

前言
缓存是非常重要的,其更新方式也有集中比较典型的模式,这些模式各有利弊,因此总结一下。期待可以在阅读代码的时候,能够快速的反应出缓存使用的模式。
错误的做法:先删除缓存,再更新数据库
这是常见的错误方法,在并发环境下容易产生脏数据。具体逻辑如下:
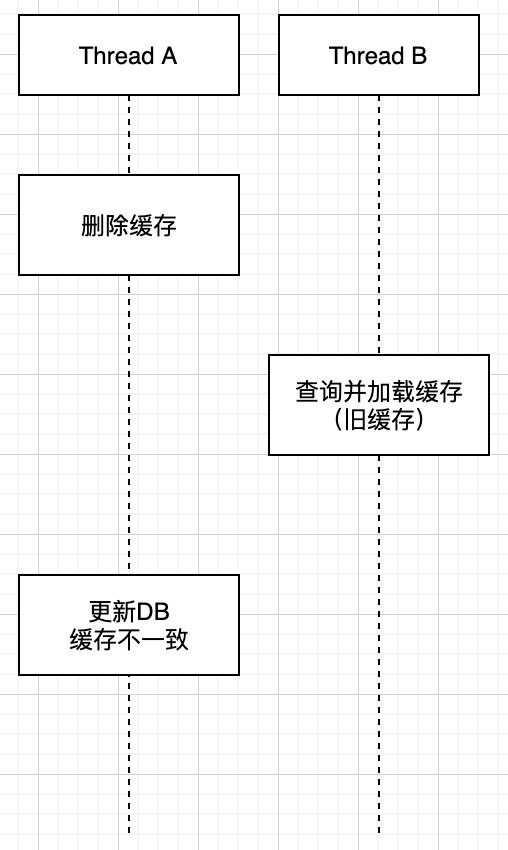
这个脏数据会一致存在缓存中,并且会一致脏下去,所以是比较有问题的。
Read/Write Through
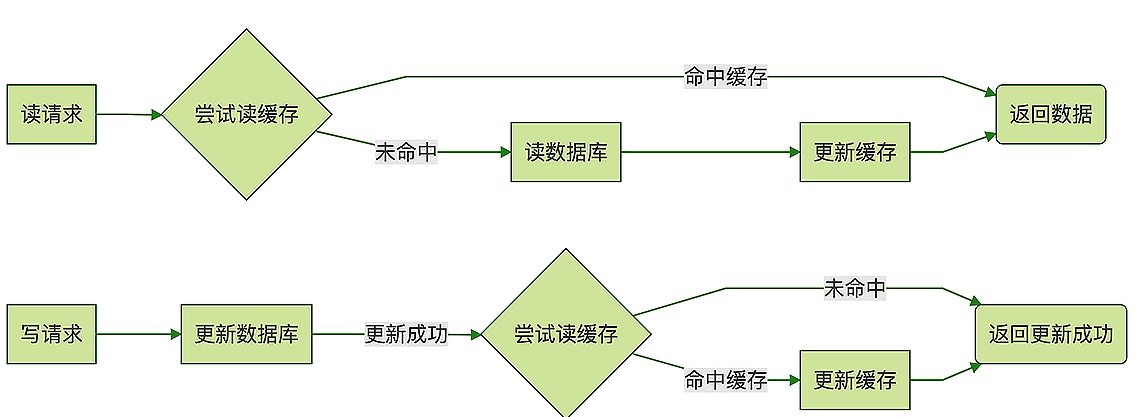
图片引用自 极客时间 后端存储实践课 11讲
这是一种典型的使用方法,大概的操作分两个
- 读数据,命中则直接返回,不命中;就读库,并且更新缓存;
- 写数据,先更新数据库,检查缓存,命中,则更新缓存;不命中,不操作直接完成。
这是一种典型的使用方式,但在并发环境下依然会出现脏数据。如下图所示
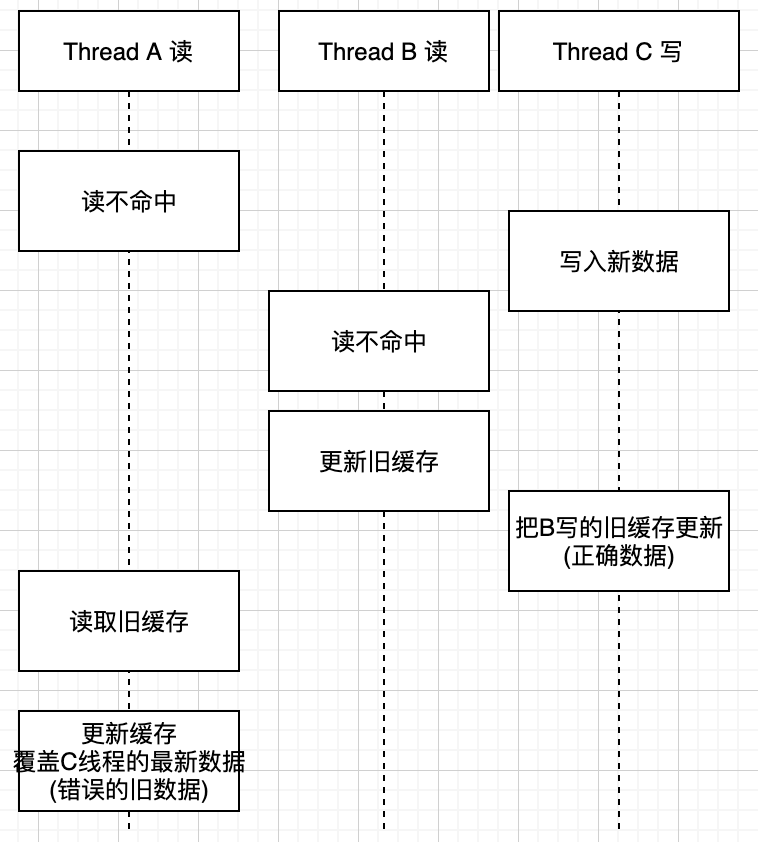
这种情况有一种条件,就是写比读速度更快,因为写还需要锁,所以上述情况一般情况下是比较难出现的。
如果两个线程都是写,那么就真的有可能出现上述的脏数据了。以下是Quora关于这个问题的回答。
Just imagine what if two concurrent updates of the same data element occur? You might have different values of the same data item in DB and in memcached. Which is bad. There is a certain number of ways to avoid or to decrease probability of this. Here is the couple of them:
- A single transaction coordinator
- Many transaction coordinators, with an elected master via Paxos or Raft consensus algorithm
- Deletion of elements from memcached on DB updates I assume that they chose the way #3 because "a single" means a single point of failure, and Paxos/Raft is not easy to implement plus it sacrifices availability for the benefit of consistency.
Cache Aside
上文说了,并发写有可能产生脏数据问题,Cache Aside 这个模式则可以避免,Cache Aside 也不是完全可以解决缓存不一致的问题,至少读慢于写所引发的脏数据还是可能存在的。
不过 Cache Aside 算是非常安全的了,也是最常用的模式。它只会在读的时候把数据写到缓存中,所有的写数据最终都是会清除缓存的。
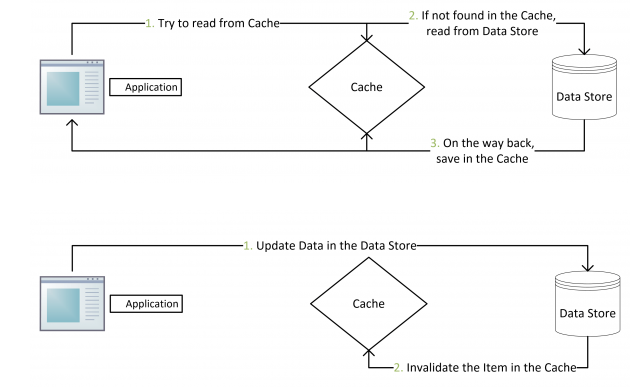
图片引用自 CoolShell《缓存更新的套路》
Write Behind Caching
这也叫做Wirte Back。简单来说,就是更新数据的时候,只更新缓存,不更新数据库,而缓存会异步地批量更新数据库。这个设计的好处是让数据的I/O操作可以很快,异步的操作还可以合并对同一个数据的多次操作,性能上是非常可观的。 ---- CoolShell 《缓存更新的套路》
我的游戏项目为了最求比较极致的响应速度,会把更新的操作通过队列异步入库。这里也会带来两个问题:
- 1 由于存在中间环节,数据有可能会因为断电丢失;
- 2 缓存只能有一份,代码中只能使用Local cache;
- 3 只用一个缓存对象,不同的线程处理,那就引起了一种可见性问题;
这里我解决的有1、3个问题:
- 1 参考Mysql的redo log,对于关键数据,通过消息队列把数据向其他的数据库 ES 备份一次。这里的数据可以一个月一清。
- 3 在对象内部设置一个 volatile 变量,代表版本信息,在每次改变值的时候都会递增值;在入库的时候都会去读这个变量,通过 volatile 的 happen-before ,入库线程就可以对对象的数据始终可见。
后记
这是常用的集中缓存更新的模式,总而言之,Cache Aside 是比较常用的。Write Behind Caching 技术是一种有损的缓存技术,带来极致的性能的同时,也会带来一些数据丢失的风险。
