

Kafka 入门
Kafka 是什么
Kafka 是分布式的流处理平台。
Kafka 主要的应用场景大体分为两类:
- 在多个应用之间构建一条实时流式数据管道
- 构建用于响应或修改流数据的应用
Kafka 中的几个概念
-
Topic
Kafka 中给流记录是按分类来存储的,每个分类就是一个 Topic -
Broker
消息中间件处理节点,一个 Kafka 节点就是一个 Broker,一个或者多个 Broker 可以组成一个 Kafka 集群,一般情况下 Kafka 都是已集群方式运行的,由 Zookeeper 来管理每个节点 -
Producer
数据生产者 它的职责是选择分配记录给哪个 Topic 的哪个 Partition,一般采用的策略是轮训,也可以根据记录的 key 进行自定义配置 -
Consumer
数据消费者
每个消费者保留的唯一元数据是该消费者在日志中的 offset 或 position,消费者可以以任意顺序来处理记录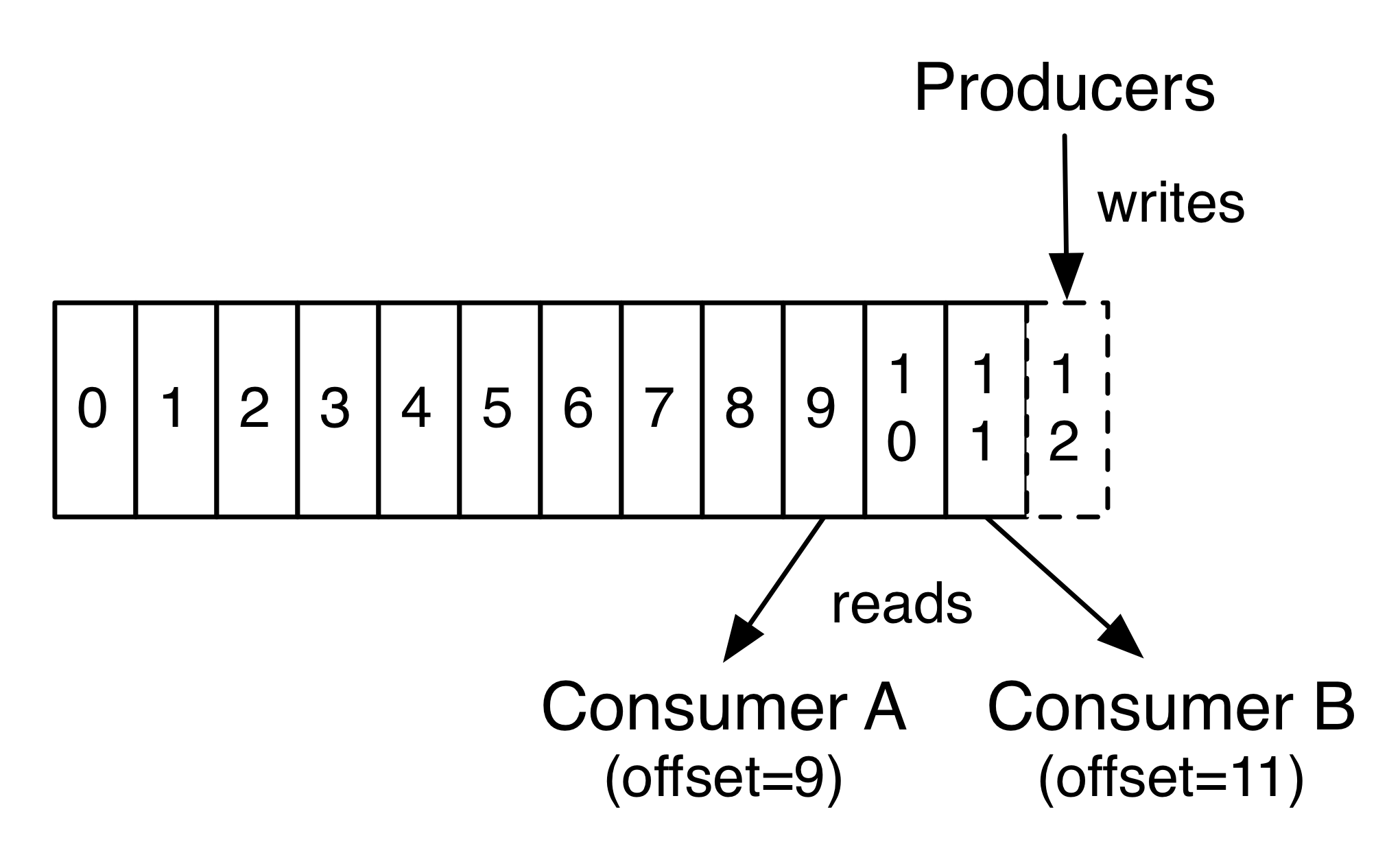
消费者默认都会有一个消费者组,消费者组中的消费者可以使用在多个进程中或者多个机器中,发布到一个 Topic 的记录会被发送到每个消费者组内的其中一个消费者,也就是说一个消费者组实际上算是一个订阅者,内部的消费者有统一的 offset。
消费者组保证了消费者的容错性,每个新的组员加入都会接手同组内其他成员的部分 Partition 日志,当一个消费者挂掉后,同组内的其他消费者可以代替它来继续工作。 -
Partition
物理上的概念,一个 Topic 可以分为多个 Partition,每个 Partition 内部是有序的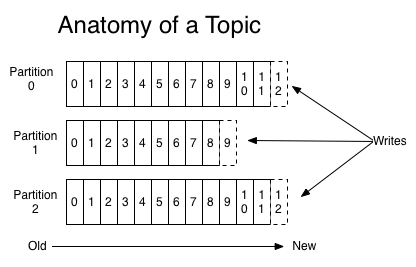
每条记录都会分配一个顺序增长的 id 数字被称为 offset,这个数字在每个 Partition 内是唯一的
Partition 的作用有两个。首先,它们允许日志扩展到超出单个服务器所能容纳的大小。每个单独的分区都必须适合承载它的服务器,但是一个主题可能有很多分区,因此它可以处理任意数量的数据。 其次,它们当做并行单元来处理。
给出一组 Kafka 集群运行案例
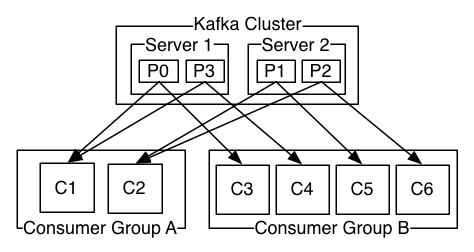
案例中一个集群中有两个 Broker,每个 Broker 有两个 Partition,有两个消费者组,消费者组 A 有两个消费者,消费者组 B 有 4 个消费者。每个 Broker 产生的消息由一组消费者中的一个消费者消费。
快速上手
- 下载 Kafka 2.4.1 并解压,我选择解压到 /usr/local/ 下
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.1/kafka_2.12-2.4.1.tgz
tar -xzf kafka_2.12-2.4.1.tgz -C /usr/local
cd /usr/local/kafka_2.12-2.4.1
- 开启 Zookeeper 服务,Kafka 依赖 Zookeeper 来管理节点,为了方便我们上手,官方提供了一个启动单节点 Zookeeper 实例的脚本,我们直接使用就好了,当然生产环境不会这样。
bin/zookeeper-server-start.sh config/zookeeper.properties
- 开启一个 Kafka 服务
bin/kafka-server-start.sh config/server.properties
- 创建一个 Topic
发布的消息存储在 localhost:9092 这个服务上,也就是我们刚才启动的 Kafka 服务,端口信息可以在 config/server.properties 中看到 --replication-factor 1 冗余份数一份(容错用)
--partitions 1 分区个数一个
--topic test 主题名称 test
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
- 发送消息
启动一个生产者,向 test 生产消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
- 消费消息
启动一个消费者,从头开始消费 test 的消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
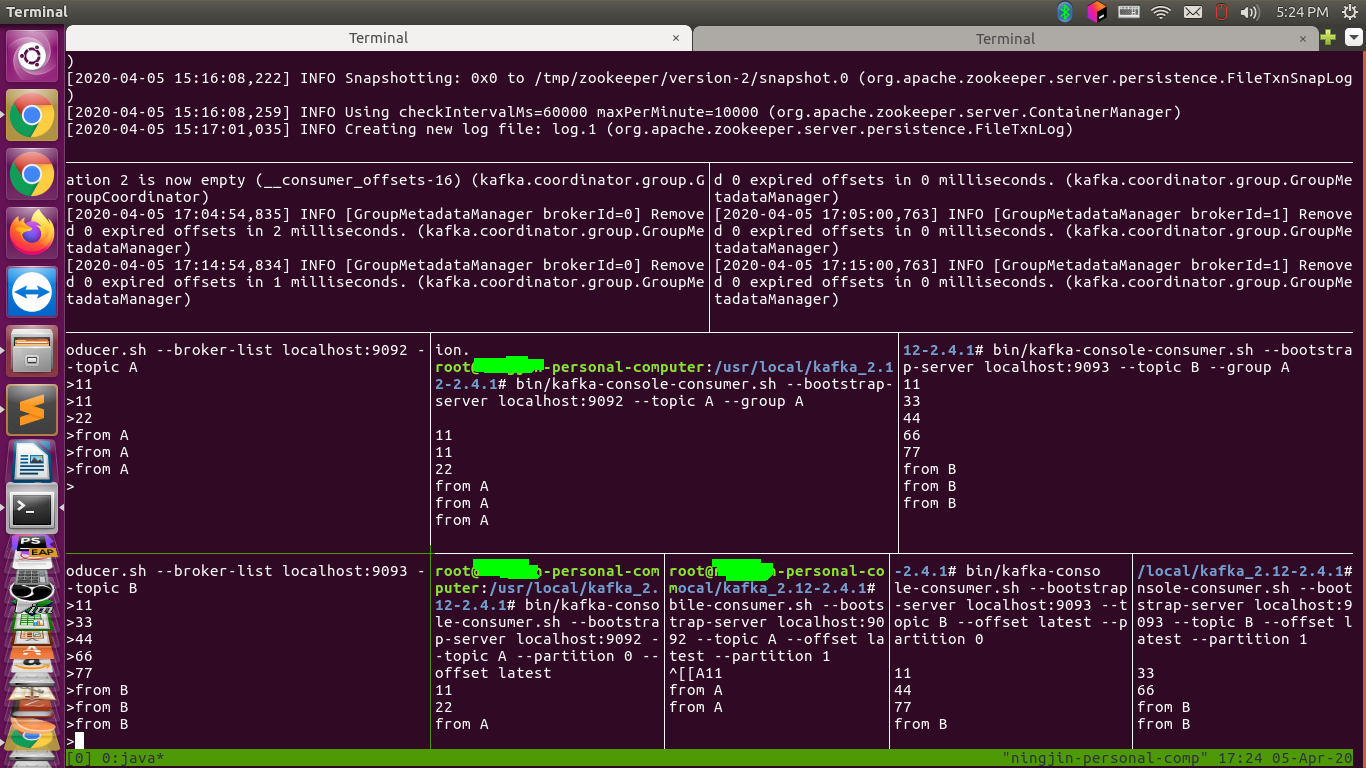
下面是我的实验截图
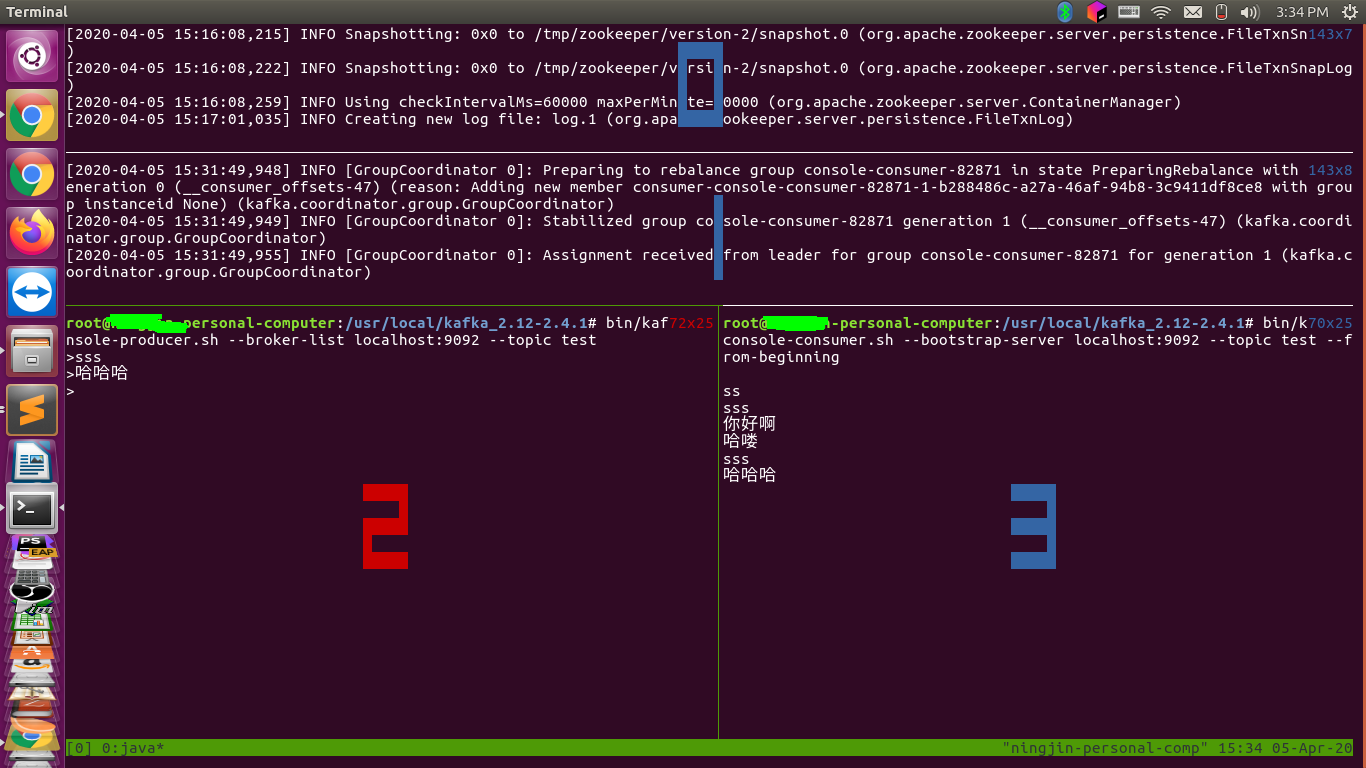
0 是 zookeeper,1 是 Kafka 节点,2 是生产者,3 是消费者
集群搭建
接下来我们以上面给的集群示例图搭建一个 Kafka 集群,这里把图再贴一遍
我们先搭建 Broker 集群,复制一份 config/server.properties 改名为 config/server-1.properties
cp config/server.properties config/server-1.properties
修改 config/server-1.properties 中的参数
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
先启动 Zookeeper 服务,这里再贴一遍
bin/zookeeper-server-start.sh config/zookeeper.properties
然后启动 server 和 server-1
bin/kafka-server-start.sh config/server.properties
bin/kafka-server-start.sh config/server-1.properties
然后在 server 上创建一个有两个 Partition 的 Topic A,在 server-1 上创建一个有两个 Partition 的 Topic B
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic A
bin/kafka-topics.sh --create --bootstrap-server localhost:9093 --replication-factor 1 --partitions 2 --topic B
然后启动两个生产者,分别向 A B 生产数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic A
bin/kafka-console-producer.sh --broker-list localhost:9093 --topic B
启动两个消费者集组,一个消费者组 A 有两个消费者,一个消费者组 B 有四个消费者
消费者组 A
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic A --group A
bin/kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic B --group A
消费者组 B
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic A --offset latest --partition 0
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic A --offset latest --partition 1
bin/kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic B --offset latest --partition 0
bin/kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic B --offset latest --partition 1
消费者组 B 有些问题,因为官方不允许 group 参数和 partition 参数同时存在,所以没有给 B 组的消费者指定组 id,但是可以把它们理解为一个逻辑上的组。
以下是我的实验截图
最后安利下,tmux 真的挺好用的。
