- 2020年4月23日更新:如果以后要使用Nutch建议安装jdk8
- 在虚拟机上搭建CentOS6
具体方法可自行百度,此过程中容易出现报错“此主机支持Intel VT-X,但Intel VT-X并未开启...”,出现此问题是因为宿主机的虚拟化没有打开,进入宿主机BIOS,找到SETUP中的Security,然后找到Virtualization(不同型号机器可能位置不同),打开重启即可。
有的机器完成了上述步骤但仍然不能安装虚拟机,可能是因为Windows的Hyper-V(微软的虚拟机)被打开了,Vmware和Hyper-V不能兼容,移除Hyper-V即可。Win10下打开“程序与功能”然后单击“启用或关闭Windows功能”,弹出窗口中找到Hyper-V,关闭即可。
- Vmware虚拟网络配置和CentOS静态IP设置
Vmware为我们提供了三种工作模式Bridge(VMnet0),NAT(VMnet1),HOST-ONLY(VMnet2)。
- Bridge,桥接模式,主机网卡和虚拟机通过虚拟网桥通信,实际上宿主机承担了交换机的作用。在桥接模式下,虚拟机应该和宿主机在同一网段,DNS和网关。
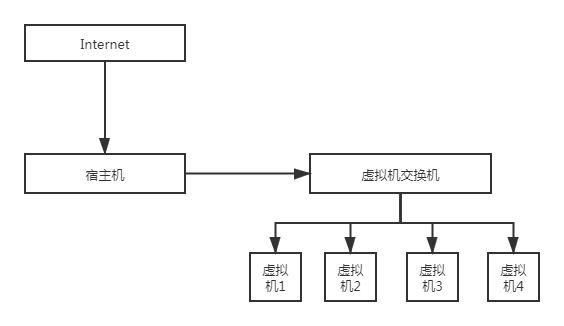
- NAT模式(地址转换模式)
桥接模式在IP充足的情况下使用,但在IP资源缺少的情况下就需要使用NAT模式。NAT借助虚拟NAT设备和虚拟的DHCP服务器为虚拟机提供通信,同时虚拟网卡提供虚拟机和宿主机的通信。配置时按照配置主机网络的方法,设置好子网IP,子网掩码,DHCP,DNS,网关。
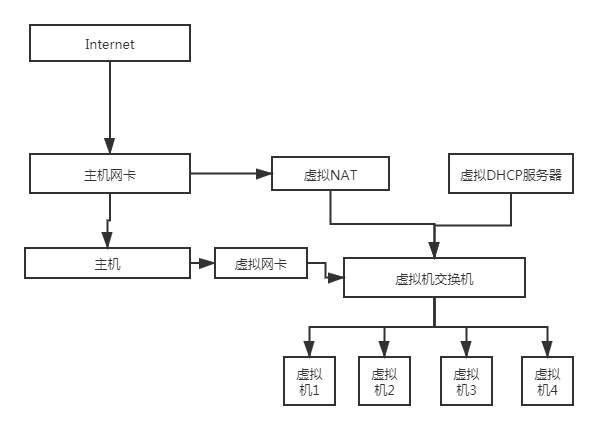
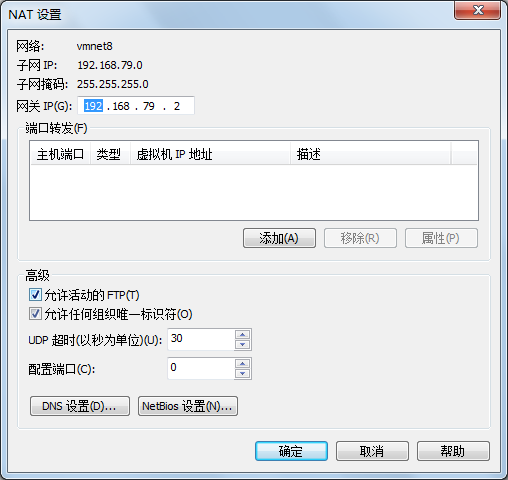
这里给出一个参考设置
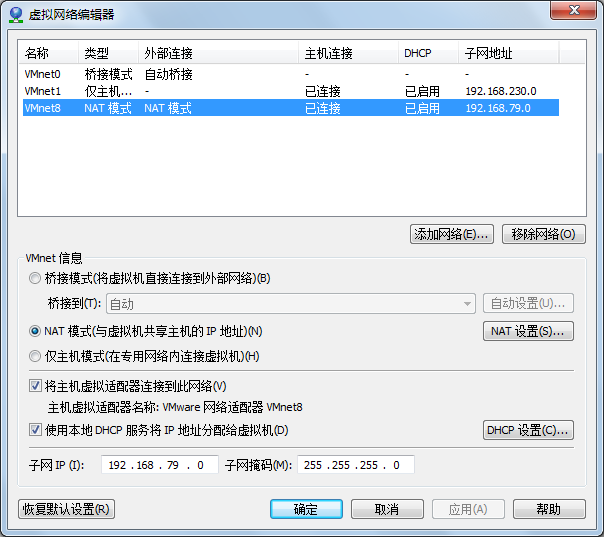
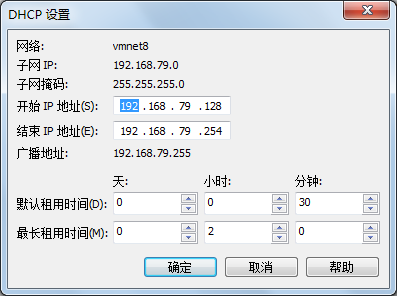
3.HOST-ONLY
在这种模式下,实际上屏蔽了虚拟机与外网的连接,使得虚拟机成为一个独立的系统,只能与主机通信。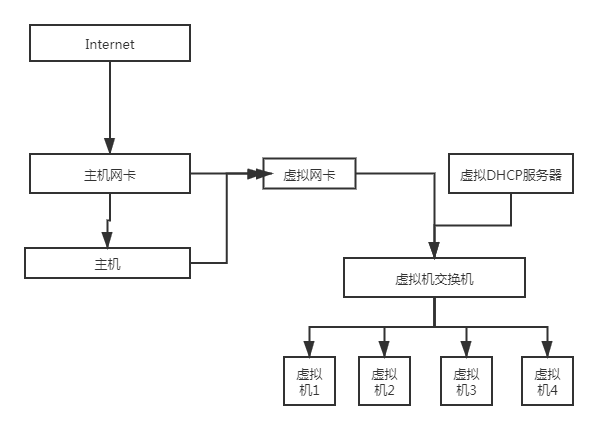
那么有没有办法让虚拟机联网呢?此时我们是需把主机网卡共享给虚拟网卡即可。在设置好DHCP后,在主机的网络设置里选择分享网络即可。
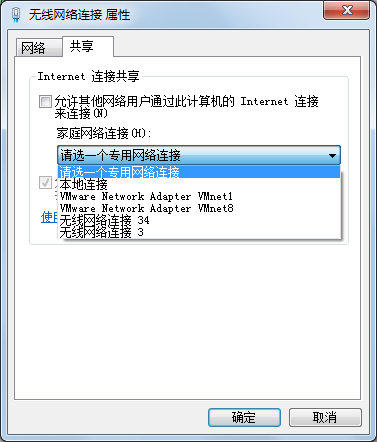
在配置好Vmware虚拟网络后,我们来配置虚拟机网络(这里以NAT为例),在一个工作组内的每台虚拟机都已同样地方式配置。打开虚拟机,右键网络设置
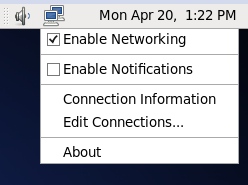 选择EDIT CONNECTIONS,
选择EDIT CONNECTIONS,
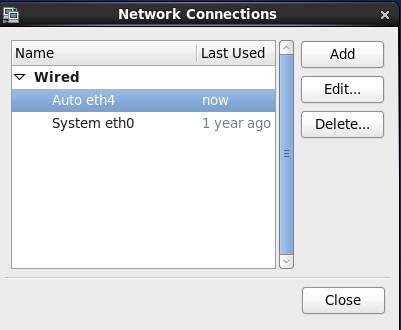
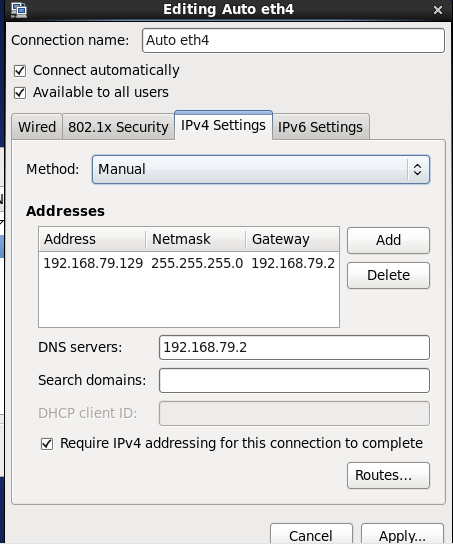
设置静态的IP(要在之前设置的DHCP范围内),保存即可。
- Hadoop的安装(分布式安装,一台master,两台及以上slave)
- 设置虚拟机时钟同步(该操作在每台虚拟机上都设置)
打开终端进入root用户(su root),输入
#crontab -e
编辑crontab服务,设置一个时钟同步的地址(这里是vi编辑,按i插入模式,esc+:wq保存退出,更多vi操作可自行了解)
0 1 * * * /usr/sbin/ntpdate
cn.pool.ntp.org
这里注意空格,然后修改时区
# vi /etc/sysconfig/clock
修改为ZONE="Asia/Shanghai"。
# rm /etc/localtime //删除本地时种配置
# ln -sf
/usr/share/zoneinfo/Asia/Shanghai /etc/localtime //连接到上海时区
# reboot //重启
2.配置主机名(每个虚拟机均进行)
# vi /etc/sysconfig/network
设置为(其他节点设置不同名字即可,因为是分布式安装,本次演示配置一个master,两个slave节点,分别为slave0,slave 1)
NETWORKING=yes
HOSTNAME=master
使修改生效
# hostname master //hostnmae slave0 //hostname slave1
修改hosts文件,建立主机名和IP的映射
#vi /etc/hosts
192.168.79.129 master
192.168.79.130 slave0
192.168.79.131 slave1
将上面内容添加进入(添加你之前实际配置的静态IP,这里的IP是我的配置,同样,你有几个slave就写几个进去)
3.关闭防火墙(每个虚拟机均进行)
输入命令$ setup
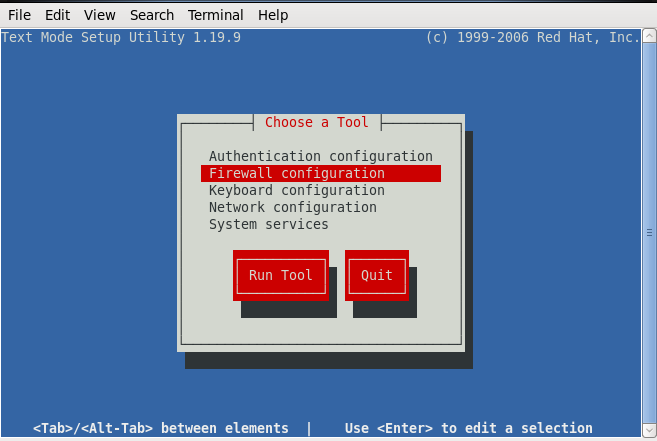
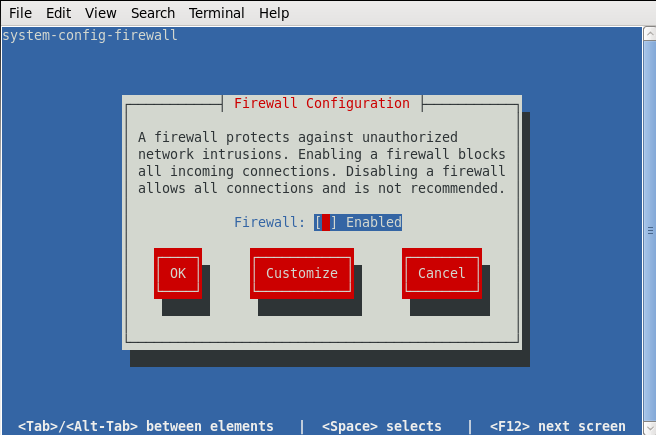
按图示把*改成空格保存即可。
这时候可以ping一下各个节点看看是否连通,ping通则配置成功。
4.安装JDK(所有虚拟机均配置)
这里不建议安装太高版本的jdk,会报错反射相关的错误,我这里安装的是jdk7,我记得安装jdk8以下都行。创建好相应的路径(一般在/usr下创建一个叫java的文件夹),把安装包解压到里面,设置环境变量。(注意:如果以后能用到Nutch,建议安装jdk8)
$ gedit /home/hfut/.bash_profile
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export PATH=$JAVA_HOME/bin:$PATH //这里设置成你自己的路径
$ source /home/hfut/.bash_profile //使改动生效

5.设置SSH免密登录(在master配置,通过ssh复制到其他节点)
$ ssh-keygen -t rsa //新建一个密钥,一路回车即可
$ cat ~/.ssh/id_rsa.pub >>
~/.ssh/authorized_keys //将公钥追加到授权列表
$ chmod 600 ~/.ssh/authorized_keys //更改aythorized_keys文件的权限
$ scp ~/.ssh/authorized_keys hfut@slave0:~/.ssh 将公钥复制到从节点
$ scp ~/.ssh/authorized_keys hfut@slave1:~/.ssh
5.部署和配置Hadoop(只在master下操作,复制到从节点)
还是一样创建一个hadoop的文件夹,把包解压进去,记录这个路径,完成后面的配置工作
<1>配置环境变量hadoop-env.sh(只需配置改文件的jdk即可)
$ gedit
~/hadoop-2.5.2/etc/hadoop/hadoop-env.sh
在文件靠前的部分找到下面的一行代码:
export
JAVA_HOME=${JAVA_HOME}
将这行代码修改为下面的代码:
export
JAVA_HOME=/usr/java/jdk1.7.0_71/ //你自己的路径
<2>配置环境变量yarn-env.sh
在文件靠前的部分找到下面的一行代码:
#
export JAVA_HOME=/home/y/libexec/jdk1.6.0/
将这行代码修改为下面的代码(将#号也去掉):
export JAVA_HOME=/usr/java/jdk1.7.0_71/
<3>配置核心组件core-site.xml
$ gedit
~/hadoop-2.5.2/etc/hadoop/core-site.xml
打开后用下面的配置替换掉
<?xml
version="1.0" encoding="UTF-8"?>
<?xml-stylesheet
type="text/xsl" href="configuration.xsl"?>
<!-- Put
site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hfut/hadoopdata</value>
</property>
</configuration>
<4>配置文件系统hdfs-site.xml
$ gedit
~/hadoop-2.5.2/etc/hadoop/hdfs-site.xml
<?xml
version="1.0" encoding="UTF-8"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?><!-- Put site-specificproperty overrides in this file. --><configuration> <property> <name>dfs.replication</name> <value>1</value> </property></configuration>
<5>配置文件系统yarn-site.xml
$ gedit
~/hadoop-2.5.2/etc/hadoop/yarn-site.xml
<?xml
version="1.0"?><configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:18088</value> </property></configuration>
<6>配置计算框架mapred-site.xml
$ cp
~/hadoop-2.5.2/etc/hadoop/mapred-site.xml.template
~/hadoop-2.5.2/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<7>在master节点配置slaves文件
gedit
~/hadoop-2.5.2/etc/hadoop/slaves
将里面的内容替换为slave0,slave1。
<8>复制到从节点
$ cp
$ scp
-r hadoop-2.5.2/ hfut@slave:~/
6.启动Hadoop集群
下面的操作都在非root下进行
<1>配置Hadoop启动的系统环境变量
该节的配置需要同时在两个节点(HadoopMaster和HadoopSlave)上进行操作,操作命令如下:
$ cd
$ gedit ~/.bash_profile
将下面的代码追加到.bash_profile末尾:
#HADOOP
export HADOOP_HOME=/home/hfut/hadoop-2.5.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后执行命令:
$ source ~/.bash_profile
<2>创建数据目录
该节的配置需要同时在两个节点(HadoopMaster和HadoopSlave)上进行操作,操作命令如下:
在用户主目录下,创建数据目录,命令如下:
$ mkdir /home/hfut/hadoopdata //设置你自己的目录
<3>格式化文件系统
格式化命令如下,该操作需要在HadoopMaster节点上执行:
$ hdfs namenode -format
如果出现Exception/Error,则表示出现问题。
<4>启动Hadoop
$ cd ~/hadoop-2.5.2
$ sbin/start-all.sh询问yes/no选择yes即可
在master终端执行jps命令,查看是否有四个进程启动,在从节点输入jps命令显示三个进程启动,hadoop启动成功
!牢记每次使用完后关闭集群
$ stop-all.sh
启动集群命令
start-all.sh
实际上Hadoop建议放弃这两个命令,使用start-yarn.sh start-dfs.sh即可。
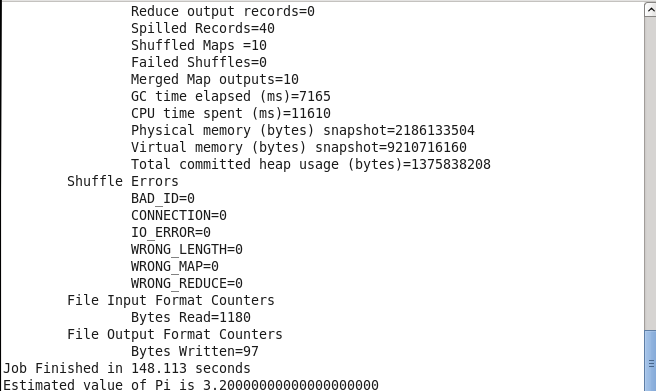
<5>运行PI实例检查Hadoop集群是否搭建成功
进入Hadoop安装主目录,执行下面的命令:
$ cd ~/hadoop-2.5.2/share/hadoop/mapreduce/
$ hadoop jar
~/hadoop-2.5.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar pi 10
10看到这样的结果表示集群部署成功。