

一、Celery分布式系统构建简介
1、Celery简介
Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列, 同时也支持任务调度,Celery一个worker就是一个守护进程。
2、组件
在网上可以搜到Celery分布式组件大概是由这三个组件构成,Celery+RabbitMQ+Redis,当然也可以用MySQL,这种中间件的选择可以根据你的业务情况来选择,在这里主要讲的也是这3种组件各自在Celery框架中的作用,以及详细讲解任务流是怎么走的。
3、本例中的框架
Celery broker = RabbitMQ broker是消息中间件,主要的作用是缓存Celery提交的任务队列,行成堵塞作用。 backend = Redis backend是结果存储件,主要的作用是对Celery执行完的数据进行存储,同时还会存储任务的执行结果,如果不需要储存结果,则不需要设置。
4、Celery简单配置文件
RabbitMQ 账号密码都是root,dispatch_server_host是自定义的一个rabbitmq虚拟主机,也可理解为队列。
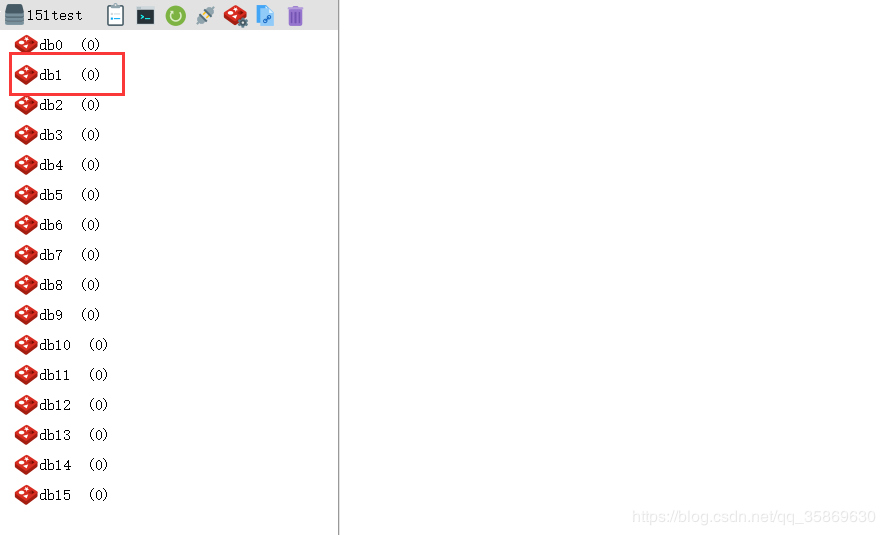
Redis 这里选择存到redis 1号库 db1
# 账号密码都是root,dispatch_server_host是自定义的一个rabbitmq虚拟主机,也可理解为队列
BROKER_URL = 'amqp://root:root@127.0.0.1/dispatch_server_host'
# Redis地址,这里选择存到redis 1号库
CELERY_RESULT_BACKEND = "redis://:password@127.0.0.1:6379/1"
# 注册任务的地址
CELERY_INCLUDE = ['logic.celery_core.task_register']
这是测试的两个主要函数
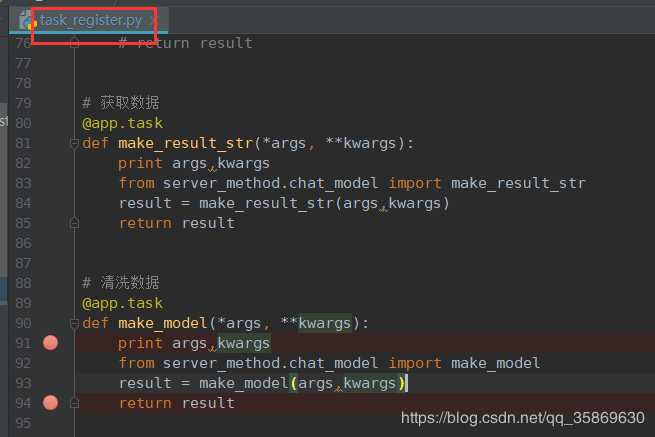
5、分发任务
在这里选择测试的案例是之前的博客里面写过的,以玩家的聊天记录进行热点排行。 具体任务的构建也可以看一下之前博客的构建过程。 这里简单介绍一下 对20200406,20200407两天分1-450 451-900级这两个等级段对玩家的聊天记录进行分布式计算。一共有4个task,分别为 task_1 :20200406 1-450 玩家的聊天记录进行jieba分词计算 task_2 :20200406 451-900 玩家的聊天记录进行jieba分词计算 ...... 最终Celery构建的任务如下: chord(group([worker_1 ,worker_2 ,worker_3 ,worker_4]))
二、启动RabbitMQ,Redis
安装启动命令如果有需要再私信我再出个详细的部署教程,这里就不详说了。
连接Redis,借助RedisDesktopManager工具
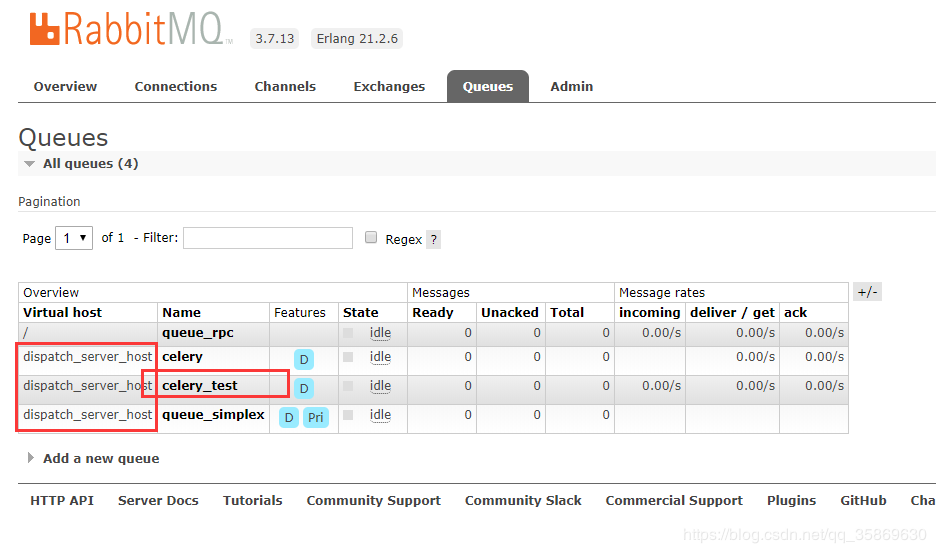
三、提交任务流
1、RabbitMQ接收任务
RPC队列将参数通过RabbitMQ传给接受者


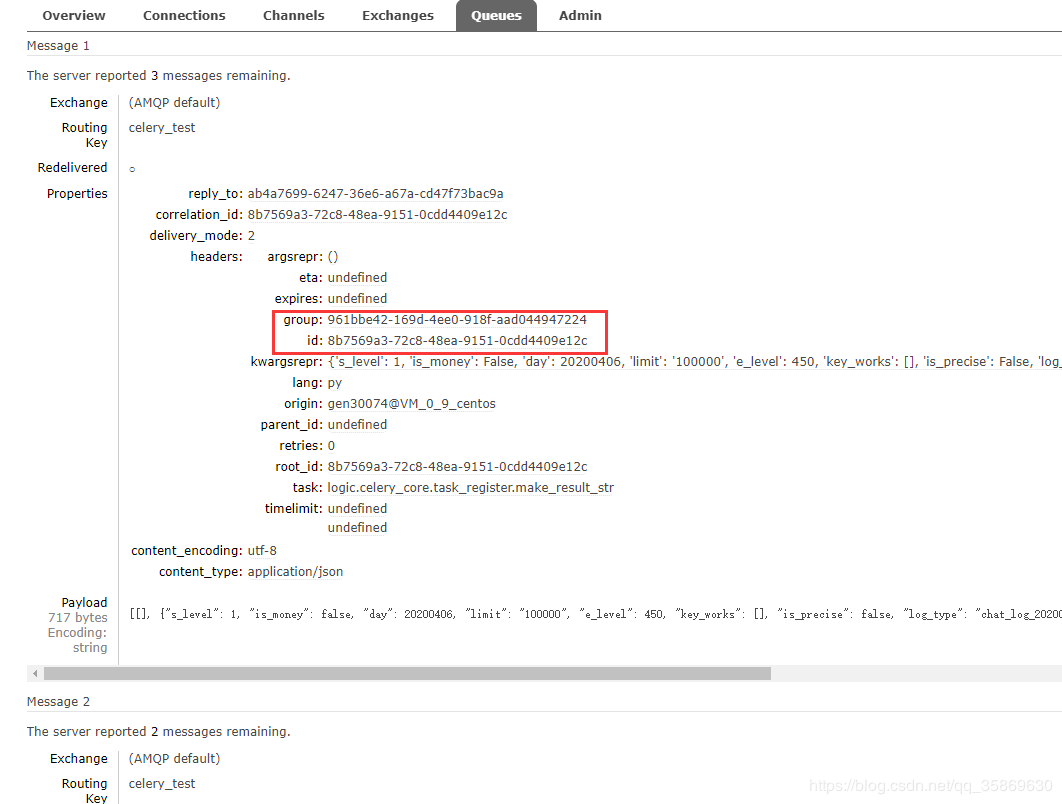
2、启动Celery服务端
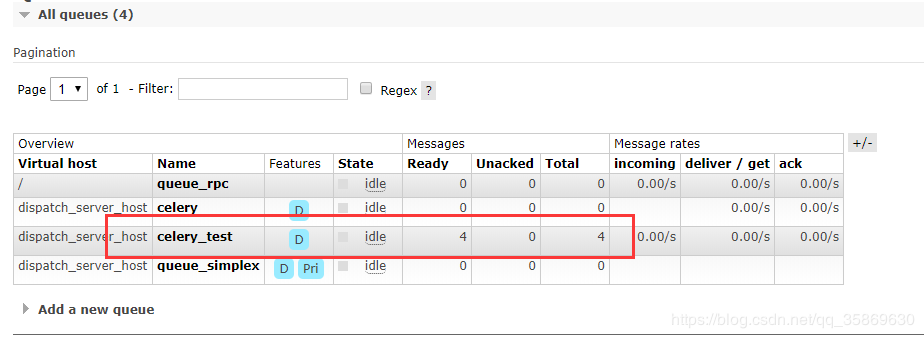
启动队列名为celery_test的队列去消费RabbitMQ中的任务,在这里启动了4个worker celery -A main worker -n celery_test -c 4 -l info -Q celery_test
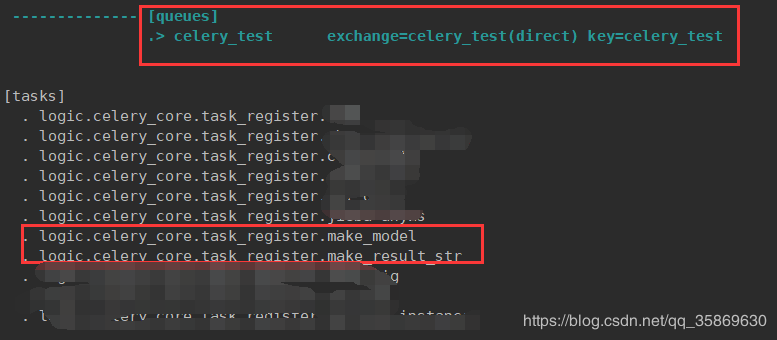
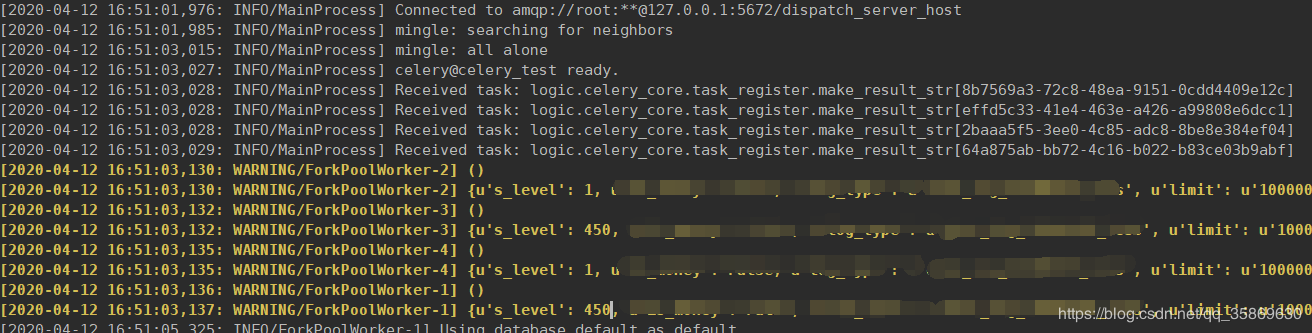
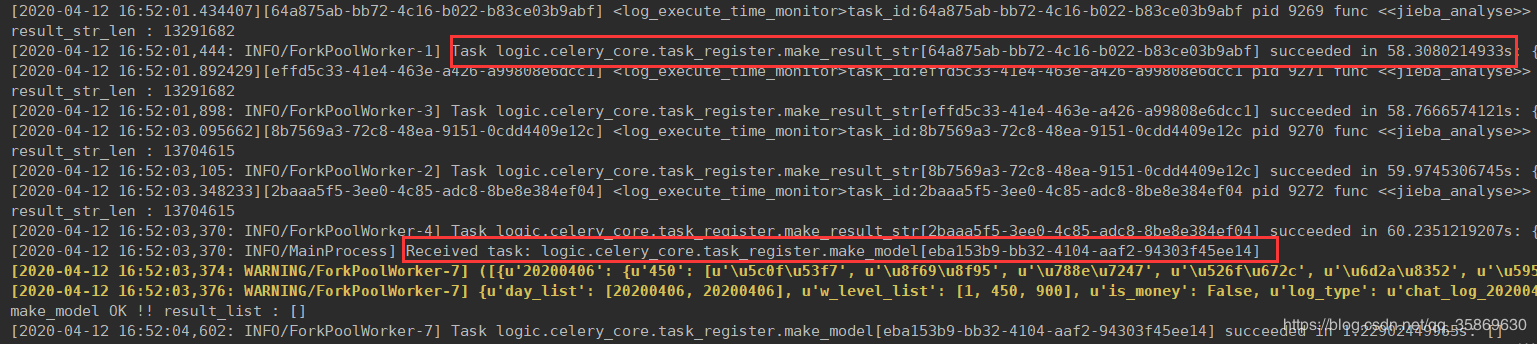
3、Redis的储存
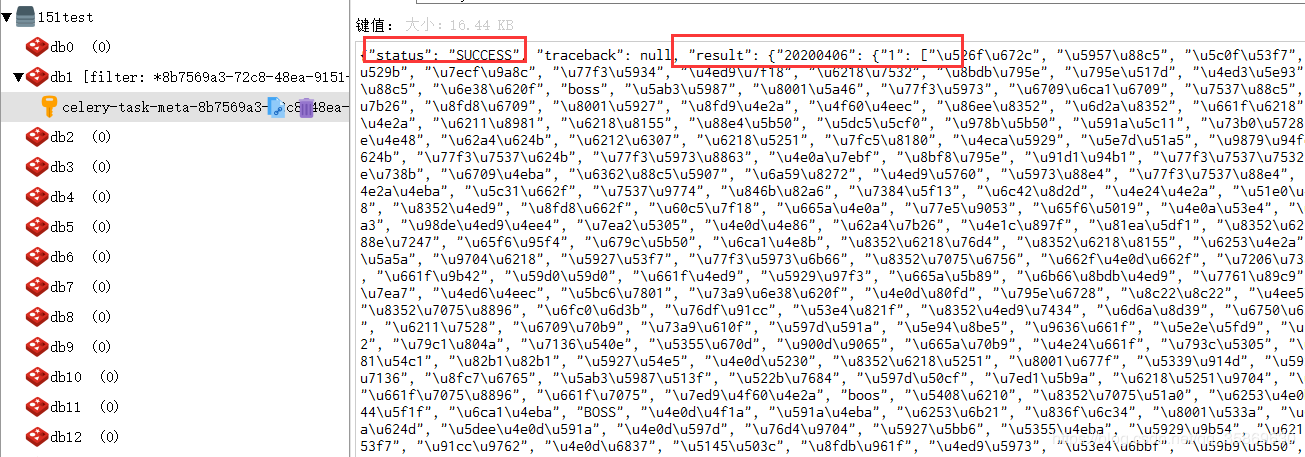
我们看一下Redis db1的情况
四、总结
Celery分布式框架是比较简单的一个微服务框架,但是如果要有针对性的进行优化还是要搞清楚对于整个框架中具体的数据是怎么走的。Celery+RabbitMQ+Redis+MySQL应该是比较常用的结构,但是这些都可以根据业务的情况来选择中间件。对于整体框架的管理的话,本人使用的flower+supervisor进行队列查看和管理。
在这里关于前面RabbitMQ的RPC队列具体拿来做什么的,如果有读者比较感兴趣的话再具体讲解。
如果对你有帮助的话麻烦给个赞支持一下,这很重要!感谢!
整个框架都是个人的理解,如果有大佬发现哪里有问题请一定要告诉我,如果有好的优化框架思路也可以说一下一起讨论一下。感谢!
