

你好,我是悦创。
博客文章:www.aiyc.top/archives/24…
实战项目一:爬取西刺代理(获取代理IP)
爬虫的学习就是与反扒措施、反扒系统做斗争的一个过程,而使用代理 IP 是我们重要的防反扒的重要措施,代理 IP 的来源有两种。 一是:你花钱去购买商家会给你提供一个接口你直接调用就可以了,二是:自己在网上爬取高效IP。在这篇博客中我重点给大家讲一下如何从网上获取高效IP,我们下面的IP来源于西刺代理,这是我很久之前写的一篇博客,今天来进行“翻新”一番希望可以帮助到大家。
1. 安装必要的第三方库
BeautifulSoup 和 requests,BeautifulSoup 负责解析 HTML 网页源码,requests 负责发送请求来获取网页源码,BeautifulSoup 和 requests 均属于 Python 爬虫的基础库,可以通过pip安装。打开命令行输入命令 pip install BeautifulSoup4 和 pip install requests 进行安装:
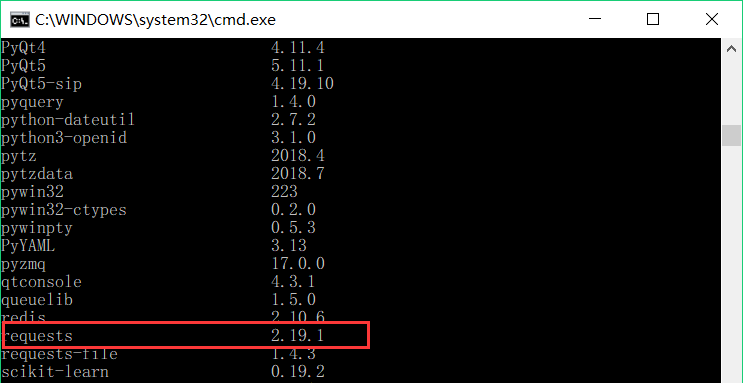
pip list 在 pip 安装包列表中检查 BeautifulSoup 和 requests 库是否安装成功。
2. 分析网页结构
待续。。。。
3. 完整代码
#IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/
from bs4 import BeautifulSoup
import requests,random
def get_ipInfors(url, headers):
'''
爬取IP数据,单个IP信息以json格式存储,所有json格式的IP数据信息放入列表中
return:ip_infor
'''
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
nodes = soup.find_all('tr')
for node in nodes[1:]:
ip_ = node.find_all('td')
ip_address = ip_[1].text
ip_port = ip_[2].text
ip_type = ip_[5].text
ip_time = ip_[8].text
ip_infors = {
"ip_address" : ip_address,
"ip_port" : ip_port,
"ip_type" : ip_type,
"ip_time" : ip_time
}
return ip_infors
def write_ipInfors(ip_infors):
'''
将IP数据写入文件中
'''
for ip_infor in ip_infors:
f=open('IP.txt','a+',encoding='utf-8')
f.write(ip_infors)
f.write('\n')
f.close()
if __name__ == '__main__':
for i in range(1,10):
url = 'https://www.xicidaili.com/nn/{}'.format(i)
headers = {
'Host': 'www.xicidaili.com',
'Referer': 'https://www.xicidaili.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
ip_infors = get_ipInfors(url, headers=headers)
proxies = write_ipInfors(ip_infors)
实战项目二:实现CSDN自动点赞
环境: Python3.6.5 编译器: Sublime Text 3 代码: GitHub 第三方库: selenium
文章目录
一、思路 二、代码实现 (一)导入第三方库 (二)登录账号 (三)保存cookies到文件中 (四)读取并传入cookies (五)实现自动点赞 三、完整代码 四、后记
一、思路 在CSDN中,如果实现自动点赞,就必须登录,这就避免不了和 selenium 打交道。Selenium 是一个WEB自动化测试工具,在Python中常用于模拟登陆的实现 实现 CSDN 自动点赞分以下几个步骤:
- 登录账号
- 获取并储存 cookies
- 读取并传入 cookies
- 实现自动点赞
二、代码实现
(一)导入第三方库
对于 selenium 还没安装的童鞋可以用在命令行中安装
pip install selenium
import time,json,random
from selenium import webdriver
(二)登录账号
在 selenium 安装完成后,需要下一个驱动器(即 chromedriver.exe) 【谷歌驱动器下载】
而后运行代码
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get("https://passport.csdn.net/account/login")
可以看到弹出 CSDN 的登录界面
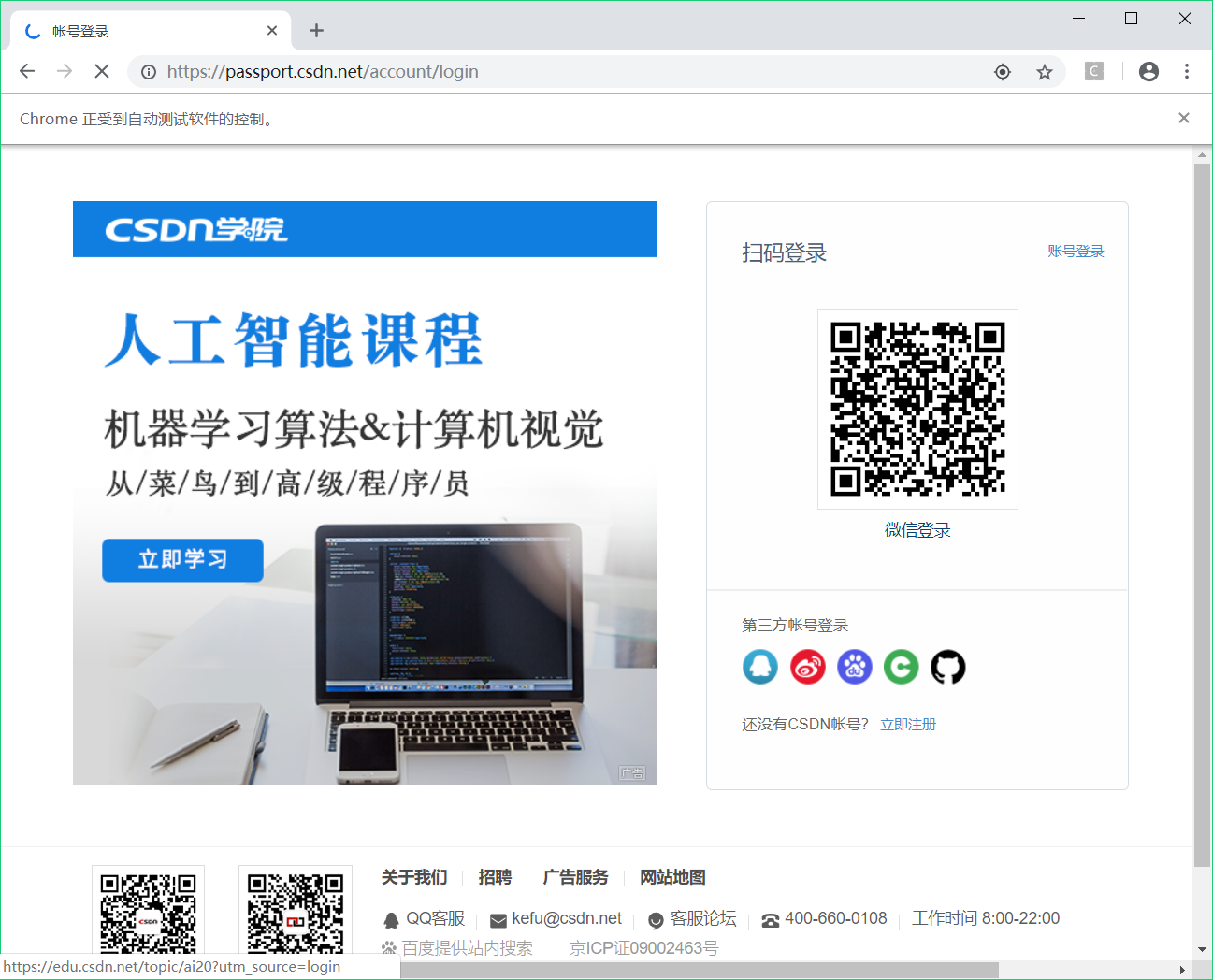
我们这里采用的是账号密码登录方式,我们再来做一个切换,点击“账号登录”
time.sleep(3)
#进入账号密码登录界面
driver.find_element_by_xpath("//a[@class='login-code__open js_login_trigger login-user__active']").click()
time.sleep(3)
看到如下界面
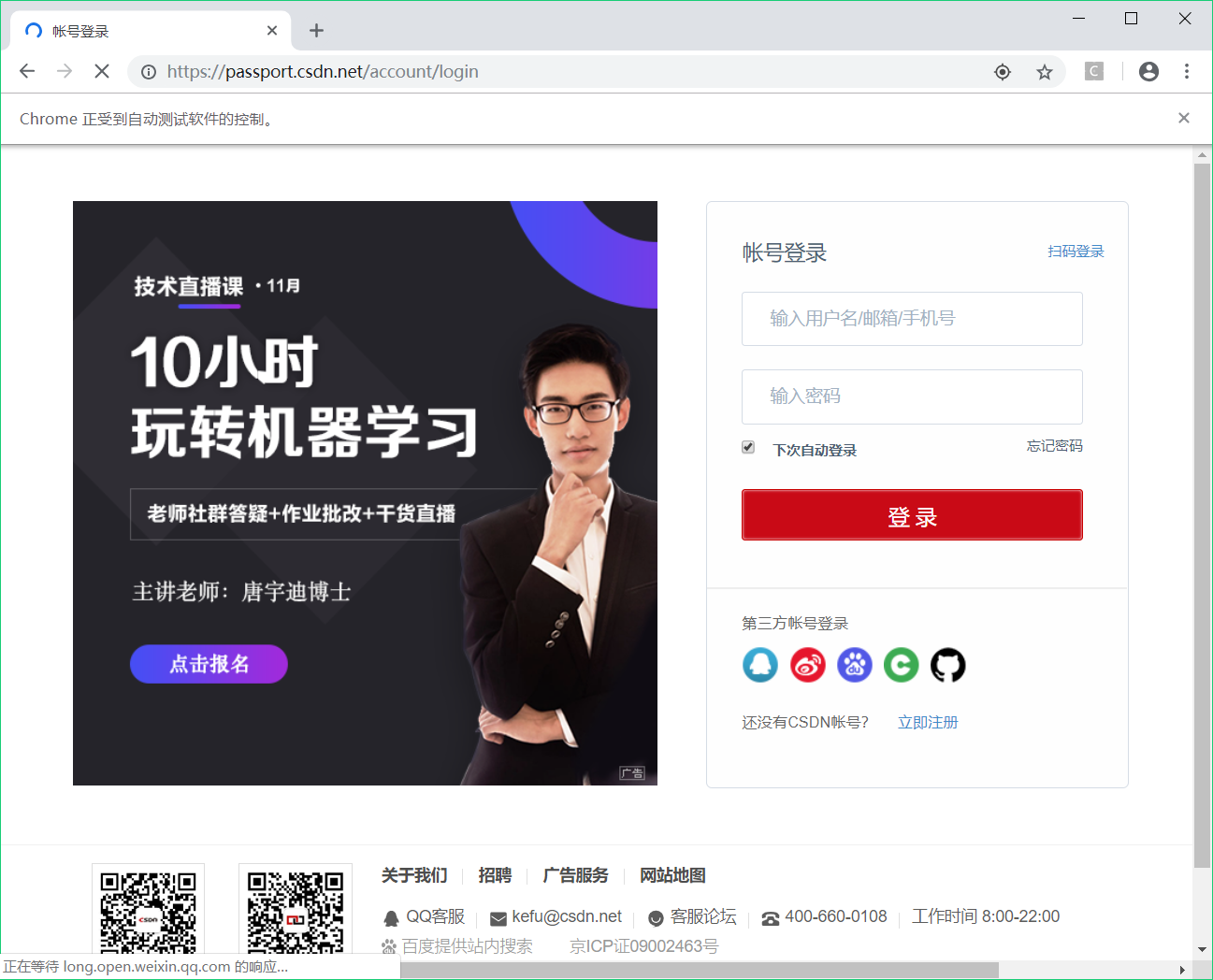
最后我们清空账号密码框,将自己的 CSDN 账号密码输入进去即可
#清空账号框中的内容
driver.find_element_by_xpath("//input[@name='username']").clear()
print("账号框清空完成")
#自动填入登录用户名
driver.find_element_by_xpath("//form[@id='fm1']/input[@name='username']").send_keys(account_CSDN)
print("账号输入完成")
#清空密码框中的内容
driver.find_element_by_xpath("//input[@name='password']").clear()
#自动填入登录密码
driver.find_element_by_xpath("//input[@name='password']").send_keys(password_CSDN)
time.sleep(3)
#点击登录
driver.find_element_by_xpath("//input[@class='logging']").click()
大家可能也注意到了我代码上用了很多time.sleep()进行休眠,这个是为了给服务器一个反应时间。拿输入账号密码后的登录操作来举例,如果你在输入账号密码后立即登录,系统会报出账号密码错误的提起,这个是由于我们代码输入账号密码的速度太快了,服务器还没接收到你输入的信息,代码就已经登录操作了,它自然会给你报错。当然人工输入是不会遇到这个问题的,你速度没那么快嘛。
(三)保存cookies到文件中
在介绍下面的内容前,我先来介绍几个知识点
- json.loads() 是将str转化成dict格式
- json.dumps() 是将dict转化成str格式。
- json.dump(dict,fp) 把 dict 转换成str类型存到fp指向的文件里。
- json.load(fp) 把 fp 指向的文件里的内容读取出来。
#获取并保存cookies
cookies = driver.get_cookies()
with open("cookies.txt", "w") as fp:
json.dump(cookies, fp)
(四)读取并传入cookies
这里我么将事先存入cookies.txt文件中的cookies提取出来加载进去即可。这里我补充一些webdriver中提供了操作cookie的相关方法:
- get_cookies() 获得 cookie 信息
- add_cookie(cookie_dict) 添加 cookie
- delete_cookie(name) 删除特定(部分)的cookie
- delete_all_cookies() 删除所有的cookie
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get("https://blog.csdn.net/qq_38251616/article/details/82963395")
with open("cookies.txt", "r") as fp:
cookies = json.load(fp)
for cookie in cookies:
driver.add_cookie(cookie)
(五)实现自动点赞
driver.get("https://blog.csdn.net/qq_38251616/article/details/82963395")
time.sleep(3)
driver.find_element_by_xpath("//button[@class=' low-height hover-box btn-like ']").click()
print("点赞完成!")
time.sleep(3)
完。。。。
三、完整代码
#CSDN自动点赞
import time,json,random
from selenium import webdriver
#CSDN账号
account_CSDN = "你的账号"
#CSDN密码
password_CSDN = "你的密码"
def CSDN_login():
'''
登录CSDN并保存cookies
'''
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get("https://passport.csdn.net/account/login")
time.sleep(3)
#进入账号密码登录界面
driver.find_element_by_xpath("//a[@class='login-code__open js_login_trigger login-user__active']").click()
time.sleep(3)
#清空账号框中的内容
driver.find_element_by_xpath("//input[@name='username']").clear()
print("账号框清空完成")
#自动填入登录用户名
driver.find_element_by_xpath("//form[@id='fm1']/input[@name='username']").send_keys(account_CSDN)
print("账号输入完成")
#清空密码框中的内容
driver.find_element_by_xpath("//input[@name='password']").clear()
#自动填入登录密码
driver.find_element_by_xpath("//input[@name='password']").send_keys(password_CSDN)
time.sleep(3)
#点击登录
driver.find_element_by_xpath("//input[@class='logging']").click()
#获取并保存cookies
cookies = driver.get_cookies()
with open("cookies.txt", "w") as fp:
json.dump(cookies, fp)
def dianZan(url_list):
'''
实现自动点赞功能
'''
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get("https://blog.csdn.net/qq_38251616/article/details/82963395")
with open("cookies.txt", "r") as fp:
cookies = json.load(fp)
for cookie in cookies:
driver.add_cookie(cookie)
print("cookies加载完成,成功登录")
time.sleep(3)
driver.get("https://blog.csdn.net/qq_38251616/article/details/82963395")
time.sleep(3)
driver.find_element_by_xpath("//button[@class=' low-height hover-box btn-like ']").click()
print("点赞完成!")
time.sleep(3)
if __name__ == '__main__':
url_list = ""
CSDN_login()
dianZan(url_list)
四、后记
如果觉得我写得可以点个赞呗;如果有什么不足的地方,还你希望可以在下方留言告诉我。
实战项目三:爬取QQ群中的人员信息
文章目录
一、selenium简介 (一)实例说明 (二)元素定位方式 (三)实现滚动条自动下拉 二、Xpath简介 (一)语法: (二)实例: 三、定义一个爬虫类 (一)导入包 (二)初始化类 (三)滚动条自动下拉 (四)获取Tbody标签的列表 (五)解析Tbody标签 (六)提取Tbody标签中每个群员的信息 (七)将提取到群员的信息写入文件 四、主函数
一、selenium简介
我们模拟登陆用的是 selenium 库,selenium 是一个自动化测试工具,在爬虫中通常用来进行模拟登陆。
(一)实例说明
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
代码功能:
- 打开谷歌浏览器,
- 自动输入百度网址并打开百度
如果程序执行错误,浏览器没有打开,那么应该是没有装 Chrome 浏览器或者 Chrome 驱动没有配置在环境变量里。下载驱动,然后将驱动文件路径配置在环境变量即可。 谷歌浏览器驱动下载
(二)元素定位方式
单个元素选取:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
多个元素选取:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
代码示例:
#获取网页中的h1标签
h1 = driver.find_element_by_name("h1")
#获取网页中所有的h1标签
h1_list = driver.find_elements_by_name("h1")
(三)实现滚动条自动下拉
代码展示:
#将滚动条移动到页面的底部
js="var q=document.documentElement.scrollTop=100000"
driver.execute_script(js)
二、Xpath简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。结构关系包括 父、子、兄弟、先辈、后代等。
(一)语法:
| 表达式 | 功能描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
(二)实例:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
更多语法知识参考:Xpath实现信息提取
代码实例:
#获取 class 为 bold 的标签名
result = html.xpath('//*[@class="bold"]')
三、定义一个爬虫类
(一)导入包
import time
from selenium import webdriver
(二)初始化类
class qqGroupSpider():
'''
Q群爬虫类
'''
def __init__(self, driver,qq,passwd,qqgroup):
'''
初始化根据用户信息登录到Q群管理界面
:param driver:
:param qq:
:param passwd:
:param qqgroup:
:param writefile:
'''
url = "https://qun.qq.com/member.html#gid={}".format(qqgroup)
self.driver=driver
driver.delete_all_cookies()
driver.get(url)
time.sleep(1)
driver.switch_to.frame("login_frame") # 进入登录iframe
time.sleep(1)
change = driver.find_element_by_id("switcher_plogin")
change.click()
driver.find_element_by_id('u').clear() # 选择用户名框
driver.find_element_by_id('u').send_keys(qq)
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys(passwd)
driver.find_element_by_class_name("login_button").click()
time.sleep(1)
(三)滚动条自动下拉
def scroll_foot(self,driver):
'''
控制屏幕向下滚动到底部
:param driver:
:return:
'''
js = "var q=document.documentElement.scrollTop=100000"
return driver.execute_script(js)
(四)获取Tbody标签的列表
def getTbodyList(self, driver):
print("getTbodyList()函数运行过")
return driver.find_elements_by_xpath('//div[@class="group-memeber"]//tbody[contains(@class,"list")]')
(五)解析Tbody标签
def parseTbody(self, html):
'''
解析tbody里面的内容,一个tbody里面有多个成员,
解析完成后,返回成员基本情况的列表
:param html:
:return:
'''
# selector = etree.HTML(html)
print("parseTbody()函数运行过")
memberLists = []
for each in html:
memberList = each.find_elements_by_xpath('tr[contains(@class,"mb mb")]')
memberLists += memberList
print("memberLists长度为:{}".format(len(memberLists)))
memberLists_data = []
for each in memberLists:
memberLists_data.append(self.parseMember(each))
return memberLists_data
(六)提取Tbody标签中每个群员的信息
def parseMember(self, mb):
'''
解析每个人各项描述,以逗号隔开,返回一个成员的基本情况
:param mb:
:return:
'''
print("parseMember()函数运行过")
td = mb.find_elements_by_xpath('td')
print("td长度为:{}".format(len(td)))
qId = td[1].text.strip()
nickName = td[2].find_element_by_xpath('span').text.strip()
card = td[3].find_element_by_xpath('span').text.strip()
qq = td[4].text.strip()
sex = td[5].text.strip()
qqAge = td[6].text.strip()
joinTime = td[7].text.strip()
lastTime = td[8].text.strip()
a = (qId + "|" + qq + "|" + nickName + "|" + card + "|" + sex + "|" + qqAge + "|" + joinTime + "|" + lastTime)
print(a)
return a
(七)将提取到群员的信息写入文件
def parseAndWrite(self, tbody):
'''
解析HTML中的tbody,解析完成后写入到本地文件
:param tbody:
:return:
'''
print("parseAndWrite()函数运行过")
memberList = self.parseTbody(tbody)
with open("1607.csv", 'a+', encoding="utf-8") as f:
for each in memberList:
f.write(str(each)+"\n")
四、主函数
def main():
qq = "你的QQ账号"
passwd = "你的QQ密码"
qqgroup = "想要爬取的QQ群群号"
driver = webdriver.Chrome()
spider=qqGroupSpider(driver,qq,passwd,qqgroup)
time.sleep(10)
# 找到QQ群的人数
qqNum = int(driver.find_element_by_xpath('//*[@id="groupMemberNum"]').text.strip())
print("QQ群人数为:"+str(qqNum))
curren_qq_num=0
prelen=0
while curren_qq_num != qqNum:
curren_qq_num=len(driver.find_elements_by_xpath('//*[@id="groupMember"]//td[contains(@class,"td-no")]'))
#不停的向下滚动屏幕,直到底部
spider.scroll_foot(driver)
#每次滚动休息1秒
time.sleep(1)
tlist = spider.getTbodyList(driver)
spider.parseAndWrite(tlist[prelen:])
prelen = len(tlist)#更新tbody列表的长度
driver.quit()
if __name__ == '__main__':
main()
实战项目四:爬取911网站
这是我在某个项目写的一份爬虫代码,今天将它整理一下分享给大家,仅供参考学习,请勿用作其他用途。
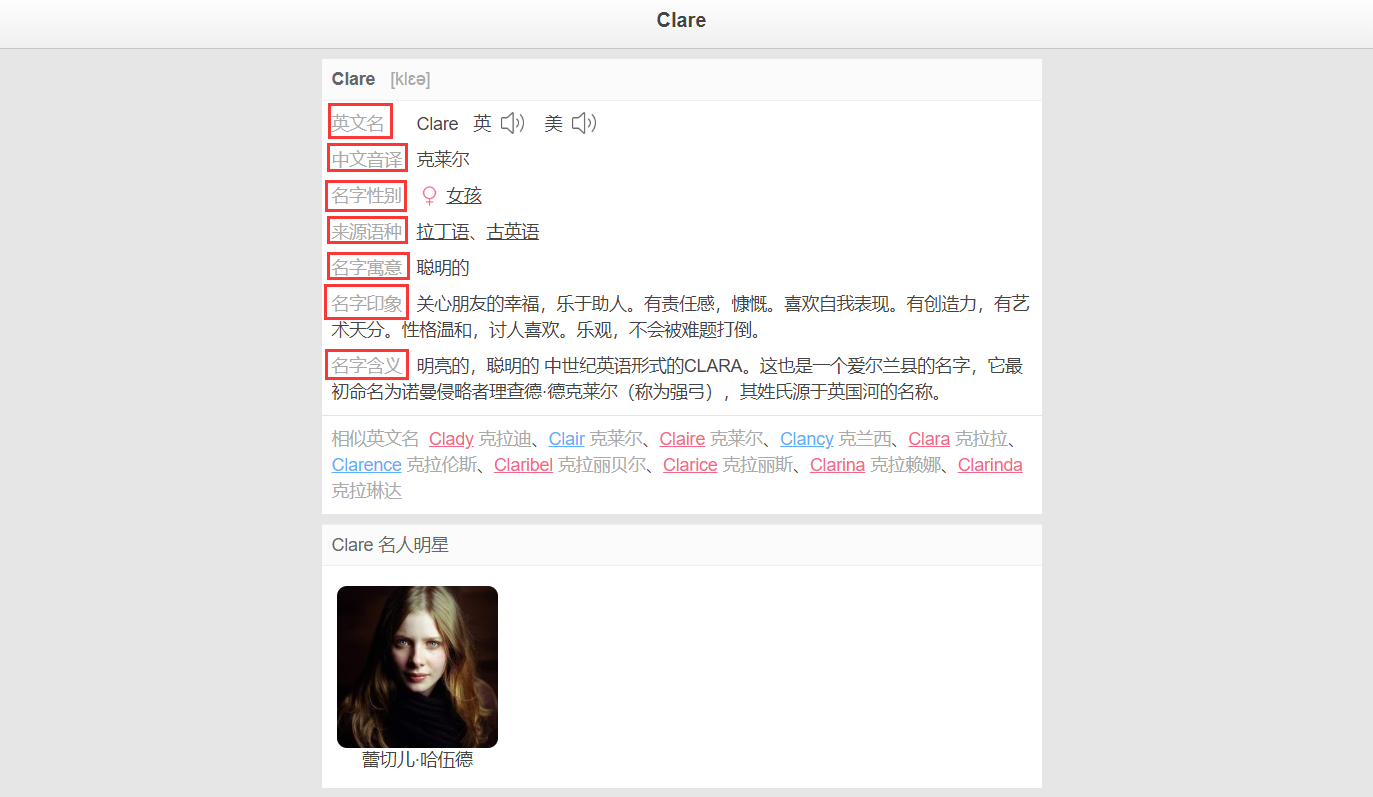
需要爬取的东西
我爬取的是 myingwenming.911cha.com 网站,采集的是网站中的中文音译、名字性别、来源语种、名字寓意、名字印象、名字含义6个数据。我分别设置 namesChineseTransliteration、namesGender、namesFromLanguage、namesMoral、namesImpression、namesMeaning 等6个字段来存放相应的数据。
防反扒措施
在这防反扒这一块我选择每发送一次 requests 请求更换一个 User-Agent 与 IP 。User-Agent 的更换我依靠第三方库 fake_useragent 来完成,在每次发送 requests 请求前通过 {'User-Agent':str(UserAgent().random)} 语句来获取一个随机 User-Agent。关于 代理 IP 这块我则是事先准备好IP存放到 IP.txt 文件中,每一次发送 requests 前从该文件中随机获取一个IP 用于本次请求。
def get_ip_list():
'''
读取IP.txt中的数据
'''
f=open('IP.txt','r')
ip_list=f.readlines()
f.close()
return ip_list
def get_random_ip(ip_list):
'''
从IP列表中获取随机IP
'''
proxy_ip = random.choice(ip_list)
proxy_ip=proxy_ip.strip('\n')
proxies = {'http': proxy_ip}
return proxies
关于 requests 请求 我这里的requests请求供包含url、proxies、headers、timeout、verify五个参数,在每一次发送请求前更换新的proxies,headers并在超时处理,若请求时间超过10秒则中断本次请求,设置verify=False则会忽略对网页证书的验证。
在我遇到的反扒系统中有这样一种,拿出来和大家分享。对方识别到你的爬虫在网站上爬行时,不会阻止它的爬取行为而是让其陷入一种死循环转态,表现的形式是:本报错同时也不会返回任何数据。在 requests 请求中加上一个超时设置就可以很好避开该反扒措施。
关于网页解析
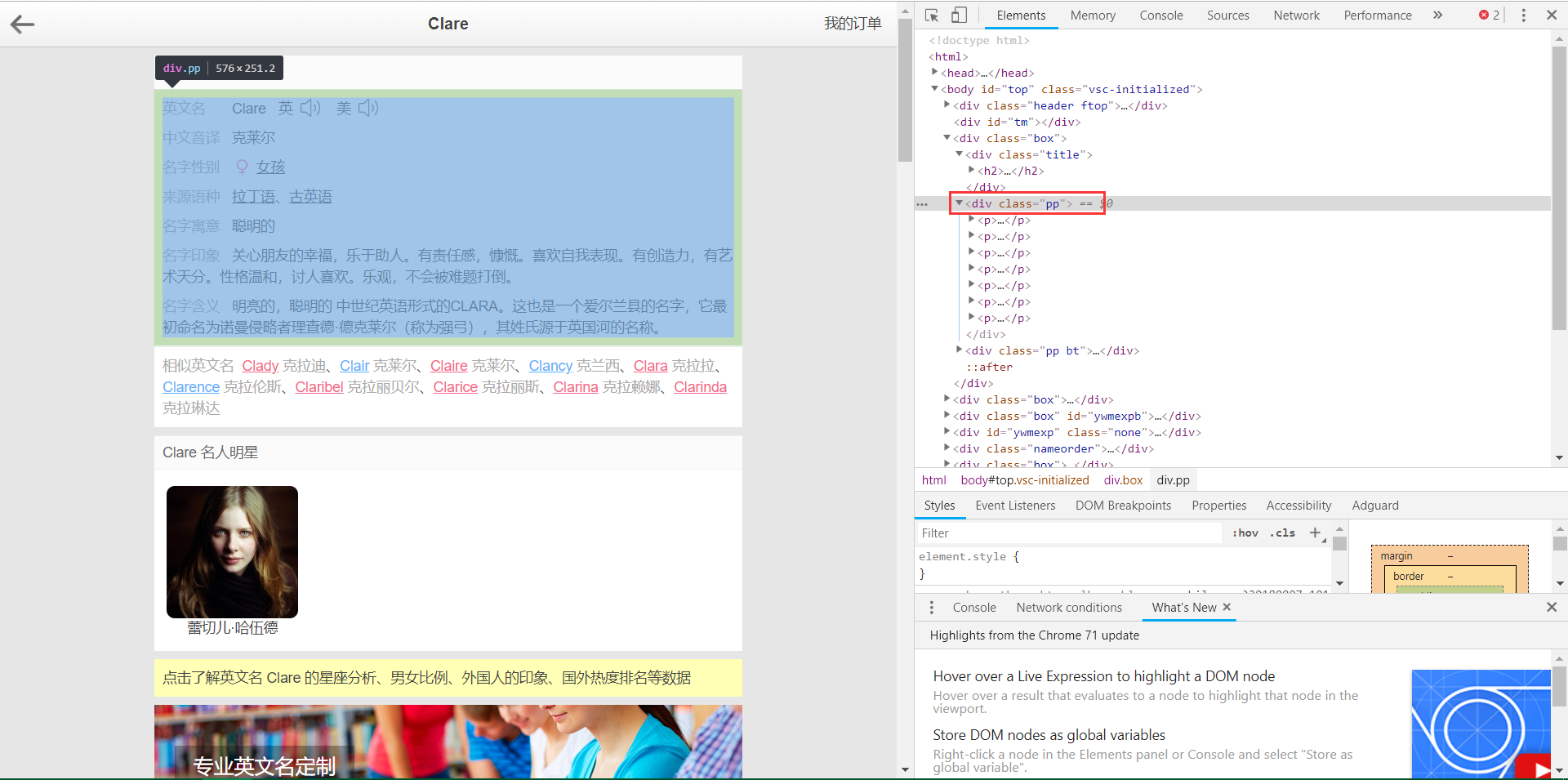
在网页解析这块我选择的是 Python 解析库 BeautifulSoup4 与解析器 lxml ,在定位方面我选择的是 find() 与 find_all(),find() 返回的是单个结点,find_all() 返回结点列表,在提取文本信息中我这里使用的是 get_text() 。
首先定位到 <div class="pp"> ,其次是 div 下的 p 标签,最后分别存入对应的字段当中。
soup = BeautifulSoup(r.text, 'lxml')
body = soup.find("div", class_="pp")
contents = body.find_all('p')
完整代码
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import pandas as pd
import requests,csv,time,random
def get_ip_list():
'''
读取IP.txt中的数据
'''
f=open('IP.txt','r')
ip_list=f.readlines()
f.close()
return ip_list
def get_random_ip(ip_list):
'''
从IP列表中获取随机IP
'''
proxy_ip = random.choice(ip_list)
proxy_ip=proxy_ip.strip('\n')
proxies = {'http': proxy_ip}
return proxies
def parsePage(url,ip_list):
'''
爬取网页并返回所需信息以及状态码
'''
headers= {'User-Agent':str(UserAgent().random)}
proxies = get_random_ip(ip_list)
try:
#verify设置为False,Requests也能忽略对SSL证书的验证。
r = requests.get(url, proxies=proxies, headers=headers, timeout=10,verify=False)
except:
print('运行错误,程序暂停20秒')
time.sleep(20)
headers= {'User-Agent':str(UserAgent().random)}
proxies = get_random_ip(ip_list)
r = requests.get(url, proxies=proxies, headers=headers, timeout=10, verify=False)
#状态码status_code为200代表爬取成功,为404则为未爬取到相关信息
if r.status_code == 200:
soup = BeautifulSoup(r.text, 'lxml')
body = soup.find("div", class_="pp")
contents = body.find_all('p')
return r.status_code, contents
else:
return r.status_code, None
def getDict(contents):
namesChineseTransliteration = [] #中文音译
namesGender = [] #名字性别
namesFromLanguage = [] #来源语种
namesMoral = [] #名字寓意
namesImpression = [] #名字印象
namesMeaning = [] #名字含义
namesChineseTransliteration.append(contents[1].get_text()[4:])
namesGender.append(contents[-5].get_text()[4:])
namesFromLanguage.append(contents[-4].get_text()[4:])
namesMoral.append(contents[-3].get_text()[4:])
namesImpression.append(contents[-2].get_text()[4:])
namesMeaning.append(contents[-1].get_text()[4:])
str_row=namesChineseTransliteration+namesGender+namesFromLanguage+namesMoral+namesImpression+namesMeaning
return str_row
def write_file(filePath, row):
with open(filePath,'a+',encoding='utf-8',newline='') as csvfile:
spanreader = csv.writer(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
spanreader.writerow(row)
if __name__ == "__main__":
names = pd.read_csv("name_data.csv")['name'] #获取需要爬取文件的名字
base_url = "https://myingwenming.911cha.com/"
ip_list = get_ip_list()
for name in names:
url = base_url + name + ".html"
status_code, contents = parsePage(url,ip_list)
print("{}检索完成".format(name), "状态码为:{}".format(status_code))
#状态码为200爬取成功,状态码为404爬取失败
if status_code == 200:
str_row = getDict(contents)
row = ["{}".format(name)] + str_row
write_file("new.csv",row)
else:
continue
有不明的地方在下方留言,我看到后会尽快回复的
实战项目五:抓取简书文章信息
源码:
from fake_useragent import UserAgent
from lxml import etree
import lxml,requests
url="https://www.jianshu.com/c/qqfxgN?utm_campaign=haruki&utm_content=note&utm_medium=reader_share&utm_source=qq"
def getHtml(url):
'''
获取网页源码
return html
'''
headers = {
"Host": "www.jianshu.com",
"Referer": "https://www.jianshu.com/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
req = requests.get(url, headers=headers)
html = etree.HTML(req.text)
return html
def parse(html):
'''
解析网页
'''
nodes = html.xpath("//ul[@class='note-list']/li//div[@class='content']")
for node in nodes:
title = node.xpath(".//a[@class='title']/text()")[0]
nickname = node.xpath(".//div[@class='meta']/a/text()")[0]
comment = node.xpath(".//div[@class='meta']/a//text()")[2].strip()
like = node.xpath(".//div[@class='meta']/span/text()")[0].strip()
essay = {
"title" : title,
"nickname" : nickname,
"comment" : comment,
"like" : like
}
print("文章信息:{}".format(essay))
def main():
html = getHtml(url)
parse(html)
if __name__ == '__main__':
main()
Python3--批量爬取数据之调金山词霸api进行翻译
上代码:
#/usr/bin/env python3
#coding=utf8
from fake_useragent import UserAgent
import http.client
import hashlib
import urllib
import random,csv
import json,time
import requests
#获取IP列表并检验IP的有效性
def get_ip_list():
f=open('IP.txt','r')
ip_list=f.readlines()
f.close()
return ip_list
#从IP列表中获取随机IP
def get_random_ip(ip_list):
proxy_ip = random.choice(ip_list)
proxy_ip=proxy_ip.strip('\n')
proxies = {'https': proxy_ip}
return proxies
#注释:a若查找不到中人名则返回a(row[6])
def getTransResult(q):
type = "json"
q = q.lower()
myurl = 'http://dict-co.iciba.com/api/trans/vip/translate'
#q = 'hello baidu trans' #要翻译的内容
myurl = "http://dict-co.iciba.com/api/dictionary.php?w="+q+"&type="+type+"&key=key" #开发者Key
ip_list = get_ip_list()
proxies = get_random_ip(ip_list)
headers = { 'User-Agent':str(UserAgent().random)}
try:
time.sleep(1)
req=requests.get(myurl,headers=headers,proxies=proxies)
except:
print('程序出错,暂停20秒')
time.sleep(20)
proxies = get_random_ip(ip_list)
headers = { 'User-Agent':str(UserAgent().random)}
req=requests.get(myurl,headers=headers,proxies=proxies)
req.encoding="utf-8"
data = req.text
mresult = json.loads(data)
getTransResult=''
try:
getTransResult = mresult['symbols'][0]['parts'][0]['means'][0]
except:
return getTransResult
print('翻译结果为:'+getTransResult)
return getTransResult
#功能:读取文件并处理
def read_file(filepath):
reader=[]
with open(filepath,'r') as csvfile:
spanreader = csv.reader(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
for row in spanreader:
if row:
reader.append(row)
return reader
#功能:将爬取到的内容写入文件
#注意事项:写文件时open中要加上newline='',否则写一行后程序会自动换行
def write_file(filepath,row):
with open(filepath,'a+',encoding='utf-8',newline='') as csvfile:
spanreader = csv.writer(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
spanreader.writerow(row)
if __name__ == "__main__":
reader = read_file('S_baiduBaike_youdaoChinese_utf-8.csv')
for row in reader:
if not row[6]:
print('现在爬取的人名是:'+row[0])
TransResult = getTransResult(row[0])
if not TransResult.find('[人名]')==-1:
TransResult=TransResult.replace('[人名]','')
row[6] = TransResult
elif not TransResult.find('[男子名]')==-1:
TransResult=TransResult.replace('[男子名]','')
row[6] = TransResult
elif not TransResult.find('[女子名]')==-1:
TransResult=TransResult.replace('[女子名]','')
row[6] = TransResult
write_file('经有道金山词霸爬取后/S_baiduBaike_youdaoChinese_jscb.csv',row)
print('程序运行结束')
Python3--批量爬取数据之调用百度api进行翻译
#************************************************************
#文件功能:利用百度翻译将英文名翻译成中文
#************************************************************
import csv,requests,random
from fake_useragent import UserAgent
import hashlib
import json
import time
import urllib.parse
class Baidufanyi:
"""docstring for ClassName"""
def __init__(self, appid, appSecret, ip_list):
self.url = 'https://fanyi-api.baidu.com/api/trans/vip/translate'
self.ip_list = ip_list #ip列表
self.appid = appid #应用ID
self.appSecret = appSecret #应用密钥
self.langFrom = 'en' #翻译前语言
self.langTo = 'zh' #翻译后语言
'''
功能:将数据url编码
注释:param queryText:待翻译的文字
return:返回url编码过的数据
'''
def getUrlEncodeData(self,queryText):
salt = '2' #我们将随机数固定为2
sign_str = self.appid + queryText + salt + self.appSecret
sign_str = sign_str.encode('utf-8')
sign = hashlib.md5(sign_str).hexdigest()
payload = {
'q': queryText,
'from': self.langFrom,
'to': self.langTo,
'appid': self.appid,
'salt': salt,
'sign': sign
}
# 注意是get请求,不是请求
data = urllib.parse.urlencode(payload)
return data
'''''
解析页面,输出翻译结果
:param html: 翻译返回的页面内容
:return: None
'''
def parseHtml(self, html):
data = json.loads(html)
print ('-------------------------')
translationResult = data['trans_result'][0]['dst']
if isinstance(translationResult, list):
translationResult = translationResult[0]
print (translationResult)
return translationResult
def get_translateResult(self,queryText):
data = self.getUrlEncodeData(queryText) #获取url编码过的数据
target_url = self.url + '?' + data #构造目标url
print('target_url为:'+target_url)
headers = {'User-Agent':'str(UserAgent().random)'}
try:
proxies = get_randomIp(self.ip_list)
req = requests.get(target_url,proxies=proxies,headers=headers,timeout=10) #构造请求
except:
print('运行错误,暂停20秒')
proxies = get_randomIp(self.ip_list)
req = requests.get(target_url,proxies=proxies,headers=headers) #再次进行构造请求
req.encoding='utf-8'
html = req.text
translateResult = self.parseHtml(html) #解析,显示翻译结果
return translateResult
#获取IP列表并检验IP的有效性
def get_ipList():
f=open('IP.txt','r')
ip_list=f.readlines()
f.close()
return ip_list
#从IP列表中获取随机IP
def get_randomIp(ip_list):
proxy_ip = random.choice(ip_list)
proxy_ip=proxy_ip.strip('\n')
proxies = {'http': proxy_ip}
return proxies
#功能:获取需要翻译的文件内容
def reader_file(filePath):
reader=[]
with open(filePath,'r',encoding='utf-8') as csvfile:
spanreader = csv.reader(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
for row in spanreader:
if row:
reader.append(row)
return reader
#功能:将信息写入文件
def write_file(filePath,row):
with open(filePath,'a+',encoding='utf-8',newline='') as csvfile:
spanreader = csv.writer(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
spanreader.writerow(row)
#主程序
def main():
print('程序开始运行!')
appid = appid #应用ID
appSecret = appSecret #应用密钥
filePath = 'baidubaike.csv' #需要翻译的文件
ip_list = get_ipList()
fanyi = Baidufanyi(appid,appSecret,ip_list)
reader = reader_file(filePath)
for row in reader:
translateResult = '翻译成功后的结果' #翻译成功后的结果
if not row[6]:
print('现在翻译的英文名是:'+row[0])
translateResult = fanyi.get_translateResult(row[0])
print('翻译成功后的结果是:'+translateResult)
row[6] = translateResult
write_file('baidubaike_notChinese.csv',row) #将爬取过的内容存入test.csv文件
else:
write_file('baidubaike_Chinese.csv',row) #将未进行爬取的内容存进test_.csv文件
print('信息爬取成功,程序运行结束')
if __name__ == '__main__':
main()
Python3--批量爬取数据之调用有道api进行翻译
# coding=utf-8
import urllib,urllib.request
from fake_useragent import UserAgent
import json
import time
import hashlib
import urllib.parse
import requests
import random
import csv,re
class YouDaoFanyi:
def __init__(self, appKey, appSecret):
self.url = 'https://openapi.youdao.com/api/'
self.headers = { 'User-Agent':str(UserAgent().random)}
self.appKey = appKey # 应用id
self.appSecret = appSecret # 应用密钥
self.langFrom = 'EN' # 翻译前文字语言,auto为自动检查
self.langTo = 'zh-CHS' # 翻译后文字语言,auto为自动检查
def getUrlEncodedData(self, queryText):
'''
将数据url编码
:param queryText: 待翻译的文字
:return: 返回url编码过的数据
'''
salt = '2' # 产生随机数 ,其实固定值也可以,不如"2"
sign_str = self.appKey + queryText + salt + self.appSecret
sign_str=sign_str.encode('utf-8')
sign = hashlib.md5(sign_str).hexdigest()
payload = {
'q': queryText,
'from': self.langFrom,
'to': self.langTo,
'appKey': self.appKey,
'salt': salt,
'sign': sign
}
# 注意是get请求,不是请求
data = urllib.parse.urlencode(payload)
return data
def parseHtml(self, html):
'''
解析页面,输出翻译结果
:param html: 翻译返回的页面内容
:return: None
'''
data = json.loads(html)
print ('-------------------------')
translationResult = data['translation']
if isinstance(translationResult, list):
translationResult = translationResult[0]
print (translationResult)
return translationResult
def translate(self, queryText):
data = self.getUrlEncodedData(queryText) # 获取url编码过的数据
target_url = self.url + '?' + data # 构造目标url
# request = urllib2.Request(target_url, headers=self.headers) # 构造请求
ip_list=get_ip_list()
proxies=get_random_ip(ip_list)
print('随机ip为:'+str(proxies))
req = requests.get(target_url,proxies=proxies, headers=self.headers) # 构造请求
# with request.urlopen(request) as response111: # 发送请求
req.encoding='utf-8'
html=req.text
translationResult=self.parseHtml(html) # 解析,显示翻译结果
return translationResult
#功能:读取文件并处理
def read_file(filepath):
reader=[]
with open(filepath,'r',encoding='utf-8') as csvfile:
spanreader = csv.reader(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
for row in spanreader:
if row:
reader.append(row)
return reader
#功能:将爬取到的内容写入文件
#注意事项:写文件时open中要加上newline='',否则写一行后程序会自动换行
def write_file(filepath,row):
with open(filepath,'a+',encoding='utf-8',newline='') as csvfile:
spanreader = csv.writer(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL)
spanreader.writerow(row)
#获取IP列表并检验IP的有效性
def get_ip_list():
f=open('IP.txt','r')
ip_list=f.readlines()
f.close()
return ip_list
#从IP列表中获取随机IP
def get_random_ip(ip_list):
proxy_ip = random.choice(ip_list)
proxy_ip=proxy_ip.strip('\n')
proxies = {'http': proxy_ip}
return proxies
if __name__ == "__main__":
print('程序开始运行!')
appKey = '应用id' # 应用id
appSecret = '应用密钥' # 应用密钥
fanyi = YouDaoFanyi(appKey, appSecret)
reader=read_file('E_baiduBaike_notHaveChinese.csv')
for row in reader:
print('现在翻译的人名是:'+row[0])
translationResult=fanyi.translate(row[0])
print('翻译结果为:'+str(translationResult))
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
if zhPattern.search(translationResult):
row[6]=translationResult
write_file('经有道翻译处理后的文件/E_baiduBaike_youdaoChinese.csv',row)
print('爬取完成')

