域的S-type槽数,以防止我们的模型预测一些不属于当前域的插槽。R是一个分布在所有的G-slot和[EMPTY]使用
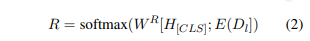
特别是 ,
的损失被定义为两者之间的Kullback-Leibler (KL)散度
,其中真实分布
计算如下:
- 如果没有需要预测的槽位,
接收到特殊槽[EMPTY]的概率1。
- 如果需要预测的槽数为k(≥1),则对应的k个槽位置的概率质量为
。
c型槽分类模块
给定当前预测的域结果 ,我们构建一个包含
中所有c类型槽的
集。如果
为空,则表示当前域中不需要预测c类型槽。其他方面,执行For循环操作,将
的每个槽划分为“Yes”或“No”,作为一个二元分类任务。分类函数如下所示
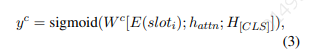
其中 输出
中第i个槽的嵌入表示,则
由
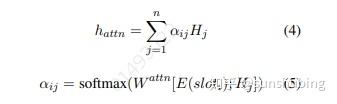
s型槽标签模块
为了标记给定输入的s型槽,我们将 的最终隐藏状态输入到softmax层中,对所有s型槽进行分类,
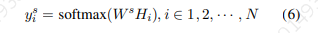
而不是基于 直接预测s型槽结果,我们引入了一个域约束上下文信息R,目的是避免生成不属于预测域的s型槽。为此,我们执行一个乘法运算\
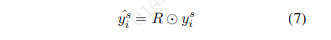
在训练过程中,我们对 使用交叉熵损失
和
,分别表示为
,
,
。R的损失定义为前述的Kullback-Leibler (KL)散度,记作LR。共同训练的最后,所有的参数都最小化加权和三个损失(α,β,γ,θ是hyperparameters):
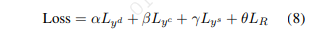
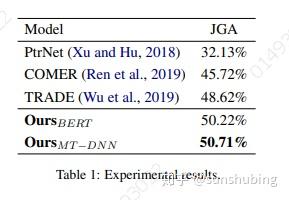
实验
结论
在DST中,观察到最大的挑战主要是提取槽值,因为可能的槽值的数量可能很大而且是可变的,而槽名相对有限且固定。在本文中,提出了分解的方法将DST分成三个子任务,共同完成状态提取任务。特别地,提出的模型的新颖之处在于两个方面。首先,利用预先训练的语言模型的力量来帮助改进表示。其次,采用Kullback-Leibler (KL)散度作为学习领域相关上下文的损失。
推荐一篇融入槽位的意图识别
PaperWeekly:BERT在小米NLP业务中的实战探索zhuanlan.zhihu.com
