

0. 写在前面
源码参考github redis/evict.c,commitid - d1a005ab3963c16b65e805675a76f0e40c723158
过程中需要时刻提醒自己,阅读源码是为了学习实现细节,但也不能陷入细节,分析顺序按照执行顺序,避免贴大块源码。
1. Redis内存淘汰策略实现
当内存使用超过配置时的内存淘汰策略,非常好记忆:不处理/LRU算法/LFU算法/随机/过期时间
-
noeviction: 不会驱逐任何key -
allkeys-lru: 对所有key使用LRU算法进行删除 -
volatile-lru: 对所有设置了过期时间的key使用LRU算法进行删除 -
allkeys-random:对所有key随机删除 -
volatile-random: 对所有设置了过期时间的key随机删除 -
volatile-ttl: 删除马上要过期的key -
allkeys-lfu: 对所有key使用LFU算法进行删除 -
volatile-lfu: 对所有设置了过期时间的key使用LFU算法进行删除
1.1 freeMemoryIfNeededAndSafe: 开始释放内存
没有lua脚本处于超时状态且不在载入数据状态时,才会执行freeMemoryIfNeeded()函数
int freeMemoryIfNeededAndSafe(void) {
if (server.lua_timedout || server.loading) return C_OK;
return freeMemoryIfNeeded();
}
1.2 freeMemoryIfNeeded: 根据淘汰策略清理内存
默认情况下,从节点应该忽略maxmemory指令,仅仅做从节点该做的事情就好
if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
如果淘汰策略是noeviction, 那redis只能说"我尽力了"
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
goto cant_free; /* We need to free memory, but policy forbids. */
cant_free有如下两种情况,它能做的只有检查lazyfree线程(应该是redis v4添加的)是否还有任务,然后等待。
- 第一种是淘汰策略为
noeviction - 第二种是在当前的淘汰策略下,"nothing to free"
cant_free:
while(bioPendingJobsOfType(BIO_LAZY_FREE)) {
if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree)
break;
usleep(1000);
}
return C_ERR;
}
通过getMaxmemoryState函数(不重要,略),取得要释放多少空间mem_tofrtee,选择策略开始清理
size_t mem_reported, mem_tofree, mem_freed;
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return C_OK;
mem_freed = 0
while (mem_freed < mem_tofree) {
// 匹配的key
sds bestkey = NULL;
// bestkey所在的db
int bestdbid;
// LRU算法/LFU算法/TTL过期时间
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
}
// 随机淘汰
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM || server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)) {
}
// 删除所选的key
if (bestkey) {
// 获取当前内存
delta = (long long) zmalloc_used_memory();
// 是否非阻塞删除
if (server.lazyfree_lazy_eviction)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
// 计算释放了多少内存
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
} else {
goto cant_free; /* nothing to free... */
}
}
1.3 allkeys-random和volatile-random分支
当选择随机淘汰时,会遍历当前redis实例的每一个db,如果是所有key随机删除选择db->dict, 否则只选择设置了过期时间的集合: db->expires,
如果每一个db的dictSize(dict)都是0,则会进入到上面提到的cant_free的第二种情况
for (i = 0; i < server.dbnum; i++) {
j = (++next_db) % server.dbnum;
db = server.db+j;
dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ? db->dict : db->expires;
if (dictSize(dict) != 0) {
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
bestdbid = j;
break;
}
}
1.4 lfu/lru/ttl分支
相关定义,可以知道,淘汰策略的核心字段在于idle这个属性
#define EVPOOL_SIZE 16
#define EVPOOL_CACHED_SDS_SIZE 255
// 样本集类型
struct evictionPoolEntry {
unsigned long long idle; /* Object idle time (inverse frequency for LFU) */
sds key; /* Key name. */
sds cached; /* Cached SDS object for key name. */
int dbid; /* Key DB number. */
};
static struct evictionPoolEntry *EvictionPoolLRU;
首先初始化样本集,这部分和lru/lfu/ttl并无关系,核心在于evictionPoolPopulate函数
// 初始化样本集合
struct evictionPoolEntry *pool = EvictionPoolLRU;
while (bestkey == NULL) {
unsigned long total_keys = 0, keys;
// 遍历每一个db,更新/维护pool样本集
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
// 四个参数可以理解为:dbid, 候选集合(db->dict/db->expires), 完整集合(db->dict), 样本集合
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
// 无key可淘汰
if (!total_keys) break;
// 从后向前遍历, 并重置样本集
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[pool[k].dbid].dict,pool[k].key);
} else {
de = dictFind(server.db[pool[k].dbid].expires,pool[k].key);
}
pool[k].key = NULL;
pool[k].idle = 0;
// 寻找到bestkey,break
if (de) {
bestkey = dictGetKey(de);
break;
}
}
}
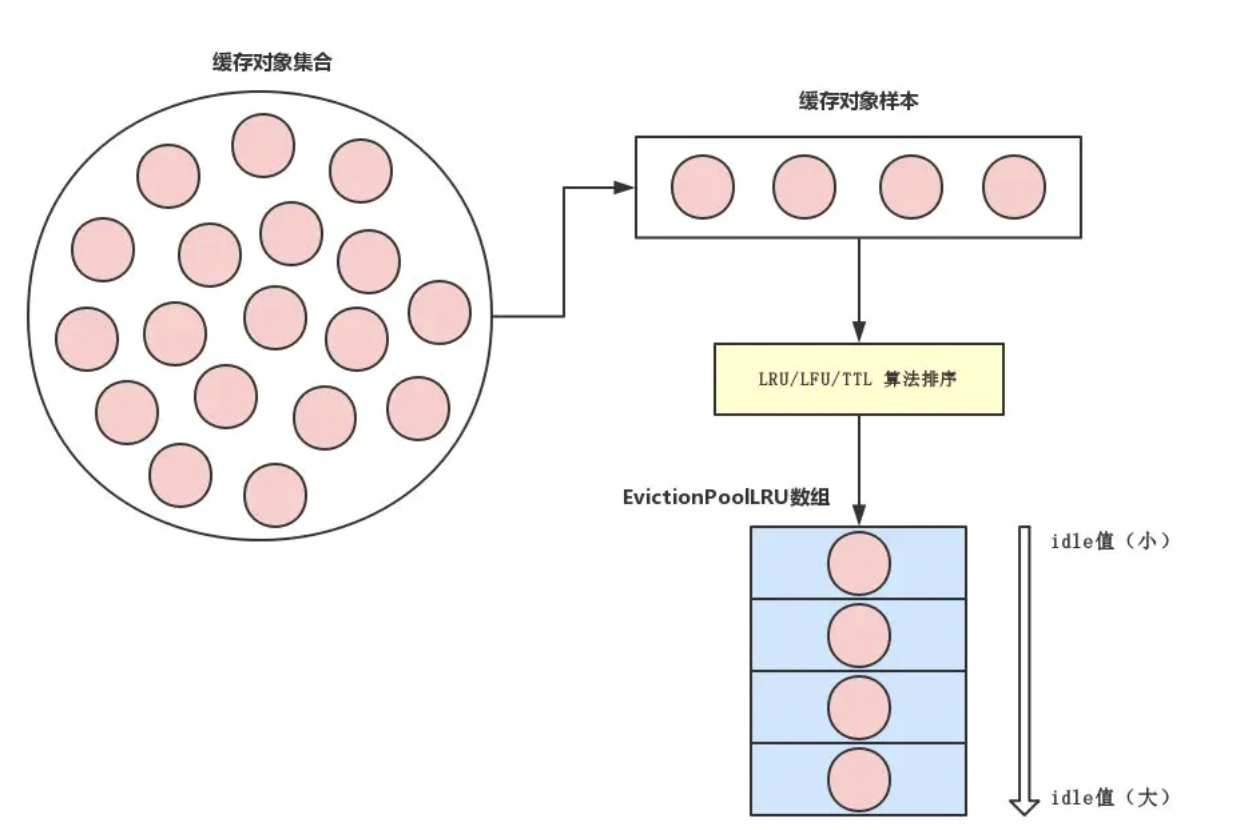
1.5 evictionPoolPopulate: LRU/LFU算法
首先,根据maxmemory_samples配置,选择一定数量的样本,这个值默认为5,值越高越接近真实的LRU/LFU算法,值越低,性能越高,所以需要平衡
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
// 见下一个代码块
}
遍历,根据策略计算出每一个样本的idle值,值越高,可以理解为匹配度越高,优先删除
volatile-ttl策略计算idle值方式: 快过期的放后面lru策略计算方式: 更久没访问的放前面lfu策略计算方式方式: 访问频率更低的放在后面,频率一致,比较谁更久没访问
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
// 然后维护样本集即可,后面的代码省略了
1.6 Redis LRU的实现
Redis维护了一个24bit的全局时钟,可以简单的理解为当前系统的时间戳,每隔一定时间会更新这个时钟,此处不拓展
// server.h 595行
#define LRU_BITS 24 // 24bit的时钟
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) // obj->lru时钟的最大值
#define LRU_CLOCK_RESOLUTION 1000 // 时钟精度,毫秒
// server.h 1017行
stuct redisServer {
// Clock for LRU eviction
_Atomic unsigned int lruclock;
}
每个key对象内部同样维护了一个24bit的时钟,后文中使用o->lru指代
// server.h 600行
typedef struct redisObject {
// LRU time (relative to global lru_clock)
unsigned lru:LRU_BITS
}
设置全局lruclock,当lruclock的值超过LRU_CLOCK_MAX,会从头开始计算
// src/evict.c 70行
unsigned int getLRUClock(void) {
return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
}
设置o->lru, 当新增key对象的时候会把系统的时钟赋值到这个内部对象时钟
// src/evict.c 78行
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
lruclock = server.lruclock;
} else {
lruclock = getLRUClock();
}
return lruclock;
}
比如现在要进行LRU,就需要对比lruclock和o->lru,它们有两种情况
lruclock >= o->lru: 这是通常情况lruclock < o->lru: 当lruclock的值超过LRU_CLOCK_MAX,会从头开始计算,因此会出现这种情况,需要计算额外的时间
// src/evict.c 88行
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION;
}
}
redis lfu的实现可以用晦涩难懂来形容了,没意思,不如去做leetcode
2. LRU golang实现
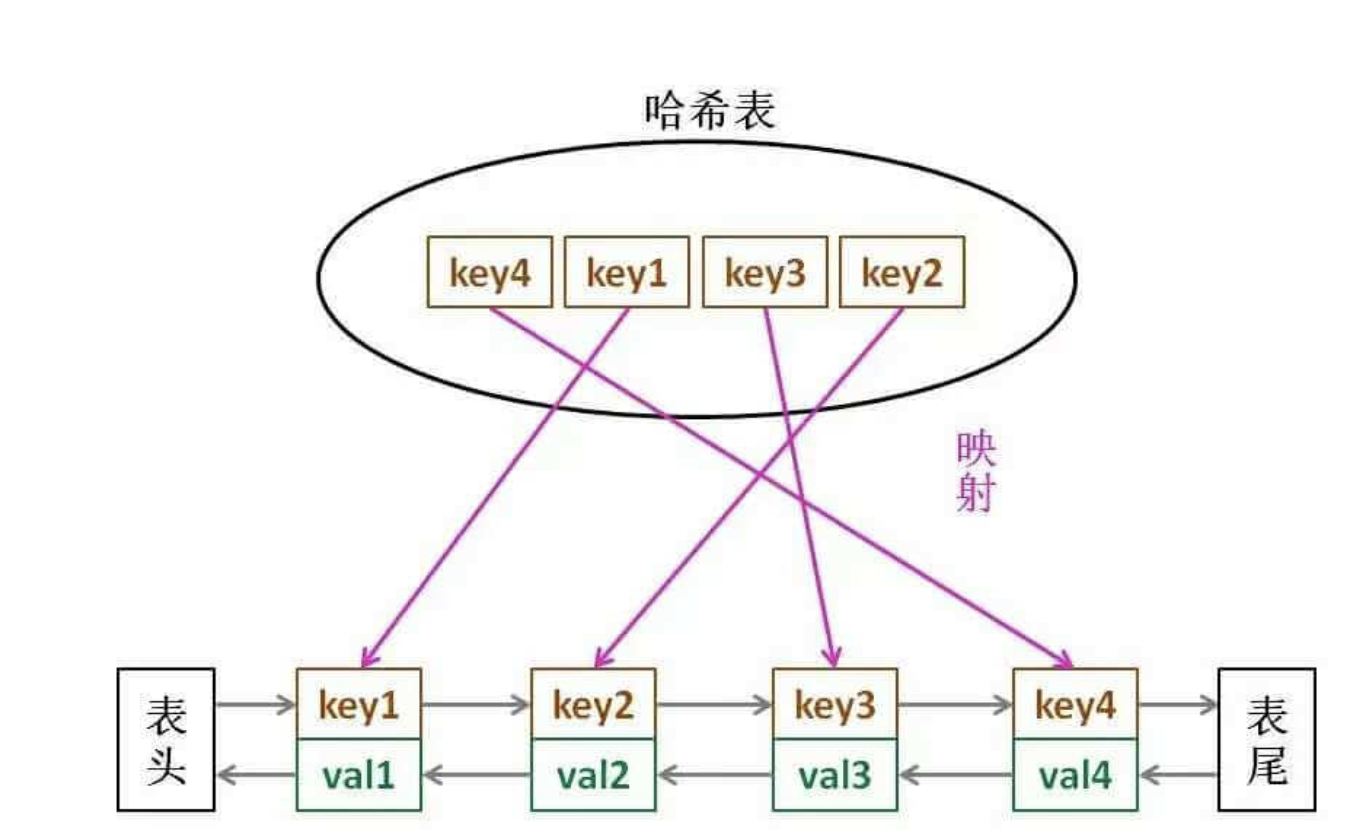
package problem0146
// 双向链表结构
type LinkNode struct {
key, value int
pre, next *LinkNode
}
// LRU结构
type LRUCache struct {
m map[int]*LinkNode
cap int
head, tail *LinkNode
}
func Constructor(capacity int) LRUCache {
head := &LinkNode{0, 0, nil, nil}
tail := &LinkNode{0, 0, nil, nil}
head.next = tail
tail.pre = head
return LRUCache{make(map[int]*LinkNode, capacity), capacity, head, tail}
}
func (this *LRUCache) moveToHead(node *LinkNode) {
this.removeNode(node)
this.addNode(node)
}
func (this *LRUCache) removeNode(node *LinkNode) {
node.pre.next = node.next
node.next.pre = node.pre
}
func (this *LRUCache) addNode(node *LinkNode) {
head := this.head
node.next = head.next
node.next.pre = node
node.pre = head
head.next = node
}
// 如果有,将这个元素移动到首位置,返回值
// 如果没有,返回-1
func (this *LRUCache) Get(key int) int {
if v, exist := this.m[key]; exist {
this.moveToHead(v)
return v.value
} else {
return -1
}
}
// 如果元素存在,将其移动到最前面,并更新值
// 如果元素不存在,插入到元素首,放入map(判断容量)
func (this *LRUCache) Put(key int, value int) {
tail := this.tail
cache := this.m
if v, exist := cache[key]; exist {
v.value = value
this.moveToHead(v)
} else {
v := &LinkNode{key, value, nil, nil}
if len(this.m) == this.cap {
delete(cache, tail.pre.key)
this.removeNode(tail.pre)
}
this.addNode(v)
cache[key] = v
}
}
3. LFU golang实现
package problem0460
// LRU: Least Recently Used,缓存满的时候,删除缓存里最久未使用的数据,然后放入新元素
// LFU: Least Frequently Used,缓存满的时候,删除缓存里使用次数最少的元素,然后放入新元素,如果使用频率一样,删除缓存最久的元素
// 节点:包含key, value, frequent访问次数, pre前驱指针, next后继指针
type Node struct {
key, value, frequent int
pre, next *Node
}
// 双向链表:包含head头指针, tail尾指针, size尺寸
type ListNode struct {
head, tail *Node
size int
}
// 双向链表辅助函数:添加一个节点到头节点后
func (this *ListNode) addNode(node *Node) {
head := this.head
node.next = head.next
node.next.pre = node
node.pre = head
head.next = node
}
// 双向链表辅助函数,删除一个节点
func (this *ListNode) removeNode(node *Node) {
node.pre.next = node.next
node.next.pre = node.pre
}
// LFUCache结构:包含capacity容量, size当前容量, minFrequent当前最少访问频次, cacheMap缓存哈希表, frequentMap频次哈希表
// minFrequent当前最少访问频次:
// 1. 插入一个新节点时,之前肯定没访问过,minFrequent = 1
// 2. put和get时,如果移除后双向链表节点个数为0,且恰好是最小访问链表, minFrequent++
type LFUCache struct {
capacity, size, minFrequent int
cacheMap map[int]*Node
frequentMap map[int]*ListNode
}
func Constructor(capacity int) LFUCache {
return LFUCache{
capacity: capacity,
size: 0,
minFrequent: 0,
cacheMap: make(map[int]*Node),
frequentMap: make(map[int]*ListNode),
}
}
// LFUCache辅助函数:将节点从对应的频次双向链表中删除
func (this *LFUCache) remove(node *Node) {
this.frequentMap[node.frequent].removeNode(node)
this.frequentMap[node.frequent].size--
}
// LFUCache辅助函数:将节点添加进对应的频次双向链表,没有则创建
func (this *LFUCache) add(node *Node) {
if listNode, exist := this.frequentMap[node.frequent]; exist {
listNode.addNode(node)
listNode.size++
} else {
listNode = &ListNode{&Node{}, &Node{}, 0}
listNode.head.next = listNode.tail
listNode.tail.pre = listNode.head
listNode.addNode(node)
listNode.size++
this.frequentMap[node.frequent] = listNode
}
}
// LFUCache辅助函数:移除一个key
func (this *LFUCache) evictNode() {
listNode := this.frequentMap[this.minFrequent]
delete(this.cacheMap, listNode.tail.pre.key)
listNode.removeNode(listNode.tail.pre)
listNode.size--
}
// LFUCache辅助函数:获取一个key和修改一个key都会增加对应key的访问频次,可以独立为一个方法,完成如下任务:
// 1. 将对应node从频次列表中移出
// 2. 维护minFrequent
// 3. 该节点访问频次++,移动进下一个访问频次链表
func (this *LFUCache) triggerVisit(node *Node) {
this.remove(node)
if node.frequent == this.minFrequent && this.frequentMap[node.frequent].size == 0 {
this.minFrequent++
}
node.frequent++
this.add(node)
}
func (this *LFUCache) Get(key int) int {
if node, exist := this.cacheMap[key]; exist {
this.triggerVisit(node)
return node.value
}
return -1
}
func (this *LFUCache) Put(key int, value int) {
if this.capacity == 0 {
return
}
if node, exist := this.cacheMap[key]; exist {
this.triggerVisit(node)
this.cacheMap[key].value = value
} else {
newNode := &Node{key, value, 1, nil, nil}
if this.size < this.capacity {
this.add(newNode)
this.size++
this.minFrequent = 1
} else {
this.evictNode()
this.add(newNode)
this.minFrequent = 1
}
this.cacheMap[key] = newNode
}
}
