

前言
个人情况(陈年老词):
2020.1 公司因为业务调整,90% 被友好劝退了(N+1)。又逢疫情在家耗了 4 个月,3 月末开始找工作,发现都没人搭理我,快 30 的我开始慌了。
某晚看到【新鲜面经】 四月面试不用慌,掘友攻略来帮忙| 掘金技术征文展(第一弹),深深佩服各位掘友的 掘学 出众,反思自己太“弱”了,就这段时间好好再巩固下前端知识点,希望也能找到个不错的工作。
这篇主要写下 网络相关 的知识点。后续还会涉及:数据结构、js、css、Vue 等一些能归纳的知识块,不会面面俱到,起码为后续自己面试有个足够的准备。
每篇内容肯定不够细致,更多扩展的地方可以看如下的“参考文章”。
TCP
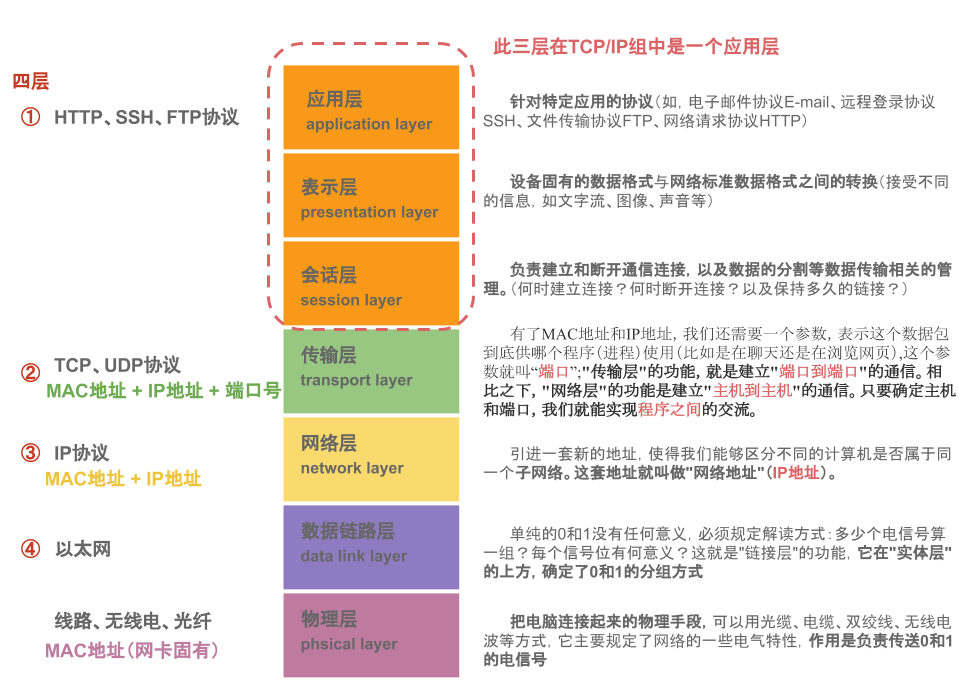
TCP/IP 四层网络模型
TCP(Transmission Control Protocol),是一种面向连接的、可靠的、基于字节流的 传输层通信协议。同类的还有 UDP 协议,在 应用层 还有 HTTP、FTP 等常见协议。
另外,我们平时听的最多的就是 TCP/IP 这么一个称呼,IP 属于**网络层协议。
附张图说明:
三次握手(Three-way Handshake)
名词解释
- SYN(S_ynchronize Sequence Numbers_) 同步序列编号,表示建立连接。
- ISN(Initial Seque*nce Number) 初始化序号,避免信息被人篡改。
- ACK(Acknowledge character) 确认标识,表示接受到的信息无误并响应。
握手过程
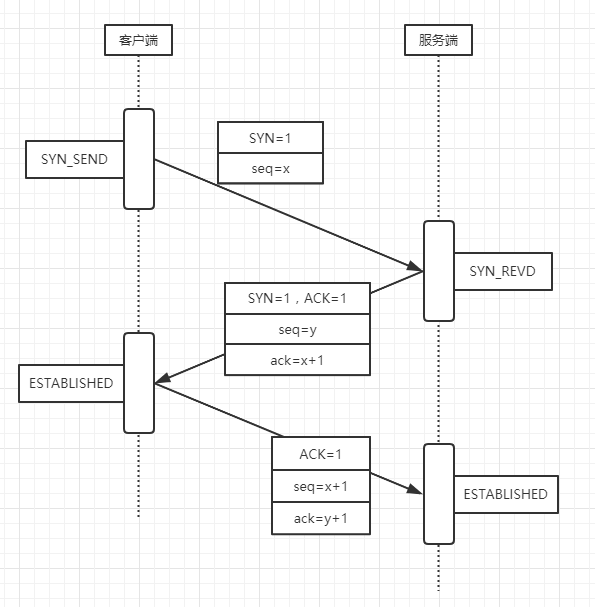
- 客户端 --> 服务端。报文控制位设置 SYN=1 示意开始建立连接,设置客户端序号 seq=x,并不含数据内容。更新客户端状态为 SYN_SEND
- 客户端 <-- 服务端。报文控制位设置 SYN=1,ACK=1 示意服务端连接应答并确认,设置来自服务端的序号 seq=y,以 x+1 作为 ack 结果值。更新服务端状态 SYN_REVD
- 客户端 --> 服务端。报文控制为设置 ACK=1 示意连接建立确认,设置这次客户端序号 seq=x+1,以 y+1 作为 ack 结果值。更新客户端状态 ESTABLISHED
灵魂拷问,为什么不是二次?
举个例子,A,B 两个人打架: 第一次:A 举起手,往 B 的脸上抽。我不爽,想要干架(可能手短打不到 B) 第二次:B 的脸成功被抽了,捂捂脸很痛,确认脸上的红印是 A 打来的,也挥手向 A 打去(可能手短打不到 A)。 第三次:A 被回击了,但现在知道 B 已经被我打红脸了(这个距离我能打到 B,B 这小子敢还手),往 B 吐口口水说道:我也被你打痛了,开始干架吧。
如此通过这三步,A,B才能相互确认对象的存在,并能顺利打到对方。
TCP 四次挥手(Four-way handshake)
挥手过程
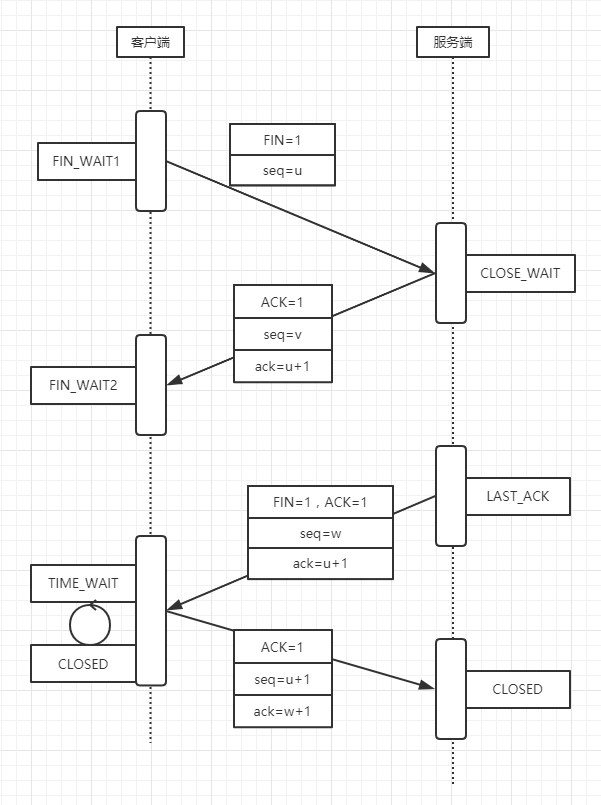
- 客户端 --> 服务端。报文控制位设置 FIN=1 示意连接到此结束,设置客户端序号 seq=u,并不在发送数据,关闭连接。更新客户端状态为 FIN_WAIT1(终止等待,等待服务器确认)
- 客户端 <-- 服务端。报文控制位设置 ACK=1 示意确认应答,设置来自服务端的序号 seq=v,以 u+1 作为 ack 结果值。更新服务端状态 CLOSE_WAIT(等待关闭);客户端此时调整状态为 FIN_WAIT2 (等待服务器释放连接信号)
- 客户端 <-- 服务端。服务端也要关闭,则发送 FIN=1,ACK=1 示意也要连接也要关闭并做应答,再次设置序号 seq=w,以及 ack=u+1(同上)。更新服务端状态 LAST_ACK (最后确认,等待客户端告诉服务端确认响应)
- 客户端 --> 服务端。接受到服务端 FIN 请求后,更新状态为 TIME_WAIT,再反馈 ACK=1,设置 seq=u+1,ack=w+1 ,等待 2MSL 周期,无其他问题后,进入 CLOSED 状态
为何挥手要进行四次?
其实就是解释:为何服务端要单独返送一次 ACK 报文(第二次)
因为可能整个 TCP 连接过程中,需要先等待其他连接的结束,所以这里服务器告知客户端(我知道你要关闭了,你先等我这边处理完手头事情,再关闭服务端)
透彻些,就是 TCP 连接的半关闭机制导致,TCP 是全双工的(两端都具备发送和接受信息的功能),客户端做关闭请求时,服务端不可能马上关闭,可能还有其他数据需要处理。
2MSL 机制
MSL(Maximum Segment Lifetime)报文片段最大的生存周期,超过这个周期,报文将被丢弃。
为何需要在 TIME_WAIT 状态需要等待 2MSL 的时间?
假设网络等有问题时,主动关闭方的 ACK 可能没有传达给对方(这里是服务端),服务端基于超时机制会重新发送一次 FIN 报文,此次流程又将进行 FIN 以及 ACK 两次握手状态,我们已经知道单次是 MSL,那两次则为 2MSL,确保有有效的时间来响应完整个流程(客户端发送的最后一次 ACK 能达到服务端)
Http
缓存策略
类型上分两种:强缓存、协商缓存
强缓存
首次服务端响应将含有 **Expires **、 Cache-Control 两个请求头属性。
前者 Expires 将在服务器端设置一个固定时间,下次浏览器请求资源时,这个时间点内将直接从缓存中拿取资源。
后者 Cache-Control 区别 Expires,可以通过 max-age 设置相对时间,从而避免前者因为客户端本地时间的问题造成缓存失效。
同时 Cache-Control 还可以设置如下属性,进一步细化控制缓存规则:
- public:整个网络请求中的任何中间层都可以缓存资源
- private:对比 public,只有客户端可以缓存资源
- no-cache:交给服务端判断是否要缓存,跳过强缓存,走入下一环节:协商缓存
- no-store:不缓存,每次都从服务器获取资源
注意:Cache-Control 的优先级高于 Expires
协商缓存
当强缓存没有命中时,将直接询问服务端,服务端判断是否有内容更新。
有如下这些判断方式:
- Last-Modified(服务端文件修改时间),If-Modified-Since(客户端文件上次的修改时间):这两个属性时间做对比。但还会导致相同文件内容因为发布原因,文件又被修改一次,导致缓存失效。
- Etag(指纹标记):通过文件的 hash 值确认文件是否被修改,客户端下次请求将携带 If-no-match 把上次的 Etag 内容传给服务端做对比,确认缓存是否失效。
强缓存和协商缓存的区别
- 强缓存只在第一次需要服务端参与
- 协商缓存每次请求都需要服务端判断缓存状态
- 协商缓存中,命中的缓存将由服务端告知 304 状态;强缓存一直是 200
Http2
Http2 的特点 & 解决的问题
- 源于 SPDY 协议,虽然 Http2 不强制使用 TLS,但主流浏览器(Chrome)推荐使用 TLS
- 二进制分帧(Bitary Frame):在不改变 Http 内容前提下,将 Http 报文内容封装到不同帧中,以更小的形式进行传递。改善传输性能。
- 多路复用(Multiplexing):多个请求共享同个连接,避免队头阻塞(head of line blocking)问题
- header 压缩:减少请求内容,提升传输速度
- 服务端推送能力(push):服务端可以自主控制资源 or 数据,对应客户端可选择接受或拒绝。极端些可以把 js、css 之类的嵌入资源的方式取消,由服务端主动推送给客户端。
header 压缩好处说明
基于 Http2 的首部表,保存并跟踪请求内容的 key/value。最后发送时,删除冗余内容,这样有效减少重复内容占用网络资源。
像我们 Cookies 可能就包含了大量的请求信息,每次请求都会带入到网络中,消耗资源。
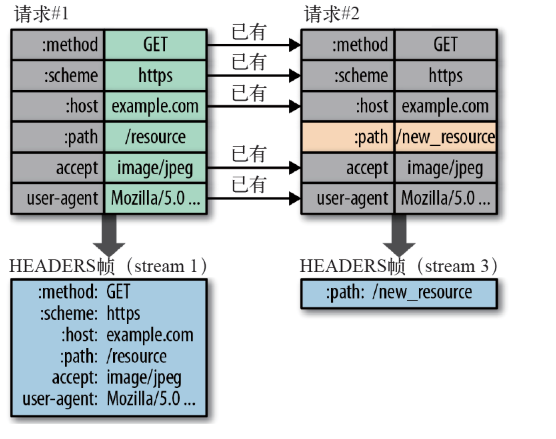
二进制分帧怎么回事
这是在应用层中,添加一层 二进制处理层,对 Http 数据进行拆分,对应内容投递到对应的帧中。
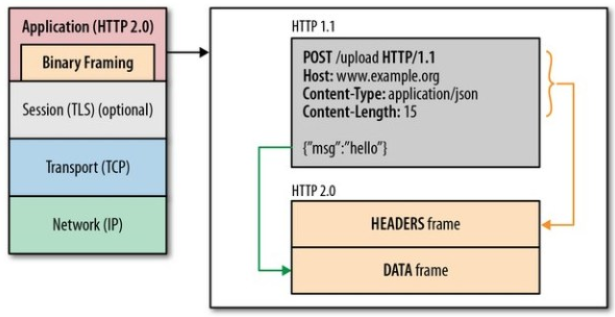
几种帧类型说明:
- ATA:用于传输HTTP消息体;
- HEADERS:用于传输关于流的额外的首部字段;
- PRIORITY:用于指定或重新指定引用资源的优先级;
- RST_STREAM:用于知道流的非正常终止;
- SETTINGS:用于通知两端通信方式的配置数据;
- PUSH_PROMISE:用于发出创建流和服务器引用资源的要约;
- PING:用于计算往返时间,执行活性检查;
- GOWAY:通知远端对等端不要在这个连接上建立新流;
- WINDOW_UPDATE:用于针对个别流或个别连接实现流量控制;
- CONTINUATION:用于继续一系列首部片段。
那怎么变快呢?可以看下这图:
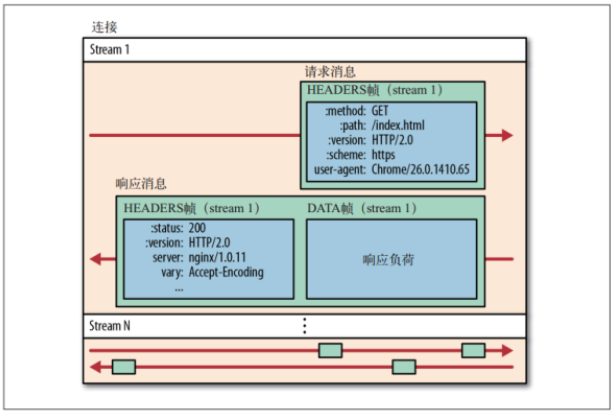
对应的 Http 内容被分放于不同帧块中,整个数据传输的过程中不再丢一个大 Http 包,而是排列紧密的“小帧包”。
帧也是 Http2 中,数据传递的最小单位。
浏览器
浏览器输入 URL 后,整个过程
- 逐级查询 DNS,解析获得对应 IP
- 与目标地址建立 TCP 连接(三次握手)
- 浏览器构造 Http 请求报文发送给服务器
- 服务端解析请求,返回页面数据
- 浏览器解析 HTML
- 浏览器继续准备加载其他资源,如 css、js
- 根据缓存策略,判断哪些是要从服务器拉取新文件
- 资源文件解析完毕后,根据渲染树计算元素位置开始绘制页面
回流和重绘
还是从一张常见的图开始:
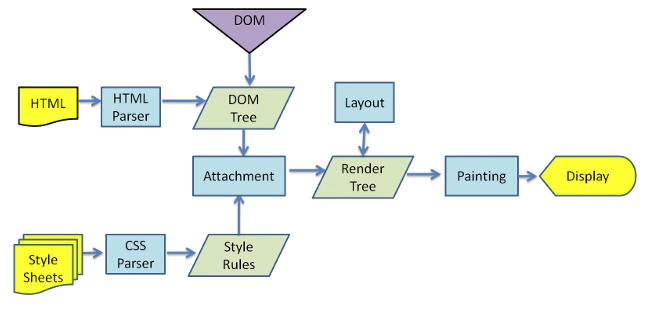
一些名词做个解释:
- 回流(reflow):渲染树(Render Tree)中的内容因为某些修改,将重新计算元素的几何信息(长宽高、位置等),计算完后再进行重新绘制。
- 重绘(repaint):只是更改元素的样子,但不影响页面的布局效果。
应该已经知道的规则是:回流后必定引起重绘,而重绘不一定会回流。
几种回流触发的点:
- DOM 的增减
- 元素的几何属性变化(长宽高等,形状变了)
- 元素的位置
- 获取元素的偏移量(scrollTop、scrollLeft、scrollWidth、offsetTop、offsetLeft、offsetWidth、offsetHeight 等)
- 页面首次渲染
- 浏览器窗口尺寸变动
浏览器帮我们做了很多优化,使之多次的回流操作将被加入到一个队列中缓存,最后一次执行;但如果是需要获取最新的位置信息,将绕过这层优化。
怎么优化?平时该怎么注意:
- 减少回流操作;将多次触发回流的操作合并成一次
- 减少或者批量修改 DOM(使用 DocumentFragment,或者挪至一个新节点操作)
- 将频繁触发回流重绘的元素(比如,动画)脱离文档流
- 使用 css3 硬件 gpu 加速(transform、opacity、filters、will-change)
Event Loop
程序中的代码当执行时,会丢到 执行栈 中,并以 先进后出 的方式操作调用。
大致过程如下图所示:
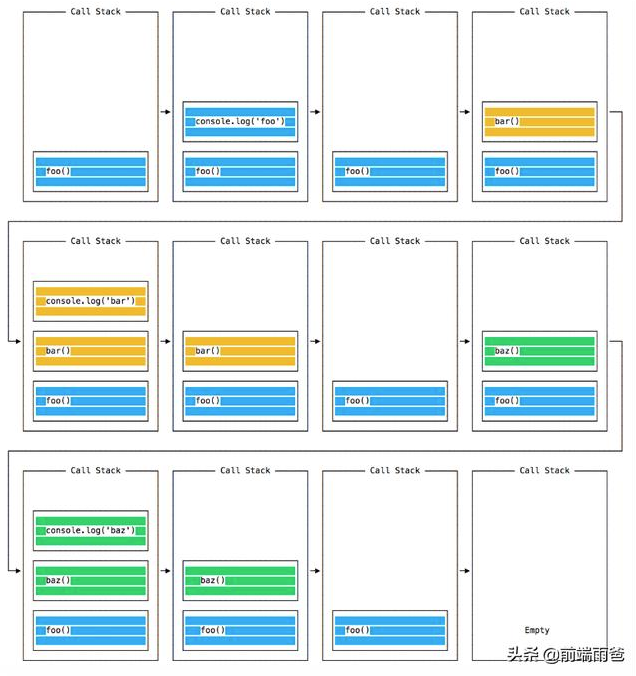
但是一旦遇到 setTimout 之类的代码时,执行栈内的方法却会变得不同,setTimeout 只是在栈内注册下,而非在栈内执行:
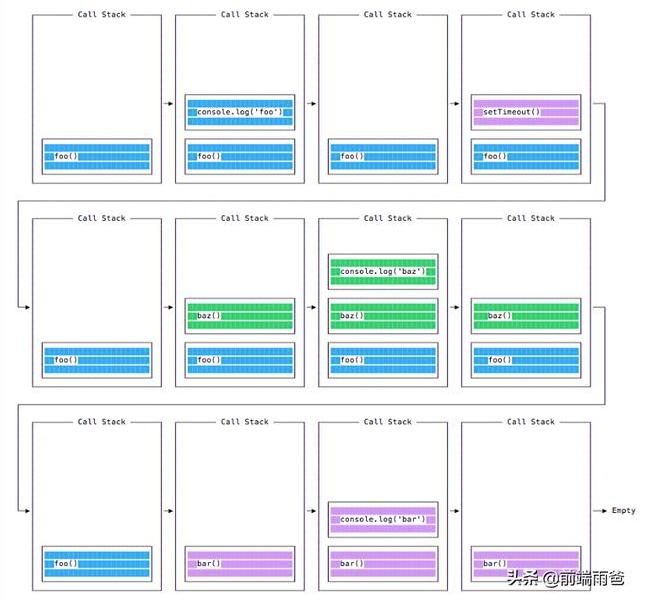
setTimout 真正执行的地方在消息队列。当执行栈的所有任务完毕后,此队列会通过类似 while 的机制,不停检查 setTimout 之类异步代码的情况,直至执行。
当然消息队列中,针对这些方法进行了分类:
- macroTask
- setTimeout
- setInterval
- setImmediate
- I/O
- UI render
- http
- microTask
- process.nextTick
- promise
- Object.observe
- MutationObserver
并且,microTask 的优先于 macroTask。
安全
XSS
XSS(Cross Site Script)跨站脚本攻击,通过恶意代码的注入,截取用户信息,或者影响正常的页面操作,甚至危害到服务端。
比如:通过 input 向服务端保存些脚本,下次获取数据时,这些脚本将直接工作。
如何防范:
- 对输入内容做不可信处理,采取过滤、转义等处理
- 增加 httpOnly,避免 cookie 信息的截取
CSRF
CSRF(Cross Site Request Forgery)跨站请求伪造,通常伪造网站信息(比如,用户已登录的 cookie 信息),在用户不知情的情况下骗取服务端信任,从而进行某些操作。
如何预防:
- 加强对 Referer、网站的校验
- 提升 Cookie 的安全性
- 添加验证信息,让用户参与每次敏感操作
- 使用 Token 机制,增加信息伪造难度
最后
如果有错误,欢迎各位掘友指出;若是有收获,请点点赞支持下,谢谢。
《30岁的我找工作好难》系列,其他面试文章:
参考文章
短期内,无法落地 demo 用于实践,多数还是借鉴网上各个作者的知识总结,这里为他们的付出表示感谢!
