

前两天一个新上线的后段项目开始出现频繁的fullgc,导致系统瘫痪,服务处于不可用状态,经过一系列的排查发现jvm参数设置有问题,经过参数调优之后系统恢复正常。在讲解具体的调优步骤之前,让我们先来了解一下jvm相关的一些基础知识。
一 jvm的常用参数
JVM的参数非常之多,这里只列举比较重要的几个,通过各种各样的搜索引擎也可以得知这些信息。
| 参数名称 | 含义 | 默认值 | 说明 |
|---|---|---|---|
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 |
| -Xmn | 年轻代大小(1.4or lator) | 注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。整个堆大小=年轻代大小 + 老年代大小 + 持久代(永久代)大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 | |
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 | |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长)和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了 | |
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | -XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 | |
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10 | |
| -XX:+DisableExplicitGC | 关闭System.gc() | 这个参数需要严格的测试 | |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 | 单位字节 新生代采用Parallel ScavengeGC时无效另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象. |
| -XX:ParallelGCThreads | 并行收集器的线程数 | 此值最好配置与处理器数目相等 同样适用于CMS | |
| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) | 如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值. |
二 垃圾回收器
HotSpot VM中的垃圾回收器,以及适用场景
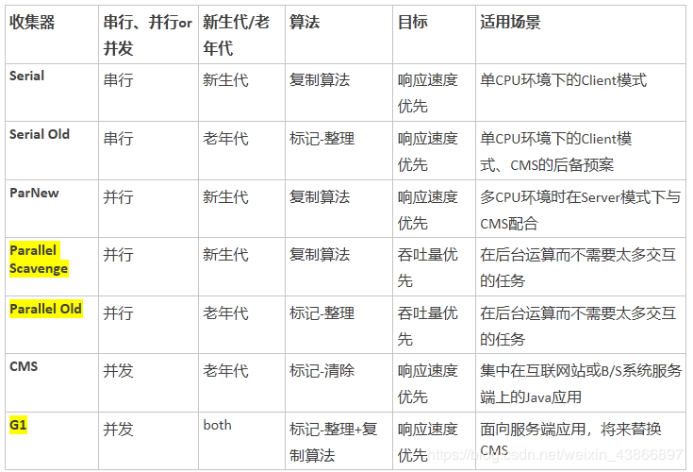
到jdk8为止,默认的垃圾收集器是Parallel Scavenge 和 Parallel Old。从jdk9开始,G1收集器成为默认的垃圾收集器。目前来看,G1回收器停顿时间最短而且没有明显缺点,非常适合Web应用。在jdk8中测试Web应用,堆内存6G,新生代4.5G的情况下,Parallel Scavenge 回收新生代停顿长达1.5秒。G1回收器回收同样大小的新生代只停顿0.2秒。
三 调优过程
我们的应用比较耗内存,所以在项目上线之前设置的参数 -Xms10g -Xmx10g -Xmn5g,在开发和测试环节并没有出现什么问题,上线之后前期的适用阶段也没有出现过什么问题,前两天开始了大规模的线上运用,问题开始暴露了出来,一开始查看gc.log,发现系统在持续的fullgc,之后暂停线上的任务,继续观察日志情况,发现内存回收还在持续进行。
jvm的垃圾回收器我们采用的是G1,对于我们这种高内存需求的应用来讲,G1更加适合,有想深入了解的小伙伴可以再多看一些相关的文章了解一下,那么我们可以来看一下G1的日志,这样有助于我们发现问题。
G1模式下遇到的频率最高的GC,GC日志如下所示:

1. 信息总览:
a. 通过设置 ‘-XX:+PrintGCDateStamps’ 得到GC发生的准备日期时间 - 2016-12-12T10:40:18.811-0500
b. JVM启动到当前时间的相对时间 - 29.959
c. 收集的类型 - G1 Evacuation Pause (young)
d. 垃圾收集消耗的总时长 - 0.0305171 sec
2. 并行任务:
a. Parallel Time - 并行任务STW总时长 - 26.6ms
b. GC Workers - 并行GC workers的总数量,通过 "-XX:ParallelGCThreads"设置 - 4
i. 当cpu内核数 <= 8,设置为cpu核数;>8时,设置为核数的5/8
c. GC Worker Start - GCworker开始工作时间相对于JVM启动的最大最小时间,diff就是第一个线程启动与最后一个线程启动时间之差,这个差值肯定越小越好
d. Ext Root Scanning - 外部根区(堆外区,线程栈根,JNI,全局变量,系统目录,classloader等)扫描消耗时间
e. Update RS (Remembered Set or RSet) - 在每次开始收集之前都要进行Rset更新,保证RSet是最新的。-XX:MaxGCPauseMillis参数是限制G1的暂停时间,一般RSet更新的时间小于10%的目标暂停时间是比较可取的。如果花费在RSetUpdate的时间过长,可以修改其占用总暂停时间的百分比-XX:G1RSetUpdatingPauseTimePercent。这个参数的默认值是10。
f. Scan RS - 扫描每个Region的RSet,寻找被待收集集合引用的区域
g. Code Root Scanning - 扫描被待收集集合引用的编译源码根节点
h. Object Copy - 将待收集集合中所有存活的对象拷贝到新的区域
i. Termination - 当一个GC worker结束工作后,需要等待其他线程,并尝试帮其他线程完成为完成的task. 结束时间指的就是这个线程结束收集到真正结束的时间差
j. GC Worker Other - 花在GC之外的工作线程的时间,比如因为JVM的某个活动,导致GC线程被停掉。这部分消耗的时间不是真正花在GC上,只是作为log的一部分记录
k. GC Worker Total - 每个并行回收线程的时间统计
l. GC Worker End - GC相对于JVM启动的结束时间. diff指第一个和最后一个完成的线程之间差值,越小越好
3. 串行任务:
a. Code Root Fixup - 遍历那些指向CSet的方法,修正指针
b. Code Root Purge - 清理code root table
c. Clear CT - 清除card table里的脏cards
4. 其他串行操作:
a. Choose CSet - 选取CSet
b. Ref Proc - 处理STW引用处理器发现的soft/weak/final/phantom/JNI引用
c. Ref Enq - 将引用排列到相应的reference队列里
d. Reditry Cards - 在回收过程中被修改的cards标记为脏卡
e. Humongous Register - 在youngGC的时候会收集巨型区域。这个指标是指评估巨型区域是否足够记录的时间。
f. Humongous Reclaim - 确认巨型对象死亡并清理,释放巨型对象区域,重置区域类型,将该区域放回空闲队列所用的时间
g. Free CSet - 释放CSet,其中也会清理CSet中的RSet,将其放回空闲队列
5. 各个代的变化统计
a. Eden: 1097.0M(1097.0M)->0.0B(967.0M)
i. 该次Young GC被触发是因为Eden区满了
ii. Eden区通过该次垃圾回收被清空,变为0.0B
iii. Eden区的总容量变化1097M -> 967M
b. Survivors: 13.0M->139.0M
i. Survivor space从13M增长到139M
c. Heap: 1694.4M(2048.0M)->736.3M(2048.0M)
i. 收集的时候,整个堆总量为2048M,被使用了1694M
ii. 回收完毕,整个堆总量为2048M,被使用了736.3M
6. 垃圾回收花费的时间
a. user=0.08 - 在回收过程中花费在用户代码上的CPU时间,是所有thread在所有CPU上的花费时间之和。并没有计算处理器之外花费的时间和等待时间
b. sys=0.00 - 在回收过程中花费在内核处理上的CPU时间,是所有thread在所有CPU上的花费时间之和。并没有计算处理器之外花费的时间和等待时间
c. real=0.03 - 从垃圾回收到结束的真实时间,包括其他处理器花费的时候及等待时间
并发标记的分析,并发标记可以由不同的方式触发,但是它的表现是一致的。
根据刚刚涉及的jvm的知识点,我们可以尝试对JVM进行调优,主要就是堆内存那块。所有线程共享数据区大小=新生代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m。所以java堆中增大年轻代后,将会减小年老代大小(因为老年代的清理是使用fullgc,所以老年代过小的话反而是会增多fullgc的)。此值对系统性能影响较大,Sun官方推荐配置为java堆的3/8。
-Xmx –Xms:指定java堆最大值(默认值是物理内存的1/4(<1GB))和初始java堆最小值(默认值是物理内存的1/64(<1GB))。默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。简单点来说,你不停地往堆内存里面丢数据,等它剩余大小小于40%了,JVM就会动态申请内存空间不过会小于-Xmx,如果剩余大小大于70%,又会动态缩小不过不会小于–Xms。就这么简单开发过程中,通常会将 -Xms 与 -Xmx两个参数的配置相同的值,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源。
之后将jvm的参数设置为了-Xms10g -Xmx20g -Xmn8g,其他的参数仍保持之前的设置,经过一段时间的运行之后,没有再出现频繁的fullgc情况,程序运行也比较平稳,在这里我写的比较粗糙,由于时间的原因没有对全部的流程进行完整的描述,希望大家能够掌握一些基本的知识点,遇到问题按照步骤进行分析拆解就可以很好的处理这些问题。
