


文字 | jiayangchen
封面图片 | Unsplash Clay Banks
1. 写在前面
最开始服务之间的调用借助的是域名,域名其实是个好东西,使用起来很方便,但所有调用请求都得走域名解析和负载均衡,相对来说性能就差一点,而且这些夹在中间的零部件会演变成性能瓶颈和潜在的单点风险。
后来大家一比较发现还不如直接端到端调用,那么就需要一个东西把调用链的两端连起来,这就是注册中心。
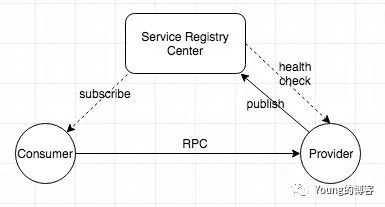
图片来源 主流微服务注册中心浅析和对比
注册中心提供服务的注册发现,用来连接调用链路的 Provider 和 Consumer 这两个端点。
一个注册中心得管理好服务的扩缩容、故障转移、流量分配这类的核心功能,自身同样需要高可用,妥善解决跨地域部署情况下注册中心节点之间的数据一致性。
因此我更倾向于认为注册中心是一个偏向体系化的产品,它的价值依赖于与之相匹配的服务规模和治理体系,它的思想虽然产生得很早,但是规模化地落地并不容易。
偏小的服务规模本身对于注册中心的依赖并不明显,实现的手段也没有定式;大型服务又会对注册中心的定位、功能提出更苛刻的需求。
2. CP 还是 AP
究竟是选择强一致性还是高可用性,当下的主流技术选型倾向于后者,但这并不是说明 CP 组件没有存在的意义,而是 AP 组件更契合互联网对于注册中心的定位。
互联网系统高可用永远是摆在首位的东西,因为系统不可用的时间通常跟财产损失直接挂钩。服务列表在短时间少了一两个节点、多了一两个节点,这点流量倾斜对于大多数服务来说感知并不明显,只需要注册中心在某个短暂的时间窗口内重新达到一致性的状态就可以,注册中心不应该在运行时影响到处于正常调用的两个端点之间的连通性。
3. 放过 ZK 吧
CP 的代表就是 zookeeper,至今 zookeeper 也是非常流行的用于注册中心的组件,这在一定程度上要感谢 dubbo。
dubbo 在 zookeeper 中是用一个树形结构的两个节点,分别维护服务的 Provider 和 Comsumer 的,列表注册在这两个节点下面,服务的健康检查依赖 zookeeper 提供的临时节点特性,实际上跟 session 的生命周期绑定在一起。但临时节点的问题就是数据易失,一旦集群故障节点重启丢失服务列表,可能造成服务大面积瘫痪,电商新贵 PDD 就曾经出现过这个问题。
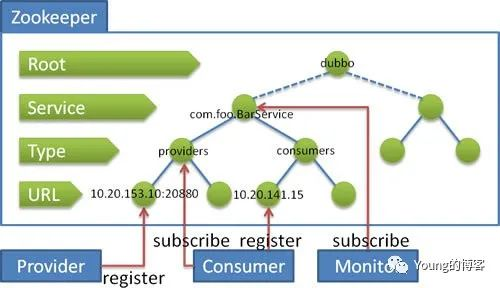
图片来源 Dubbo 官网
CP 最关键的问题在于无法支持机房容灾,例如 ABC 三个机房,机房 C 和其他两个机房产生了网络隔离,部署在机房 C 的 zookeeper 节点是无法提供写入的,这意味着机房 C 部署的 Provider 不能扩缩容、不能重启,最好在故障期间一直保持原样,否则 Provider 任何操作都会是高危的,会直接影响到部署在机房 C 的 Comsumer。
顺带说一句,我认为 zookeeper 真挺好的,它本身的定位就是个分布式协调服务,并不是专门为注册中心设计的,你不能拿评价注册中心的眼光去评价它,你要的功能 zookeeper 基本上都有,借助 Curator 拿来就可以用,提供了 election,提供了 ZAB,TPS 低了点(其实也可以了)但是也满足大部分服务规模。
4. Eureka 的挣扎
Eureka —— 奈飞的网红组件,AP 注册中心的代表。
Eureka 1.x 今天回头看来是个很牵强的实现,因为它的架构从诞生之日起,就意味着将来数据规模增长之后大概率会出问题,集群整体可伸缩性很低,每扩容一台 Eureka 节点意味着整体点对点之间需要多一份数据流,而这种 Peer 点对点机制的数据流很容易打满网卡,造成服务端压力。
根据公开的资料,Eureka 在实例规模五千左右时就会出现明显的性能瓶颈,甚至是服务不可用的情况。
但是从另一个方面来说,Eureka 的架构清晰、运维部署都很方便,而且 Eureka 作为 SpringCloud 推荐的注册中心实现,国内用户数目也相当可观,可见在服务规模恰当的情况下其性能并没有问题,从携程的分享资料也可以看出,其内部的注册中心也是类似于 Eureka 的实现。
可见没有绝对完美的架构设计,适合自己、满足业务需求才是最主要的。
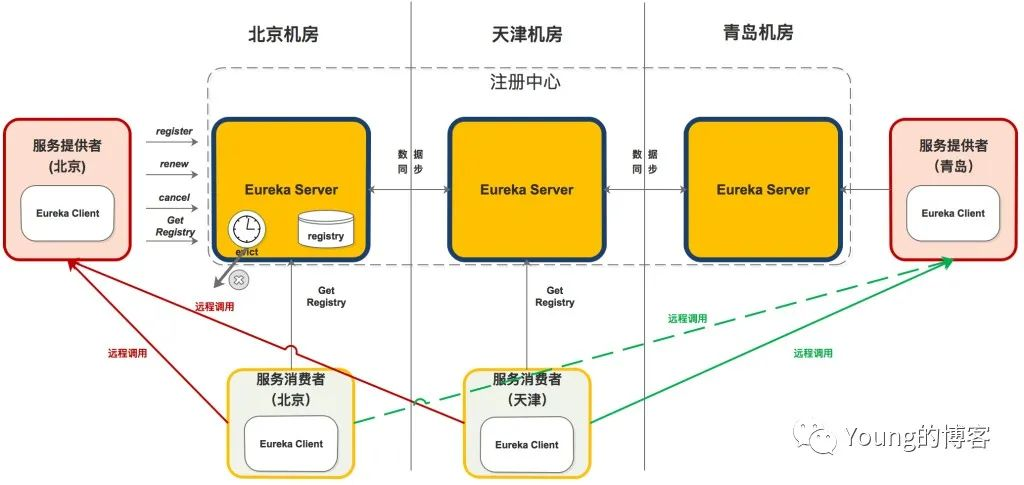
图片来源 infoQ:微服务注册中心 Eureka 架构深入解读,作者马军伟
Eureka 服务端多节点架构其实有点去中心化的意思,有意保持了每个节点的无状态特性,但是代价就是每个节点都持有全量数据,新增的数据可以往任意一个节点写入,然后由这个节点向其他节点广播,最终达到一致性。
数据都没有持久化,仅保存在内存中,带来了更好的读写性能、更短的响应时间,但是无法处理数据瓶颈,大节点扩容造成的数据同步存在打满网卡的风险,这点跟 redis 集群很像。
客户端 30s 定期上报心跳、客户端缓存服务列表这些都没什么好谈的,Eureka 有个很有意思的点是,它的集群节点实现了一个自我保护机制,用来预测到底是集群出问题还是客户端出问题,实现很简单但是思想挺实用的。
Eureka 2.0 的设计文档上体现了读写分离集群的思想,本质上是为了提升集群性能和容量,但是非常遗憾,目前 2.0 的状态是 Discontinued,短时间应该不会有成熟的产品出现。
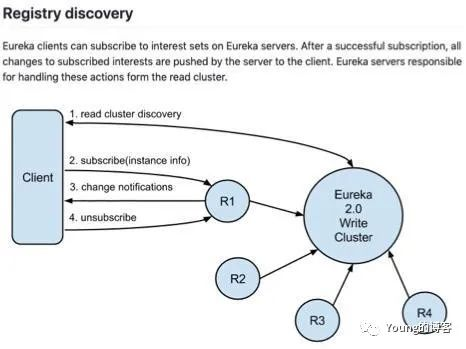
图片来源 网络
5. Sofa-Registry = 未来?
虽然没有 Eureka 2.0,但是可以从蚂蚁开源的 Sofa-Registry 中了解类似思想的实现,Sofa-Registry 脱胎于阿里的 ConfigServer,从公开的资料显示,国内阿里应该是最早做注册中心读写分离实践的。
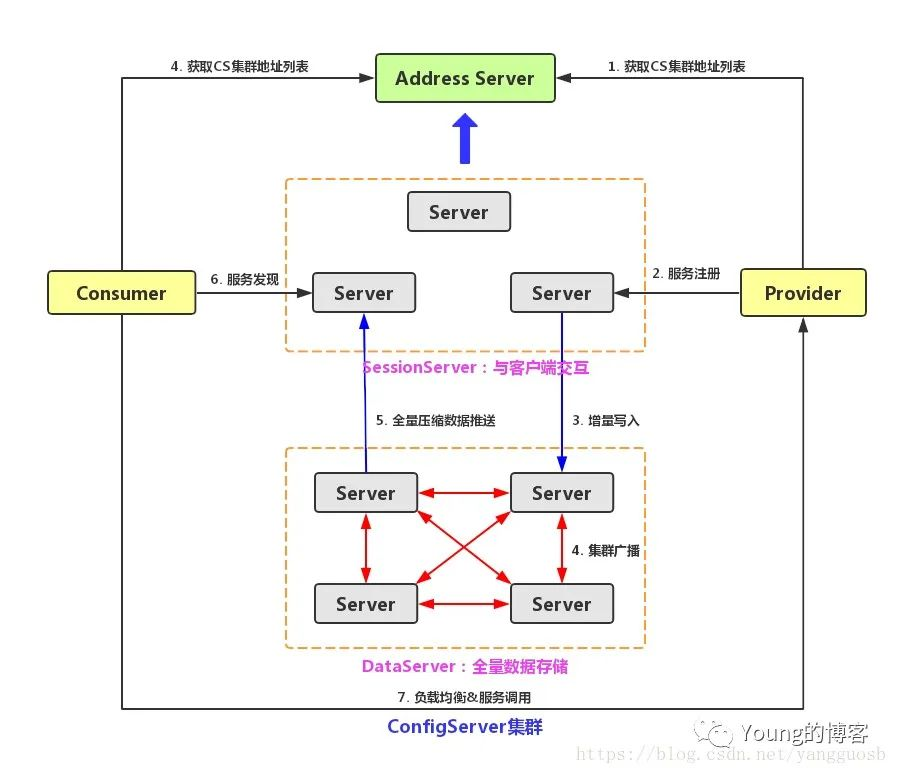
图片来源 ConfigServer架构,作者库昊天
这种架构带来的直接好处就是可以支持海量数据。
第一层的 session 集群可以无限水平扩展,彼此之间完全不需要通信,session 集群在内存中维护了注册中心需要的一切拓扑关系,客户端仅仅连接一部分 session 集群中的机器,如果某台 session 机器挂了客户端会选择另一台重连。
背后的 data 集群则通过分片存储所有的源数据,分片之间通过主从副本保证高可用,再将源数据推送到 session 集群保存下来,供客户端读取。
缺点也很明显,这种架构人力投入、运维成本肯定高于 Eureka。
6. 跨地域部署
这几乎是注册中心不可避免的问题,高可用、机房容灾、网络延迟等都会催生出要求注册中心节点能够跨地域部署,这会引申出另一个问题就是如何做数据同步。
这种情况下已经不可能通过客户端注册或者是集群节点数据流复制来保证异地注册中心集群之间的数据一致,而是会研发单独的数据同步组件,通过跨地域专线实现地域间注册中心的数据同步。
如果专线断开,此时各自地域的注册中心依旧可以独立服务于本地域内服务的调用,等到专线恢复,二者的数据继续进行同步合并纠正,最终达到一致性。
对这个知识点感兴趣的可以了解下 Nacos-Sync 组件,是 Nacos 项目专门推出的开源数据同步服务。
7. 写在最后
文章略过了一些注册中心通用的概念,例如数据模型的分层、服务列表本地缓存、健康检查的方式、推拉权衡等,我认为叙述这些细节的意义并不大。
很多时候,理解某个组件我认为最重要的是理清它的架构演进过程,这是宝贵的经验财富,你可以抓住并学习每次架构演进的方向和原因。
