

前言
作为一名从事交易所相关开发的工程师,我们每天都在跟数字货币打交道,每天都在充币、提币、转账、查询余额、身份验证、交易数确认等等。其中一些数字货币是基于以太坊的erc20代币, 那大家有没有想过或者思考过这些代币是以一种什么样的方式组织并存储在以太坊的区块链系统中的?它又是如何记录每一次的转账过程? 它又是如何在出现分叉并确定主链后还原到之前的账户状态的?底层采用了什么样的数据结构来支撑这个账户系统的呢?
问题
在解决问题之前我们一般都是要定义清楚问题,除了对问题进行详细的分析和调研,还可以对一些模糊的需求进行假设来限定问题的范围,让我们更加的聚焦问题本身
我们可以思考一下, 账户系统需要提供哪些常用的操作
- 查询,存钱, 取钱
这些用关系型数据库或者KV数据库是否可以解决?
如果能解决,那前提是什么呢?
如何保证账目没有被篡改?
如何保证我们查询到的余额是真实并且正确的?
那对于去中心化的系统我们如何解决这个问题呢?接下来我们来看下以太坊是如何处理的
以太坊是如何解决的
系统需要满足的几个常用的基本需求:
- 能够快速的通过账户地址查询,添加,删除和更新余额
- 需要能够提供一种快速计算维护数据集哈希的机制(如果是用hash来做地址的话)
- 能够提供快速状态回滚的机制
- 能够提供轻节点证明的机制
以太坊采用来一个叫 MPT 的数据结构, Merkle Patricia tree/trie, 最早是由Alan Reiner设想并在Ripple协议中实现的.
由于MPT结合了 Merkle tree 和 Patricia tree 两种树结构的特点与优势,
因此在介绍MPT之前,我们首先简要地介绍下这两种树结构特点.
Merkle tree (默克尔树)
Merkle树是由计算机科学家 Ralph Merkle 在很多年前提出的,并以他本人的名字来命名,由于在比特币网络中用到了这种数据结构来进行数据正确性的验证,在这里简要地介绍一下merkle树的特点及原理。
在比特币网络中,merkle树被用来归纳一个区块中的所有交易,同时生成整个交易集合的数字指纹。此外,由于merkle树的存在,使得在比特币这种公链的场景下,扩展一种“轻节点”实现简单支付验证变成可能。
特点
- 默克尔树是一种树,大多数是二叉树,也可以多叉树,无论是几叉树,它都具有树结构的所有特点;
- 默克尔树叶子节点的value是数据项的内容,或者是数据项的哈希值;
- 非叶子节点的value根据其孩子节点的信息,然后按照Hash算法计算而得出的;
原理
在比特币网络中,merkle树是自底向上构建的。在下图的例子中,首先将L1-L4四个单元数据哈希化,然后将哈希值存储至相应的叶子节点。这些节点是Hash0-0, Hash0-1, Hash1-0, Hash1-1
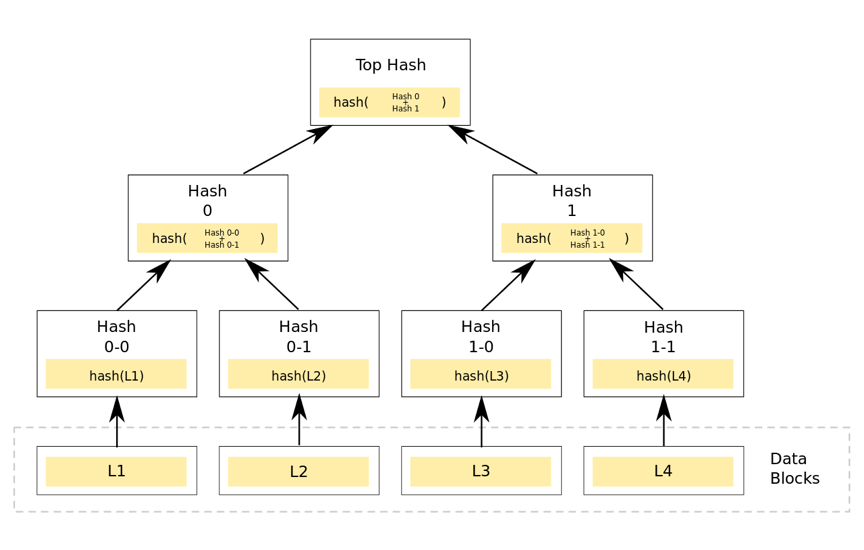
将相邻两个节点的哈希值合并成一个字符串,然后计算这个字符串的哈希,得到的就是这两个节点的父节点的哈希值。
如果该层的树节点个数是单数,那么对于最后剩下的树节点,这种情况就直接对它进行哈希运算,其父节点的哈希就是其哈希值的哈希值(对于单数个叶子节点,有着不同的处理方法,也可以采用复制最后一个叶子节点凑齐偶数个叶子节点的方式)。循环重复上述计算过程,最后计算得到最后一个节点的哈希值,将该节点的哈希值作为整棵树的哈希。
若两棵树的根哈希一致,则这两棵树的结构、节点的内容必然相同。
如上图所示,一棵有着4个叶子节点的树,计算代表整棵树的哈希需要经过7次计算,若采用将这四个叶子节点拼接成一个字符串进行计算,仅仅只需要一次哈希就可以实现,那么为什么要采用这种看似奇怪的方式呢?
优势:
- 快速重哈希
默克尔树的特点之一就是当树节点内容发生变化时,能够在前一次哈希计算的基础上,仅仅将被修改的树节点进行哈希重计算,便能得到一个新的根哈希用来代表整棵树的状态。
- 轻节点扩展
采用默克尔树,可以在公链环境下扩展一种“轻节点”。轻节点的特点是对于每个区块,仅仅需要存储约80个字节大小的区块头数据,而不存储交易列表,回执列表等数据。然而通过轻节点,可以实现在非信任的公链环境中验证某一笔交易是否被收录在区块链账本的功能。这使得像比特币,以太坊这样的区块链能够运行在个人PC,智能手机等拥有小存储容量的终端上。
劣势:
- 存储空间开销大
Patricia tree (帕特里夏树)
是一种改良的前缀树, 所以又叫压缩前缀树
在计算机科学中,Patricia trie/tree 是一种更节省空间的Trie(前缀树)。对于基数树的每个节点,如果该节点是唯一的子树的话,就和父节点合并
---- 维基百科
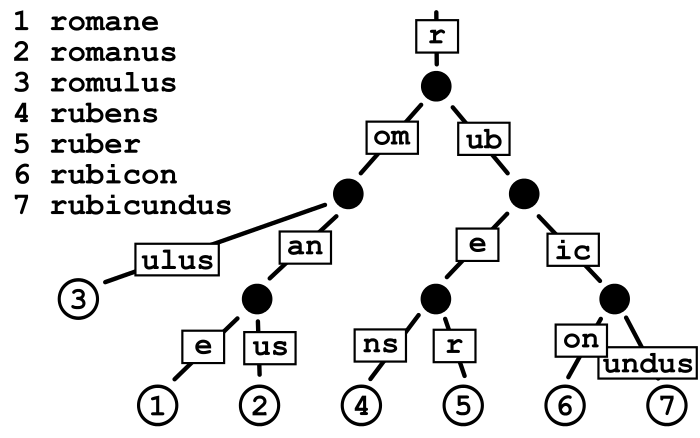
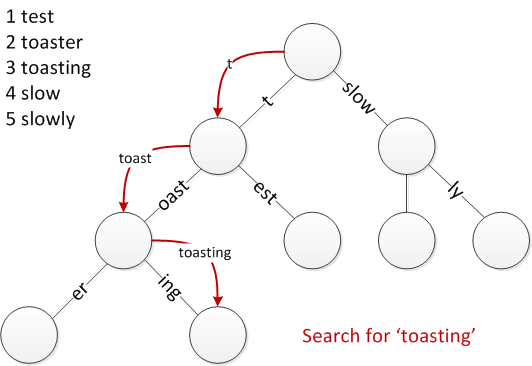
Patricia tree 的时间复杂度是 O(m) 下图是一次查找过程
以太坊经过整合将上面的两种数据结构取长补短,最终创造了 MPT 树。
MPT树
下面我们将详细地介绍MPT树这种结构设计,以及采用这种结构设计的用意,
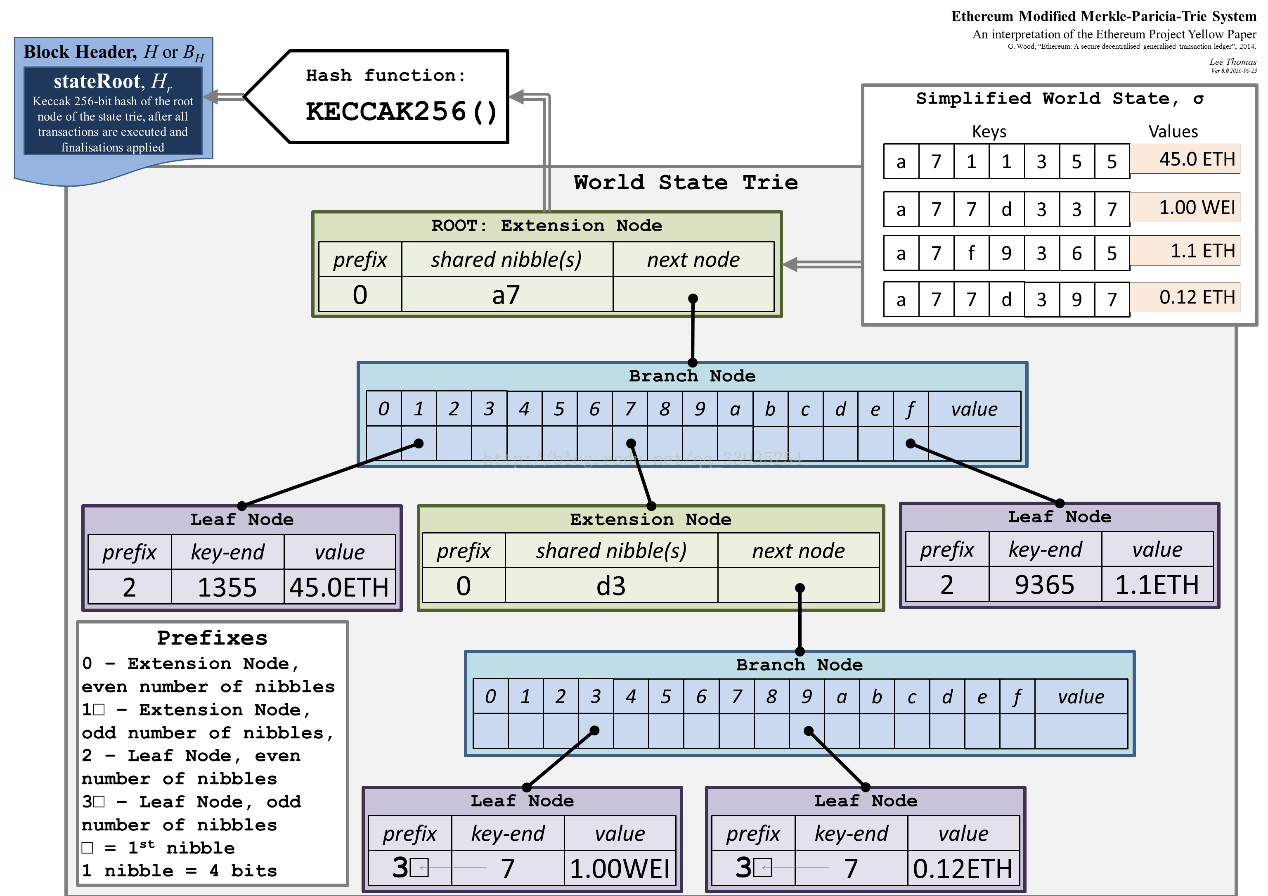
MPT 的节点按功能和存储的数据可以划分成 4 种类型:
- null (空节点):表示空字符串
- branch (分支节点):一个长度为 17 的数组 [ v0 … v15, vt ],也被称为分支节点
- leaf (叶子节点):一个长度为 2 的数组 [ encodedPath, value ]
- extension (扩展节点):一个长度为 2 的数组 [ encodedPath, key ],与 leaf 不同的是 key 是一个键,用于在数据库中寻值或者通过映射获取更复杂的数据
空节点
空节点用来表示空串分支节点
分支节点用来表示MPT树中所有拥有超过1个孩子节点以上的非叶子节点
type fullNode struct {
Children [17]node
flags nodeFlag
}
// nodeFlag contains caching-related metadata about a node.
type nodeFlag struct {
hash hashNode // cached hash of the node (may be nil)
gen uint16 // cache generation counter
dirty bool // whether the node has changes that must be written to the database
}叶子节点和扩展节点
type shortNode struct {
Key []byte
Val node
flags nodeFlag
}优化
MPT把key-value数据项的key编码在树的路径中,但是key的每一个字节值的范围太大[0-127]因此在以太坊中,在进行树操作之前,首先会进行一个key编码的转换,将一个字节的高低四位内容分拆成两个字节存储。通过编码转换,key'的每一位的值范围都在[0, 15]内。因此,一个分支节点的孩子至多只有16个。以太坊通过这种方式,减小了每个分支节点的容量,但是在一定程度上增加了树高。
一次插入过程为:
首先找到与新插入节点拥有最长相同路径前缀的节点,记为Node然后看下该节点的类型
- 若该Node为分支节点:
剩余的搜索路径不为空,则将新节点作为一个叶子节点插入到对应的孩子列表中.
剩余的搜索路径为空(完全匹配),则将新节点的内容存储在分支节点的第17个孩子节点项中(Value).
2. 若该节点为叶子/扩展节点:
剩余的搜索路径与当前节点的key一致,则把当前节点Val更新即可.
剩余的搜索路径与当前节点的key不完全一致,则将叶子/扩展节点的孩子节点替换成分支节点,将新节点与当前节点key的共同前缀作为当前节点的key,将新节点与当前节点的孩子节点作为两个孩子插入到分支节点的孩子列表中,同时当前节点转换成了一个扩展节点(若新节点与当前节点没有共同前缀,则直接用生成的分支节点替换当前节点).
一次删除过程为:
找到与需要插入的节点拥有最长相同路径前缀的节点,记为Node;
- 若Node为叶子/扩展节点:
若剩余的搜索路径与node的Key完全一致,则将整个node删除;
若剩余的搜索路径与node的key不匹配,则表示需要删除的节点不存于树中,删除失败;
若node的key是剩余搜索路径的前缀,则对该节点的Val做递归的删除调用;
2. 若Node为分支节点:
删除孩子列表中相应下标标志的节点;
删除结束,若Node的孩子个数只剩下一个,那么将分支节点替换成一个叶子/扩展节点;
若删除成功,则将被修改节点的dirty标志置为true,hash标志置空(之前的结果已经不可能用),且将节点的诞生标记更新为现在
时间复杂度分析
Trie树的时间复杂度是 O(m) (m 为字符串长度)
我们假设插入一个节点需要 1 个单位时间
增加一个分支节点的过程会将一个叶子节点拆分成一个分支节点和两个叶子节点,并将分支节点的索引当作value值存储起来
又因为所有的key都被转换成hex进制编码并作为树的路径
分支节点的概率会很高 (1 / 16)
插入一个分支节点的开销 -> 两个叶子节点的开销 2 + 分支节点1个字符的对应数组
时间消耗变成了跟树的高度有关系

插入节点的时间复杂度为
T(n) = 1 + 2 + 2^2 + 2^4 + 2^(n - 1) = ((1 + 2^n - 1) * n) / 2 = 2^n - 1
公式推算:
n = 1
S1 = 1 + 2 + 2^2 + 2^3 .... 2^k-1
S2 = 2 + 2^2 + 2^3 ..... 2^k-1 + 2^k
S2 - S1 = 2^k - 1
n = 2^k - 1
k = log(n)
MPT 时间复杂度 O(log(n))
实例
假设我们列举一个包含四个键值对的 trie
('do', 'verb'), ('dog', 'puppy'), ('doge', 'coin'), ('horse', 'stallion')
<64 6f> : 'verb'
<64 6f 67> : 'puppy'
<64 6f 67 65> : 'coin'
<68 6f 72 73 65> : 'stallion'
key为“do”, value为“verb”的数据项, 其Hex编码为 [6, 4, 6, f]
key为“dog”, value为“puppy”的数据项,其Hex编码为 [6, 4, 6, f, 6, 7]
key为“doge”, value为“coin”的数据项,其Hex编码为 [6, 4, 6, f, 6, 7, 6 , 5]
key为“horse”, value为“stallion”的数据项,其Hex编码为 [6, 4, 6, f, 7, 2, 7, 3, 6, 5]

总结
默克尔证明安全性
为什么不直接向全节点请求该节点是否存在于区块链中?
- 若全节点返回的是一条恶意的路径?试图为一个不存在于区块链中的节点伪造一条合法的merkle路径,使得最终的计算结果与区块头中的默克尔根哈希相同由于哈希的计算具有不可预测性,使得一个恶意的“全”节点想要为一条不存在的节点伪造一条“伪路径”使得最终计算的根哈希与轻节点所维护的根哈希相同是不可能的
- 由于在公链的环境中,无法判断请求的全节点是否为恶意节点,因此直接向某一个或者多个全节点请求得到的结果是无法得到保证的。但是轻节点本地维护的区块头信息,是经过工作量证明验证的,也就是经过共识一定正确的,若利用全节点提供的默克尔路径,与代验证的节点进行哈希计算,若最终结果与本地维护的区块头中根哈希一致,则能够证明该节点一定存在于默克尔树中
简单支付验证
在以太坊中,利用默克尔证明在轻节点中实现简单支付验证,即在无需维护具体交易信息的前提下,证明某一笔交易是否存在于区块链中
那么就需要这样一种数据结构,它能在一次插入、更新、删除操作后快速计算到树根,而不需要重新计算整棵树的 hash。 这种数据结构同样得包括两个非常好的第二特征:
树的深度是有限制的,不然,攻击者可以通过操纵树的深度,或者执行拒绝服务攻击(DOS attack),使得区块更新变得极其缓慢。
roothash 只取决于数据,和其中的更新顺序无关。换个顺序进行更新,甚至从头开始重新计算整棵树也不会改变根的值。
显然,Trie 是最接近同时满足上面的性质的的数据结构,而为了能够更高效地运作,MPT 便是最佳的数据结构。
通过这个分享我的一点领悟:
- 如何通过需求去选择一种数据结构, 并学会简单的分析一种数据结构的时间复杂度
- 需要查找,需要减少时间复杂度,应该想到什么 ---- 散列表
- 如果某个表达式计算开销比较大,有需要频繁的使用怎么办? ----- 预处理,并缓存
ASCII字符和数值有256个(2^8),每个ASCII字符编码用8个byte,是单字节,在ASCII里,数值0到127范围通用所有的计算机,而从128到255,各类计算机的安排有所不同
参考文献
