

大家都知道ES6中的Map是新增的一种数据结构。它类似对象,但是对象的键只能是字符串,Map的键不限定是字符串,Map的键可以是一个
对象,可以是布尔值等。Map提供"值-值"的对应关系,是一种Hash结构,但实际上ES6又比传统Hash多了一些特性。
通过下面这个小例子,我们看一下Map比传统Hash多的特性是什么:
let m = new Map()
m.set(1,1).set(2,2).set(3,3) //Map(3) {1 => 1, 2 => 2, 3 => 3}
m.delete(2) //true Map(2) {1 => 1, 3 => 3}
m.set(1,'1') //Map(2) {1 => "1", 3 => 3}
m.set(4,4) //Map(3) {1 => "1", 3 => 3, 4 => 4}
我简单罗列一下 Map 的api(但并不是重点)
- Map.prototype.set(key,value),返回Map本身,所以可以链式
- Map.prototype.get(key) 如果找不到,返回undefined
- Map.prototype.has(key)
- Map.prototype.clear()
这篇文章的重点不是讲解api的,而是透过Map提供的这些api,能够体会到Map底层的数据结构是什么样的
上面的例子,先初始化一个Map m,然后一次性set 3 个值,可以看到此时的m是Map(3) {1 => 1, 2 => 2, 3 => 3}正好和我们
set的顺序是对应的,然后删除key=2的键值对,然后m是Map(2) {1 => 1, 3 => 3},然后重新m.set(1,'1'),
这时m是Map(2) {1 => "1", 3 => 3},再m.set(4,4),可以看到m是Map(3) {1 => "1", 3 => 3, 4 => 4}。key=4的键值对是
在最后的,这标明了一种顺序,在set新值的时候,保持着一种先后顺序。
这个特性就是,Map的插入总是保持着先后顺序(删除了中间元素也会保持顺序),这和传统Hash并不一样。传统Hash是一种散列结构,元素并不具备顺序性,而Map很明显,
后插入的元素就在最后,保持着这种先后顺序。
Hash本是哈希函数,表示为index = fn(key),这里的fn就是哈希函数,它代表一种生成地址的规则,一般有直接定制法、数组分析法、
平方取中法等等,这离本篇文章跑远了,哈希算法哪种好,已经在计算机算法中有所研究,可以看https://blog.csdn.net/u011109881/article/details/80379505
我们模拟Map的数据结构,就需要自己制定一个Hash函数。
Hash是一段连续的有限的内存空间,根据散列函数H(key)和处理冲突的方法将一组关键字映射到一个有限的连续的地集(区间)上,并以关键字 在地址集中的"象"作为记录在表中的存储位置,这种表就是散列表,这一映象过程称为散列造表或散列,所得的额存储位置称散列地址。
我们可以捋捋思路了,根据上文,Map底层使用了Hash毋庸置疑,但保持顺序这个特性,我猜测Map的底层使用了链表数据结构(链表是前一个结点的next指针指向后一个结点),所以Map的底层数据结构,使用了Hash + 链表实现。
Map可以保证顺序,也可以使用O(1)的时间复杂度来找到某个元素,所以我们初步方案,Hash的散列表存储Map中的数据,同时每个结点存入的先后顺序使用链表的形式表示。
我画了两张示意图,表示数据结构的一种基本实现和删除某个结点时的实现,如下:
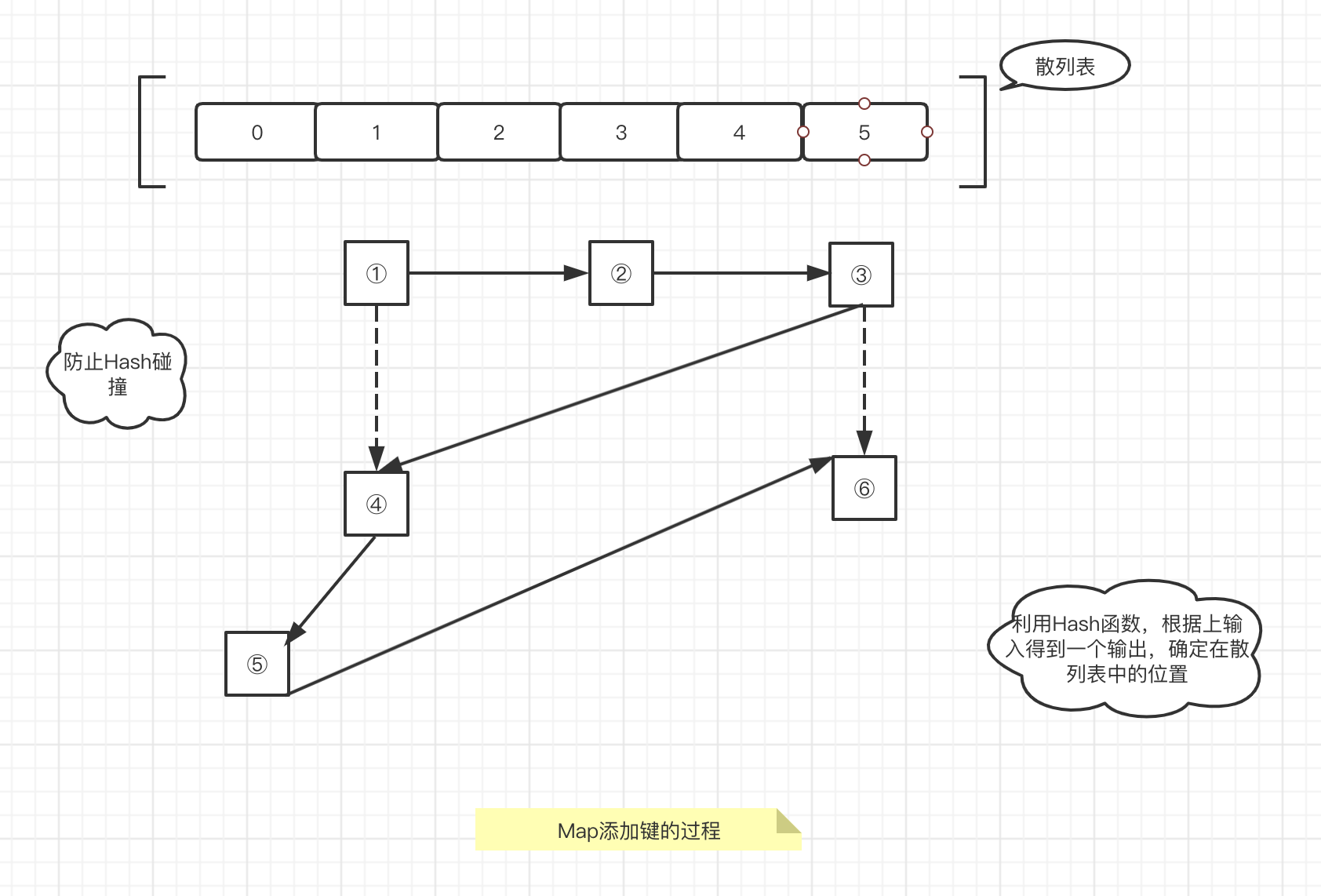
图中,我为了简化默认散列表的长度是6,插入节点时,我们使用Hash()函数,根据传入的key,获取一个应该插入的位置index,比如第一个结点①,
得出index=1,那么放入位置,再放一个结点②,得出index,这里要有一个指针(next),从①指向②,这样才能保证Map中数据的顺序,然后是插入结点③。插入结点④
的时候,通过Hash函数,得出和①结点相同的位置,这种现象叫做Hash碰撞,碰撞是不可避免的,好的Hash函数应该尽可能少的出现碰撞,更加平均的使用散列表。
出现了碰撞,怎么处理呢,这里我选择使用指针,连接①结点和④结点,这样在同一个位置,会映射多个结点。(理论上应该尽可能少的碰撞,否则影响查找速度)
,按照这样的规律,依次创建了结点⑤和结点⑥
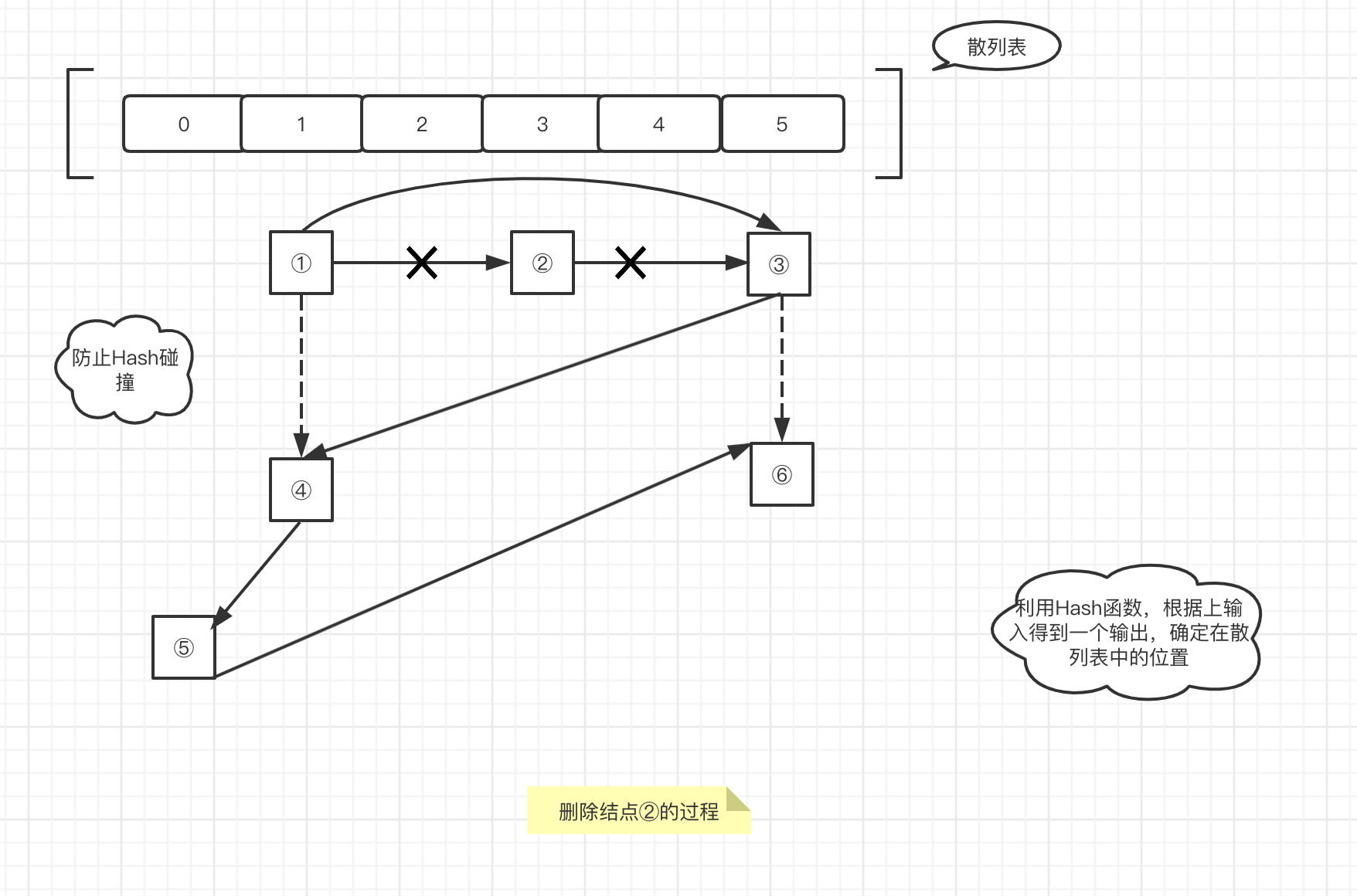
删除某个结点时,传入要删除的key,通过Hash函数,非常快的找到所在位置,不需要遍历。然而我们说了Map的值的插入是有顺序的,比如删除结点②,
为了保持这种顺序性,我们使用链表的特性,把结点②的前一个结点①的next指针指向结点③。这里不需要移动结点什么,只是改变一下指针的指向,所以操作非常快
像Map的其他操作,比如get(key) 就很容易了,关键是理解上面的两个图模型。好了,接下来用Javascript原生来模拟一个Map数据结构,上代码:
class ListNode {
constructor(key, value) {
this.key = key;
this.value = value;
this.next = null; //记录插入顺序
this.ne = null; //记录Hash碰撞后的结点
}
}
function myMap() {
this.init()
}
myMap.prototype.init = function(){
this.collection = new Array(6) //map底层用了hash算法。假如使用collection容器存放map中的数据
for (let i = 0; i < this.collection.length; i++) {
this.collection[i] = Object.create(null)
this.collection[i].ne = null;
this.collection[i].next = null;
}
this.size = 0
this.head = null; //头指针,总是指向第一个
this.tail = null; //尾指针,总是指向最后一个
}
//插入或更新key结点
myMap.prototype.set = function (key, value) {
let index = this.hash(key) //获取容器中的位置
let node = this.collection[index] //获得index位置处的对象
while (node.ne) {
if (node.ne.key === key) {
node.ne.value = value //更新
return this //注意返回当前对象this
} else {
node = node.ne
}
}
//map中没有该key,就在链表尾部插入
let new_node = new ListNode(key, value)
node.ne = new_node
if (!this.tail) {
this.tail = new_node
}
if (!this.head) {
this.head = new_node //如果是第一个结点,头指针指向它
}
this.tail.next = new_node //尾指针
this.tail = new_node
this.size++
return this //注意返回当前对象this
}
//获取key结点的值
myMap.prototype.get = function (key) {
let index = this.hash(key)
let node = this.collection[index] //获取容器相应位置处的对象
while (node) {
if (node.key === key) {
return node.value
} else {
node = node.ne
}
}
return undefined
}
//删掉key结点
myMap.prototype.delete = function (key) {
if (!this.head) {
return false
}
//从容器中删除
let index = this.hash(key)
let node = this.collection[index]
let pre = null;
while (node.ne) {
if (node.ne.key === key) {
let _prev = node; //从链表中删除,需要前置结点
let _node = node.ne //保存要删除的结点
_prev.ne = node.ne.ne//从容器中删除,前置结点的指针指向要删除结点的指针
//从链表中删除
if (this.head === _node) { //如果要删除的结点是头结点
this.head = _node.next;
} else if (this.tail === _node) { //如果要删除的结点时尾结点
this.tail = _prev; //将尾指针指为前置结点
_prev.next = null; //将前置结点的指针置为空
} else {
let cur = this.head;
while (cur) {
if (cur.key !== key) {
pre = cur;
cur = cur.next;
} else {
break
}
}
pre.next = cur.next
}
this.size--
return true;
} else {
node = node.ne
}
}
return false
}
myMap.prototype.has = function (key) {
let index = this.hash(key)
let node = this.collection[index]
while (node.ne) {
if (node.ne.key === key) {
return true
} else {
node = node.ne
}
}
return false
}
//返回键名的遍历器
myMap.prototype.keys = function* () {
let head = this.head
// 遍历链表,把链表中所有Key放入生成器中
while (head) {
if (head.key) {
yield head.key
}
head = head.next
}
}
//返回键值的遍历器
myMap.prototype.values = function* () {
let head = this.head;
while (head) {
if (head.value) {
yield head.value
}
head = head.next
}
}
//返回所有成员 遍历器
myMap.prototype.entries = function* () {
let head = this.head;
while (head) {
if (head.key) {
yield [head.key, head.value]
}
head = head.next
}
}
myMap.prototype[Symbol.iterator] = myMap.prototype.entries //默认遍历器接口,for of使用
//返回Map的所有成员,接受一个函数作为第一个参数,第二个参数是thisArg 如果省略了 thisArg 参数,或者其值为 null 或 undefined,this 则指向全局对象。
myMap.prototype.forEach = function (callbackFn, thisArg) {
let head = this.head
while (head) {
if (head.key) {
callbackFn.call(thisArg, head.key, head.value, this)
head = head.next
}
}
}
myMap.prototype.clear = function () {
this.init()
}
/**
* @param any key
* @return {number}
*/
//Hash 方法,Hash的算法我自己模拟一个,真正实践中的Hash算法肯定十分复杂
myMap.prototype.hash = function (key) {
let index = 0;
if (typeof key === 'string') {
//字符串的话取前10位,也没必要全部遍历完字符串,会影响性能、计算时间
for (let i = 0; i < 10; i++) {
index += isNaN(key.charCodeAt(i)) ? 0 : key.charCodeAt(i)
}
} else if (typeof key === 'number') {
index = isNaN(key) ? this.collection.length - 1 : key % this.collection.length
} else if (typeof key === 'object') {
// 如果传入的是一个对象作为键,es6中的Map,底层Hash算法一定跟它的内存地址有关,因为取值时,比较的是是否是同一个引用。就算给了一个字面量相同的值,也不能取到值,必须试试引用相同的值才能取到
// 这里我只能模拟key为对象时,经Hash算法得到的都是index=0了
index = 0
} else if (typeof key === 'undefined') {
index = 1
} else if (typeof key === 'boolean') {
index = 2
}
return index % this.collection.length
}
由于要注意的细节太多,所以我加上了注释,一定要好好看注释啊~
先说一句前提Javascript底层是用c/c++写的,为什么这么说呢?因为ES6的Map可以用对象作为键,那么在计算机底层,肯定是和传入对象的内存地址有关系的,
Map取值时,如果是引用类型,必须是相同的内存地址才可以取到。
综上,模拟的主要思路是,用Hash思想来存储数据,达到O(1)的查找时间,用链表思想来维持插入数据的先后顺序。细节点是,Hash的碰撞处理,我是自己模拟Hash函数,因为Javascript底层是用
c/c++写的,所以用js写只能是叫"模拟"。我还用了单链表来处理碰撞,通过ne指针,可以取到碰撞的后续值,这样有个隐藏问题是,当碰撞多了,Map的查找速度会慢,
其实也可以用数组来处理碰撞,好处是Map查找速度会快那么点。
多说一句,在计算机领域Hash碰撞算是一个课题,如果要深入研究都可以写篇论文了。Hash函数也有很多种,但以哪种算法为准,则要看使用场景,不过最终目标是一样的,就是减少碰撞,均匀使用每个存储地址。
来验证一下结果吧:
let m = new myMap();
m.set('a', 1).set('b', 2)
console.log(m.get('a'), m.get('b')) //1 2
let obj = {name: 'lolita'}
let obj2 = {name: 'obj2'}
m.set(obj, 'obj')
m.set(obj2, 'obj2')
console.log(m.get(obj)) //obj
console.log(m.size) //4
console.log(m.delete('a')) //true
console.log(m.delete('a')) //false,因为'a'已经被删除过了
console.log(m.delete(obj)) //true
console.log(m.get(obj2)) // obj2
for (let key of m.keys()) {
console.log('key:', key) //key: b key: { name: 'obj2' }
}
for (let value of m.values()) {
console.log('value:', value) //value: 2 value: obj2
}
for (let item of m.entries()) {
console.log(item[0], item[1]) //b 2 { name: 'obj2' } 'obj2'
}
for (let [key, value] of m) {
console.log(key, value); //b 2 { name: 'obj2' } 'obj2'
}
let ooo = {name: 'Jack'}
m.forEach(function (key, value, map) {
console.log("key: %s, value: %s", key, value)
console.log(this) //forEach第二个参数不写或者null或者undefined,this都会是全局对象
}, ooo)
//key: b, value: 2 { name: 'Jack' }
// key: [object Object], value: obj2 { name: 'Jack' }
console.log(m.clear()) //undefined
经过验证,完全符合预期结果,可以说模拟是到位的,欧耶~
Question:
-
为什么底层用Hash表示,用对象不行吗? 不行,对象虽然也可以达到get set的效果,但是在遍历时,使用 for ... in 或者Object.keys()都会按升序自动排序问题
-
怎么模拟内存地址生成过程呢?
let generator = function* RandomRefFun() {
const random = Math.random().toString(16).slice(2,8)
yield `0x${random}`;
}
let RandomRefFun = generator()
let randomRef = RandomRefFun().next().value
参考链接:
