

背景: 在生产运维中,我们往往因为没有健全的可观测性方案或平台,不得以最后背上那口可保一家人吃饭的"锅",然后继续拼搏。 本篇文章就来讲解下
Traefik中的可观测性方案是如何做的,如何使用可观测性方案,让你进一步告别"背锅"。
注意: 在Traefik-2.X的生态里,将可观测性分为了如下几个部分,并提升到了专门的文档说明中traefik-observability.
服务日志: Traefik进程本身相关的操作日志访问日志: 由Traefik接管的代理服务的访问日志(access.log)Metrics: Traefik提供的自身详细的metrics数据Tracing: Traefik也提供了追踪相关的接口,用来可视化分布式或微服务中的调用情况
服务日志
注意:默认的环境中,Traefik会将日志以text格式写入到stdout中,如果使用docker的方式部署的话,想要查看日志需要使用docker logs container_name方式来查看日志。
相关配置
# toml 配置文件 $ cat traefik.toml [log] filePath = "/path/to/traefik.log" # 配置traefik的进程日志路径 format = "json" # 配置日志文件的格式[text(text|json)] level = "DEBUG" # 指定日志输出的级别[ERROR(ERROR|DEBUG|INFO|PANIC|FATAL|WARN)]cli 配置
--log.filePath=/path/to/traefik.log --log.format=json --log.level=DEBUG
注意: 具体的日志配置参数需要和当前环境中的traefik大版本兼容,否则可能会出现意想不到的问题。
访问日志
访问日志用来记录通过traefik进来的各个请求的访问详情,包含HTTP请求的各个header以及响应时间等数据,类似于Nginx中的access.log,通常情况,我们可以使用访问日志来分析整个traefik的整体流量以及各个服务流量以及状态详情。
注意: 访问日志默认也是以text格式被写到标准输出的
相关配置
# toml 配置文件 $ cat traefik.toml [accessLog] filePath = "/path/to/traefik.log" format = "" # 指定访问日志的格式,默认使用CLF(Common Log Format),可以指定为json格式 bufferingSize = 100 # 以异步方式写入日志需要指定该参数,表示写入到指定输出设备前保留在内存中的日志行数 [accessLog.filters] # 指定一组逻辑上是Or的过滤连接器,指定多个过滤器将比只指定一个过滤器保留更多的访问日志 statusCodes = ["200", "300-302"] # 过滤指定状态码范围的请求日志 retryAttempts = true # 当有重试时保留日志 minDuration = "10ms" # 当请求花费的时间超过指定的持续时间时,保留访问日志[accessLog.fields] # 限制访问日志中的字段(可以使用fields.names和fields.header选项来决定字段的输出) defaultMode = "keep" # 每种字段可以设置成如下字段(keep:保留字段,drop:丢弃,redact:使用redacted替换值) [accessLog.fields.names] # 指定限制的字段名称 "ClientUsername" = "drop" # 设置ClientUsername字段为丢弃 [accessLog.fields.headers] # 设置headers相关字段 defaultMode = "keep" # 对全部的header进行默认保留 [accessLog.fields.headers.names] # 对指定的header字段设置保留规则 "User-Agent" = "redact" "Authorization" = "drop" "Content-Type" = "keep"
cli 配置
--accesslog=true --accesslog.filepath=/path/to/access.log --accesslog.format=json --accesslog.bufferingsize=100 --accesslog.filters.statuscodes=200,300-302 --accesslog.filters.retryattempts --accesslog.filters.minduration=10ms --accesslog.fields.defaultmode=keep --accesslog.fields.names.ClientUsername=drop --accesslog.fields.headers.defaultmode=keep --accesslog.fields.headers.names.User-Agent=redact --accesslog.fields.headers.names.Authorization=drop --accesslog.fields.headers.names.Content-Type=keep
注意: 由于我们是将Traefik当做Kubernetes集群中的边缘节点,去代理内部HTTP服务的,因此Traefik部署在集群内部,将进程日志和访问日志都以volume的方式挂载到边缘节点的数据目录中。
使用DaemonSet方式将Traefik部署在k8s集群内部,具体的配置如下:
$ cat traefik-ds.yml --- kind: DaemonSet apiVersion: extensions/v1beta1 metadata: name: traefik-ingress-controller namespace: kube-system labels: k8s-app: traefik-ingress-lb spec: template: metadata: labels: k8s-app: traefik-ingress-lb name: traefik-ingress-lb spec: affinity: # 定义node的亲和性,不允许调度到master节点 nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-role.kubernetes.io/master operator: DoesNotExist serviceAccountName: traefik-ingress-controller terminationGracePeriodSeconds: 30 hostNetwork: true containers: - image: traefik:v1.7.16 name: traefik-ingress-lb ports: - name: http containerPort: 80 hostPort: 80 - name: admin containerPort: 8080 securityContext: capabilities: drop: - ALL add: - NET_BIND_SERVICE args: - --api - --kubernetes - --logLevel=INFO - --traefikLog.filePath=/logdata/traefik.log - --configfile=/config/traefik.toml - --accesslog.filepath=/logdata/access.log - --accesslog.bufferingsize=100 volumeMounts: - mountPath: /config name: config - mountPath: /logdata name: access-log volumes: - configMap: name: traefik-config name: config - name: access-log hostPath: path: /opt/logs/ingress/查看traefik 的状态
$ kubectl get pods -n kube-system | grep traefik traefik-ingress-controller-2dx7k 1/1 Running 0 5h28m ... ...
$ kubectl get svc -n kube-system | grep traefik traefik-ingress-service ClusterIP 10.253.132.216 <none> 80/TCP,8080/TCP 123d traefik-web-ui ClusterIP 10.253.54.184 <none> 80/TCP 172d
可以通过节点的ping接口和admin接口来查看traefik服务是否正常
$ curl 10.253.132.216/ping OK
$ curl 10.253.132.216:8080 <a href="/dashboard/">Found</a>.
在调度到treafik的节点上查看进程日志和访问日志
$ tree -L 2 /opt/logs/ingress/ /opt/logs/ingress/ ├── access.log └── traefik.log
$ tail -n 10 /opt/logs/ingress/traefik.log time="2020-04-07T08:53:38Z" level=warning msg="Endpoints not available for my-data/my-data-selfaccess-dev" time="2020-04-07T08:53:38Z" level=warning msg="Endpoints not available for my-data/my-data-metadata-prod1"
$ tail -n 10 /opt/logs/ingress/access.log 172.16.21.28 - - [07/Apr/2020:08:52:54 +0000] "POST /.kibana/_search?ignore_unavailable=true&filter_path=aggregations.types.buckets HTTP/1.1" 503 161 "-" "-" 491674 "prod-es-cluster.soulapp-inc.cn" "http://20.0.41.10:9200" 1ms 172.16.21.28 - - [07/Apr/2020:08:52:54 +0000] "POST /.kibana/_search?ignore_unavailable=true&filter_path=aggregations.types.buckets HTTP/1.1" 503 161 "-" "-" 491671 "prod-es-cluster.soulapp-inc.cn" "http://20.0.26.20:9200" 1ms 172.16.21.28 - - [07/Apr/2020:08:52:54 +0000] "GET /.kibana/doc/config%3A6.4.0 HTTP/1.1" 503 301 "-" "-" 491675 "prod-es-cluster.soulapp-inc.cn" "http://20.0.14.6:9200" 1ms
从访问日志的输出格式中,我们可以看到,traefik的访问日志和Nginx的访问日志会比较相似,有了这份日志后,我们可以通过一些ELK之类的日志分析方案来分期网站的整体状态,比如UV,PV,区域分布,状态分布以及响应时间等等。
另外,我们是将访问日志直接持久化输出到node节点上,后面可以通过node主机上的日志采集插件,将日志发送到ELK Stack中进行分析,当然也可以直接将ELK Stack的日志采集端部署到traefik的pod中。
Metrics
Traefik默认支持四种Metrics的后端架构:
想要开启metrics的支持,只需要做如下配置:
# toml 配置文件 [metrics]yaml 配置文件
metrics: {}
cli 配置
--metrics=true
Datadog后端支持
配置详情:
# toml配置文件 [metrics] [metrics.datadog] address = "127.0.0.1:8125" addEntryPointsLabels = true #在入口处增加metrics标签[true] addServicesLabels = true #在service中启用meirtcs[true] pushInterval = 10s #push metrics到datalog的间隔时间[10s]cli 配置
--metrics.datadog=true --metrics.datadog.address=127.0.0.1:8125 --metrics.datadog.addEntryPointsLabels=true --metrics.datadog.addServicesLabels=true --metrics.datadog.pushInterval=10s
InfluxDB后端支持
配置详情:
# toml配置 [metrics] [metrics.influxDB] address = "localhost:8089" #指定influxdb地址 [localhost:8089] protocol = "udp" #influxdb的传输协议 [udp(udp|http)] database = "db" #指定metrics写入的库[""] retentionPolicy = "two_hours" #metrics在influxdb中的保留策略 [""] username = "" #influxdb用户名 password = "" #influxdb密码 addEntryPointsLabels = true #入口处增加metrics标签[true] addServicesLabels = true #在service中启用meirtcs[true] pushInterval = 10s #push metrics到datalog的间隔时间[10s]cli 配置
--metrics.influxdb=true --metrics.influxdb.address=localhost:8089 --metrics.influxdb.protocol=udp --metrics.influxdb.database=db --metrics.influxdb.retentionPolicy=two_hours --metrics.influxdb.username=john --metrics.influxdb.password=secret --metrics.influxdb.addEntryPointsLabels=true --metrics.influxdb.addServicesLabels=true --metrics.influxdb.pushInterval=10s
Prometheus后端支持
配置详情:
# toml配置 [metrics] [metrics.prometheus] buckets = [0.1,0.3,1.2,5.0] #延迟的metrics的bucket存储[0.100000, 0.300000, 1.200000, 5.000000] addEntryPointsLabels = true #入口处增加metrics标签[true] addServicesLabels = true #在service中启用meirtcs[true] entryPoint = "traefik" #指定metrics的端点[traefik(默认是管理端口8080/metrics)],也可以自定义 manualRouting = true #是否禁用内部路由[false]cli配置
--metrics.prometheus=true --metrics.prometheus.buckets=0.100000, 0.300000, 1.200000, 5.000000 --metrics.prometheus.addEntryPointsLabels=true --metrics.prometheus.addServicesLabels=true
自定义了一个metrics端点,并指定了端口
--metrics.prometheus.entryPoint=metrics --entryPoints.metrics.address=:8082 --metrics.prometheus.manualrouting=true
注意:和其他两种方式不同的是,prometheus仅会暴露metrics,是需要使用prometheus-server定期进行pull来收集数据的。
配置生效后,可以访问如下端口进行测试:
# 自定义了metrics端点 $ curl localhost:8082/metrics使用默认的traefik端点(用的是admin的端口)
$ curl localhost:8080/metrics
StatsD后端支持
详细配置:
# toml 配置 [metrics] [metrics.statsD] address = "localhost:8125" # 指定statsD服务地址 addEntryPointsLabels = true # 入口处增加metrics标签[true] addServicesLabels = true # 在service中启用meirtcs[true] pushInterval = 10s # push间隔 prefix = "traefik" # 定义metrics收集的前缀[traefik]cli 配置
--metrics.statsd=true --metrics.statsd.address=localhost:8125 --metrics.statsd.addEntryPointsLabels=true --metrics.statsd.addServicesLabels=true --metrics.statsd.pushInterval=10s --metrics.statsd.prefix="traefik"
基于Prometheus后端的Metrics分析
注意: 由于在生产环境使用的是traefik-1.7.6版本,因此上述的一些配置参数可能并不适用于该版本,详细的参数需要查看具体版本的支持参数,同时我们将traefik当做kubernetes集群中的ingress方案,因此如下操作在一个可用的k8s集群内部。
1.traefik的metrics配置
# traefik metrics 配置 $ cat traefik-config.yaml apiVersion: v1 kind: ConfigMap metadata: name: traefik-config namespace: kube-system data: traefik.toml: | defaultEntryPoints = ["http","https"] debug = false logLevel = "INFO"InsecureSkipVerify = true [entryPoints] [entryPoints.http] address = ":80" compress = true [entryPoints.https] address = ":443" [entryPoints.https.tls] [web] address = ":8080" [kubernetes] # 定义metrics相关参数 [metrics] [metrics.prometheus] buckets=[0.1,0.3,1.2,5.0] entryPoint = "traefik" [ping] entryPoint = "http"重新调度pod后,即可查看暴露的endpoint
$ kubectl get ep -A | grep traefik kube-system traefik-ingress-service 172.16.171.163:80,172.16.21.26:80,172.16.21.27:80 + 11 more... 122d kube-system traefik-web-ui 172.16.171.163:8080,172.16.21.26:8080,172.16.21.27:8080 + 4 more... 171d
$ kubectl get svc -n kube-system | grep traefik traefik-ingress-service ClusterIP 10.253.132.216 <none> 80/TCP,8080/TCP 122d traefik-web-ui ClusterIP 10.253.54.184 <none> 80/TCP 171d
测试访问metrics服务(因为和traefik相关的两个service均路由到了traefil-ingress的pod上,下面两个效果是一致的)
curl -s 10.253.54.184/metrics | head -10
注意: 推荐使用traefik-web-ui暴露的svc地址
指标以及相关含义:
| 指标项 | 含义 |
|---|---|
| process_max_fds | traefik进程最大的fd |
| process_open_fds | 进程打开的fd |
| process_resident_memory_bytes | 进程占用内存 |
| process_start_time_seconds | 进程启动时间 |
| process_virtual_memory_bytes | 进程占用虚拟内存 |
| traefik_backend_open_connections | traefik后端打开链接 |
| traefik_backend_request_duration_seconds_bucket | traefik后端请求处理时间 |
| traefik_backend_request_duration_seconds_sum | 总时间 |
| traefik_backend_request_duration_seconds_count | 总请求时间 |
| traefik_backend_requests_total | 一个后端处理的总请求数(按status code, protocol, and method划分) |
| traefik_backend_server_up | 后端是否up(0 |
| traefik_config_last_reload_failure | traefik上次失败reload的时间 |
| traefik_config_last_reload_success | 上次成功reload的时间 |
| traefik_config_reloads_failure_total | 失败次数 |
| traefik_config_reloads_total | 成功次数 |
| traefik_entrypoint_open_connections | 入口点存在打开链接的数量(method and protocol划分) |
| traefik_entrypoint_request_duration_seconds_bucket | 在入口点处理请求花费的时间(status code, protocol, and method.) |
| traefik_entrypoint_requests_total | 一个入口点处理的总请求数(状态码分布) |
2.配置prometheus-server
注意,此时我们需要配置prometheus-server来对traefik暴露的metrics进行定期的pull采集。
# 在k8s中创建一个prometheus monitor service $ cat prometheus-traefik.yml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: traefik-ingress-lb name: traefik-metrics namespace: monitoring spec: # 对应的端点是上面创建的svc的ports endpoints: # 定义endpoint采集的时间 - interval: 30s port: admin path: /metrics jobLabel: k8s-app # 匹配monitoring命名空间的app=gpu-metrics的svc namespaceSelector: matchNames: - kube-system selector: matchLabels: k8s-app: traefik-ingress-lb
$ kubectl apply -f prometheus-traefik.yml
配置完成后,即可在prometheus中查看相关的metrics数据。
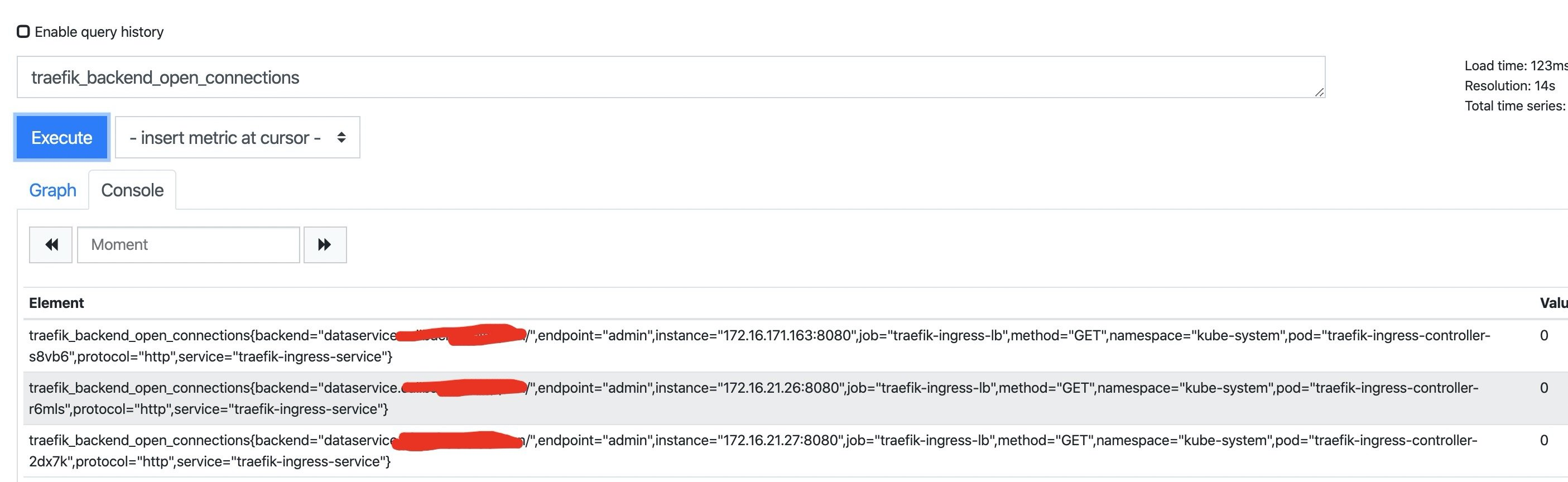
3.根据指标配置Grafana
针对Traefik-Metrics的指标展示,在Grafana官网中已经有很多开源的模板,这里我基于实际需求也开源了一个模板,可以直接使用(具体导入方式请百度)。
Traefik-Process-All-Grafana-Template
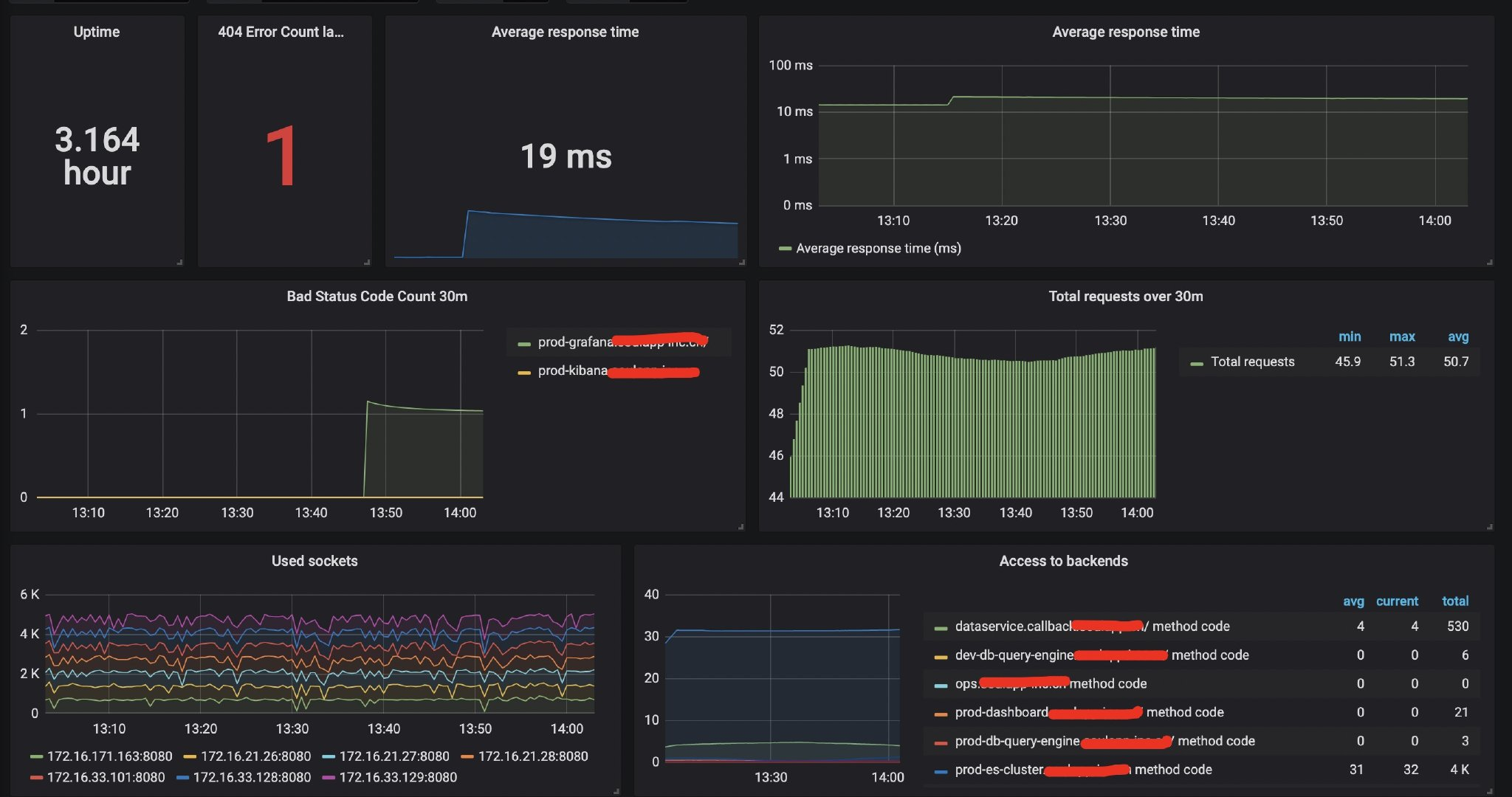
有了Merics的可视化后,针对于HTTP服务来说做各种滚动升级以及切流发布时,就很容易能够看到整个流量的变化。
Tracing
追踪系统可以开发人员可视化其基础架构中的调用流程.
Traefik遵循OpenTracing规范(一个为分布式跟踪而设计的开放标准)
Traefik支持五种追踪系统后端:
注意: Datadog,Instana,Haystack为商业解决方案,以下不做介绍
1.配置
注意: 默认情况下,traefik使用Jaeger来最为追踪系统的后端实现.
# toml 配置文件 $ cat traefik.toml [tracing] serviceName = "traefik" # 选择追踪系统的后端实现[traefik(表示使用jaeger)] spanNameLimit = 150 # 限制长名称的名称阶段(这可以防止某些跟踪提供程序删除超过其长度限制的跟踪)cli 配置
--tracing=true --tracing.serviceName=traefik --tracing.spanNameLimit=150
2.Jaeger
相关配置:
# toml 配置文件 $ cat traefik.toml [tracing] [tracing.jaeger] # 开启jaeger的追踪支持 samplingServerURL = "http://localhost:5778/sampling" # 指定jaeger-agent的http采样地址 samplingType = "const" # 指定采样类型[const(const|probabilistic|rateLimiting)] samplingParam = 1.0 # 采样参数的值[1.0(const:0|1,probabilistic:0-1,rateLimiting:每秒的span数)] localAgentHostPort = "127.0.0.1:6831" # 本地agent主机和端口(会发送到jaeger-agent) gen128Bit = true # 生成128位的traceId,兼容OpenCensus propagation = "jaeger" # 设置数据传输的header类型[jaeger(jaeger|b3兼容OpenZipkin)] traceContextHeaderName = "uber-trace-id" # 跟踪上下文的header,用于传输跟踪上下文的http头名 [tracing.jaeger.collector] # 指定jaeger的collector服务 endpoint = "http://127.0.0.1:14268/api/traces?format=jaeger.thrift" user = "my-user" # 向collector提交时的http认证用户[""] password = "my-password" # 向collector提交时的http认证密码[""]cli 配置
--tracing.jaeger=true --tracing.jaeger.samplingServerURL=http://localhost:5778/sampling --tracing.jaeger.samplingType=const --tracing.jaeger.samplingParam=1.0 --tracing.jaeger.localAgentHostPort=127.0.0.1:6831 --tracing.jaeger.gen128Bit --tracing.jaeger.propagation=jaeger --tracing.jaeger.traceContextHeaderName=uber-trace-id --tracing.jaeger.collector.endpoint=http://127.0.0.1:14268/api/traces?format=jaeger.thrift --tracing.jaeger.collector.user=my-user --tracing.jaeger.collector.password=my-password
3.Zipkin
相关配置:
# toml 配置文件 [tracing] [tracing.zipkin] # 指定使用zipkin追踪系统 httpEndpoint = "http://localhost:9411/api/v2/spans" # 指定zipkip收集数据的http端点 sameSpan = true # 使用Zipkin SameSpan RPC 类型追踪方式 id128Bit = true # 使用Zipkin 128 bit的追踪id(true) sampleRate = 0.2 # 指定请求trace系统的频率[1.0(0.1-1.0)]cli 配置
--tracing.zipkin=true --tracing.zipkin.httpEndpoint=http://localhost:9411/api/v2/spans --tracing.zipkin.sameSpan=true --tracing.zipkin.id128Bit=false --tracing.zipkin.sampleRate=0.2
4.Elastic
相关配置:
# toml 配置文件 $ cat traefik.toml [tracing] [tracing.elastic] serverURL = "http://apm:8200" # 指定Elastic APM服务地址 secretToken = "" # 指定Elastic APM服务的安全token serviceEnvironment = "" # 指定APM Server的环境cli 配置
--tracing.elastic=true --tracing.elastic.serverurl="http://apm:8200" --tracing.elastic.secrettoken="mytoken" --tracing.elastic.serviceenvironment="production"


本文使用 mdnice 排版
