

团队:skFeTeam 本文作者:李世伟
作为前端程序员,webpack,rollup,babel,eslint这些是不是经常用到?他们是打包工具,代码编译工具,语法检查工具。他们是如何实现的呢?本文介绍的抽象语法树,就是他们用到的技术,是不是应该了解一下呢?
本文没有晦涩难懂的理论,也没有大段大段的代码,完全从零开始,小白阅读也无任何障碍。通过本文的阅读,您将会了解AST的基本原理以及使用方法。
前言
什么是抽象语法树?
- AST(Abstract Syntax Tree)是源代码的抽象语法结构树状表现形式。下面这张图示意了一段JavaScript代码的抽象语法树的表现形式。
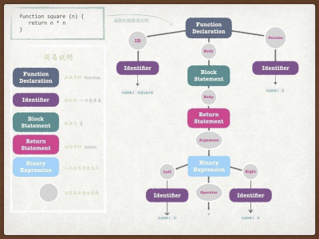
抽象语法树有什么用呢?
- IDE的错误提示、代码格式化、代码高亮、代码自动补全等
- JSLint、JSHint、ESLint对代码错误或风格的检查等
- webpack、rollup进行代码打包等
- Babel 转换 ES6 到 ES5 语法
- 注入代码统计单元测试覆盖率
目录
- 1.AST解析器
- 2.AST in Babel
- 3.Demo with esprima
- 4.思考题
1.AST解析器
1.1 JS Parser解析器
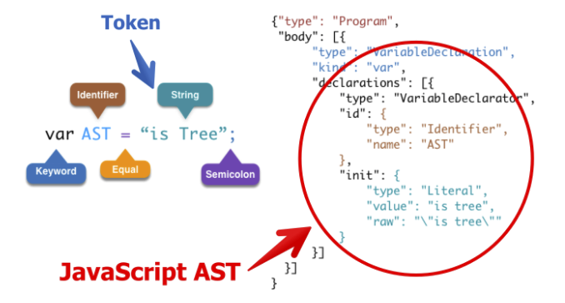
AST是如何生成的?
- 能够将JavaScript源码转化为抽象语法树(AST)的工具叫做JS Parser解析器。
JS Parser的解析过程包括两部分
- 词法分析(Lexical Analysis):将整个代码字符串分割成最小语法单元数组
- 语法分析(Syntax Analysis):在分词基础上建立分析语法单元之间的关系
常见的AST parser
- 早期有uglifyjs和esprima
- Espree,基于esprima,用于eslint
- Acorn,号称是相对于esprima性能更优,体积更小
- Babylon,出自acorn,用于babel
- Babel-eslint,babel团队维护,用于配合使用ESLint
1.2 词法分析(Lexical Analysis)
语法单元是被解析语法当中具备实际意义的最小单元,简单的来理解就是自然语言中的词语。
Javascript 代码中的语法单元主要包括以下这么几种:
- 关键字:例如 var、let、const等
- 标识符:没有被引号括起来的连续字符,可能是一个变量,也可能是 if、else 这些关键字,又或者是 true、false 这些内置常量
- 运算符: +、-、 *、/ 等
- 数字:像十六进制,十进制,八进制以及科学表达式等
- 字符串:因为对计算机而言,字符串的内容会参与计算或显示
- 空格:连续的空格,换行,缩进等
- 注释:行注释或块注释都是一个不可拆分的最小语法单元
- 其他:大括号、小括号、分号、冒号等
1.3 语法分析(Syntax Analysis)
组合分词的结果,确定词语之间的关系,确定词语最终的表达含义,生成抽象语法树。
1.4 示例
- 以赋值语句为例,使用esprima来解析:
var a = 1;
- 词法分析结果如下,可以看到,分词的结果是一个数组,每一个元素都是一个最小的语法单元:
[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "1"
},
{
"type": "Punctuator",
"value": ";"
}
]
- 语法分析结果如下,把分词的结果按照相互的关系组成一个树形结构:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
1.5 工具网站
- 经典的JavaScript抽象语法树解析器,网站提供的功能也非常丰富
- 可以在线查看分词和抽象语法树
- Syntax展示抽象语法树,Tokens展示分词
- 还提供了各种parse的性能比较,看起来Acorn的性能更优秀一点。
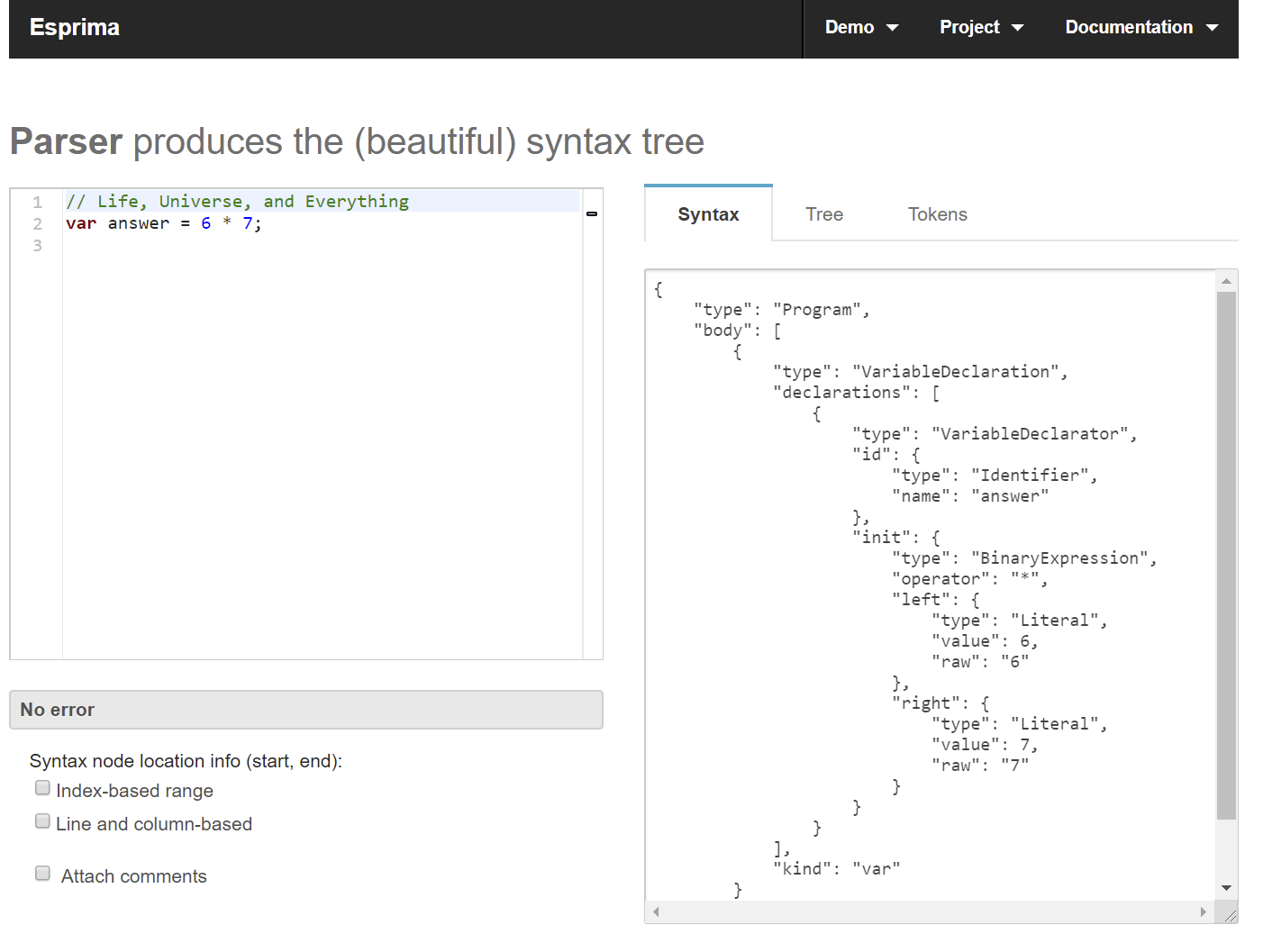
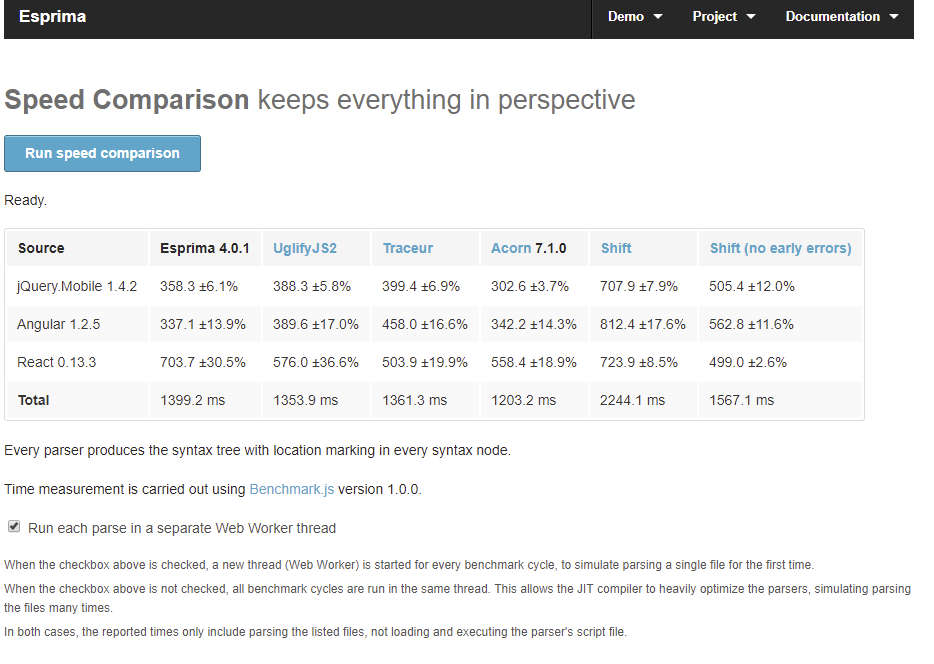
- AST的可视化工具网站,可以使用各种parse对代码进行AST转换
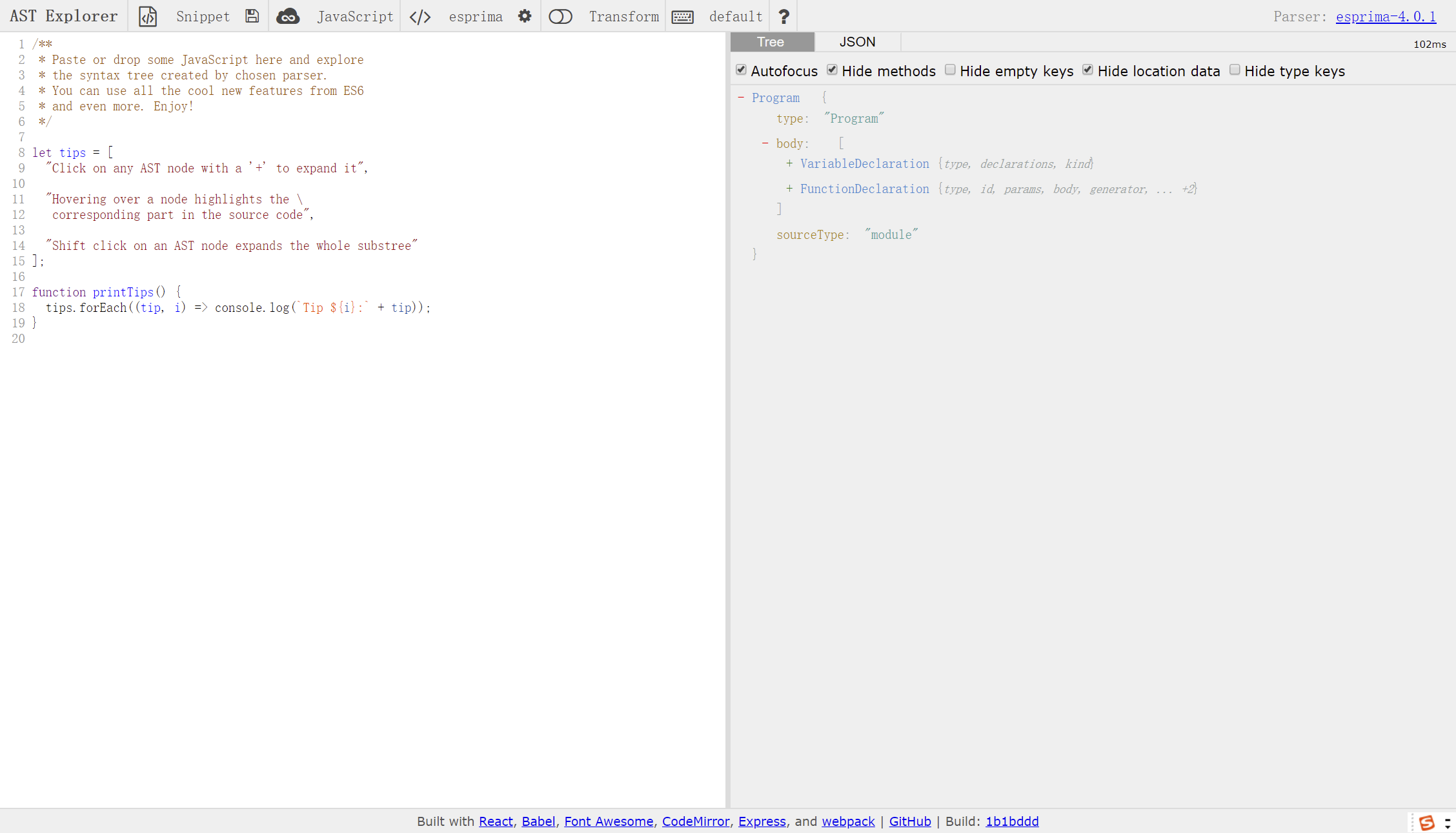
AST解析规范(The Estree Spec)
- 相同的JavaScript代码,通过各种parser解析的AST结果都是一样的,这是因为他们都参照了同样的AST解析规范
- The Estree Spec 规范是 Mozilla 的工程师给出的 SpiderMonkey 引擎输出的 JavaScript AST 的规范文档,也可以参考:SpiderMonkey in MDN
2.AST in Babel
前面已经介绍了AST的内容,下面我们来看看babel是如何使用AST的。
Babel的运行原理
Babel的工作过程经过三个阶段,parse、transform、generate
- parse阶段,将源代码转换为AST
- transform阶段,利用各种插件进行代码转换
- generator阶段,再利用代码生成工具,将AST转换成代码
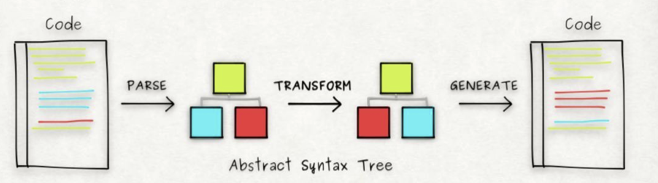
Parse-解析
- Babel 使用 @babel/parser 解析代码,输入的 js 代码字符串根据 ESTree 规范生成 AST
- Babel 使用的解析器是 babylon
Transform-转换
- 接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。也是Babel插件接入工作的部分。
- Babel提供了@babel/traverse(遍历)方法维护AST树的整体状态,方法的参数为原始AST和自定义的转换规则,返回结果为转换后的AST。
Generator-生成
- 代码生成步骤把最终(经过一系列转换之后)的 AST 转换成字符串形式的代码,同时还会创建源码映射(source maps)。
- 遍历整个 AST,然后构建可以表示转换后代码的字符串。
- Babel使用 @babel/generator 将修改后的 AST 转换成代码,生成过程可以对是否压缩以及是否删除注释等进行配置,并且支持 sourceMap。
3.Demo with esprima
了解了babel的运行原理,我们根据babel的三个步骤来动手写一个demo,加深对AST的理解。
我们准备使用esprima来模拟两个代码转换的功能:
- 把 == 改为全等 ===
- 把parseInt(a) 改为 parseInt(a,10)
转换前的代码,before.js:
function fun1(opt) {
if (opt.status == 1) {
console.log('1');
}
}
function fun2(age) {
if (parseInt(age) >= 18) {
console.log('2');
}
}
期望转换后的代码,after.js:
function fun1(opt) {
if (opt.status === 1) {//==变成===
console.log('1');
}
}
function fun2(age) {
if (parseInt(age, 10) >= 18) {//parseInt(a)变成parseInt(a,10)
console.log('2');
}
}
- 开始动手,先引入工具包
//引入工具包
const esprima = require('esprima');//JS语法树模块
const estraverse = require('estraverse');//JS语法树遍历各节点
const escodegen = require('escodegen');//JS语法树反编译模块
const fs = require('fs');//读写文件
- 使用esprima parse把源代码转换成AST。怎么样,是不是很简单,一句代码就搞定了。
const before = fs.readFileSync('./before.js', 'utf8');
const ast = esprima.parseScript(before);
- 遍历AST,找到符合转换规则的代码进行转换
estraverse.traverse(ast, {
enter: (node) => {
toEqual(node);//把 == 改为全等 ===
setParseInt(node); //把 parseInt(a) 改为 parseInt(a,10)
}
});
- 再来看看toEqual和setParseInt函数的实现
function toEqual(node) {
if (node.operator === '==') {
node.operator = '===';
}
}
function setParseInt(node) {
//判断节点类型,方法名称,方法的参数的数量,数量为1就增加第二个参数
if (node.type === 'CallExpression' && node.callee.name === 'parseInt' && node.arguments.length === 1) {
node.arguments.push({//增加参数,其实就是数组操作
"type": "Literal",
"value": 10,
"raw": "10"
});
}
}
- 最后,把转换后的AST生成字符串代码,写入文件。
//生成目标代码
const code = escodegen.generate(ast);
//写入文件
fs.existsSync('./after.js') && fs.unlinkSync('./after.js');
fs.writeFileSync('./after.js', code, 'utf8');
好了,打开after.js文件看看,是不是已经转换成功了?是不是和我们期望的一样?有没有一种babel的感觉?是的,其实babel也是这么做的,只不过它的转换规则函数相当的复杂,因为需要考虑各种JavaScript的语法情况,工作量巨大,这也就是babel最核心的地方。
再回头看看我们写的demo,是完全遵循babel的三个步骤来做的。第一步parse和第三步generate都非常简单,一句话的事,没什么好说的。重点是Transform,转换规则函数的实现,有人可能会问,你怎么知道,toEqual和setParseInt转换函数要这么写呢?
好的,为了回答这个问题,我们来看看这两个规则的代码转换前后的AST就明白了。
- 把 == 改为全等 ===
a==b的AST如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "BinaryExpression",
"operator": "==",
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "Identifier",
"name": "b"
}
}
}
],
"sourceType": "script"
}
a===b的AST如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "BinaryExpression",
"operator": "===",
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "Identifier",
"name": "b"
}
}
}
],
"sourceType": "script"
}
比较上面两个AST,是不是只有一个"operator"字段有区别,一个是==, 另一个是===。
再来看看toEqual函数,是不是明白了?只要修改一下node.operator的值就能完成转换了。
function toEqual(node) {
if (node.operator === '==') {
node.operator = '===';
}
}
- 把parseInt(a) 改为 parseInt(a,10)
parseInt(a)的AST如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "parseInt"
},
"arguments": [
{
"type": "Identifier",
"name": "a"
}
]
}
}
],
"sourceType": "script"
}
parseInt(a, 10)的AST如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "parseInt"
},
"arguments": [
{
"type": "Identifier",
"name": "a"
},
{
"type": "Literal",
"value": 10,
"raw": "10"
}
]
}
}
],
"sourceType": "script"
}
比较这两个AST,看到了吗?只是arguments数组多了下面这个元素。
{
"type": "Literal",
"value": 10,
"raw": "10"
}
所以在转换规则函数中,我们把这个元素加进去就能实现转换了。是不是非常简单?
function setParseInt(node) {
//判断节点类型,方法名称,方法的参数的数量,数量为1就增加第二个参数
if (node.type === 'CallExpression' && node.callee.name === 'parseInt' && node.arguments.length === 1) {
node.arguments.push({//增加参数,其实就是数组操作
"type": "Literal",
"value": 10,
"raw": "10"
});
}
}
好了,到此为止,这个Demo应该完全理解了吧。
4.思考题
看到这里,你已经明白了AST的原理以及使用方法。下面来看一道题目,检验一下学习成果。
假设a是一个对象,var a = { b : 1},那么a.b和a['b'] ,哪个性能更高呢?
a.b和a['b']的写法,大家经常会用到,也许没有注意过这两种写法会有性能差异。事实上,有人做过测试,两者的性能差距不大,a.b会比a['b']性能稍微好一点。那么,为什么a.b比a['b']性能稍微好一点呢?
我认为,a.b可以直接解析b为a的属性,而a['b']可能会多一个判断的过程,因为[]里面的内容可能是一个变量,也可能是个常量。
这种说法看起来好像很有道理,事实上是不是这样呢?有没有什么证据来证明这个说法吗?
好吧,要想解释清楚这个问题,就只能从V8引擎说起了。
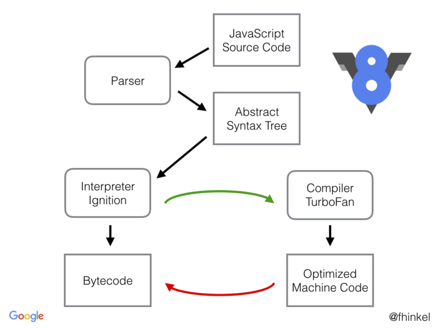
js代码能在cpu上运行,主要是js引擎的功劳,V8引擎是google开发,应用在chrome浏览器和nodejs上,是一个经典的js引擎。上图可以看出,在V8引擎中,js从源代码到机器码的转译主要有三个步骤:Parser(AST) ->Ignition(Bytecode)->TurboFan(Machine Code)
- Parser:负责将JavaScript源码转换为Abstract Syntax Tree (AST)
- Ignition:interpreter,即解释器,负责将AST转换为Bytecode,解释执行Bytecode;同时收集TurboFan优化编译所需的信息,比如函数参数的类型
- TurboFan:compiler,即编译器,利用Ignitio所收集的类型信息,将Bytecode转换为优化的汇编代码
Parser-AST解析器
- 大家应该很熟悉了,就是我们今天介绍的AST解析器
Ignition-解释器
- 把AST解析成一种类汇编语言,样子和汇编语言很相似,叫做Bytecode。这种语言和CPU无关,不同cpu的机器上生成的Bytecode都是相同的。
TurboFan-编译器
- 大家知道,每种cpu的架构和指令集是不同的,对应的汇编语言会有差异。V8在这一步,针对不同的cpu,把Bytecode解析成适合不同cpu的汇编语言。V8可以支持十几种cpu的汇编语言。

现在,我们就来比较一下a.b和a['b']在V8的解析下,到底有什么不同
- a.b的测试代码如下:
function test001() {
var a = { b: 1 };
console.log(a.b)
}
test001();
- a['b']的测试代码如下:
function test002() {
var a = { b: 1 };
console.log(a['b'])
}
test002();
先看下他们生成的Bytecode
- a.b的Bytecode代码如下:
[generated bytecode for function: test001]
Parameter count 1
Frame size 32
16 E> 000001F6C03D7192 @ 0 : a0 StackCheck
33 S> 000001F6C03D7193 @ 1 : 79 00 00 29 fa CreateObjectLiteral [0], [0], #41, r1
000001F6C03D7198 @ 6 : 27 fa fb Mov r1, r0
46 S> 000001F6C03D719B @ 9 : 13 01 01 LdaGlobal [1], [1]
000001F6C03D719E @ 12 : 26 f9 Star r2
54 E> 000001F6C03D71A0 @ 14 : 28 f9 02 03 LdaNamedProperty r2, [2], [3]
000001F6C03D71A4 @ 18 : 26 fa Star r1
60 E> 000001F6C03D71A6 @ 20 : 28 fb 03 05 LdaNamedProperty r0, [3], [5]
000001F6C03D71AA @ 24 : 26 f8 Star r3
54 E> 000001F6C03D71AC @ 26 : 57 fa f9 f8 07 CallProperty1 r1, r2, r3, [7]
000001F6C03D71B1 @ 31 : 0d LdaUndefined
63 S> 000001F6C03D71B2 @ 32 : a4 Return
Constant pool (size = 4)
Handler Table (size = 0)
- a['b']的Bytecode代码如下:
[generated bytecode for function: test002]
Parameter count 1
Frame size 32
16 E> 0000022E1C7D6DC2 @ 0 : a0 StackCheck
33 S> 0000022E1C7D6DC3 @ 1 : 79 00 00 29 fa CreateObjectLiteral [0], [0], #41, r1
0000022E1C7D6DC8 @ 6 : 27 fa fb Mov r1, r0
46 S> 0000022E1C7D6DCB @ 9 : 13 01 01 LdaGlobal [1], [1]
0000022E1C7D6DCE @ 12 : 26 f9 Star r2
54 E> 0000022E1C7D6DD0 @ 14 : 28 f9 02 03 LdaNamedProperty r2, [2], [3]
0000022E1C7D6DD4 @ 18 : 26 fa Star r1
59 E> 0000022E1C7D6DD6 @ 20 : 28 fb 03 05 LdaNamedProperty r0, [3], [5]
0000022E1C7D6DDA @ 24 : 26 f8 Star r3
54 E> 0000022E1C7D6DDC @ 26 : 57 fa f9 f8 07 CallProperty1 r1, r2, r3, [7]
0000022E1C7D6DE1 @ 31 : 0d LdaUndefined
66 S> 0000022E1C7D6DE2 @ 32 : a4 Return
Constant pool (size = 4)
Handler Table (size = 0)
比较一下两者的Bytecode,你会发现它们完全相同,这就说明,这两种写法在Bytecode层及以下的执行,性能是没有差别的。事实上,它们有差别,就只能往上找,上面就只有Parser阶段了。我们再来看看它们的AST有什么区别。
- a.b的AST代码如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "MemberExpression",
"computed": false,
"object": {
"type": "Identifier",
"name": "a"
},
"property": {
"type": "Identifier",
"name": "b"
}
}
}
],
"sourceType": "script"
}
- a['b']的AST代码如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "MemberExpression",
"computed": true,
"object": {
"type": "Identifier",
"name": "a"
},
"property": {
"type": "Literal",
"value": "b",
"raw": "'b'"
}
}
}
],
"sourceType": "script"
}
我们发现唯一的区别就是"computed"属性,a.b是false,a['b']是true,说明在解析成AST时,a['b']比a.b多了一个计算的过程。由此我们断定,两者微小的差异应该就在这里。好了,证据找到了,现在应该没有疑问了吧。
收尾
看到这里,你不但了解了AST的相关知识,还知道了V8引擎是如何解析js代码的,是不是有所收获呢?如果你觉得这篇文章对你有用,还请顺便点个赞,非常感谢(90度鞠躬)。
