

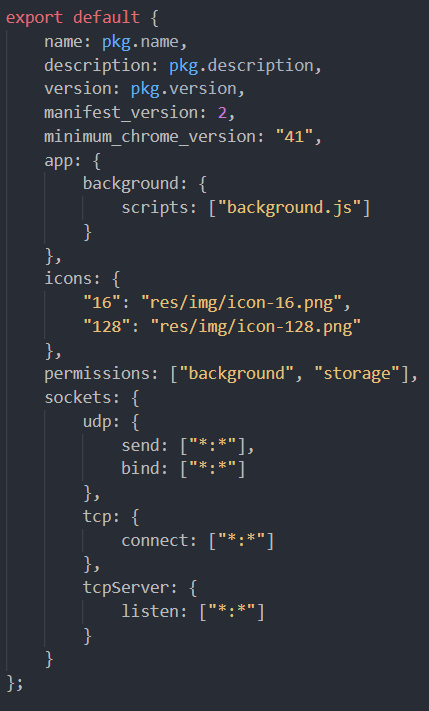
如果想要选中上述代码中的黄色部分也就是所有的字符串类型的值,无论是正则还是啥方法,都是基本无法完成的;所以我们需要引入 AST 换个角度分析问题。
居然 IDE 可以让其渲染成黄色?是不是意味着, IDE 有能力理解他,然后修改默认的渲染行为?这就是 AST,相比最为简单的关键字高亮,其是对代码结构的一种抽象表示,所以能获取更多代码的隐含意义。
比如上面的黄色部分就可以理解为 Property 下面的 Key 和 Value,且其类型为 String。
那么这种脱离整颗树,看待个别节点层级关系的方式是不是有些熟悉?这和 CSS 层叠样式表的选择器是不是极为相似?
那么层叠样式表又具有什么样的特性?首先,划分层次,之后通过选择表达式来选取部分相互独立的节点。
那如果将 AST 和 CSS Selector 柔和在一起能产生什么奇奇怪怪的东西?于是有了下面这个 AST Selector。
对于造一个轮子我们先得知道他有什么现实价值?
- 首先能学会 AST,了解语言的内在划分逻辑
- 其次能了解 CSS 选择器的作用原理,尤其是为什么要把标签和类写在后面?
- 最后,能获得一个更高效的文本处理方案,他不同于传统的标准结构化文本(XML 和 JSON),而是更加复杂和语义化的文本类型;如果自然语言什么时候能抽离出 AST,指不定他也能解释一下?
为了更好的进行数据处理,我们有了各种各样的数据结构和模式。但是这些年 NoSQL 的爆发也说明了可结构化的数据只是冰山一角。虽然这个立意有点大,但是假装我们以及完成了极为丰富的非结构化数据的抽象,然后再来看这个工具。
回到最开始的字符串选择?既然有了 Property 下面的 Key 和 Value,且其类型为 String,我们将其映射到 AST 上会有什么结果?
Property->StringPropertyAssignment > StringLiteral
是不是极为相似,随后我们就能实现一个满足上述要求的工具。
之前分析 Webpack 也是为了干这个,结果发现 Webpack 和这个逻辑不一样;随换个思路,自己重写一个对 AST 的选择器工具。
在 npm 额 Github 上摸了半天,也没找到合适的库。
唯一一个各方面都还行的,json-q 本身实现有问题,未处理存在自身引用的问题,会栈溢出;而且也和 CSS 选择器思路不太一样,学习成本高了点。
于是换个思路,上面的 json-css 有点骚,把 JSON 转化成 DOM 结构,然后用原生的选择器。那么重新思考一下 AST 的数据结构,或许这才是更合适的方法;类似 XML 的 tag, attrs, childs ,对应 AST 的 type, 节点属性, 子节点。
但是 nodejs 环境,没法整出来 DOM 环境,不过好在有个 jsdom 的库,提供了对浏览器下 DOM 的模拟;但是 AST -> HTML -> DOM 这个过程总感觉没什么意义,太冗杂了;想着去看看 React 这些,有个 vDOM 或许服务端渲染会用得上,打开源码的瞬间意识到,React 不直接操作 DOM,保存的是对 DOM 对象的引用,所以不存在选择器这种东西。
最后还是回到 jsdom 上,看了看 jsdom 下 querySelectorAll 是如何实现的
const { addNwsapi } = require("../helpers/selectors");
// Warning for internal users: this returns a NodeList containing IDL wrappers instead of impls
querySelectorAll(selectors) {
if (shouldAlwaysSelectNothing(this)) {
return NodeList.create([], { nodes: [] });
}
const matcher = addNwsapi(this);
const list = matcher.select(selectors, idlUtils.wrapperForImpl(this));
return NodeList.create([], { nodes: list.map(n => idlUtils.tryImplForWrapper(n)) });
}
这里有一个 selectors 里面用到了Nwsapi, 这是一个高性能的 CSS 选择器引擎,其传递了一个 document 对象的实现进去?所以按照我们的需求只要把 AST 转化成 document 就行了;何必走 HTML 这个标记语言的中间层。
这个 CSS 选择器写的还是比较魔幻的,所以阅读起来有点恶心。而且实现完整的 document 其实没什么意义,他也不可能啥都用到的,这时候 ES6 的新特性 Proxy 就很方便了。它提供了对整个对象的代理,对其的所有操作都会被转化成几个处理函数,我们可以用它来记录 nwsapi 具体使用了那些接口和属性,然后针对性的实现他们。
let wrapper = (item) => item instanceof Object ? new Proxy(item, {
get: (obj, key) => {
if (key in obj) {
console.debug(obj, key);
} else {
console.debug(obj, new Error(key).stack);
}
let result = wrapper(obj[key]);
return result;
}
}) : item;
一个简单粗暴的包装函数,只要用他把需要处理的对象包裹一下,他就会递归处理所有的属性,存在的打印方法名,不存在的打印方法名和调用链,然后可以根据调用链,确定其作用以及来源。
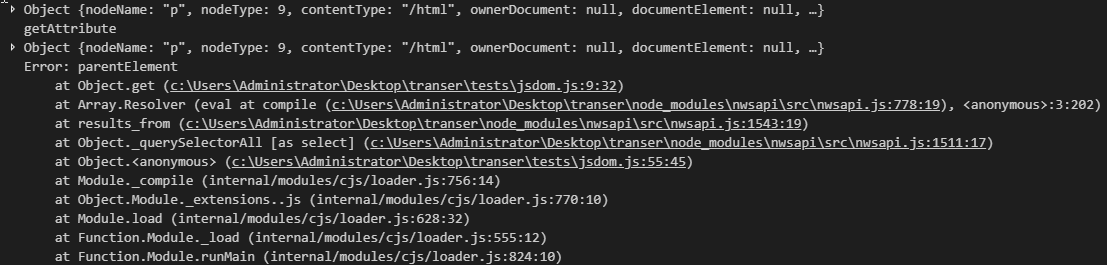
这样我们能针对性的模拟需要的属性,而不必完整的实现它。这个技巧在修改别人的项目上非常好用,之前做 ambari 的汉化,6k 多个文件,全理清除是很费时间的;直接包装一下,检查一下调用链,问题都解决了;甚至可以用来追踪 Promise 链(尚未成功)。思路应该是来源于黑盒测试,以及一些逆向的操作。
function (node) {
var doc = node.ownerDocument || node;
return doc.nodeType == 9 &&
// contentType not in IE <= 11
'contentType' in doc ?
doc.contentType.indexOf('/html') > 0 :
doc.createElement('DiV').nodeName == 'DIV';
}
最早是这块,判断传递进来的是不是一个 DOM 对象,我们加个 nodeType:9 和 contentType:'/html'来解决它。
这时候 vDocument已经变成这样了;
let vDocument = {
nodeType: 9,
contentType: '/html'
}
FakeDOM
类似的还要添加 ownerDocument,documentElement 这 2 个属性只是为了避免打印栈错误,其实没什么用。
而最主要的是这 4 个方法 getElementsByTagName,getElementsByClassName,getElementById,getAttribute。假装实现了一下,的确可以用了。
let document = {
nodeName: 'p',
nodeType: 9,
contentType: '/html',
ownerDocument: null,
documentElement: null,
getElementsByTagName(tagName) {
return Object.assign([element], { tagName });
},
getElementsByClassName(className) {
return Object.assign([element], { className });
},
getElementById(id) {
return Object.assign([element], { id });
},
getAttribute(attribute) {
return "testClass"
}
};
let element = {
_name: 'element',
parentElement: document
};
之后就得细化这几个方法,让它实际有效。
CSS 选择器是自右向左匹配的,这个虽然都可能听说过,但是可能并不一定知道为什么,来分析一下这个高性能选择器。
因为 DOM 原生提供了对树的部分节点的引用,通过
id,class,tagName三种方式。相比自上向下的遍历,直接读取 HashMap 的性能更好,而且无需重复遍历,只要初始化 DOM 结构时,记录一下即可。
之后再通过
parentElement递归取出父元素,匹配前面的选择器。所以选择器能短就短,要不会产生额外的匹配损耗。
参照上面对于 CSS 选择的实现的理解,我们需要实现遍历 AST,然后提供上述 4 个方法和对父级的反向引用。
至于为何不去修改 AST 的生成设施 typescript ,因为工作量太大啊!我还没看明白 TS,让我去改 TS 解释器,不是脑子有点问题?
而且这样会和各种解析器强耦合,不适合抽象出基础组件和接口,参照 ASTExplorer 的项目结构。
黑盒探针
这是之前也用到的一个技巧,对于复杂的组件内部的对象,我们可以通过分析其源码和运行机制获取到内部的参数和配置;也可以通过数据驱动常用的方法,将对数据的操作转化为方法,并输出相关的日志;这实际上就被当成黑盒,而 Proxy 的回调就是一个个探针,协助我们获取内部的实现。
let wrapper = (item) => item instanceof Object ? new Proxy(item, {
get: (obj, key) => {
// For Dom
if ('getAttribute' === key) {
return (attribute) => {
if ('class' === attribute) {
return wrapper(Object.keys(obj).join(' '));
}
if (attribute in obj) {
return wrapper(obj[attribute]);
}
console.error(obj, key, attribute, new Error().stack);
};
}
if (key in obj) {
// console.debug(obj, key);
} else {
console.error(obj, key, new Error().stack);
}
let result = wrapper(obj[key]);
return result;
}
}) : item;
而最后实现的 FakeDOM 也是通过这样实现的覆盖了 CSS 选择器所必要的方法和属性的最小 DOM 结构。
遍历转化
constructor(parser, ast) {
walkAST.call(parser, ast, (node, key, parent) => {
node.nodeName = parser.getNodeName(node);
node.pkey = key;
// 模拟 DOM
node.parentElement = parent;
// 处理必要的接口
if (!this.tagMap[node.nodeName]) {
this.tagMap[node.nodeName] = [];
}
this.tagMap[node.nodeName].push(node);
});
this.__proto__.__proto__ = ast;
}
function walkNodes(nodes, parent, key, handler) {
nodes.forEach(node => walkNode.call(this, node, parent, key, handler));
}
function walkNode(node, parent, key, handler) {
if (Array.isArray(node)) {
return walkNodes.call(this, node, parent, key, handler);
}
handler(node, key, parent);
// 处理子元素
Object.keys(node).forEach(key => {
if (this.walkByDefault(node, key)) {
return walkNode.call(this, node[key], node, key, handler);
}
})
}
function walkAST(ast, handler) {
walkNode.call(this, ast, undefined, undefined, handler);
}
递归遍历整个节点树,并执行输入的回调方法,进行替换和覆盖操作,其实这块应该被抽象到 parser 内部,对外暴露统一的 DOM 结构。
表达式映射
PropertyAssignment-> 类型为PropertyAssignment的节点.initializer > StringLiteral父节点包含.initializer属性的StringLiteral节点.initializer[type=PropertyAssignment] > StringLiteral父节点为PropertyAssignment且存在.initializer属性的StringLiteral节点
这时候会遇到一个问题

这里的 .initializer 和 .name 均会被相同的表达式获取,因为 HTML DOM 中只存在一个子节点树,而 AST 的子节点数的不定数目的。
所以需要增加一个约束性的语法来解决这个问题。
比如在遍历的时候将,key 写入子节点,这样就可以用 .initializer > StringLiteral[$key] 来表达这个意图。
但是发现 $ 和 # 都是有意义的表达式,于是暂时没想好用啥符号。只能叫他 pkey 了。。。
结果如下
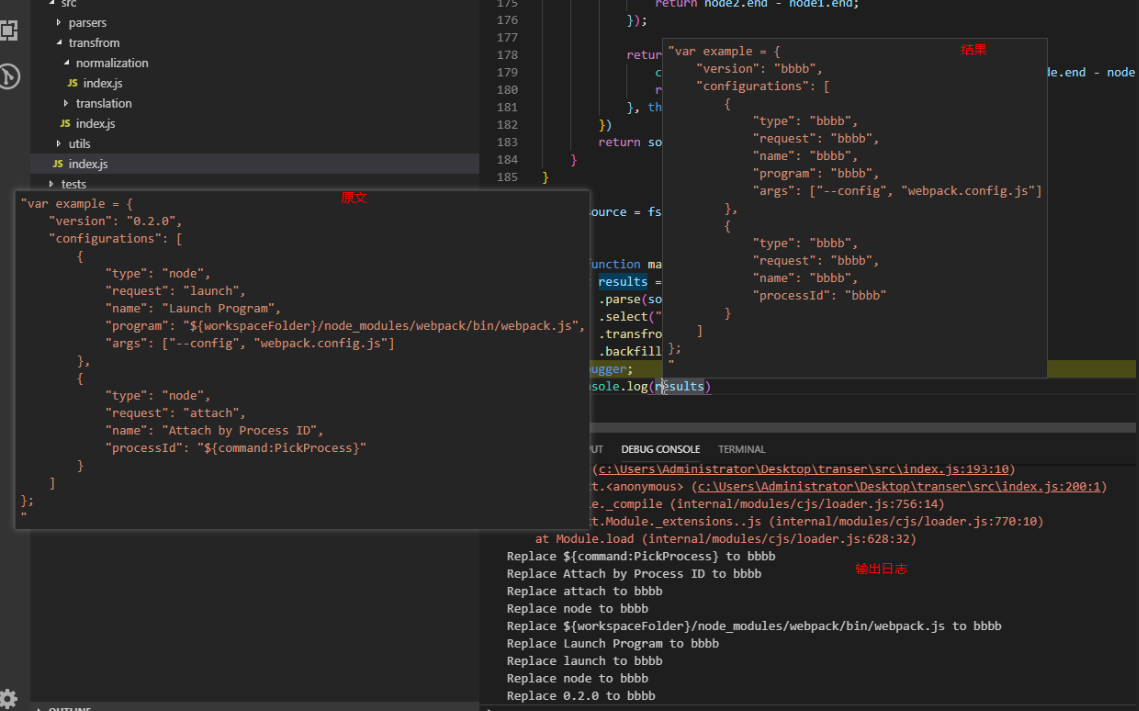
var example = {
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"program": "${workspaceFolder}/node_modules/webpack/bin/webpack.js",
"args": ["--config", "webpack.config.js"]
},
{
"type": "node",
"request": "attach",
"name": "Attach by Process ID",
"processId": "${command:PickProcess}"
}
]
};
上述代码通过表达式 PropertyAssignment > StringLiteral[pkey=initializer] 选择之后,得到这些结果
应该算是比较符合要求的了。
文本处理工具包
刚开始只是为了做个自动化翻译,但是最后发现处理汉化,还有一些其他操作的可能性;于是借鉴了 Koa 的中间件模型。
_compose(middleware) {
return function (context) {
return dispatch(0)
function dispatch(i) {
let fn = middleware[i]
if (!fn) {
return Promise.resolve()
}
return Promise.resolve(fn(context, function next() {
return dispatch(i + 1)
}))
}
}
}
可以使用如下方式定义插件调用。
module.exports = async function middleware(node, next) {
this.aaa = "aaaa";
await next;
node.text = "bbbb";
}
然后在 transfrom 方法调用对应的中间件路径或者函数,他们都会异步执行,并且形成一个捕获和冒泡的调用链,每个插件也有对应的捕获和冒泡阶段。
在这突然明白了之后会写的 Chrome onMessage 事件会直接返回,而异步事件需要返回 true 之后才等待结果。
类似的结构在浏览器的冒泡上却不需要这个操作,因为 onMessage 方法,外部能检测到的只有 return 和 callback,而事件循环中,事件的状态由一个 cancelBubble 确定,默认的 Koa 中间级机制时不允许提前返回,我们可以在上面的每个函数执行之后检查一下 ctx 的 return 属性,来判断是否需要提前终止调用链。
逆向替换
因为我们获取到一个储存了全部需要处理的数据集合
[
{
text: "text",
start: 0,
end: 3
}
]
如果直接通过 start 和 end 替换会导致,后面的游标失效,所以先 sort 一下,然后 reduce 替换。
之后得到如下操作
async backfill() {
let sources = await Promise.all(this.transTokens).then(transTokens => {
transTokens = transTokens.sort((node1, node2) => {
return node2.end - node1.end;
});
return transTokens.reduce((source, node) => {
console.log('Replace', source.splice(node.start + 1, node.end - node.start - 2, ...node.text.split('')).join(''), 'to', node.text);
return source;
}, this.source.split(''))
})
return sources.join('');
}
这里还有个操作,把字符串切分成数组,然后用数组的 splice 方法,直接替换指定位置的子数组。
最后调用方式
async function main() {
// 初始化实例
let results = await new Transer()
// 载入源码
.parse(source)
// 设置选择符
.select("PropertyAssignment > StringLiteral[pkey=initializer]")
// 需要使用的注册组件
.transfrom("normalization")
// 填入
.backfill();
console.log(results)
}
main();
VSC 的文本处理插件(未完成)
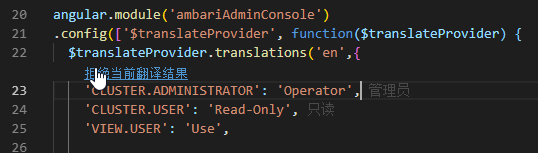
- 实时显示对应节点的处理结果,并提供自定义输入的方式
虽然不能开源,但是可以写一篇 VSC 插件开发的文章出来描述一下。
