

01 找出数组中的幸运数
题目描述【Easy】
在整数数组中,如果一个整数的出现频次和它的数值大小相等,我们就称这个整数为「幸运数」。 给你一个整数数组 arr,请你从中找出并返回一个幸运数。 如果数组中存在多个幸运数,只需返回 最大 的那个。 如果数组中不含幸运数,则返回 -1 。 示例: 输入:arr = [2, 2, 3, 4] 输出:2 解释:数组中的唯一幸运数是 2,因为数值 2 出现的频次也是 2。
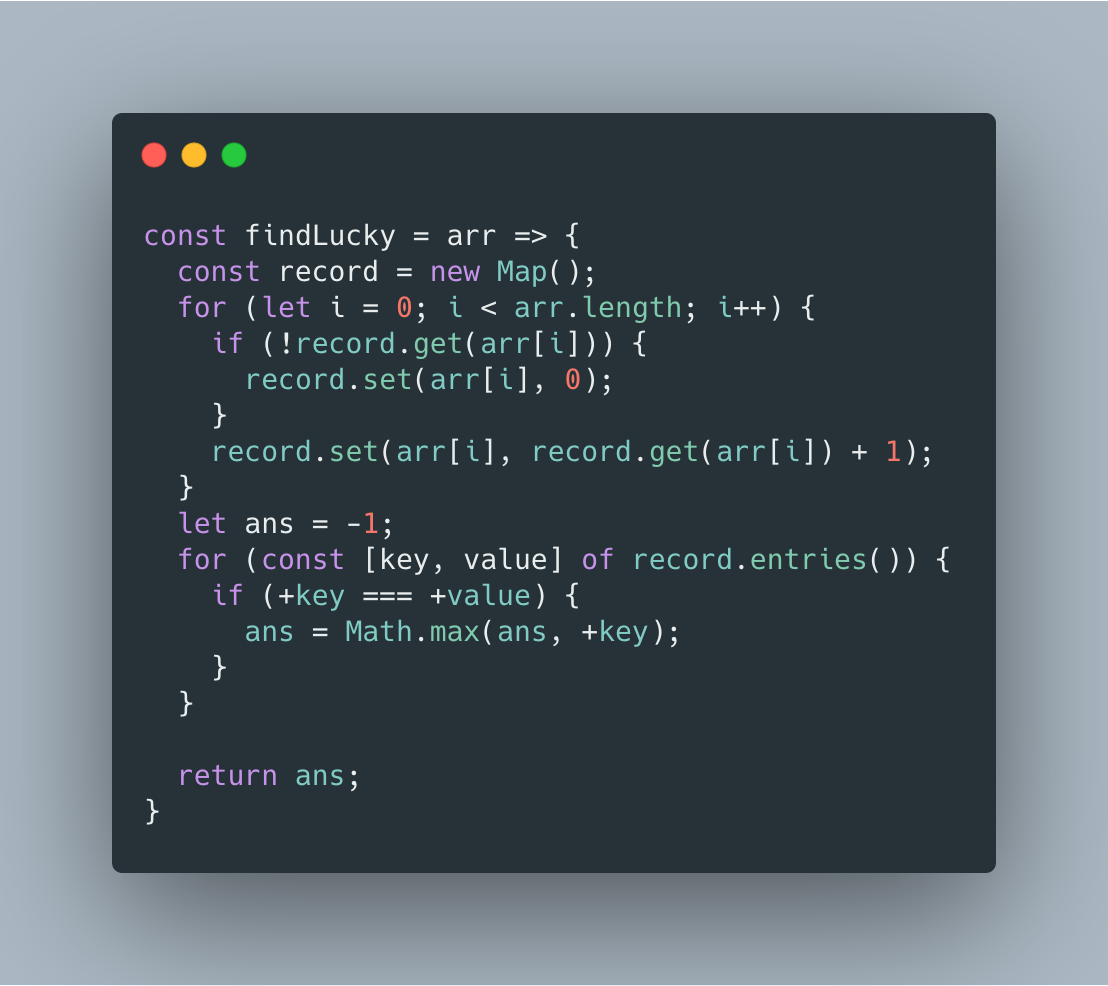
本道题主要考察 JavaScript 中的 Map 数据结构的使用。
第一步:利用 Map 可以来统计每个数字出现的次数。
第二步:从 Map 中找出次数出现相同并且数值最大的数。
时间复杂度 O(n),空间复杂度 O(n)。
02 统计作战单位数
题目描述【Medium】
n 名士兵站成一排。每个士兵都有一个 独一无二 的评分 rating 。 每 3 个士兵可以组成一个作战单位,分组规则如下: 从队伍中选出下标分别为 i、j、k 的 3 名士兵,他们的评分分别为 rating[i]、rating[j]、rating[k] 作战单位需满足:rating[i] < rating[j] < rating[k] 或者 rating[i] > rating[j] > rating[k] ,其中 0 <= i < j < k < n 请你返回按上述条件可以组建的作战单位数量。每个士兵都可以是多个作战单位的一部分。 示例: 输入:rating = [2, 5, 3, 4, 1] 输出:3 解释:可以组建三个作战单位(2, 3, 4)(5, 3, 1)(5, 4, 1)
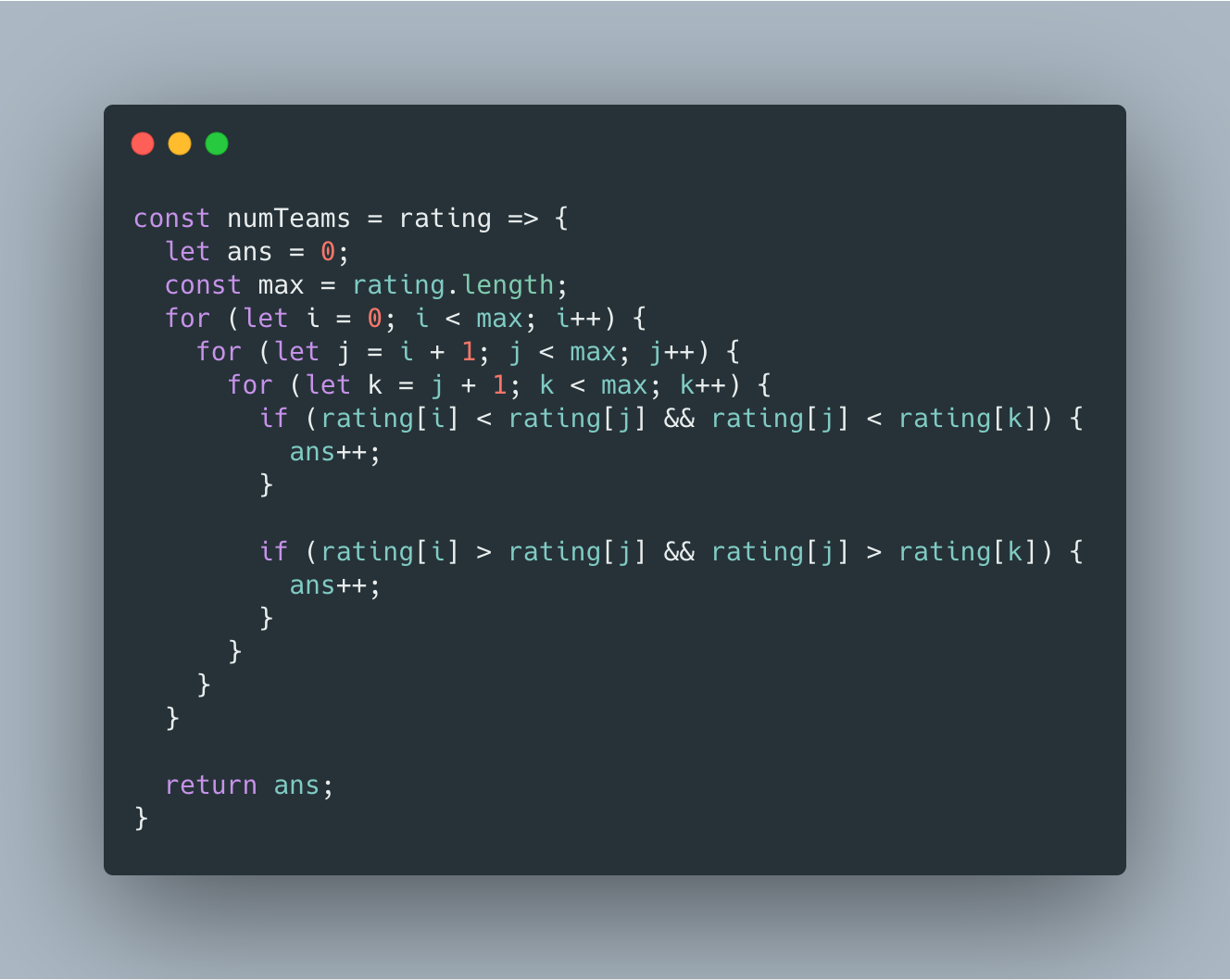
由于本道题的数组长度给定的范围非常小,尝试了一下暴露枚举竟然过了。
时间复杂度 O(n^3)。
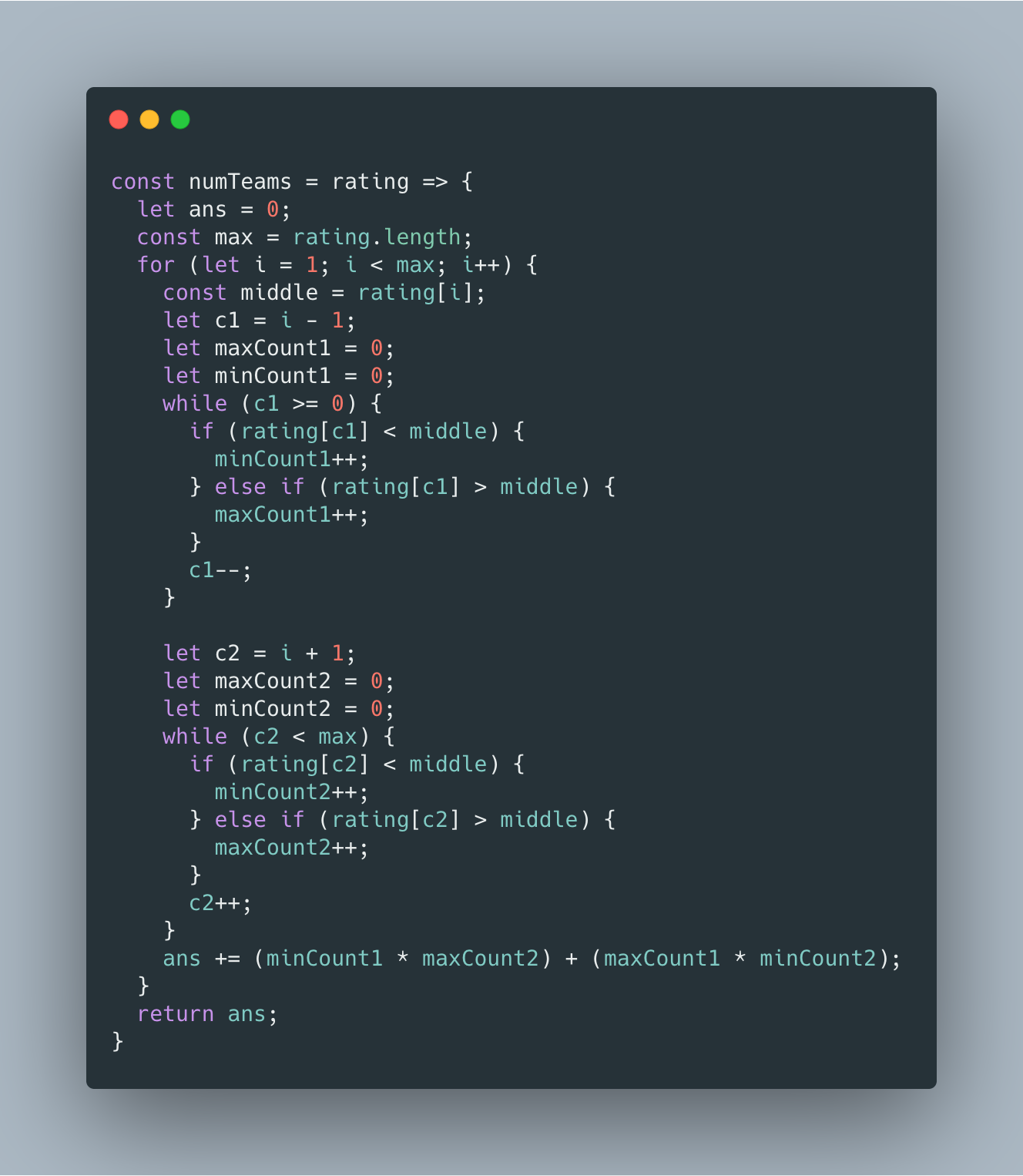
总共要求有三个士兵,那么可以以中间的士兵为参考点,向两边寻找满足要求的士兵。
这实际上就是利用双指针技巧来降维,时间复杂度优化为 O(n^2)。
03 5370.设计地铁系统
题目描述【Medium】
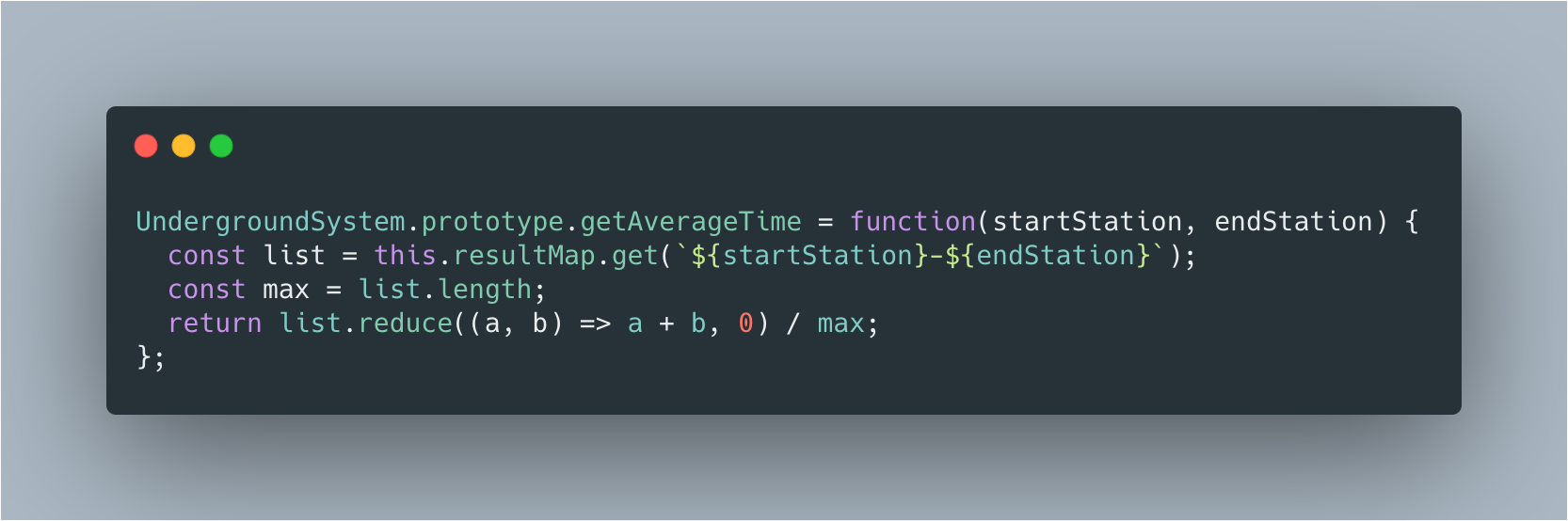
请你实现一个类 UndergroundSystem ,它支持以下 3 种方法: 1. checkIn(int id, string stationName, int t) 编号为 id 的乘客在 t 时刻进入地铁站 stationName 。 一个乘客在同一时间只能在一个地铁站进入或者离开。 2. checkOut(int id, string stationName, int t) 编号为 id 的乘客在 t 时刻离开地铁站 stationName 。 3. getAverageTime(string startStation, string endStation) 返回从地铁站 startStation 到地铁站 endStation 的平均花费时间。 平均时间计算的行程包括当前为止所有从 startStation 直接到达 endStation 的行程。 调用 getAverageTime 时,询问的路线至少包含一趟行程。 你可以假设所有对 checkIn 和 checkOut 的调用都是符合逻辑的。也就是说,如果一个顾客在 t1 时刻到达某个地铁站,那么他离开的时间 t2 一定满足 t2 > t1 。所有的事件都按时间顺序给出。
看完本道题的描述,大部分 coder 都会想到利用 HashMap 来统计,但是要统计哪些信息来方便 getAverageTime 方法计算呢?
首先,对于任意一个乘客,他必然是先进再出,依次循环,那么当我们拿到他出站的信息时,只需要保留进站和出站的时间间隔即可,之前的进站和出站信息可以删除掉,不然再统计该乘客后续的进出站就比较麻烦了。
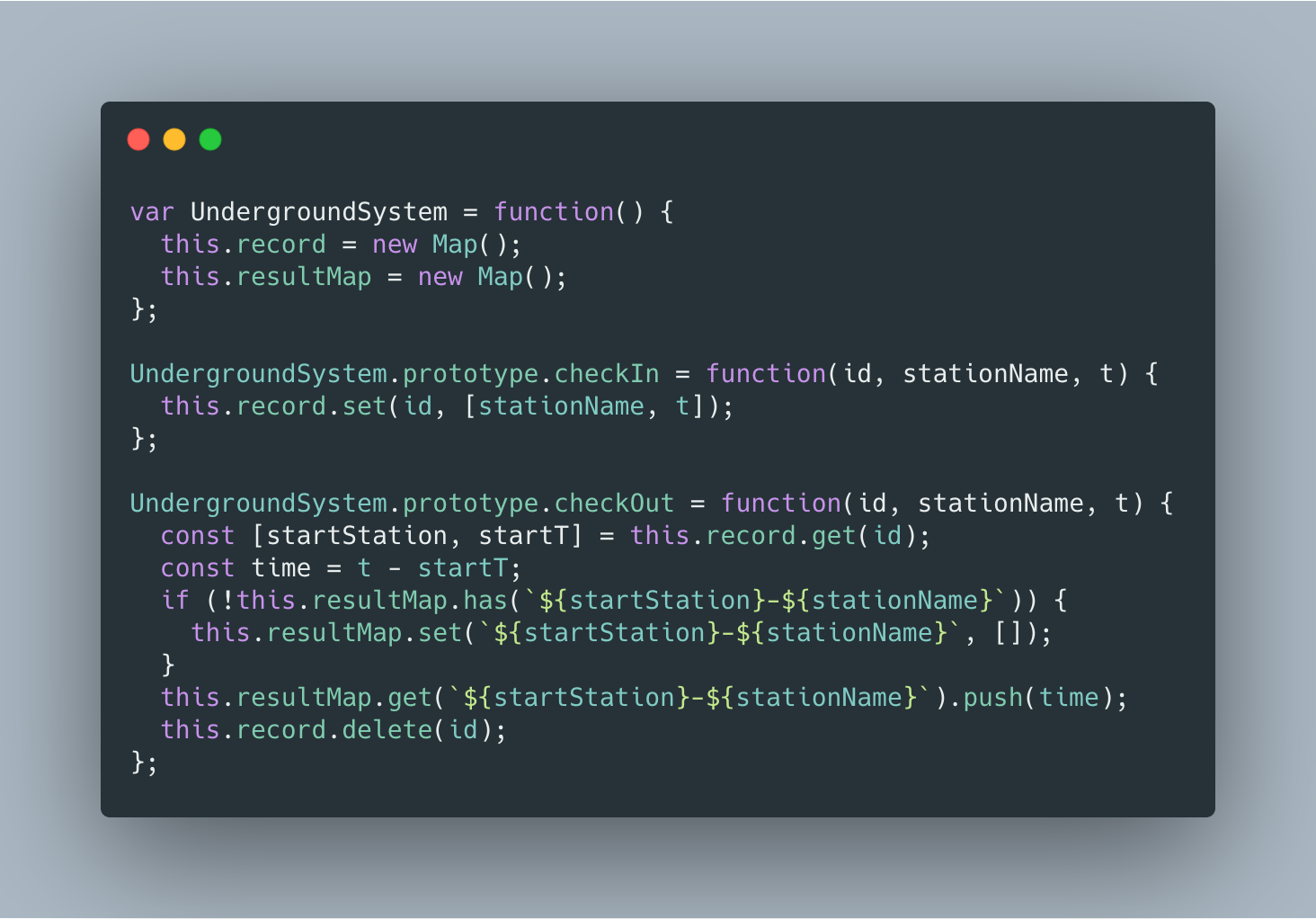
最后执行 getAverageTime 方法时,利用进站和出站信息查询 HashMap 计算和值即可。
空间复杂度 O(n),checkIn 和 checkOut 的时间复杂度为 O(1),getAverageTime 的时间复杂度为 O(n)。
04 5371.找到所有好字符串
题目描述【Hard】
给你两个长度为 n 的字符串 s1 和 s2 ,以及一个字符串 evil 。请你返回 好字符串 的数目。 好字符串 的定义为:它的长度为 n ,字典序大于等于 s1 ,字典序小于等于 s2 ,且不包含 evil 为子字符串。 由于答案可能很大,请你返回答案对 10^9 + 7 取余的结果。 示例: 输入:n = 2, s1 = 'aa', s2 = 'da', evil = 'b' 输出:51 解释:总共有 25 个以 'a' 开头的好字符串:'aa','ac','ad',...,'az'。还有 25 个以 'c' 开头的好字符串:'ca','cc','cd',...,'cz'。最后,还有一个以 'd' 开头的好字符串:'da'。
本题涉及两个知识点:
数位 DP
KMP
首先,我们可以将 evil 这个条件忽略,如何求解 [s1, s2] 之间的所有字符串?
比较容易想到的思路是:判断上下限,暴力枚举出所有情况。
这个方法存在两个问题:
在枚举的过程中,同时处理上下限是比较复杂的
暴力枚举会出现很多重复枚举的情况,效率低
对于第一个问题:可以将这个问题转为更加简单的形式,先求解出字典序小于等于 s1,再求解出字典序小于等于 s2,那么结果就是 s2 - s1 + 1。
对于第二个问题:从高位开始枚举结合记忆化优化重复枚举操作,这就是数位 DP。
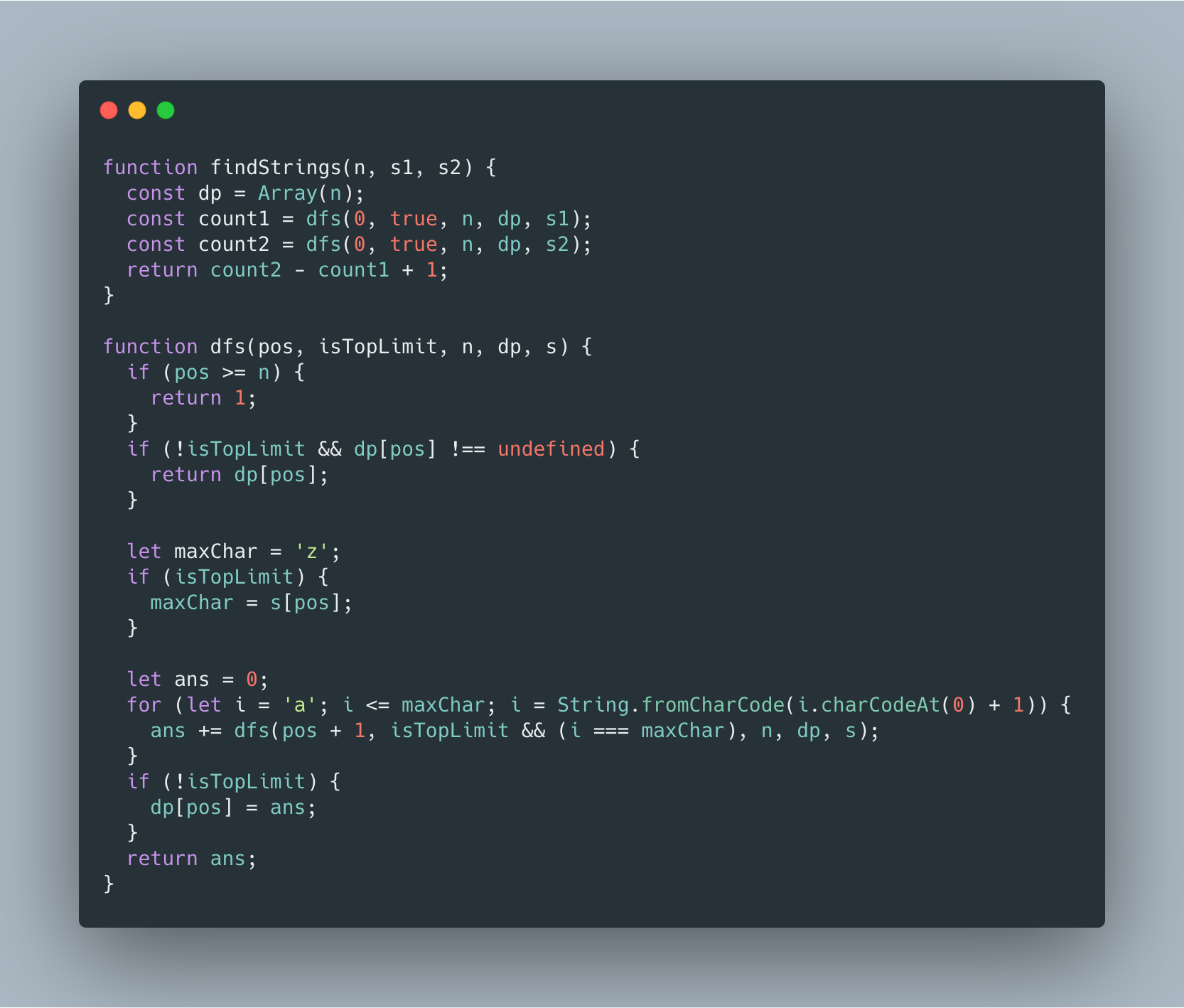
本题难点在于:不包含 evil 字符串。
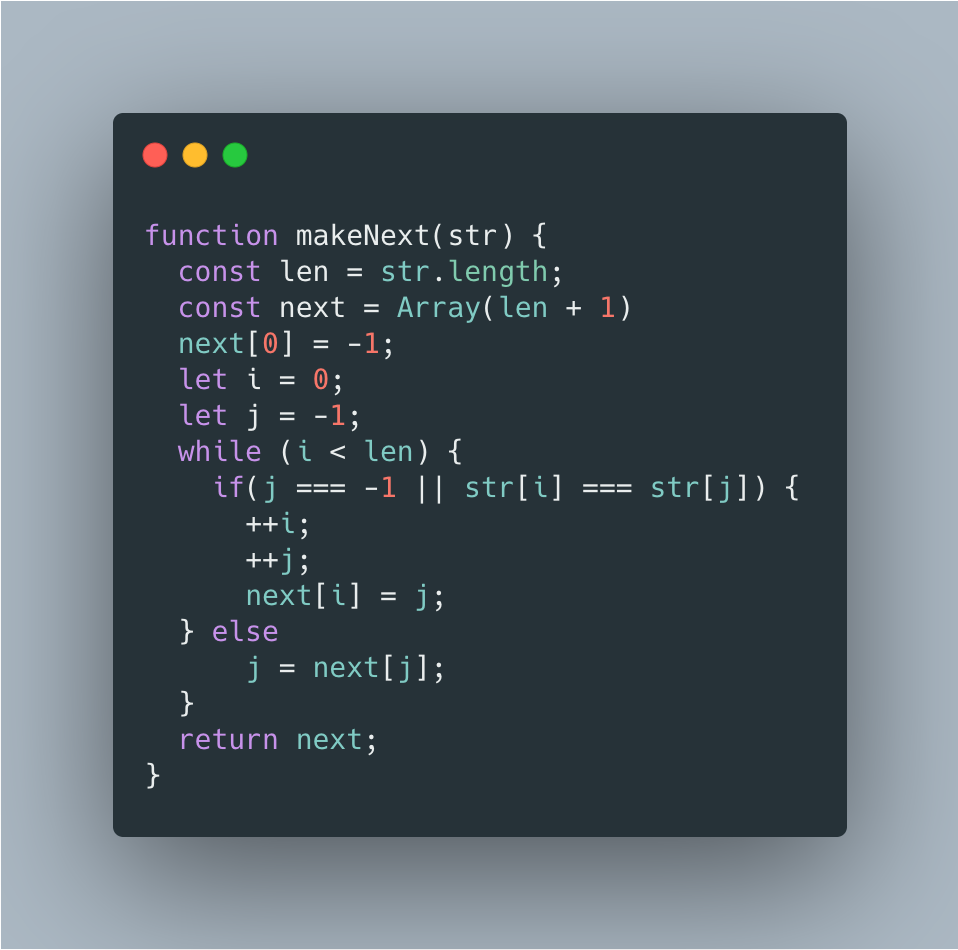
这就需要 KMP 算法中的 next 数组来帮助我们记录当前字符串是否匹配上 evil 字符串。
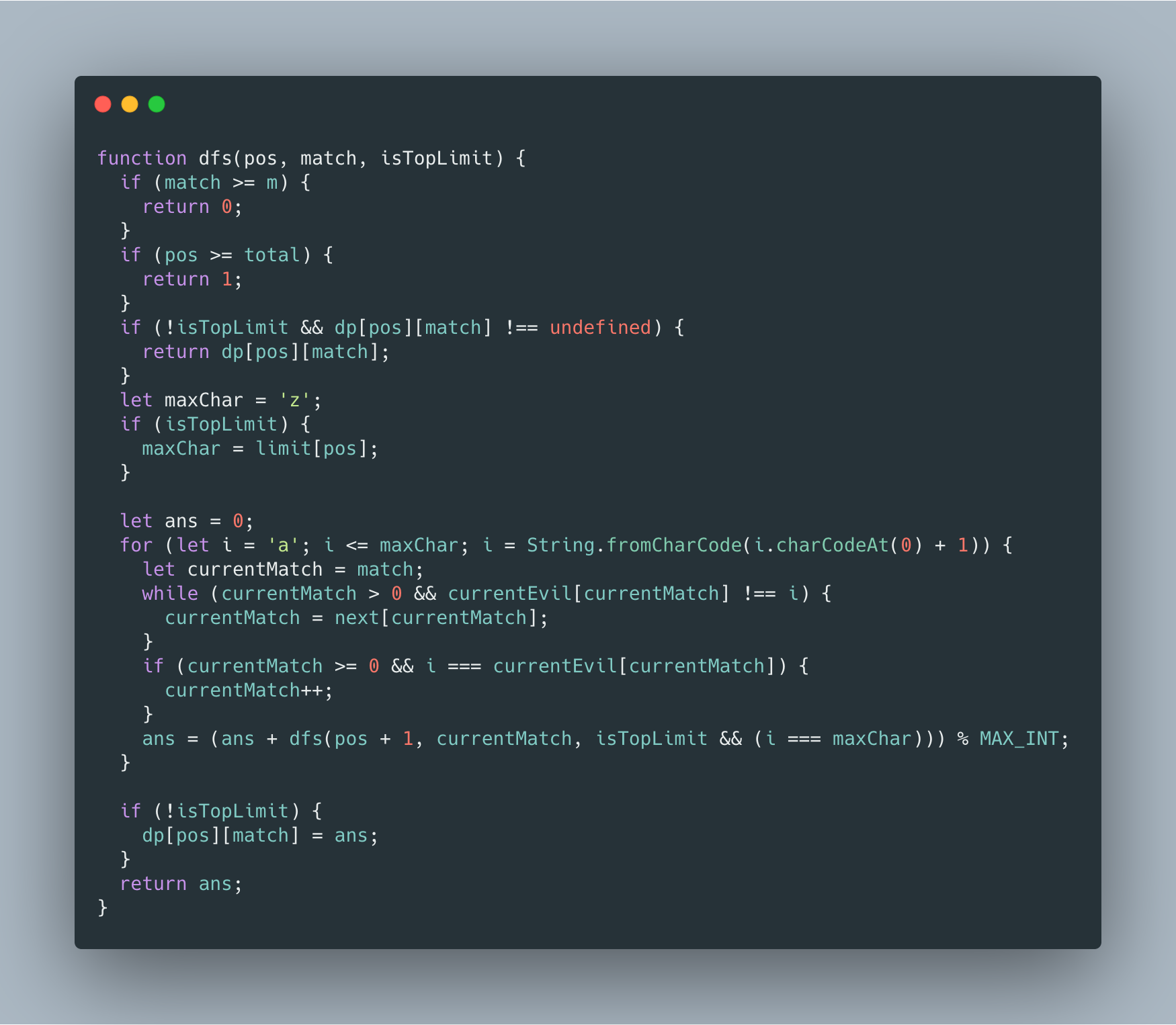
那么在数位 DP 的过程中,我们需要添加一个当前匹配上 evil 字符长度的状态,并且在枚举的过程中利用 KMP 的 next 数组来求解当前匹配上的字符。
05 往期精彩回顾

