


前言
这篇文章的诞生,其实来自于郭神给我的意见,同样的也是对之前面试官问我:“泛型擦除是什么,会带来什么问题?”一文中内容的一个补充,希望我如果有理解错误的地方能给我指正。
逆变与协变是什么?
从百度上只要这样输入关键词,java 逆变与协变 你就能得到类似与下方文字的统一解。
逆变与协变描述的是类型转换后的继承关系。
定义A,B两个类型,A是由B派生出来的子类(A<=B),f()表示类型转换如new List();
- 协变: 当A<=B时,f(A)<=f(B)成立。(String -> Object)
- 逆变: 当A<=B时,f(B)<=f(A)成立。(Object -> String)
- 不变: 当A<=B时,上面两个式子都不成立
先来解释一下,这几句话都是什么意思吧。
// 协变
List<? extends Fruit> fruit = new ArrayList<Apple>();
// 逆变
List<? super Apple> fruit = new ArrayList<Fruit>();
// 不变
List<Apple> fruit = new ArrayList<Apple>();
我想你一定会想问我,明明类似List<String> list = new ArrayList()或者Fruit[] fruit = new Apple[10];是可以编译成功的,但是不变的部分并不能编译成功这是为什么呢?
其实这和List内部并不自带协变机制是有关系,也就是上面说的不变,而如果这样写List<Fruit> fruit = new ArrayList<Apple>();就会编译出错的情况,换句话说就是ArrayList<Apple>和ArrayList<Fruit>他们不是一家人了。而逆变和协变的机制的引入,就是为了让他们重新建立亲子关系。而这个步骤的完成,就需要使用到我们之前在面试官问我:“泛型擦除是什么,会带来什么问题?”已经有所涉及的extends和super来完成任务了。
知道了上述的这些基本知识,我们就来逻辑证明一下上面说的论据吧。
协变: 当A<=B时,f(A)<=f(B)成立
定义: A是B的子类,就可以完成父类向子类的变换。
这个知识点的内容,你一定程度上可以参考向下转型。
List list = new ArrayList();
List<Fruit> flist = new ArrayList<Apple>(); // 为了让这样的形式成立,有了我们下方的代码
List<? extends Fruit> fruitList = new ArrayList<Apple>();
先来看看extends的作用范围:
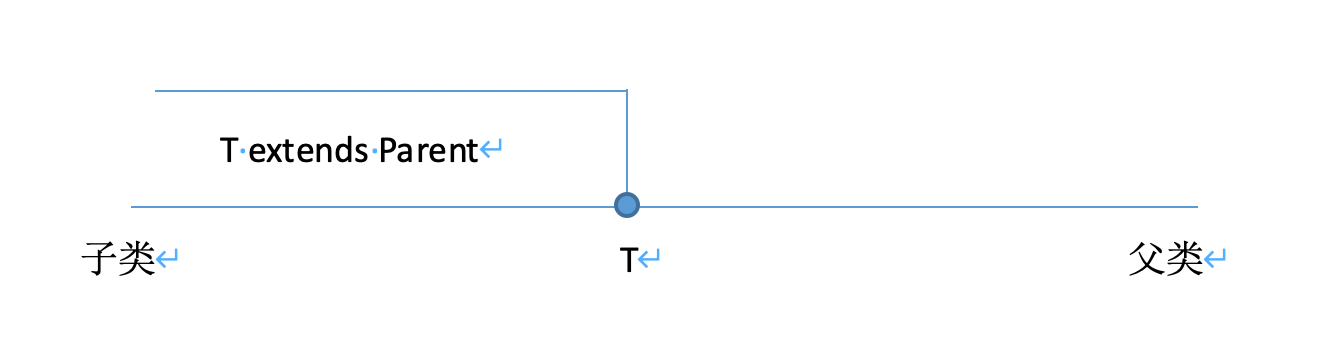
extends作为泛型中用于引入协变机制的关键词,他的作用域我们想来已经有所了解了,比较上述的两段代码,第一段是能够编译成功的,第二段则是编译失败的,这是为什么呢?我们已经说过了其实List内部并不像自带数组或者你直接创建一个对象一样直接完成变化,类似于T这样的泛型通配符,它在编译时并没有对这样的数据进行转化,原因是什么其实我之前的文章中已经对泛型有所讲述了,等等再温习一下。
逆变: 当A<=B时,f(B)<=f(A)成立
定义: A是B的子类,就可以完成子类向父类的变换。(一定程度上可参考向上转型)
List list =(List) new ArrayList();
List<Fruit> fruit = (ArrayList<Fruit>)new ArrayList<Apple>(); // 依旧编译错误,同理引进了super
List<? super Apple> fruit1 = new ArrayList<Fruit>();
同理为了解决这样的问题,Java引入了super关键词,作用域如下图:
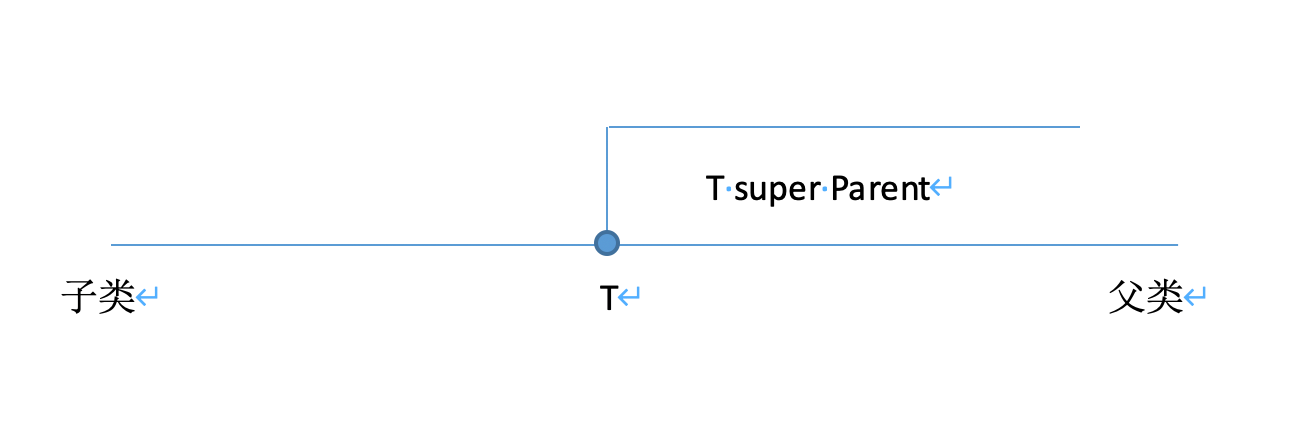
什么是不变,我就不说了。想来读者从上面的内容看完之后,已经知道了不变这个概念大概对应的含义了,其实就是下面这段代码,只能等于本身。而本身的意思就是我们上面说过的,ArrayList<Apple>和ArrayList<Fruit>他们不是一家人了。
List<Apple> list = new ArrayList<Apple>();
逆变与协变的作用是什么?
来了来了,又是一个重复的知识点。其实转化一下问题就是为什么要引入逆变与协变这两个机制呢?
先来想一下,泛型在运行时有什么问题? 很显然,泛型擦除嘛!!
那泛型擦除的具体表现是什么? 看过之前文章的读者肯定想骂我了,不就是变成了Object,最后通过强转再把类型转化回来嘛。
没错了,那我们的重新温习一下ArrayList的get()源码先。
public E get(int index) {
rangeCheck(index);
checkForComodification();
return ArrayList.this.elementData(offset + index); // 1 -->
}
E elementData(int index) {
return (E) elementData[index];
}
这个整体部分一共调用了两个函数,而第二个函数,你清晰可见的进行了强制转化,为什么?因为他保存的是Object,而不是我们赋予的Apple啊。
关于插入操作,为什么要用逆变
通过引入协变的机制,List<? extends Fruit> fruits = new ArrayList<Apple>();意味着某个继承自Fruit的具体类型,知道了上界,但是下界处于一个完全未知的状态下了。在这样的情况下,最明显的情况就是你无法完成我们的插入操作了。
List<? extends Fruit> fruits = new ArrayList<Apple>();
fruits.add(new Apple()); // 编译报错
fruits.add(new Fruit()); // 编译报错
fruits.add(new Object()); // 编译报错
为什么会这样呢?其实很简单,因为你忘记自己是谁了,但是你知道上界,也就是知道你的爸妈是谁,或者说祖父祖母是谁。就像是族谱,最顶上的人是你的曾曾曾。。。。。祖父和祖母,而我们只是族谱最下面的那几个毛头娃儿,你知道曾祖母是你的长辈,但是曾祖母却不一定知道你是她哪一个血脉的孩子。
所以创建的时候,你要注意这样的一个问题List<? extends Fruit> fruits = new ArrayList<Apple>();,他是为我们这几个毛头娃儿所创建,他这次是Apple,另一个人就可能是Orange、还有人可能是Pear,这样会出现什么问题?这个List他到底该存Apple呢,还是Orange呢,还是Pear,不论存储了哪一个,另一个就可能成为备胎,为了避开这样的问题,就干脆不要存他们好了。
而逆变机制就不一样了,他已经知道了下界,但是却不知道上界,那这个时候他的子子孙孙他就认识了,但是长辈那一栏我们知道他们,但是他们有很多东西我们继承并发展了新的东西,与他们的匹配度不再相同,就不能让老一辈他们加入我们新生代的行列了,而子子孙孙拿走了你的全部,并且有着自己的新玩意儿(当然这些新玩意儿不再我们的考虑范围内了),所以你能看到这样的情况,这个List能够加入我们的子孙的新玩意儿,而排斥着老一辈的落后思想。
List<? super Apple> apples = new ArrayList<Fruit>();
apples.add(new Apple());
apples.add(new Jonathan());
apples.add(new Fruit()); // 编译错误
关于获取操作,为什么要用协变
List<? extends Fruit> fruits = new ArrayList<Apple>();
Apple apple = fruits.get(0);
Jonathan jonathan = fruits.get(0); // 编译错误
Fruit fruit = fruits.get(0);
对于extends能够获得比大于或者等于他本身的数据,这是为什么?我们也说过了,他确定了上界,如果通过子类那数据,就会出现数据不匹配的情况。所以自然而然的对这方面进行了限制。就比如说fruits.get(0)获取的其实是Apple的里一个子类B,那这个时候,我们假设第三行代码运行成功,那么数据就会出现不匹配,因为你无法保证子类Jonathan的数据和子类B完全保持一致,但是他们俩的数据一定和Apple保持一致,当然为了数据的进一步安全,一般采用的都是使用基类来获取我们的数据,就是Fruit。
List<? super Apple> apples = new ArrayList<Fruit>();
Object jonathan = apples.get(0);
// 其余只能通过强制转化获得
而逆变的数据获取中,数据信息已经全部丢失,为什么这么说呢?因为我们虽然知道了下界,但是上界呢,他可能是Fruit,也有可能是万物的基类Object,在不知道上界,也就是父亲到底是谁的情况下,编译器直接设置成了Object,所以不再适合获取操作。
案例
在《Effective Java》给出过一个十分精炼的回答:producer-extends, consumer-super(PECS)。
从字面意思理解就是,extends是限制数据来源的(生产者),而super是限制数据流入的(消费者)。而显然我们一些经常使用到的代码中也都是符合了这一规则。
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
(src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
} else {
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++) {
di.next();
di.set(si.next());
}
}
}
Collections中的一个copy()函数,从字面意思我们应该就能知道把,就是复制的意思了,你看看他放入了什么玩意儿List<? super T> dest, List<? extends T> src,而src的数据类似就是协变,一个适合获取的方案。而比较器dest使用的就是就是super,因为要进行存储之类的操作。这也正好验证了我上述所说过的PECS。
总结
总归到底,上面这样做法的一切原因是其实都是为了数据安全。
下面总结了一条公式:
已知数据下界(super),应该细化存储;已知数据上界(extends),应该粗糙拿取。(其中细化就是指用子类或者本身存,粗糙就是用父类或者本身取)
wait!wait!wait!!!
疑惑:这里你是不是有点问题,感觉是不是和PECS这个原则有点不太一样呢? 我说extends是拿取,super是存储这不是正好反了吗?
其实是相同的,就那我们上面的案例来说好了。反证法来证明一下,Sun公司的工程师总比我资深吧,那这个玩意儿总该是对的,而且你在案例中也确实能看出是从src中获取数据,然后在des中存储对比,那说明一个问题,是不是应该把这个公式改成PSCE呢? No!No!No!!!
生产者是什么,是已经把东西做好的人,而extends正好满足了这个条件,你只管拿就好了。而消费者呢?显然就是那些能拿走这些东西的人,extends他能插入东西吗??要是你说行,你要自己写个代码试试,显然只能靠super来整啊。那也就说明PECS这个原则是正确的,而且提取的非常精炼,希望大神能够收下我的膝盖。

