点赞再看,养成习惯,微信搜索【慕容千语】有惊喜哦
前言
从 Mysql 数据库角度来说,谈到存储就一定离不开字符集,只不过在我们日常开发中统一的 utf8/utf8mb4 编码,使我们常常忽略了字符集的影响,本文仅从字符集的角度来谈谈对 InnoDB 的存储设计的一点影响,以及 Mysql 是怎么兼容各种字符集的。
过一下字符集
Unicode 作为现在通用的字符集,通常采用两个字节表示一个字符,带来的副作用就是,原本采用 ASCII 字符集只需要一个字节的,却变成了 2 个字节,造成了空间浪费,而 UTF-8 编码规则,将 Unicode 编码成 1~4 个字节,ASCII 字符集继续保持了 1 个字节空间,而中文编码成了三个字节,如下图。
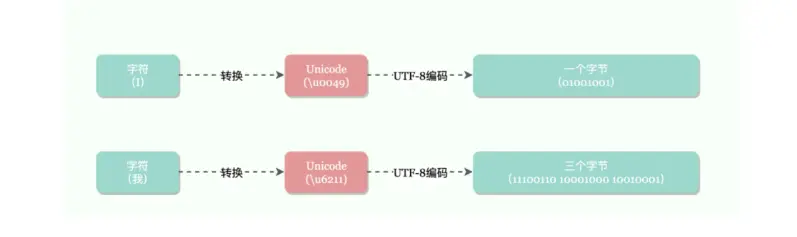
对存储带来了什么影响
先说明下 Mysql 中存在两种字符集 utf8 和 utf8mb4,以下例子均以 Mysql 的 utf8(1~3个字节)为例。
采用 utf8 编码的确很不错,但是也带来了一个问题,例如我在 Mysql 中定义了一个定长字符类型 char(5):

所谓定长字符类型代表我要给 title 分配 5 个字符大小的空间,可是 utf8 每个字符可能是 1~3 个字节,我该分配多少空间合适呢?
理论上为了兼容,最好应该采用 utf8 的最大 3 个字节进行分配,也就是 5*3 = 15 个字节的空间,这样我不管以后怎么修改这个字段的值,空间都能完美满足需求,但是如果此时存储的都是英文,比如 5 个 I,就会足足浪费 10 个字节的空间,如果这列以后都存英文,那么至少会浪费 2/3 的空间。
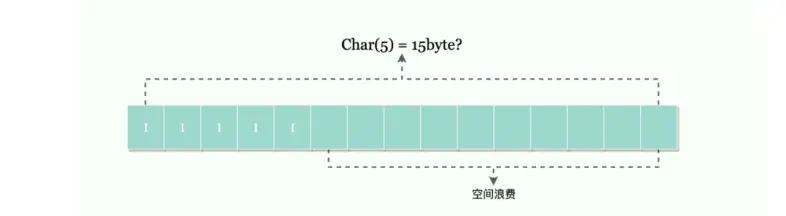
在 Mysql5.0 之前的行格式设计中,也就是 Redundant 行格式,char(5) 的确就如上面设计占用了 15 个字节空间,随着版本的迭代,后续出来的 Compact,Dynamic,Compressed 行格式都采用了另一种设计。
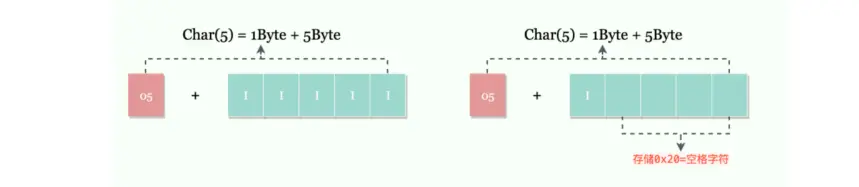
在对于 utf8 这类变长编码规则的 char 类型,采用同 varchar 类型一样的存储方式,就是在前面用一个或两个字节表示该列实际占用的字节数,对应到上图存储 5 个 I 的例子,就是 05(实际占用字节数)+5 个存储 I 的字节空间。
当然,更极端点,我只存储了一个 I,这时 char(5) 就会使用 utf8 的最小字节数 1*5(char定义的字符长度)的大小作为最小分配空间,空出的 4 个字节空间用空格字符填充,也就是说,对于 title 来说,至少会分配 5 个字节空间。
上面只是对列为 char(5) 的数据进行说明,在真实数据库表中,会存在多列 varchar 或 char 类型,由上可知变长编码规则的 char 也是按 varchar 处理的,所以这些列的实际占用字节数都会逆序存放在行格式首部,被称为变长字段长度列表,而每列的数据,则是顺序存放在列值中,如下图,至于变长字段长度列表和 Null 值列表为什么是逆序的,大家有兴趣可以去想想。

带来的更新问题
采用上面的设计,在大部分情况下能省下了很多空间,也提升了查询效率,但是也带来了另一个问题,那就是更新,用两个例子说明下:
将 title 从 1个 I 更新为 5 个 I
这个很好处理,因为 char(5) 最低会分配 5 个字节空间,更改为 5 个 I,不会产生任何影响,直接更新就好。
将 title 从 5 个 I 更改为 5 个我
5 个我 = 5 * 3 = 15 个字节空间,而实际记录只有 5 个字节空间,空间不足以支撑更新,这时候的更新只能将原数据的整行记录删除,然后再新分配合适空间供其使用,看似也没什么,但是这种删 + 增实际会对页产生很多变更,这么多变更又要保证它的事务性,也就是记录 redo , undo 日志,还是挺复杂和麻烦的。
Mysql的字符集转换机制
一个请求从客户端到 Mysql 服务器,再到表,再返回给客户端,中间是经过多层字符集转换的,主要包括下面4层:

假设我们查询 title 列,并且 Mysql 各种变量以及列字符集采用上面表格的例子,那么转换如下:

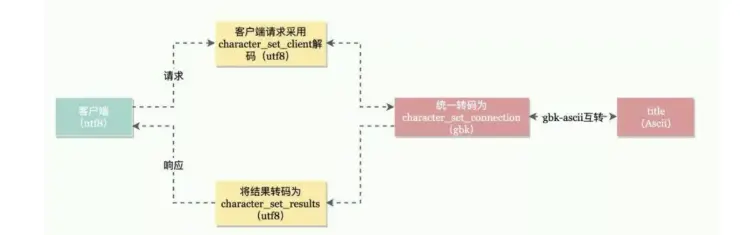
当然,实际开发中,我们都会统一均采用 utf8 ,这样就有效避免了各层字符集转换带来的性能影响。
总结
随着 Mysql 性能的提升,其代码实现复杂度也显著提升,为了性能,对一种场景进行区分各种情况,再对各种情况进行不同的优化处理,已经不再陌生,所以面对这么多复杂的实现,从一个小的切入点,发现其乐趣,也是挺有意思的。


