

1 定义
在前两节中介绍了单向链表的定义与基本的使用。相对于线性存储而言,链表具有更加灵活的使用,可以不受空间大小的约束。但单链表在使用中只能通过 next 指针进行单向的遍历,一路到底不能回头,在面临大数据的处理时会造成时间的浪费。所以,在此基础上产生了双向链表。
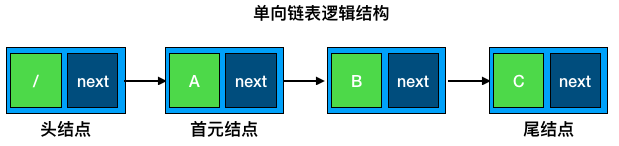

双向链表顾名思义,就是可以进行前驱或后继的遍历。在结构上就是在单链表的基础上,增加了 prior 指针指向节点的前驱,配合 next 指针实现链表的双向遍历。
因为多了 prior 指针,所以在插入、删除等操作中需要对新的指针进行额外的处理,来保证操作前后链表的正确逻辑结构。
类似于单向循环链表,当在逻辑结构上尾节点与首节点相连时,双向链表便成了双向循环链表。其中,不仅可以通过尾节点的 next 指针获取到首节点,也可以通过首节点的 prior 指针获取到尾节点。
2 双向链表
2.1 结构定义
typedef int ElementType; // 自定义数据元素类型
typedef int Status; // 自定义状态码类型
static int SUCCESS = 0; // 成功状态码
static int ERROR = -1; // 失败状态吗
/// 定义单向链表的节点
struct Node {
ElementType data; // 数据域
struct Node *next; // 指针域,指向逻辑中的下一个节点
struct Node *next; // 指针域,指向逻辑中的下一个节点
};
双向链表在单向链表的基础上多个 prior 指针,用于指向前驱结点。
2.2 创建头结点
/// 双向链表的初始化
static Status initLinkList(LinkList *l) {
// 创建一个头结点,作为哨兵节点
*l = (LinkList)malloc(sizeof(struct Node));
// 内存分配失败
if (*l == NULL) {
return ERROR;
}
// 置空指针域
(*l)->prior = NULL;
(*l)->next = NULL;
return SUCCESS;
}
同单向链表的初始化,但需要设置 prior 避免出现野指针。
2.3 创建链表
/// 链表的初始化
static Status createLinkList(LinkList *l) {
LinkList p = *l;
// 新增节点
for (int i = 0; i < 10; i++) {
// 创建节点
LinkList temp = (LinkList)malloc(sizeof(struct Node));
temp->data = i;
temp->prior = NULL;
temp->next = NULL;
// 插入新的节点
p->next = temp;
temp->prior = p;
// 移动 p 的位置,即移动到 temp
p = p->next;
}
return SUCCESS;
}
2.4 插入
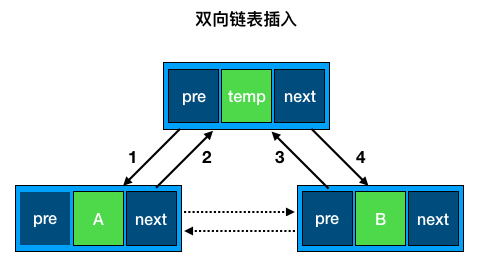
图标表示了双向链表插入的逻辑。顺序不固定,但其中第 4 号线必须在 2 号线之前执行,否则改变了 A 的后继将会丢失 B 节点。
为方便记忆,可先执行 1、4 改变 temp,将 temp “挂”在链表上,再执行 2、3 将原来的虚线重新指向。
/// 双向链表的插入
static Status insertIntoLinkList(LinkList *l, int i, ElementType e) {
int j = 1;
LinkList p = *l;
// 遍历链表寻找插入位置
while (p && j < i) {
p = p->next;
j++;
}
// 位置寻找错误
if (!p || j > i) {
return ERROR;
}
// 此时 p 为位置 i 的前一个节点
// 创建一个新的节点
LinkList temp = (LinkList)malloc(sizeof(LinkList *));
temp->data = e;
// 将 p 的后继作为 temp 的后继
temp->next = p->next;
temp->prior = p;
// 如果 p 有后继,则需要修改后继的指针
if (p->next) {
p->next->prior = temp;
}
// 将 temp 和 p 进行关联,需要执行完上述步骤再执行
p->next = temp;
return SUCCESS;
}
插入时前面的遍历和单向链表的步骤是一样的。不同的是多了两个 prior 指针的设置。单量链表是两个指针的设置,双向链表是四个指针的设置。
操作中需要注意先后顺序,一定要先设置 p 后继的指针,再修改 p 的后继,防止节点的丢失。
2.5 删除
/// 删除双向链表的节点
static Status deleteFromLinkList(LinkList *l, int i, ElementType *e) {
int j = 1;
LinkList p = (*l)->next;
// 遍历链表寻找删除位置
while (p && j < (i - 1)) {
p = p->next;
j++;
}
// 位置寻找错误
if (!p || j != (i - 1)) {
return ERROR;
}
// 此时 p 为位置 i 的前一个节点
// 获取被删除的节点
LinkList delTemp = p->next;
// 数据返回
*e = delTemp->data;
// 处理被删除节点的后继
if (delTemp->next) {
delTemp->next->prior = delTemp->prior;
}
// 处理被删除节点的前驱
p->next = delTemp->next;
// 释放被删除的节点
free(delTemp);
return SUCCESS;
}
2.6 其他
双向链表的遍历打印、清空、取值等操作与单向链表的操作是一样的,代码参考前两节,这里不再赘述。重点在双向链表的插入与删除等操作。
2.7 使用
int main() {
// 节点声明
LinkList l;
// 初始化链表头结点
if (initLinkList(&l) == SUCCESS) {
printf("链表初始化成功\n");
} else {
printf("链表初始化失败\n");
return 0;
}
printf("创建双向链表\n");
createLinkList(&l);
traverseLinkList(l);
printf("链表插入数据\n");
for (int i = 1; i < 5; i++) {
insertIntoLinkList(&l, 1, i * 5);
traverseLinkList(l);
}
ElementType e1;
deleteFromLinkList(&l, 4, &e1);
printf("链表删除第4个数据 %d\n", e1);
traverseLinkList(l);
return 0;
}
打印结果:
链表初始化成功
创建双向链表
LinkList: 0 1 2 3 4 5 6 7 8 9
链表插入数据
LinkList: 5 0 1 2 3 4 5 6 7 8 9
LinkList: 10 5 0 1 2 3 4 5 6 7 8 9
LinkList: 15 10 5 0 1 2 3 4 5 6 7 8 9
LinkList: 20 15 10 5 0 1 2 3 4 5 6 7 8 9
链表删除第4个数据 5
LinkList: 20 15 10 0 1 2 3 4 5 6 7 8 9
3 双向循环链表
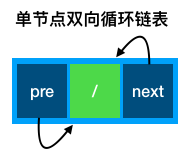
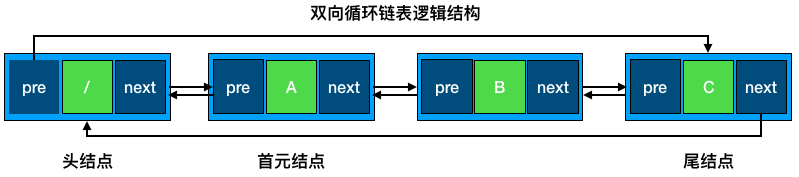
双向循环链表是指双向链表在逻辑意义上,头尾节点相连的结构。在下面的使用中,为避免首元结点的特殊处理,创建了一个头结点保证所有节点都不是第一个节点。大部分操作与上述普通的双向链表大体一致,所以在下面代码将着重描述不一致的地方。
3.1 结构定义
双向循环链表的结构定义和普通的双向循环链表是一样的。参考上面的代码。
3.2 创建头结点
/// 双向循环链表的初始化
static Status initLinkList(LinkList *l) {
*l = (LinkList)malloc(sizeof(struct Node));
if (*l == NULL) {
return ERROR;
}
// 和普通双向链表不同的是,前驱和后继都是自己
//(*l)->prior = NULL;
//(*l)->next = NULL;
(*l)->prior = *l;
(*l)->next = *l;
return SUCCESS;
}
3.3 创建链表
/// 创建双向循环链表
static Status createLinkList(LinkList *l) {
LinkList p = *l;
for (int i = 0; i < 10; i++) {
LinkList temp = (LinkList)malloc(sizeof(struct Node));
temp->data = i;
p->next = temp;
temp->prior = p;
// 将头节点的 prior 指向尾结点
p->prior = temp;
// 将尾节点的 next 指向头结点
temp->next = *l;
p = p->next;
}
return SUCCESS;
}
3.4 插入与删除等
对于双向链表的插入与删除,从逻辑上讲,等于在一个普通的双向链表中间进行插入与删除操作,不用考虑是否是首结点或尾节点,因为每个节点都有前驱与后继。
本质上双向循环链表是一种特殊的双向链表,所以,上述对普通双向链表的插入与删除的操作,可以用来操作双向循环链表。从逻辑上来讲因为不需要判断所以逻辑反而更简单,所以不再赘述了。
3.5 遍历
至于其他的遍历、读取等操作,和普通的单向循环链表一样。
/// 循环链表的遍历打印
static Status traverseLinkList(LinkList l) {
// 因为默认有头结点,所以从头结点的 next 开始
LinkList p = l->next;
printf("LinkList: ");
// p == l 作为遍历的结束条件
while (p && p != l) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
return SUCCESS;
}
3.6 使用
int main() {
// 节点声明
LinkList l;
// 初始化链表头结点
if (initLinkList(&l) == SUCCESS) {
printf("链表初始化成功\n");
} else {
printf("链表初始化失败\n");
return 0;
}
printf("创建双向链表\n");
createLinkList(&l);
traverseLinkList(l);
printf("链表插入数据\n");
for (int i = 0; i < 5; i++) {
insertIntoLinkList(&l, 1, i * 2);
traverseLinkList(l);
}
ElementType e;
deleteFromLinkList(&l, 4, &e);
printf("链表删除第4个数据 %d\n", e);
traverseLinkList(l);
return 0;
}
打印结果:
链表初始化成功
创建双向链表
LinkList: 0 1 2 3 4 5 6 7 8 9
链表插入数据
LinkList: 0 0 1 2 3 4 5 6 7 8 9
LinkList: 2 0 0 1 2 3 4 5 6 7 8 9
LinkList: 4 2 0 0 1 2 3 4 5 6 7 8 9
LinkList: 6 4 2 0 0 1 2 3 4 5 6 7 8 9
LinkList: 8 6 4 2 0 0 1 2 3 4 5 6 7 8 9
LinkList: 8 6 4 2 0 0 1 2 3 4 5 6 7 8 9
链表删除第4个数据 2
LinkList: 8 6 4 0 0 1 2 3 4 5 6 7 8 9
4 总结
- 双向链表在操作中不仅要考虑
next指针,还要考虑prior指针的设置。 - 注意指针设置的先后顺序,避免野指针的出现以及节点的丢失。
- 在增删过程中,可以通过创建辅助头结点避免首节点的特殊处理。
- 在增删过程中,需要对是否是尾节点进行判断,如果有后继需要对后继的指针进行设置,这点和单链表有些不同。
