

- 原文地址:Active Learning in Machine Learning
- 原文作者:Ana Solaguren-Beascoa, PhD
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:PingHGao
- 校对者:samyu2000, shixi-li
机器学习中的主动学习
主动学习实现简介
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/4/30/171c9caf0a6b82f2~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
大多数有监督机器学习模型都需要基于大量数据进行训练才能取得良好的效果。即使听起来很可笑,大多数公司仍很难向其数据科学家提供此类数据,尤其是带有“标记”的数据。后者是训练任何监督模型的关键,并且可能成为任何数据团队的主要瓶颈。
在大多数情况下,数据科学家拿到的的是一个庞大的、未标记的数据集,并需要使用它们来训练性能良好的模型。通常,这些数据的量太大,无法手动标记。因此使用该数据集来训练良好的监督模型是一项具有挑战性的工作。
主动学习: 动机
主动学习是指对需要标记的数据进行优先处理的过程,以便对训练监督模型产生最大影响。主动学习可以用于数据量太大而无法标记的情况,并且为了更准确高效地标记数据,需要设置一些优先级。
但是, 为什么我们不随机选取一个子集进行手动标注呢?
让我们以一个非常简单的例子来抛砖引玉。假设我们有数百万个数据点,需要根据两个特征进行分类。下图显示了实际的解决方案:
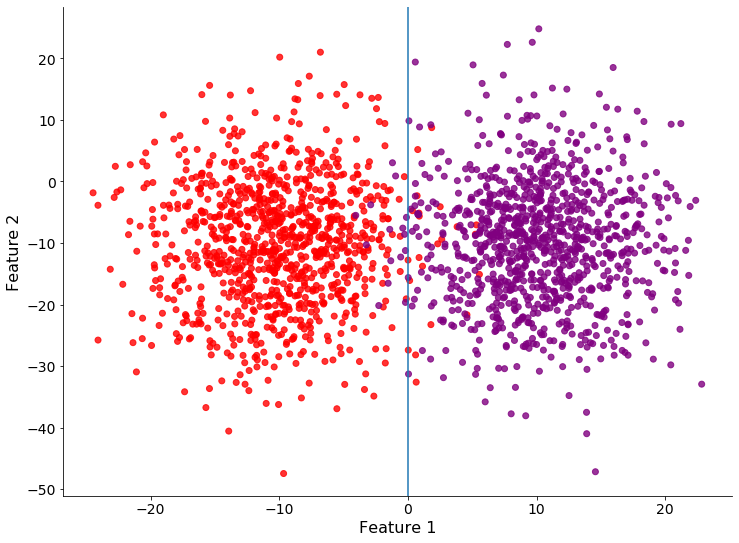
可以看到,两个类(红色和紫色)都可以很好地用一条过原点的垂直蓝色直线分开。问题是没有任何数据点经过标注,因此数据如下图所示:
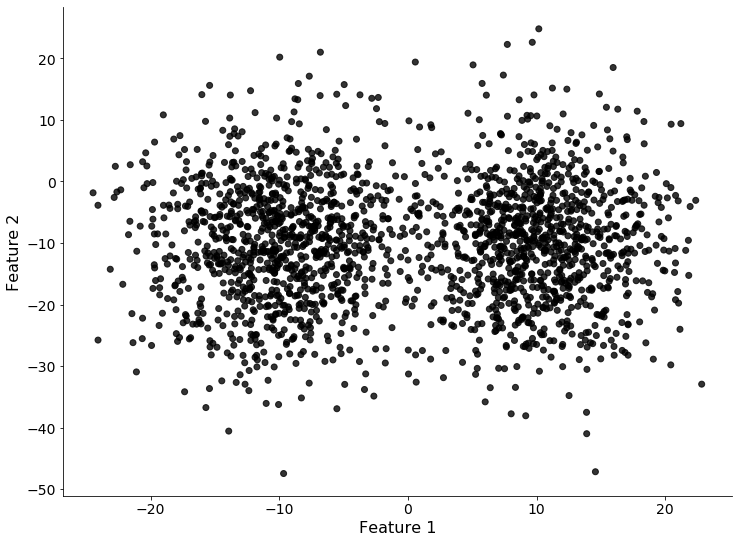
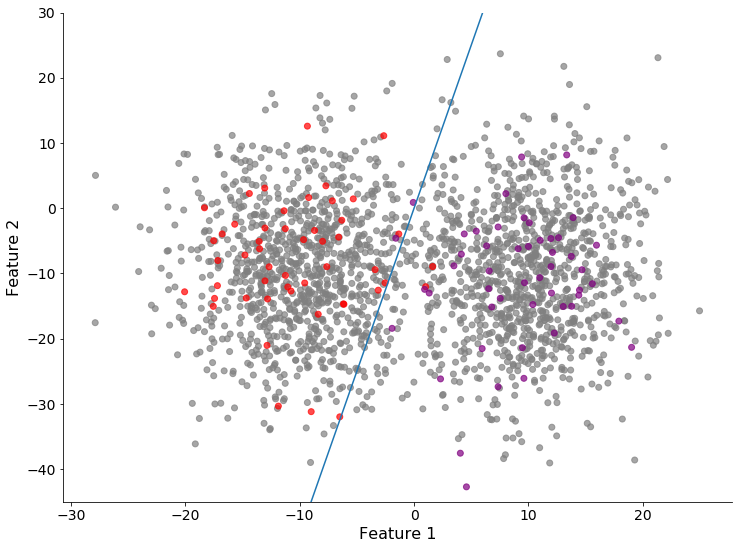
不幸的是,我们没有足够的时间标记所有数据。我们随机选择了一部分数据来标记、训练一个二分类模型。结果不是很好,因为模型预测与最佳边界有很大的偏差。
此时可以使用主动学习来优化选择的数据点,以便标记和训练模型。下面的图展示了一个训练二元分类模型的例子,该模型是根据主动学习后标记的数据点来选择训练的。
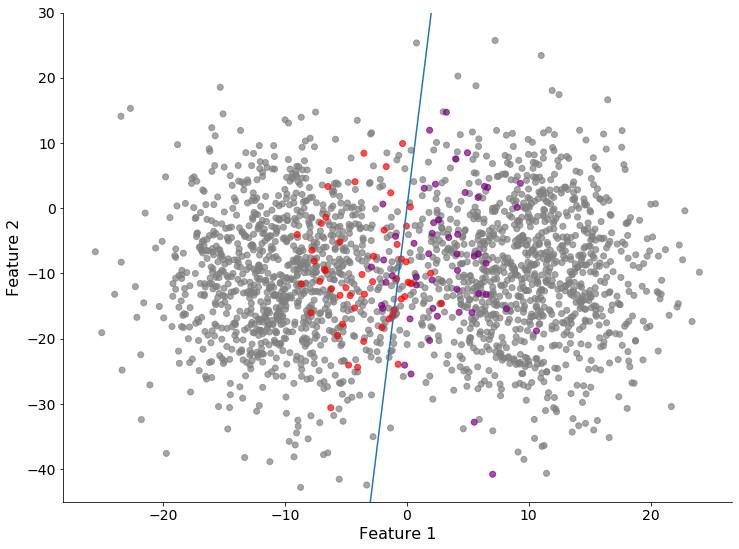
对于哪些数据点在标记时应该优先考虑,需要做出明智的选择,这样可以节省数据科学团队花费的时间,减少计算量,避免不必要的麻烦!
主动学习策略
主动学习步骤
不同文献中研究了多种方法,这些方法涉及在标记时如何确定数据点的优先级以及如何不断迭代优化。但在此我们将仅介绍最常见、最简明的方法。。
在未标注的数据集上应用主动学习的步骤是:
- 首先需要做的是选取此数据的少量子样本,对它进行手动标记。
- 一旦有了少量标记数据,就需要对模型进行训练。该模型当然不会很好,但是它将帮助我们了解参数空间的哪些区域需要首先标记以对其进行改进。
- 训练模型后,该模型将用于预测每个剩余的未标记数据点的类别。
- 基于模型的预测,在每个未标记的数据点上选择一个分数。在下一个小节中,我们会介绍一些可能经常用到的分数。
- 一旦选择了最佳方法来决定标准顺序,就可以反复重复此过程:可以在已基于优先级评分进行标注的新数据集上训练新模型。一旦在数据子集上训练了新模型,即可将该模型遍历未标记的数据点以更新优先级评分,然后继续标记。这样,随着模型变得越来越好,人们可以不断优化标注策略。
优先级评分
有几种方法可以为每个数据点分配优先级分数。下面我们描述三个基本的方法。
最小置信度:
这可能是最简单的方法。对于每个数据点的选择概率的最大值,并将其从小到大进行排序。使用最小置信度进行优先排序的实际表达式为:
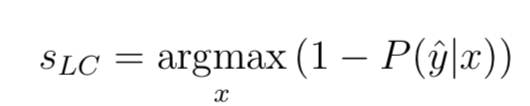
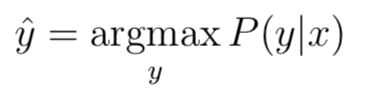
让我们举个例子来看一下它是如何工作的。假设我们有以下可能属于三类之一的数据:

在这种情况下,该算法将首先为每个数据点选择最大概率,因此有:
- X1: 0.9
- X2: 0.87
- X3:0.5
- X4:0.99.
第二步是根据最大概率(从小到大)对数据进行排序,因此顺序为 X3,X2,X1 和 X4。
边际抽样:
该方法考虑了最高概率和第二高概率之间的差异。形式上,优先级排列方式看起来像:
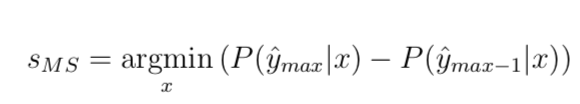
边际抽样得分较低的数据点是被标记为第一类的点;同时是模型在最可能的类别和第二个最可能的类别之间不确定的数据点。
依照 Table 1 的例子, 各个点对应的分数为:
- X1: 0.9–0.07 = 0.83
- X2: 0.87–0.1 = 0.86
- X3: 0.5–0.3 = 0.2
- X4: 0.99–0.01 = 0.98
因此,数据点按标准优先顺序排列如下:X3,X1,X2 和 X4。可以看出,在这种情况下,优先级与最小置信度略有不同。
熵:
最后,我们在这里要给出的最后一个评分函数是熵得分。熵是一个来自热力学的概念。简单的说,熵可以理解为系统中无序性的度量,例如密闭盒中的气体。熵越高,无序性就越大,而如果熵低,则意味着气体可能主要位于一个特定区域,例如盒子的一角(也许在实验开始时,气体还未在整个盒子中扩展之前)。
可以重用此概念以度量模型的确定性。如果模型对给定数据点的类别具有高度的确定性,则对于特定类可能具有较高的确定性,而所有其他类的可能性均较低。这不正与气体在盒子的一角很相似吗?在这种情况下,我们将大部分概率分配给特定类别。在高熵的情况下,这意味着该模型将概率近似的分配给所有类别,因为模型根本不确定该数据点属于哪个类别,这与使气体均匀分布在盒子的所有区域的情况相似。因此,具有较高熵的数据点较具有较低熵的数据点应该有更高的优先级。
在形式上,我们可以定义熵分数优先顺序如下:
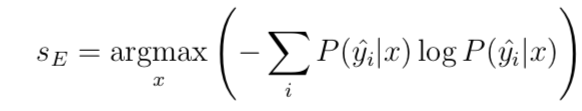
如果我们将熵得分方法应用于表 1 中的例子,有:
- X1: -0.9log(0.9)-0.07log(0.07)-0.03*log(0.03) = 0.386
- X2: -0.87log(0.87)-0.03log(0.03)-0.1*log(0.1) = 0.457
- X3: -0.2log(0.2)-0.5log(0.5)-0.3*log(0.3) =1.03
- X4: -0log(0)-0.01log(0.01)-0.99*log(0.99) = 0.056
注意,对于 X4,0 应该被替换为小的正数(如 0.00001)以保证数值稳定。
在这种情况下,数据点应按以下顺序显示:X3,X2,X1 和 X4,这与置信度方法的顺序一致!
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
