

此文针对具有webpack基础和插件开发基础的同学,这是个人在提高前端开发效率的一次实践记录,若有不足请补充
引言
我的博客地址唐益达欢迎你https://www.tangyida.top,欢迎来拍砖。
此项目仓库地址在此Svg2Iconfont-webpack svg转webfont实践,如果这篇文章对你有点点用处的话,欢迎star!同时也欢迎提PR和问题,此文仅仅是我这次开发实践的总结成果,不是webpack插件教学。
PS: 另外寻找靠谱的杭州job,希望有一个浓厚的技术氛围和技术沉淀的公司环境,欢迎私信或者博客加weixin
先看看这个插件的效果图:
写在前面
写这篇文章前,我们先确定此文章的几个核心问题:一、为什么要写这个插件?二、写这个插件有哪些技术痛点?三、这个插件有哪些需要改进的地方?
我们一个个来解答这些问题,同时欢迎大家在提高一些前端开发效率中能提供一些自己的见解。
为什么写这个插件?
你是否有这样的烦恼?一个大项目内有一堆的SVG文件要引入作为图标,又或者图标管理起来好麻烦?
这个插件的起源就是来自这个想法:如何提供一个窗口,统一来管理你的图标ICON,设计师可能不想从阿里巴巴iconfont打包,而是提供了一堆svg,能直观地显示图标,而不是引入svg,采用我们Unicode编码的方式通过css伪元素实现。
同时可以加深对于webpack中整个编译周期的理解和插件开发的理解,对于工程化的能力有进一步的提升。
写这个插件有什么技术痛点?
技术痛点主要有两个:如何将SVG正确转iconfont?如何实现图标列表预览功能?
将svg转iconfont的起点本来想自己通过svg2ttf,ttf2woff类似的底层解析包来进行设计,后来发现阿里iconfont提供了一个font-carrier来解决类似的问题,所以就直接用了,可以解决大部分常见的需求。
预览功能的技术痛点是如何实现热更新,如何监听提供的icon文件夹实时编译?
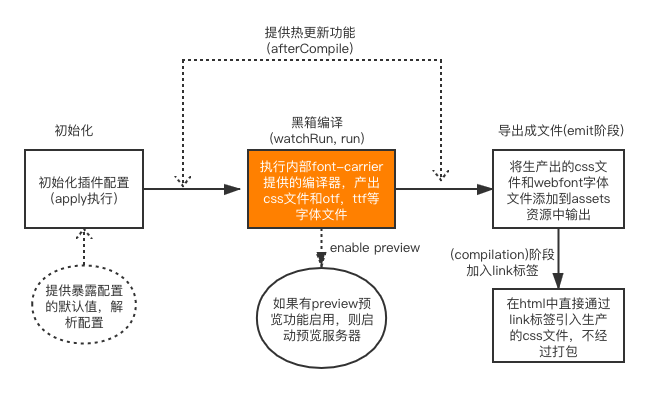
整体技术的流程图如下:
插件入口
module.exports = class Svg2IconfontWebpack {
constructor(options = {}) {
// 这里是构造函数
}
apply (compiler) {
// 插件主体入口
}
}
上述是插件架构的基础模式,我们可以在下列config中使用:
const svg2iconfontWebpack = require('svg2iconfont-webpack');
module.exports = {
// webpack 配置
plugins: [
// options 是配置 对应上述的构造函数
new svg2iconfontWebpack(options)
]
}
我们可以看到apply是整个webpack插件的整体执行入口,参数提供了Compiler实例,这个实例代表了webpack配置实例化后的主引擎,其最重要的方法是各个阶段的hooks,Compiler文档见此,其提供了各个整个编译阶段的钩子,而在每一次编译会产生一个新的实例,这个我们称为Compilation,其提供了每次编译的信息和编译中处理的阶段(loaded,optimized,chunked等)。
确定需要的Compiler钩子
编译的钩子方法继承自Tapable,当然同时你可以在在插件中根据此自定义自己插件的hooks:
const { SyncHook } = require('tapable');
this.hooks = {
before: new SyncHook(['params'])
}
// 调用
this.hooks.before.call(p);
// 外部调用你插件的hooks
pluginInstance.hooks.before.tap('pluginInjected', (params) => {})
这里要注意的是,tap是默认同步语法,如果你的操作有异步操作,你需要的是tapAsync这个钩子,这个钩子有什么区别呢?它提供了一个callback方法,可以支持你的异步操作回调:
compiler.hooks.watchRun.tapAsync('Svg2IconfontWebpack', async (compilation, callback) => {
// 进行异步操作
await asyncOperate();
// 回调
callback()
})
接下来我们需要在Compiler的编译钩子中进行我们自己的处理:从上面流程图看,首先插件要区分生产和开发环境:选取watchRun和run钩子来区分
1. watchRun和run钩子
// 开发环境(watch 模式下)
compiler.hooks.watchRun.tapAsync('Svg2IconfontWebpack',watchRun);
// 生产环境(非watch)
compiler.hooks.run.tapAsync('Svg2IconfontWebpack',run);
上述的watchRun和watch能解决流程图的黑箱编译工作,可以提供生成文件的Buffer流或者字符串内容,这里姑且称为编译阶段吧。
其次编译完我们需要如何处理这些文件内容?当然就是输出到output的assets资源了,从webpack的Compiler钩子可以看出需要“生成资源到 output 目录之前”这个钩子,那么就是emit钩子了。
2. emit钩子
compiler.hooks.emit.tap('Svg2IconfontWebpack', emit);
输出资源后,我们要如何让项目自动引入这段代码呢?我们可以通过webpack-html-plugin的钩子添加一个link标签自动引入这段css代码,那么我们就需要一个compilation钩子,在执行插件内的钩子进行钩入。
3. compilation钩子
compiler.hoos.compilation.tap('Svg2IconfontWebpack', () => {
// meke sure html-webpack-plugin already install
compilation.plugin('html-webpack-plugin-before-html-processing', data => {
// 这里添加assets资源
data.assets.css.push(`${publicPath}css/${output.cssFileName}.css`);
return data;
});
});
// 你会发现html多了一条
// <link href="/css/iconfont-web.css" rel="stylesheet">
大体的钩子就这样确定下来了:
- watchRun和run分别是开发环境和生产环境的build你的svg文件要做的事进行钩入
- emit是你需要提交到assets生产资源的钩子,生成css,webfont资源
- compilation钩子是确保你的html能正确引入这个css文件
整个流程自动化,省去了自己不停import svg的过程,达到无意识完成webfont打包引入的过程。
确定入口配置以及默认值
assetsPath
资源目录,顾名思义,就是用户提供的存放icon的资源根目录,默认取的是项目根目录下的src/assets
preview
是否开启预览图标模式,默认是(false)关闭状态,开启后默认监听本地3000端口,供开发环境下参考
output
输出配置,默认值有fileName(字体文件名),cssFileName(css文件名)
fontOptions
字体配置,如字体大小,fontFamily等。
确认一些工具函数
- log函数,输出日志,类似下图:

编译主函数
看了上面的黑箱操作,我们需要把用户设置的资源目录下的图片全部匹配出来,然后一一进行解析,输出一个总的资源文件,第一步,先进行广度优先遍历:
const { readDirAsync } = require('./utils')
// 所有图片后缀(原因见后)
const imageReg = /\.jpeg|\.png|\.jpg|\.svg/i
/**
* 遍历文件夹下所有icon图片列表
* @param {icon存放的资源地址} iconPath
*/
const wideTraversalIcons = async (iconPath, nestFolder = null) => {
let icons = []
const fileList = await readDirAsync(iconPath)
const fileTypes = fileList.filter(
file => file.isFile() && imageReg.test(file.name),
)
const dirTypes = fileList.filter(file => file.isDirectory())
icons = fileTypes.map(item => {
return {
...item,
oppositePath: nestFolder ? `${nestFolder}/${item.name}` : item.name,
}
})
for (let i = 0; i < dirTypes.length; i++) {
const each = dirTypes[i]
const nestFolderUrl = nestFolder ? `${nestFolder}/${each.name}` : each.name
const nestFiles = await wideTraversalIcons(
`${iconPath}/${each.name}`,
nestFolderUrl,
)
icons = icons.concat(nestFiles)
}
return icons
}
module.exports = wideTraversalIcons;
为什么上述的图片正则匹配是所有类型的后缀呢,而不单单是svg,PS:我这里是给自己留一个后路,我在想有没有这个可能,把一些简单png转svg再转webfont,所以这里暂时匹配了所有图片,请不要见怪。
上述是广度遍历文件夹,输出文件相对路径的逻辑,拿到所有文件(图片)的相对路径,可以和资源绝对路径进行拼接,通过读取文件内容,最后用font-carrier设置Unicode达到目的,最后output资源,逻辑如下:
const fontCreator = (assetsPath, output) => {
// ...
// 这是一些逻辑
// ...
// 拿到图标相对路径地址
const iconList = await matchIconsList(assetsPath);
// 遍历iconList
for (let i = 0; i < iconList.length; i++) {
// 当前图标
const current = iconList[i];
// 绝对路径
const svgPath = `${assetsPath}/${current.oppositePath}`;
// 读取svg文件内容
const cSvg = fs.readFileSync(svgPath).toString();
// ....
}
}
接下去要设置Unicode值,我们知道Unicode有部分编码有自己的意义的,不能乱用,起初的Unicode只有16位,可以表示2^16 = 65536个字符,这样是不够的,所以推出了后面Unicode4.0规范。
新规范定义了一组附加字符编码,附加字符采用2个16位进制表示,这样可以最多定义1048576个字符,对于我们的emoji是足够用的,所以我们的Unicode编码定义从e601开始,依次递增进行编码。
const fontCreator = (assetsPath, output) => {
// ...
for (let i = 0;i < iconList.length; i++) {
// 接上面的逻辑
// 转译成10进制
const HEX2Decimal = parseInt(startUnicodeHex, 16);
// 10进制加 下标是新的Unicode编码,后转成16进制
const HEXCode = Number(HEX2Decimal + i).toString(16);
current['unicode'] = `0${HEXCode}`;
// 设置unicode
font.setSvg(`&#x${HEXCode};`, cSvg);
}
// 输出buffers
const buffers = font.output();
return {
buffers,
iconList,
}
}
上述源码在这里,可以参照看,这些操作我们在watchRun和run钩子中完成
至此,我们的icon => buffer编译就算完成了,接下去就是把内容输出到文件了
输出到资源
return async function(compilation) {
// ... 省略逻辑
// 资源数组
fontOutputAssets.forEach(data => {
// 分别是资源绝对地址和内容
const { assetsAbsolutePath, content } = data;
// 调取compilation的assets属性,直接赋值
compilation.assets[assetsAbsolutePath] = {
// 内容
source: () => {
return content;
},
// 文件大小
size: () => {
return Buffer.byteLength(content);
},
};
});
// 记得报个喜,build成功
success(chalk.green(`${Object.keys(context.cacheBuffers).join(',')} built successfully!`));
// ... 类似逻辑
}
要注意的一点,我们选择生成css文件的需要一些css的模板,如何做到css模板的模块化分析呢?我们可以利用postcss和postcss-js来实现:
function builder () {
const postcss = require('postcss');
const postcssJs = require('postcss-js');
// 这里只是举个例子,具体可以看源码
const style = {
'font-size': 32,
}
return postcss().process(style, { parser: postcssJs });
}
至于html中的link标签,上述已经写过逻辑了,大家参照上面的compilation解析。至今基本完成了,我们通过一个测试的vue项目跑一下,看看是否能否能正确输出:
直接引入i标签如下:
<i class="iconfont-add"></i>

发现可以正确输出图标了,大功告成!
这样就OK了吗?当然不是!!重头戏在后面,我们是不是还要热更新没有实现?是不是还有预览功能没实现?
关于插件自动编译和热更新
我们编写完这些逻辑,发现有一个很严重的问题:
因为我们没有在项目中引入assets资源目录的文件,所以根据webpack-dev-server的源码可以看出,没有dist的依赖文件,他是不会watch到你的资源目录文件变动了。
换句话说,就是你不论在asset目录增加或者删除icon文件,你会发现项目无动于衷,根本不会去编译!这样也太麻烦了吧,自己还要手动编译。
带着问题我看了源码后思考了几种解决方案:
- 看
webpack-dev-server或者webpackHMR源码,看是否有支持的api - 自己声明一个
watchpack,监听我们的目录文件进行重编译 - 看
webpackwatch模式的源码,找一个依赖文件树
带着问题,我去寻找这些解决办法,先是看了webpack-dev-server和webpackHMR的源码,发现它是提供的服务器,并没有进行特别的重编译和一些api的抛出,HMR模式也不适用我这种情况,因为监听的也是源文件依赖,我这些文件根本没有被依赖啊,怎么搞,api也没有,第一种方案排除。
第二种,我能不能用webpack底层的watchpack自定义一个监听者去实现?当然随之问题就来了,你会发现watchpack定义执行编译完报错了:
// You ran Webpack twice. Each instance only supports a single concurrent compilation at a time
当然这是不支持的两个监听者,实例化两次,同时去编译项目,这是不被允许的。
那么只有最后一种可能了,添加依赖树,我去查看了源码的compilation实例,发现有几个属性很有意思:filesDependencies ,contextDependencies,这个顾名思义很像watch的依赖树!
我打印了一下看发现是一个SortableSet,就是Set结构:
sealSortableSet [Set] {
_sortFn: undefined,
_lastActiveSortFn: undefined,
_cache: undefined,
_cacheOrderIndependent: undefined
}
那么我可不可以动态添加呢?在每次afterCompile(编译后),通过
compilation.filesDependencies.add(iconList);
惊奇得发现!它watch了你的这些文件树,达到了添加文件依赖的目的,那么为什么一定要在afterCompile钩子后面呢,因为在这之前的并没有添加依赖树,所以在每次编译产生新的compilation实例后就要进行一个依赖更新,去添加你自己需要的文件依赖。
那么这里我们是以文件夹为依赖对象,所以应该:
compilation.contextDependencies.add(assetsPath);
这样项目也能追踪你的icon目录文件变动了,达到了自动编译的目的。
预览功能
项目大头来了,我们如何实现如下的预览功能呢?
如上图所示,列表是可以根据你的文件夹文件的新增,修改,删除实时反馈更新的,那么我们如何实现这个功能呢?
大概流程图如下:
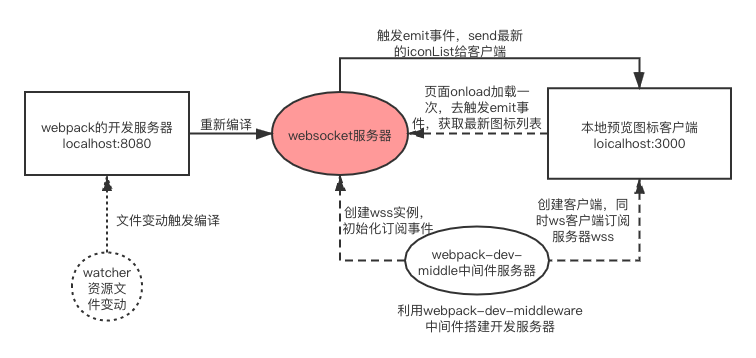
我们通过webpack-dev-middleware实现搭建服务器,然后中间层使用websocket实现双向订阅(不用SSE):
const express = require('express');
const WebSocket = require('ws');
const http = require('http');
const app = express();
// 编译
const compiler = webpack(webpackConfig);
const DevMiddleware = webpackDevMiddleware(compiler, {
//绑定中间件的公共路径,与webpack配置的路径相同
publicPath: webpackConfig.output.publicPath,
logLevel: 'silent', //向控制台显示任何内容
});
app.use(DevMiddleware);
// 默认dist文件下的index
app.use(express.static(path.resolve(__dirname, '../dist')));
const server = http.createServer(app);
const wss = new WebSocket.Server({ server });
// 服务器启动在3000
server.listen(3000, err => {
console.log('success');
if (err) {
console.error(err);
}
});
// wss启动
wss.on('connection', ws => {
ws.on('message', handleMessage);
});
// 订阅message服务
function handleMessage (event) {
// ... 逻辑
send(payload);
}
function send () {
// 发送给wss的每个订阅连接的客户端
wss.clients.forEach(function each(client) {
if (client.readyState === WebSocket.OPEN) {
client.send(JSON.stringify(payload));
}
});
}
客户端:
window.onload = function () {
const ws = new WebSocket(`ws://${window.location.host}`);
ws.onopen = function(event) {
// 第一次启动去获取iconList
console.log('WebSocket is open now.', event, ws);
ws.send('iconList');
};
ws.onerror = function() {
document.getElementById('root').innerHTML = '错误';
};
ws.addEventListener('message', function(event) {
// ... 监听获取到payload
// 去渲染
}
}
客户端代码详情见:Client
recompile
看看上面的流程图,是不是有一个阶段是文件监听变化来触发预览服务器自动编译的阶段,那么肯定需要服务器的recompile方法来执行:
function recompile ({ css, font }) {
// 执行添加 额外files内容的插件
// (见https://github.com/xdnloveme/Svg2Iconfont-webpack/blob/master/src/preview/addAssetsPlugin.js)
this.compiler.apply(new AddAssetsPlugins(fileList));
// 触发send方法,更新客户端
this.context.previewServer.send({
iconList: this.context.iconList,
pluginOptions: this.context.pluginOptions,
});
// 关键一步:invalidate可以执行middleware中间件的重编译
this.middleware.invalidate();
}
上述关键的一点就是去执行this.middleware.invalidate();这一步重新编译,把之前的bufferCache缓存也生成webfont和css文件到目标服务器内存中的assets资源。
另外,最后这里要注意的一点,由于从客户端发送的iconList是只有数据的,但是本地的link样式链接是不变的,也就是说引用的旧的css代码,这时候我们要模拟一个热更新的请求:
function fetchAssets() {
// 获取到link标签
const link2 = document.getElementsByTagName('link')[0];
// 获取link标签的href值
const href = link2.href.split(link2.baseURI)[1];
// 对link标签的href重新赋值,也就是重新请求!
// 可以请求获取到最新打包完的css代码,达到伪热更新的目的
link2.href = href;
}
上述代码关键在于获取到link标签后,对link标签的href标签进行了取值=>重新赋值的过程,这个过程会导致请求,可以做到“伪热更新”的目的,达到了无缝衔接的实时更新的效果🎉。
你可以通过开启preview来启动预览服务器,至此基本插件算完成了,还有一些细节慢慢完善。
这个插件有哪些需要改进的地方?
说实话,个人能力和时间有限,在工作之余整理一个插件真的非常累,所以此项目当然也有一些需要改进的地方,现在我们来梳理一下有哪些需要改进的地方:
一、冗余的编译
我们可以从webpack的编译周期看出,每一次编译都要重新去分析一次assets的文件内容,同时生成新的buffers(css字符串和webfont二进制内容),如果项目图标非常多,势必会带来比较大的性能消耗。
虽然我们知道在webpack5之中已经针对重编译进行了优化,比如增加缓存减少不必要的编译等等,但是在这个插件还是以webpack4为基础,所以如果能加上一些缓存存储文件内容,进行缓存文件hash(tag)映射,文件如果没有变动,就不进行重新遍历编译。
二、加载包过大
我们知道,如果在一个项目中,图标数目过多过大,那么势必会导致打包的bundle.ttf,otf,etc包非常大,对于网页的首次加载和网络传输是非常不利的。
如果我们可以根据分片(split)原理进行不同路由地址对应不同的bundle包进行包的碎片化chunk按需加载,这样势必会带来一个生产环境的性能的提升。
三、有些复杂SVG解析不了,应用面小
我们知道有一些svg图片过于复杂,可能是多渐变多颜色,复杂线条的内容,那么font-carrier的编译效果就比较差,比如颜色都被灰度化成黑白了,颜色丢失,复杂svg解析不利。
同时我们知道一些设计师都是提供的png,jpeg图片,而不是svg文件,所以导致其实这个插件也转译不了,这样会导致这个插件的应用面比较小,所以我在想有没有这个可能去解析一些简单的png,jpg等格式等,扩大这个插件的应用面
如果你对上述的缺点有提供建议或者直接来建设的,欢迎你来提PR!请戳这里
写在最后
总结这个项目的经验:这是在我自己利用平时时间提出的一个提高开发效率的,提高管理icon能力的实践,有很多不足也希望见谅!如果你看完了我这个实践,自己有一点认识学习或者意见建议,都欢迎你提出,我会尽我能力去改善。
如果你觉得这篇文章对你还有点用,对于你的思维有启发的效果,对于你的知识面有扩展的作用,那么欢迎你来star我的项目,非常感谢,你的star对我很重要!欢迎star
这个包已经发布在npm,可以npm i Svg2Iconfont-webpack使用,最后谢谢你能看到这里,你很有耐心,是个做大事的人😝。
另外插播一句:寻找靠谱的杭州job,希望有一个浓厚的技术氛围和技术沉淀的公司环境,欢迎私信或者博客加weixin
