


写在前面
学会如何从网上爬取数据是一项非常重要的技能,据统计,网络上百分之三四十都是爬虫获取的数据。
那么什么是爬虫呢? 简单来说就是通过网络上的一个链接 获取该链接(html)里面我们所需要的内容. 可以简单描述为:
node请求url - > 获取html(信息) -> 解析html
准备工作
以爬取豆瓣top250上的电影排行榜信息为一个小demo
- 使用的IDE为 vscode, 创建一个文件夹并创建一个index.js的文件
- 在该文件夹上单击右键选择在终端打开
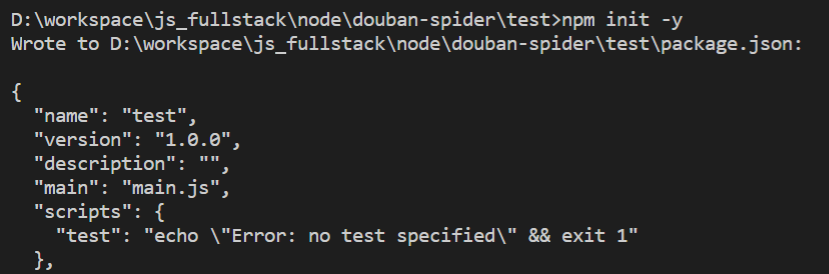
npm init -y ,回车,可以在你当前文件夹下面发现创建了一个 package.json 文件
- 继续在终端输入命令
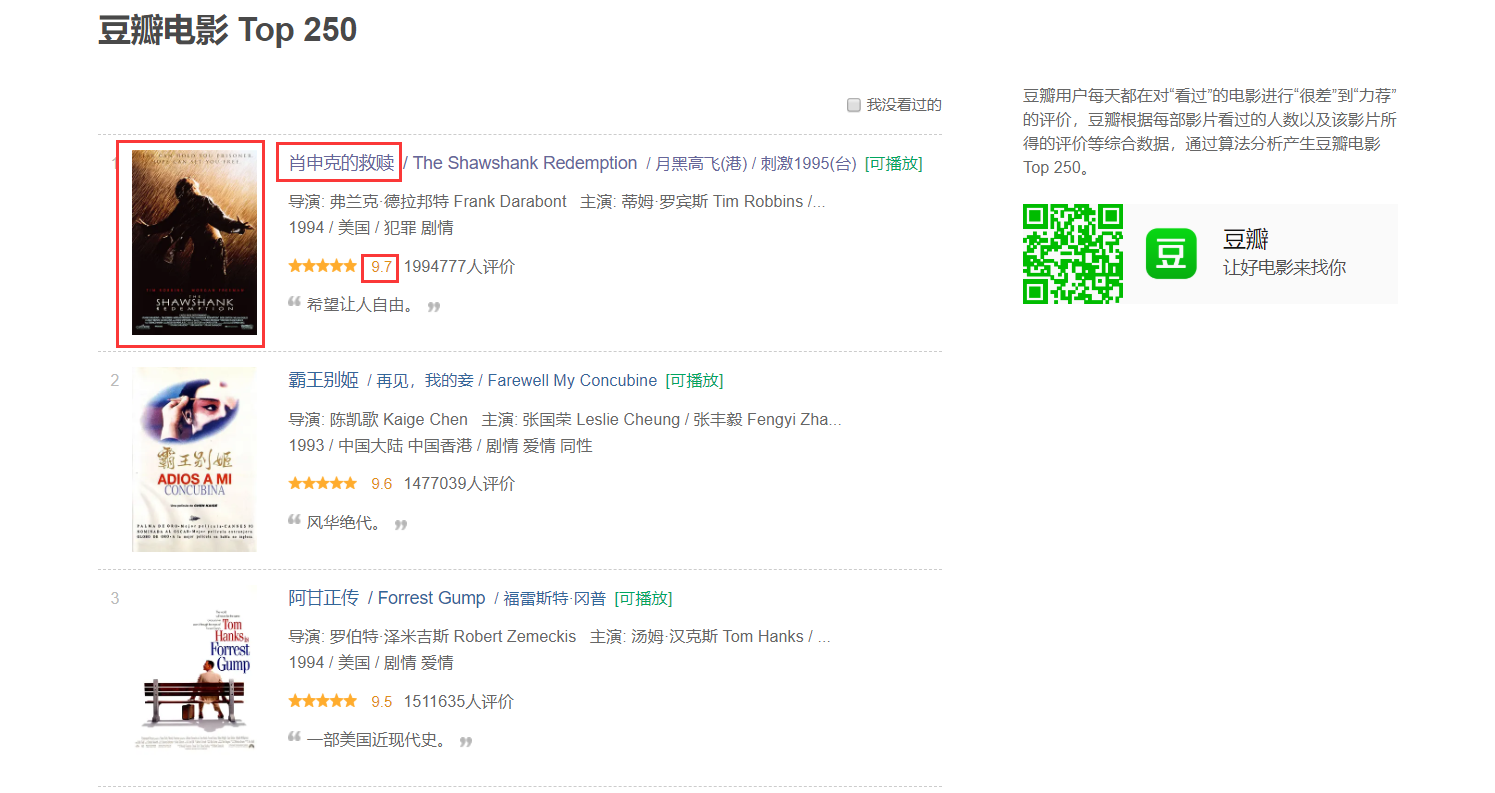
npm install cheeriocheerio是jquery核心功能的一个快速灵活而又简洁的实现,主要是为了用在服务器端需要对DOM进行操作的地方,详细可以查看cheerio官方文档 - 找到豆瓣Top250网站上 需要爬取的数据. 为了简便,我们以爬取电影名字,评分,封面为例
详细代码
代码很少,但是要了解其中的原理
- 加载模块
//加载https模块, 只要是获取网站链接都需要的操作
const https = require('https')
//加载之前下载的cheerio,在后面会有作用
const cheerio = require('cheerio')
//文件读取系统 fileSystem, 对文件的操作模块
const fs = require('fs')
- 找到 豆瓣Top250 上 名字,评分,封面 三个元素所在的位置
具体方法:第一步:右键单击检查,其他步骤如图
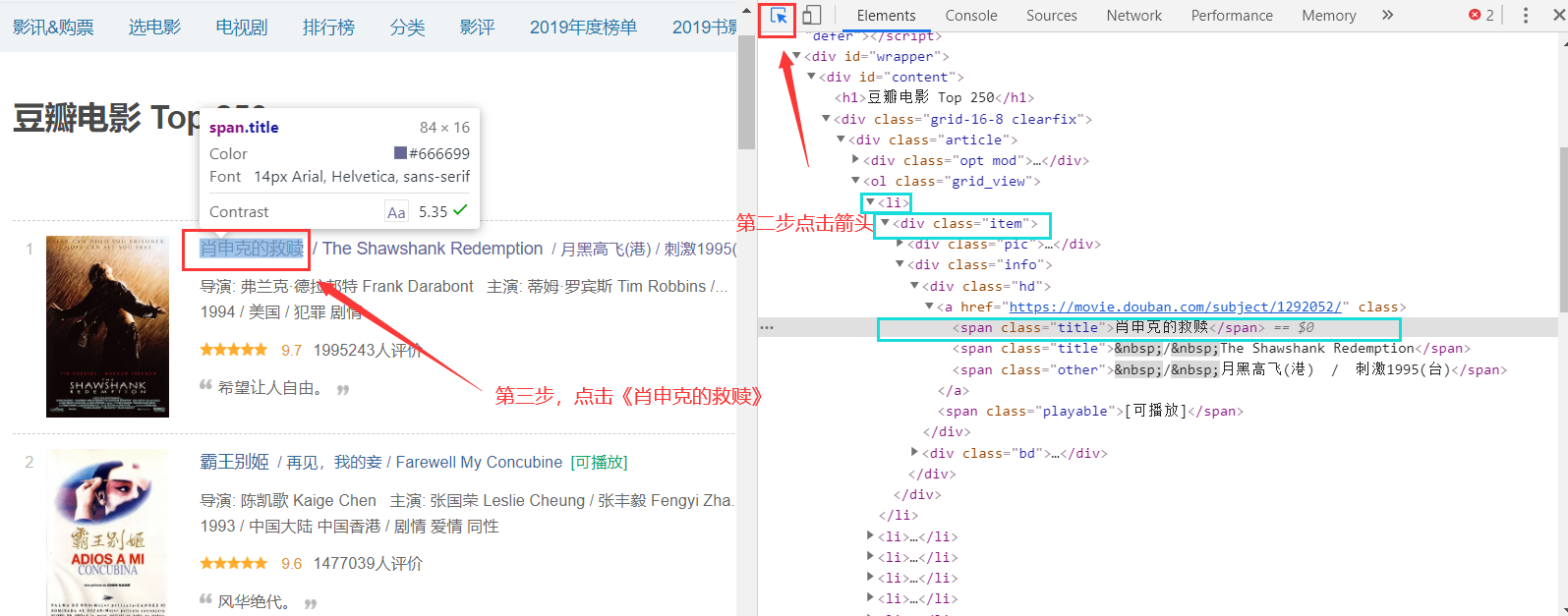
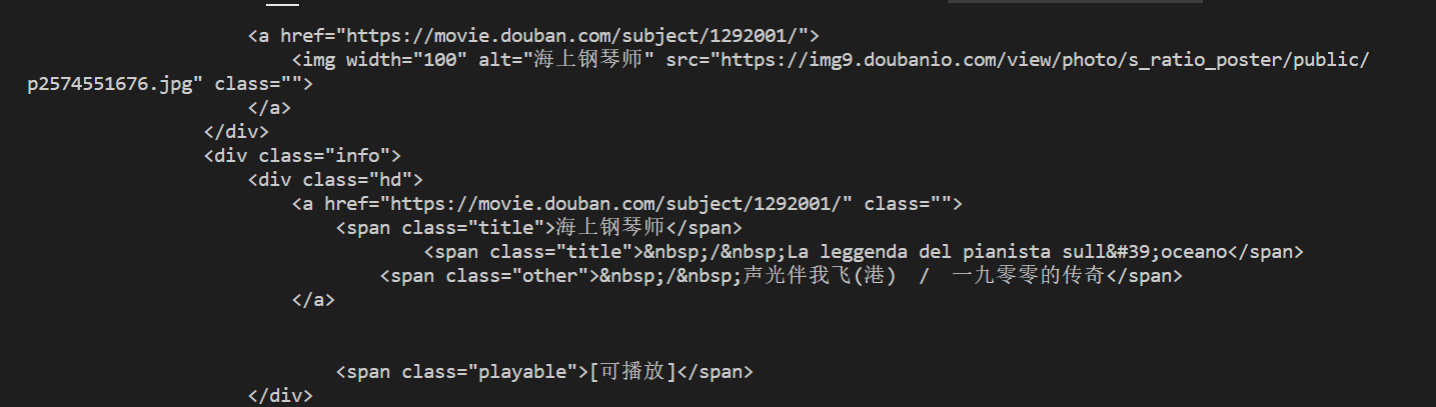
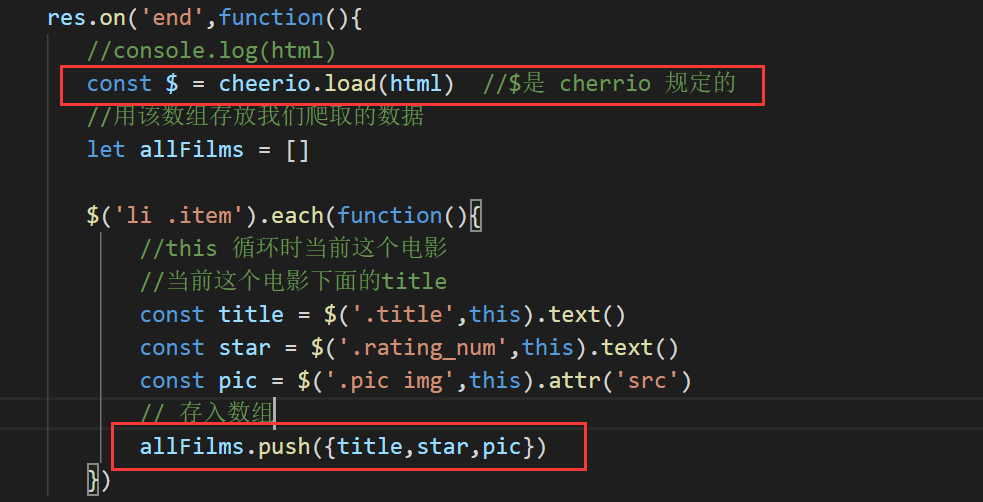
4. 使用 cheerio 模块提取 数据 刚刚我已经演示了如何找到title,其他两个也是类似的操作 找到了之后放入数组


至此我们把数据都拿到了! 这些数据可以存入数据库,成为自己的啦!
如果说担心如果有一天豆瓣Top250突然不同意我们使用链接的方式得到图片怎么办呢?
我们可以下载下来,至于如何下载下来,跟上面的步骤其实类似,就不重复了,当然如果有需要可以找我哦.
完整代码
//加载https模块, 只要是获取网站链接都需要的操作
const https = require('https')
//加载之前下载的cheerio,在后面会有作用
const cheerio = require('cheerio')
//文件读取系统 fileSystem, 对文件的操作模块
const fs = require('fs')
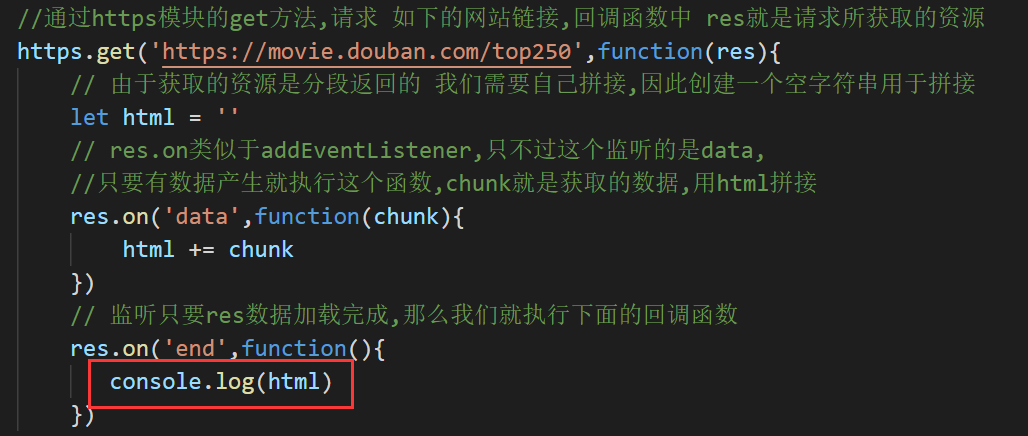
//通过https模块的get方法,请求 如下的网站链接,回调函数中 res就是请求所获取的资源
https.get('https://movie.douban.com/top250',function(res){
// 由于获取的资源是分段返回的 我们需要自己拼接,因此创建一个空字符串用于拼接
let html = ''
// res.on类似于addEventListener,只不过这个监听的是data,
//只要有数据产生就执行这个函数,chunk就是获取的数据,用html拼接
res.on('data',function(chunk){
html += chunk
})
// 监听只要res数据加载完成,那么我们就执行下面的回调函数
res.on('end',function(){
//这个时候就用到了cheerio,是我们可以使用dom操作
const $ = cheerio.load(html) //$是 cherrio 规定的
//用该数组存放我们爬取的数据
let allFilms = []
$('li .item').each(function(){
//this 循环时当前这个电影
//当前这个电影下面的title
const title = $('.title',this).text()
const star = $('.rating_num',this).text()
const pic = $('.pic img',this).attr('src')
// 存成一个 json 文件 fs
allFilms.push({title,star,pic})
})
fs.writeFile('./files.json',JSON.stringify(allFilms),function(err){
if(!err){
console.log('文件写入完毕')
}
})
})
})
难点就是理解整个流程,流程理解了,再看代码会简单很多哦~
都看到这了,不点个赞吗🙃
