

前言
下列题目是我看几十篇面经,挑出来的我不会的考题。因为我也参加春招这么久了,热门考题差不多都看过了,市面上也有许多的,我就分享一些我乍一眼不会的或者可能说不清的题目吧!答案是自己的百度然后总结的,可能会有些偏差,欢迎指正。
正文
JavaScript
- 弱类型语言的优缺点
- 和强类型语言相比,它允许隐式类型转换,这是一把双刃剑,要是你能一眼看出来发生了啥隐式转换,这就没啥
- 编码时很方便,在开发时不需要过分关注数据类型的问题,可以提升逻辑开发效率。比如强类型语言在数据数据请求时就要命了,需要定义数据类型或者接口,数据结构处理起来真的很难顶
- 内存利用率不如强类型语言,会因为要考虑通用而多分配些内存空间,而强类型则是规定好了的
- addEventListener的第三、四个参数的意义
俩个参数都可以指定时间回调的时机,true -> 时间捕获时执行,默认为false -> 事件冒泡时执行,谁写在前面谁生效(一个是Object,一个Boolean类型,位置随意,写在前面的生效)。 其他详见,MDN

- onload 是所有资源包括图片都加载完才执行
- document.ready方法在DOM树加载完成后就会执行,而window.onload是在页面资源(比如图片和媒体资源,它们的加载速度远慢于DOM的加载速度)加载完成之后才执行。也就是说$(document).ready要比window.onload先执行
- web安全,csrf token能存储在cookie里吗?
csrf token是用来应对csrf攻击的一种方法。csrf攻击简单来说就是黑客拿到你cookie,伪造登录状态,所以叫做跨站请求伪造。这么想的话,应该是不可以才对,但是答案是可以,可以去看看这篇文章,放在cookie里的前提就是cookie是http-only,也就是只能在http下传输,js脚本将无法读取到cookie信息。
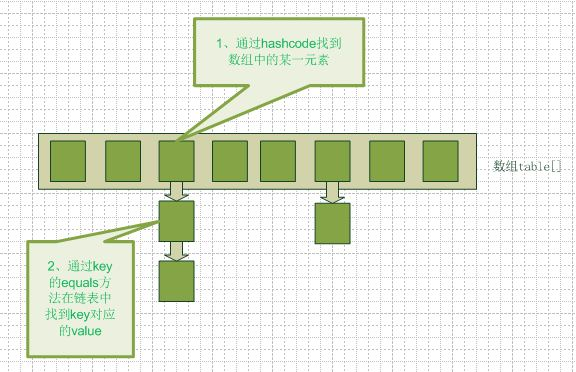
- 从底层谈谈map数据结构的设计。如果容量不够了怎么办,扩容过程中可能会耗费比较多的时间,如果在扩容时要访问怎么办
底层如何实现达到O(1)的增删查
- 数组加链表来存储数据的
- 通过一个hash函数把键值转换成hashCode
- 把hashCode转换成数组索引,即和数组长度做与运算
hashCode & (length - 1)(求模也行,但是效率不如与运算高)。- 冲突了咋整,冲突了就加链表
扩容
map的默认大小是16,loadFactor的默认值为0.75,即默认情况下map中的数组使用率达到
16 * 0.75就进行扩容操作。数组扩容的时间复杂度是O(n)的,然后还要重新计算hashCode与数组索引的对应关系,效率太低了,所以如果事先知道大小可以赋初始值new Map(1000)为啥默认长度是2的幂次方
因为
hashCode & (length - 1)做映射时,当length是2的幂次方,length-1的二进制全为1,能很好的减少冲突,所以扩容一般也是翻倍扩容
- 错误捕获
- 同步错误捕获 同步错误捕获用try...catch()就行了
- 异步错误捕获 异步错误捕获比如说回调函数发生了错误,在外界是捕获不到这个错的,只能在回调函数内部捕获错误;如果是promise的话,promise提供了一个catch来捕获错误,可以捕获reject或语法错误。async await的错误捕获和同步错误一样使用try...catch捕获就行了
- 错误事件和react中的错误捕获 当然不要忘记了还有onerror事件和react-16新增的错误边界,即增加了一个componentDidCatch(error, info)这个新的生命周期方法
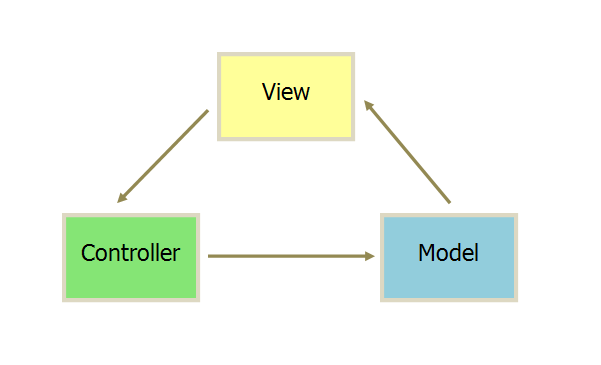
- mvc和mvvm的区别,react是什么架构?
那来分析分析react它是啥架构:个人认为,react强调单向数据流State --> View --> New State --> New View,非要说的我觉得是m-v架构,状态驱动视图。

- ES5 对象的扩展、密封和冻结
- Object.preventExtensions阻止对象扩展,让一个对象变的不可扩展,也就是永远不能再添加新的属性
- 密闭的对象seal():不可扩展,而且已有成员[ [Configurable] ]特性将被设置为false,不能删除属性和方法,不能使用Object.defineProperty()把数据属性修改为访问器属性。
- 冻结的对象freeze():既不可扩展又是密封的。而且对象数据属性[ [Writable] ]特性会被设置为false。如果定义[ [Set] ]函数,访问器属性仍然是可写的。
- ==、===的区别
除了特殊情况外,== 的比较会让让俩边发生类型转换达到相识,再进行比较。而 === 则是直接比较,不进行类型转换,值不等返回false,类型不同返回false,引用类型值比较地址
== 的转换规则
- 如果有一个是布尔型,将他们转换成数字,0 || 1
- 如果一个字符串,一个数字,则将字符串转换成数字
- 如果俩个是对象,则比较地址
- 如果一个是引用类型变量,一个不是,则调用引用类型变量的valueof()方法,或者toString()方法
其他规则
- null 和undefined 是相等的
- 要比较相等性之前,不能将null 和 undefined 转换成其他任何值
- 如果有一个操作数是NaN,则相等操作符返回 false ,而不相等操作符返回 true。重要提示:即使两个操作数都是NaN,相等操作符也返回 false了;因为按照规则, NaN 不等于 NaN
- 如果两个操作数都是对象,则比较它们是不是同一个对象,如果两个操作数都指向同一个对象,则相等操作符返回 true;否则, 返回false
- Array.sort()内部算法
sort使用的是插入排序和快速排序结合的排序算法。数组长度不超过10时,使用插入排序。长度超过10使用快速排序。在数组较短时插入排序更有效率。回答了这个就要做好,被问到时间复杂度的计算,快排的原理的准备
- ES5的继承和ES6的继承的区别
- ES5的继承是通过prototype来基础方法,然后创建子类实例,将父类属性添加到this上
Parent.apply(this)- ES6的继承机制实质上是先创建父类的实例对象this(所以必须先调用父类的super()方法),然后再用子类的构造函数修改this。具体为ES6通过class关键字定义类,里面有构造方法,类之间通过extends关键字实现继承。子类必须在constructor方法中调用super方法,否则新建实例报错。因为子类没有自己的this对象,而是继承了父类的this对象,然后对其调用。如果不调用super方法,子类得不到this对象。
- 为啥script标签的src请求不会跨域,但是ajax发的异步请求会跨域
同源策略是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。 同源策略控制不同源之间的交互,例如在使用XMLHttpRequest 或
标签时则会受到同源策略的约束。这些交互通常分为三类:
- 跨域写操作(Cross-origin writes)一般是被允许的。例如链接(links),重定向以及表单提交。特定少数的HTTP请求需要添加 preflight。
- 跨域资源嵌入(Cross-origin embedding)一般是被允许比如img的src、style的href、script的src。
- 跨域读操作(Cross-origin reads)一般是不被允许的,但常可以通过内嵌资源来巧妙的进行读取访问。例如,你可以读取嵌入图片的高度和宽度,调用内嵌脚本的方法,或availability of an embedded resource.
- http长短连接,以及长连接怎么知道数据是否传完了
长短连接
- 短连接就是每次的建立数据连接->数据传输->关闭连接
- 长连接就是建立连接->传输数据->保持连接->数据传输->关闭连接
- 优点:避免了建立/释放连接的开销
- http1.1默认设置Connection:keep-alive,表示支持持节连接
如何知道数据已经传输完了
短连接在发送完所请求的数据后就关闭了连接,这样客户端会读取到EOF(-1)表示数据传输完了
- content-length
- 顾名思义,它的值的含义就是实体长度和传输长度,当二者相等时表示数据传输完毕了;只适合用于> 服务端清楚知道返回内容的大小,比如客户端请求一个静态页面啊、一张图片啊之类的
- Transfer-Encoding
- 如果是动态页面,服务器预先不知道内容大小,就使用Transfer-Encoding:chunk模式来传输数据。即一边产生数据,一遍发送给客户端
- chunk模式就是把数据分成一块一块的发送,数据由一个个的chunk串联而成,用一个表明长度为'o'的chunk来表示结束
- 不含消息体的消息(1xx、304等响应消息),以空行结束
- 服务器关闭连接,确定消息长度
常见HTTP消息头
- Connection:
- close(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,断开连接,不要等待本次连接的后续请求了)。
- keepalive(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,保持连接,等待本次连接的后续请求)。
- Keep-Alive:如果浏览器请求保持连接,则该头部表明希望 WEB 服务器保持连接多长时间(秒)。例如:Keep-Alive:300
- expire、etag、cacheControl、last-modified、if-no-match、if-modified-since HTTP缓存那一套
- content-type: 服务端以何种方式解析客户端传来的数据
- Content-Type: application/json 对于axios,post的时候axios.post(url,{a:1,b:2}),第二个参数是对象的时候,默认是这个类型
- Content-Type: application/x-www-form-urlencoded 对于axios,post的时候let data = {a:1,b:2}; axios.post(url,qs.stringify({ data })),第二个参数是字符串的时候,默认是这个类型
- Content-Type: multipart/form-data 对于axios,post的时候let data = new FormData(); data.append('a',1'); data.append('b',2); axios.post(url,data),参数是formData类型的时候,默认是这个类型,如果用form自带的action提交,默认是这个类型
- Content-Length: WEB 服务器告诉浏览器自己响应的对象的长度
- Transfer-Encoding: WEB 服务器表明自己对本响应消息体(不是消息体里面的对象)作了怎样的编码,比如是否分块(chunked)。例如:Transfer-Encoding: chunked
- 怎么收集requestAnimationFrame的执行事件,假如掉帧了你怎么办?
先记录一下开始事件,调用100次后在记录一次事件,相减 / 100求出平均时间,这样减少了干扰,但是没有考虑掉帧的情况 应该收集出100段有效时间,什么是有效时间呢,就是requestIdleCallBack执行了说明这一帧是有效的可以收集,这样收集100帧,即可求出requestAnimationFrame。
- target和currentTarget你知道区别嘛?
这其实是事件委托那一套,target是事件触发的目标元素,而eventTarget则是绑定了事件的元素,即目标元素的父节点或者祖先节点
- react合成事件是注册在哪里,你还知道些什么?事件代理?
和原生事件绑定的区别
- react的事件并没有绑到具体的节点,而是绑到了document下,而原生事件则是绑到了具体的节点
- 原生事件(阻止冒泡)会阻止合成事件的执行,合成事件(阻止冒泡)不会阻止原生事件的执行
- 节点上的原生事件的执行是在目标阶段,然而合成事件的执行是在冒泡阶段,所以原生事件会先合成事件执行,然后再往父节点冒泡
为啥要有自己的一套事件机制
- 减少内存消耗,提升性能,不需要注册那么多的事件了,一种事件类型只在 document 上注册一次
- 统一规范,解决 ie 事件兼容问题,简化事件逻辑
- 对开发者友好
合成事件帮你干了些啥事
- 对原生事件的封装 reat会根据不同的事件类型使用不同的合成事件对象,原生事件对象放在了evet.nativeEvent中
- 对某些原生事件的升级和改造 react并不只是处理你声明的事件类型,还会额外的增加一些新的事件,比如你再react中监听onChange事件,它会同时帮你注册blur、change、click、focus等等事件,你可以实时获得其中的内容,如果你只注册了一个原生的onChange事件的话,只有在失去焦点时这个事件才能触发。
- 不同浏览器事件兼容的处理
ie浏览器没有addeventListener,所以在事件注册的时候家里一个判断,没有addEventListern就是使用attachEvent
- 为啥0.1 + 0.2 !== 0.3,原理你知道不?
这个推荐去看这篇文章,我就看了才会的,然后就被问到了。
- react hooks的capture value特性,怎么解决
- react页面卸载周边问题
路由跳转、页面刷新或者关闭会导致页面卸载
如何在页面卸载时弹出提示框?
用户跳转页面时弹出提示框
使用路由守卫,但是此时的页面跳转只能使用link标签了
import {Prompt} from 'react-router-dom';
const Editor=()=>{
return (
<div>
<Prompt
when={true}
message={location => '文章要保存吼,确定离开吗?'}
/>
</div>
)
}
用户关闭页面时弹出提示框
监听beforeUnload事件,先阻止默认事件发生,然后弹出提示框
useEffect(() => {
const listener = ev => {
ev.preventDefault();
ev.returnValue='文章要保存吼,确定离开吗?';
};
window.addEventListener('beforeunload', listener);
return () => {
window.removeEventListener('beforeunload', listener)
}
}, []);
CSS
- CSS计数器
用于写一个目录结构:
- 定义一个计数器counter-reset:section(可定义初始值)
- 在需要累加的地方定义一下 counter-increment: section(可定义增量)
- 展示 counter(section, '.')(counter可不定义分隔符,counter必须定义)
- counter和counters的区别就是显示时是否显示嵌套
<style type="text/css">
#demo1 ol {
counter-reset: section;
list-style-type: none;
}
#demo1 ol li {
counter-increment: section 1;
}
#demo1 ol li:before {
/* content: counters(section, '.'); */
content: counter(section, upper-roman)' . ';
/* content: counter(section, cjk-ideographic) "、"; */
/* content: counter(section, upper-roman) ". "; */
}
</style>
- z-index什么情况下会生效
- z-index属性只作用在被定位了的元素上。所以如果你在一个没被定位的元素上使用z-index的话,是不会有效果的.
- 同一个父元素下的元素的层叠效果会受父元素的z-index影响,如果父元素的z-index值很小,那么子元素的z-index值很大也不起作用
- 建议去实践下,中心思想就是上面这俩条,我实验出的结果是:
- 父标签 position属性为relative;
- 问题标签无position属性(不包括static);
- 问题标签含有浮动(float)属性,当有position属性(除了static)时float是不生效
- 问题标签的祖先标签的z-index值比较小
- position的属性值之间的区别
| 属性值 | 作用 |
|---|---|
| absolute | 生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位。元素的位置通过 "left", "top", "right" 以及 "bottom" 属性进行规定。 |
| fixed | 生成绝对定位的元素,相对于浏览器窗口进行定位。元素的位置通过 "left", "top", "right" 以及 "bottom" 属性进行规定。 |
| relative | 生成相对定位的元素,相对于其正常位置进行定位。因此,"left:20" 会向元素的 LEFT 位置添加 20 像素。 |
| static | 默认值。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right 或者 z-index声明)。 |
| sticky | 滚动一段时间后悬停 |
- fixed的位置确定是相对于视窗来的,不管父容器是否是relative
- relative是生成相对定位, 相对自己正常位置定位,原位置保留,亲测
- css实现动画,怎么让它执行完这个去执行另外一个keyFrame,你怎么知道这个动画什么时候结束
- 移动端适配
- 脱离文档流
脱离文档流这个是css基本常识,不知道的一定要看看,我这篇文章总结的很好
- css隐藏元素的几种方法
- display:none 元素在页面上将彻底消失,元素本来占有的空间就会被其他元素占有,也就是说它会导致浏览器的重排和重绘。 不会触发其点击事件
- visibility:hidden 和display:none的区别在于,元素在页面消失后,其占据的空间依旧会保留着,所以它只会导致浏览器重绘而不会重排。 无法触发其点击事件 适用于那些元素隐藏后不希望页面布局会发生变化的场景
- opacity:0 将元素的透明度设置为0后,在我们用户眼中,元素也是隐藏的,这算是一种隐藏元素的方法。 和visibility:hidden的一个共同点是元素隐藏后依旧占据着空间,但我们都知道,设置透明度为0后,元素只是隐身了,它依旧存在页面中。 可以触发点击事件
HTML
- innerHTML 和 react中的dangerousSetInnerHTML区别是啥?
二者的作用都是往节点里加入html,innerHTML会直接读取字符串的值,把他变成HTML结构,如果字符串中含有script标签,则会执行这段JS脚本,这就是XSS攻击,也叫做跨站脚本攻击 dangerouslySetInnerHTML做的就是不直接转换成你的html代码,来防止XSS攻击。关于web安全大家要去好好看看,我暂时还没总结,回头写一写。
- head里的hmtl会显示出来嘛?head里面的有啥东西
会显示出来,html是真的健壮,真的很难让一个html文件无法显示。但是,如果把html放在了header里,跑代码的时候浏览器会自己帮你把这段html移动到body里,同时把它下面的本来在head里的东西也挤下去了,如下图。有啥后果,head里的style、script标签的执行时间变了。

一图胜千言
- 富文本编辑器的安全隐患
富文本编辑框的安全隐患来自于展示这段内容使用的innerHTML,如果文本中存在script标签则会执行这段JS,也就是存储型的XSS攻击。
- h标签的嵌套,会有啥问题?
这个还是去实践一下哦,你可以先猜猜看,然后跑一下下面的代码。
<div>
<h1>我只被h1包裹了,且在前面<h3>我同时被h3和h1包裹了</h3>我只被h1包裹了,且在后面</h1>
</div>
- img的alt和title属性
虽然简单,但是我忘记了,大家千万要记得呀。alt属性值是必须要的属性,当图片无法正常加载时,出现在图片的位置,当鼠标移到图片上时会显示title的值
- 回流和重绘
浏览器渲染页面
- 浏览器无法直接读取html,需要先构建dom树
- 把读取到的css,变成浏览器可以理解的cssom
- css标准化,比如red -> rgba font-weigth:bold变成数值
- 计算dom树的具体样式
- 生成布局树,把不显示的去掉、把每个元素的信息计算出来
- 生成分层树,页面都是一层一层叠加在一起形成的
- 合成线程就会把分层树的图层变成图块
- GPU的栅格化把视窗附近的图块变成位图,就是也渲染的最小粒度了,然后保存在GPu的进程中
- 栅格化完成之后,浏览器进去去GPU进程里取出页面内容显示在屏幕上,这就完成了渲染阶段
回流
回流就是由具体样式和dom树生成布局树(layoutTree),这个步骤需要计算出每个元素的大小和位置(忽略display:none的元素)
重绘
我们将布局树和样式转换为屏幕上的实际像素,这个阶段就叫做重绘节点。所以,回流必定导致重绘,重绘却不一定回流,且回流的代价比重绘高。
性能优化
- 浏览器自身有优化,它会维持一个待更新队列,类似批处理的方式来优化。但是如果触发了同步布局事件,浏览器就会强制flush这个队列。所以我们要避免触发同步布局事件,我们熟悉的有如下: getBoundingClientRect、offsetTop、offsetLeft、offsetWidth、offsetHeight
- 通过减少重绘重排的发生次数,避免使用如下代码,而应该使用
el.style.cssText += 'border-left: 1px; border-right: 2px; padding: 5px;',或者对修改类名
const el = document.getElementById('test');
el.style.padding = '5px';
el.style.borderLeft = '1px';
el.style.borderRight = '2px';
- 避免频繁操作DOM结构,如果需要可以先把他们
display:none(因为这些元素不会出现不会触发回流重绘),等待dom操作结束后在把他们放出来- 具有复杂动画操作的元素使用绝对定位,使其脱离文档流减少父节点和后续节点的频繁回流
- GPU加速,就是使用一些css开启CUP加速如transform、opacity、filters这些动画不会引起回流重绘
算法
- 回溯
- 双指针
- 动态规划
- 二叉排序
- 树
- 时间复杂度
关于算法的话,面试必考题,笔试必考题。以上是必须掌握的哦。双指针看看这篇文章,很容易懂,学会了超简单,效率很高。
