

扫描下方二维码或者微信搜索公众号
菜鸟飞呀飞,即可关注微信公众号,阅读更多Spring源码分析、Java并发编程和Netty源码系列文章。

问题
在开始阅读本文之前,可以先思考一下下面两个问题。
- 众所周知,MySQL 有四大特性:ACID,其中 D 指的是持久性(Durability),它的含义是 MySQL 的事务一旦提交,它对数据库的改变是永久性的,即数据不会丢失,那么 MySQL 究竟是如何实现的呢?
- MySQL 数据库所在服务器宕机或者断电后,会出现数据丢失的问题吗?如果不丢失,它又是如何来实现数据不丢失的呢?
在 MySQL 5.5 以后,默认的存储引擎为 InnoDB,且只有 InnoDB 引擎支持事务和数据崩溃恢复,因此本文所有内容均是基于 InnoDB 存储引擎为前提。
redo log
MySQL 在更新数据时,为了减少磁盘的随机 IO,因此并不会直接更新磁盘上的数据,而是先更新 Buffer Pool 中缓存页的数据,等到合适的时间点,再将这个缓存页持久化到磁盘。而 Buffer Pool 中所有缓存页都是处于内存当中的,当 MySQL 宕机或者机器断电,内存中的数据就会丢失,因此 MySQL 为了防止缓存页中的数据在更新后出现数据丢失的现象,引入了 redo log 机制。
当进行增删改操作时,MySQL 会在更新 Buffer Pool 中的缓存页数据时,会记录一条对应操作的 redo log 日志,这样如果出现 MySQL 宕机或者断电时,如果有缓存页的数据还没来得及刷入磁盘,那么当 MySQL 重新启动时,可以根据 redo log 日志文件,进行数据重做,将数据恢复到宕机或者断电前的状态,保证了更新的数据不丢失,因此 redo log 又叫做重做日志。它的本质是保证事务提交后,更新的数据不丢失。
与 binlog 不同的是,redo log 中记录的是物理日志,是 InnoDB 引擎记录的,而 binlog 记录的是逻辑日志,是 MySQL 的 Server 层记录的。什么意思呢?binlog 中记录的是 SQL 语句(实际上并不一定为 SQL 语句,这与 binlog 的格式有关,如果指定的是 STATEMENT 格式,那么 binlog 中记录的就是 SQL 语句),也就是逻辑日志;而 redo log 中则记录的是对磁盘上的某个表空间的某个数据页的某一行数据的某个字段做了修改,修改后的值为多少,它记录的是对物理磁盘上数据的修改,因此称之为物理日志。
redo log 日志文件是持久化在磁盘上的,磁盘上可以有多个 redo log 文件,MySQL 默认有 2 个 redo log 文件,每个文件大小为 48MB,这两个文件默认存放在 MySQL 数据目录的文件夹下,这两个文件分别为 ib_logfile0 和 ib_logfile1。(本人电脑上安装的 MySQL 时,指定存放数据的目录是:/usr/local/mysql/data,因此这两个 redo log 文件所在的磁盘路径分别是:/usr/local/mysql/data/ib_logfile0 和/usr/local/mysql/data/ib_logfile1)。可以通过如下命令来查看 redo log 文件相关的配置。
show variables like 'innodb_log%'
查询结果如图。
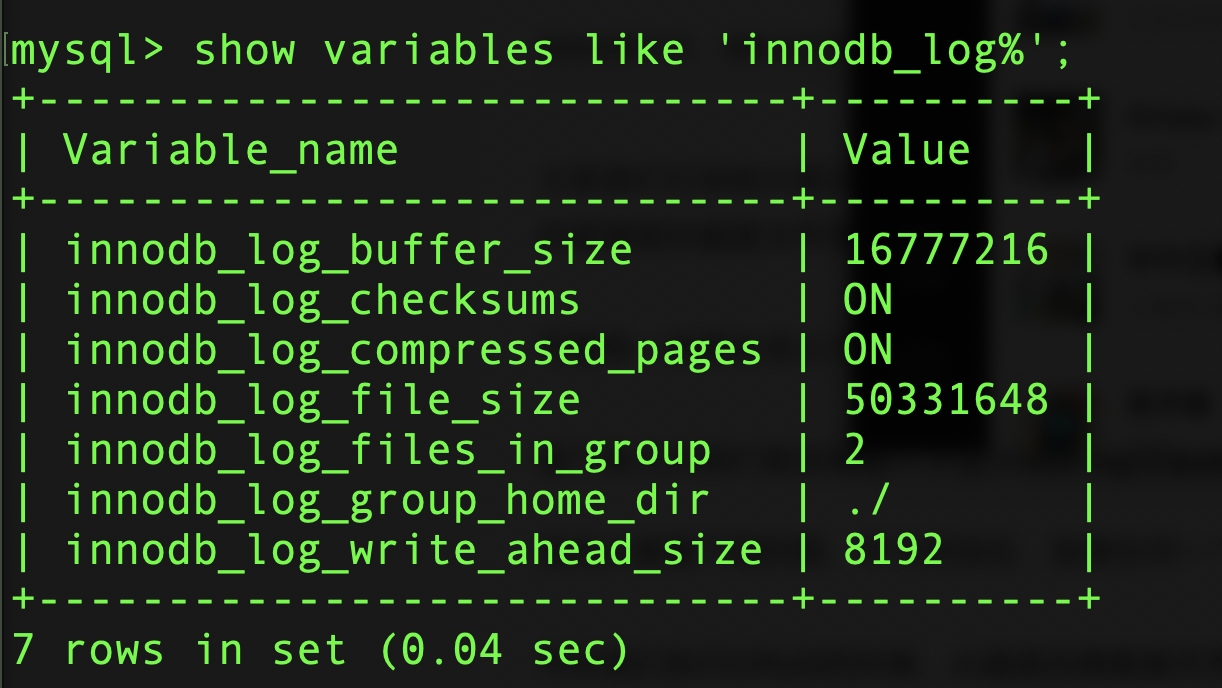
- innodb_log_files_in_group 表示的是有几个 redo log 日志文件。
- innodb_log_file_size 表示的是每个 redo log 日志文件的大小为多大。
- innodb_log_group_home_dir 表示的是 redo log 文件存放的目录,在这里./表示的是相对于 MySQL 存放数据的目录,这些参数可以根据实际需要自定义修改。
redo log buffer
当一条 SQL 更新完 Buffer Pool 中的缓存页后,就会记录一条 redo log 日志,前面提到了 redo log 日志是存储在磁盘上的,那么此时是不是立马就将 redo log 日志写入磁盘呢?显然不是的,而是先写入一个叫做 redo log buffer 的缓存中,redo log buffer 是一块不同于 buffer pool 的内存缓存区,在 MySQL 启动的时候,向内存中申请的一块内存区域,它是 redo log 日志缓冲区,默认大小是 16MB,由参数 innodb_log_buffer_size 控制(前面的截图中可以看到)。
redo log buffer 内部又可以划分为许多 redo log block,每个 redo log block 大小为 512 字节。我们写入的 redo log 日志,最终实际上是先写入在 redo log buffer 的 redo log block 中,然后在某一个合适的时间点,将这条 redo log 所在的 redo log block 刷入到磁盘中。
这个合适的时间点究竟是什么时候呢?
- MySQL 正常关闭的时候;
- MySQL 的后台线程每隔一段时间定时的讲 redo log buffer 刷入到磁盘,默认是每隔 1s 刷一次;
- 当 redo log buffer 中的日志写入量超过 redo log buffer 内存的一半时,即超过 8MB 时,会触发 redo log buffer 的刷盘;
- 当事务提交时,根据配置的参数 innodb_flush_log_at_trx_commit 来决定是否刷盘。如果 innodb_flush_log_at_trx_commit 参数配置为 0,表示事务提交时,不进行 redo log buffer 的刷盘操作;如果配置为 1,表示事务提交时,会将此时事务所对应的 redo log 所在的 redo log block 从内存写入到磁盘,同时调用 fysnc,确保数据落入到磁盘;如果配置为 2,表示只是将日志写入到操作系统的缓存,而不进行 fysnc 操作。(进程在向磁盘写入数据时,是先将数据写入到操作系统的缓存中:os cache,再调用 fsync 方法,才会将数据从 os cache 中刷新到磁盘上)
如何保证数据不丢失
前面介绍了 redo log 相关的基础知识,下面来看下 MySQL 究竟是如何来保证数据不丢失的。
- MySQL Server 层的执行器调用 InnoDB 存储引擎的数据更新接口;
- 存储引擎更新 Buffer Pool 中的缓存页,
- 同时存储引擎记录一条 redo log 到 redo log buffer 中,并将该条 redo log 的状态标记为 prepare 状态;
- 接着存储引擎告诉执行器,可以提交事务了。执行器接到通知后,会写 binlog 日志,然后提交事务;
- 存储引擎接到提交事务的通知后,将 redo log 的日志状态标记为 commit 状态;
- 接着根据 innodb_flush_log_at_commit 参数的配置,决定是否将 redo log buffer 中的日志刷入到磁盘。
将 redo log 日志标记为 prepare 状态和 commit 状态,这种做法称之为两阶段事务提交,它能保证事务在提交后,数据不丢失。为什么呢?redo log 在进行数据重做时,只有读到了 commit 标识,才会认为这条 redo log 日志是完整的,才会进行数据重做,否则会认为这个 redo log 日志不完整,不会进行数据重做。
例如,如果在 redo log 处于 prepare 状态后,buffer pool 中的缓存页(脏页)也还没来得及刷入到磁盘,写完 biglog 后就出现了宕机或者断电,此时提交的事务是失败的,那么在 MySQL 重启后,进行数据重做时,在 redo log 日志中由于该事务的 redo log 日志没有 commit 标识,那么就不会进行数据重做,磁盘上数据还是原来的数据,也就是事务没有提交,这符合我们的逻辑。
实际上要严格保证数据不丢失,必须得保证 innodb_flush_log_at_trx_commit 配置为 1。
如果配置成 0,则 redo log 即使标记为 commit 状态了,由于此时 redo log 处于 redo log buffer 中,如果断电,redo log buffer 内存中的数据会丢失,此时如果恰好 buffer pool 中的脏页也还没有刷新到磁盘,而 redo log 也丢失了,所以在 MySQL 重启后,由于丢失了一条 redo log,因此就会丢失一条 redo log 对应的重做日志,这样断电前提交的那一次事务的数据也就丢失了。
如果配置成 2,则事务提交时,会将 redo log buffer(实际上是此次事务所对应的那条 redo log 所在的 redo log block )写入磁盘,但是操作系统通常都会存在 os cache,所以这时候的写只是将数据写入到了 os cache,如果机器断电,数据依然会丢失。
而如果配置成 1,则表示事务提交时,就将对应的 redo log block 写入到磁盘,同时调用 fsync,fsync 会将数据强制从 os cache 中刷入到磁盘中,因此数据不会丢失。
从效率上来说,0 的效率最高,因为不涉及到磁盘 IO,但是会丢失数据;而 1 的效率最低,但是最安全,不会丢失数据。2 的效率居中,会丢失数据。在实际的生产环境中,通常要求是的是“双 1 配置”,即将 innodb_flush_log_at_trx_commit 设置为 1,另外一个 1 指的是写 binlog 时,将 sync_binlog 设置为 1,这样 binlog 的数据就不会丢失(后面的文章中会分析 binlog 相关的内容)。
疑惑
看到这里,有人可能会想,既然生产环境一般建议将 innodb_flush_log_at_trx_commit 设置为 1,也就是说每次更新数据时,最终还是要将 redo log 写入到磁盘,也就是还是会发生一次磁盘 IO,而我为什么不直接停止使用 redo log,而在每次更新数据时,也不要直接更新内存了,直接将数据更新到磁盘,这样也是发生了一次磁盘 IO,何必引入 redo log 这一机制呢?
首先引入 redo log 机制是十分必要的。因为写 redo log 时,我们将 redo log 日志追加到文件末尾,虽然也是一次磁盘 IO,但是这是顺序写操作(不需要移动磁头);而对于直接将数据更新到磁盘,涉及到的操作是将 buffer pool 中缓存页写入到磁盘上的数据页上,由于涉及到寻找数据页在磁盘的哪个地方,这个操作发生的是随机写操作(需要移动磁头),相比于顺序写操作,磁盘的随机写操作性能消耗更大,花费的时间更长,因此 redo log 机制更优,能提升 MySQL 的性能。
从另一方面来讲,通常一次更新操作,我们往往只会涉及到修改几个字节的数据,而如果因为仅仅修改几个字节的数据,就将整个数据页写入到磁盘(无论是磁盘还是 buffer pool,他们管理数据的单位都是以页为单位),这个代价未免也太了(每个数据页默认是 16KB),而一条 redo log 日志的大小可能就只有几个字节,因此每次磁盘 IO 写入的数据量更小,那么耗时也会更短。 综合来看,redo log 机制的引入,在提高 MySQL 性能的同时,也保证了数据的可靠性。
总结
最后解答下文章开头的两个问题。
- MySQL 通过 redo log 机制,以及两阶段事务提交(prepare 和 commit)来保证了事务的持久性。
- MySQL 中,只有当 innodb_flush_log_at_trx_commit 参数设置为 1 时,才不会出现数据丢失情况,当设置为 0 或者 2 时,可能会出现数据丢失。
相关推荐
