

单向循环链表概念
链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
单向链表
单向链表(单链表)是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要通过顺序读取从头部开始;链表是使用指针进行构造的列表;又称为结点列表,因为链表是由一个个结点组装起来的;其中每个结点都有指针成员变量指向列表中的下一个结点;

单向循环链表
单向循环链表是单向链表的一种,其特点是链表的的最后一个节点的next指针指向第一个节点地址;
单向循环链表的操作
创建
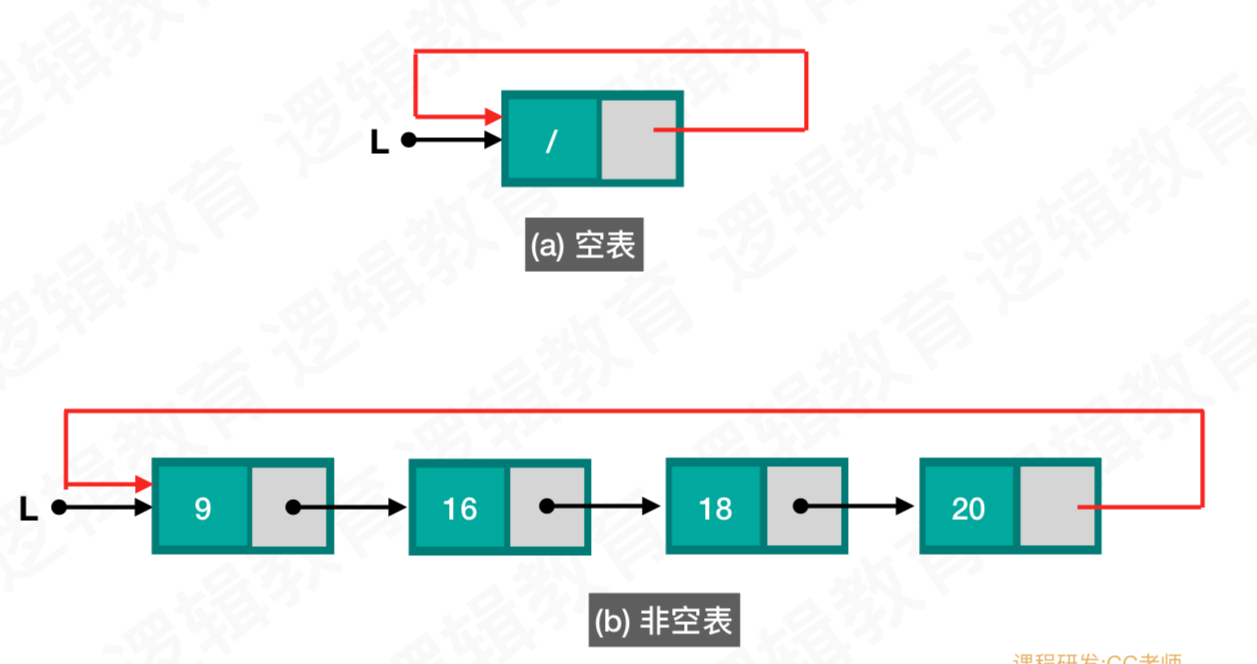
单向循环列表的创建分为两种,即空表和有数据的链表
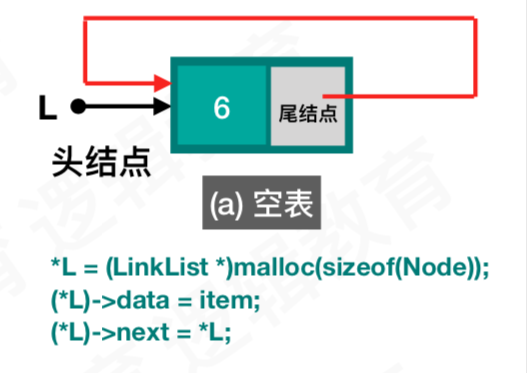
空表
非空表
/*
4.1 循环链表创建!
2种情况:① 第一次开始创建; ②已经创建,往里面新增数据
1. 判断是否第一次创建链表
YES->创建一个新结点,并使得新结点的next 指向自身; (*L)->next = (*L);
NO-> 找链表尾结点,将尾结点的next = 新结点. 新结点的next = (*L);
*/
Status CreateList(LinkList *L){
int item;
LinkList temp = NULL;
LinkList target = NULL;
printf("输入节点的值,输入0结束\n");
while(1)
{
scanf("%d",&item);
if(item==0) break;
//如果输入的链表是空。则创建一个新的节点,使其next指针指向自己 (*head)->next=*head;
if(*L==NULL)
{
*L = (LinkList)malloc(sizeof(Node));
if(!L)exit(0);
(*L)->data=item;
(*L)->next=*L;
}
else
{
//输入的链表不是空的,寻找链表的尾节点,使尾节点的next=新节点。新节点的next指向头节点
for (target = *L; target->next != *L; target = target->next);
temp=(LinkList)malloc(sizeof(Node));
if(!temp) return ERROR;
temp->data=item;
temp->next=*L; //新节点指向头节点
target->next=temp;//尾节点指向新节点
}
}
return OK;
}
查找
查找的时候,因为是循环,所以必须防止一直循环找下去,即当链表的next指针指向链表的时候,就表示已经循环查找了一遍了。
//4.2 遍历循环链表,循环链表的遍历最好用do while语句,因为头节点就有值
void show(LinkList p)
{
//如果链表是空
if(p == NULL){
printf("打印的链表为空!\n");
return;
}else{
LinkList temp;
temp = p;
do{
printf("%5d",temp->data);
temp = temp->next;
}while (temp != p);
printf("\n");
}
}
删除
单向循环链表的删除也分两种情况,即删除普通节点和删除首节点
删除首节点
- 找到尾节点
- 使得尾结点next 指向头结点的下一个结点
- 新结点做为头结点,则释放原来的头结点
- 释放删除节点的内存空间
删除普通节点
- 找到删除结点前一个结点target
- 使得target->next 指向下一个结点
- 释放需要删除的结点temp 代码如下
//4.4 循环链表删除元素
Status LinkListDelete(LinkList *L,int place){
LinkList temp,target;
int i;
//temp 指向链表首元结点
temp = *L;
if(temp == NULL) return ERROR;
if (place == 1) {
//①.如果删除到只剩下首元结点了,则直接将*L置空;
if((*L)->next == (*L)){
(*L) = NULL;
return OK;
}
//②.链表还有很多数据,但是删除的是首结点;
//1. 找到尾结点, 使得尾结点next 指向头结点的下一个结点 target->next = (*L)->next;
//2. 新结点做为头结点,则释放原来的头结点
for (target = *L; target->next != *L; target = target->next);
temp = *L;
*L = (*L)->next;
target->next = *L;
free(temp);
}else
{
//如果删除其他结点--其他结点
//1. 找到删除结点前一个结点target
//2. 使得target->next 指向下一个结点
//3. 释放需要删除的结点temp
for(i=1,target = *L;target->next != *L && i != place -1;target = target->next,i++) ;
temp = target->next;
target->next = temp->next;
free(temp);
}
return OK;
}
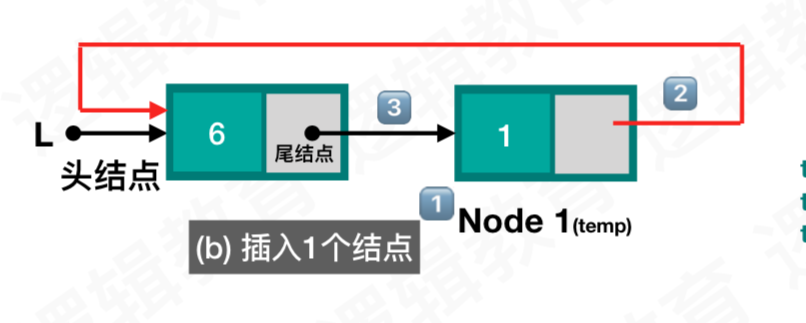
插入
插入位置为首元节点
- 创建新结点temp,并判断是否创建成功,成功则赋值,否则返回ERROR;
- 找到链表最后的结点_尾结点,
- 让新结点的next 执行头结点.
- 尾结点的next 指向新的头结点;
- 让头指针指向temp(临时的新结点)
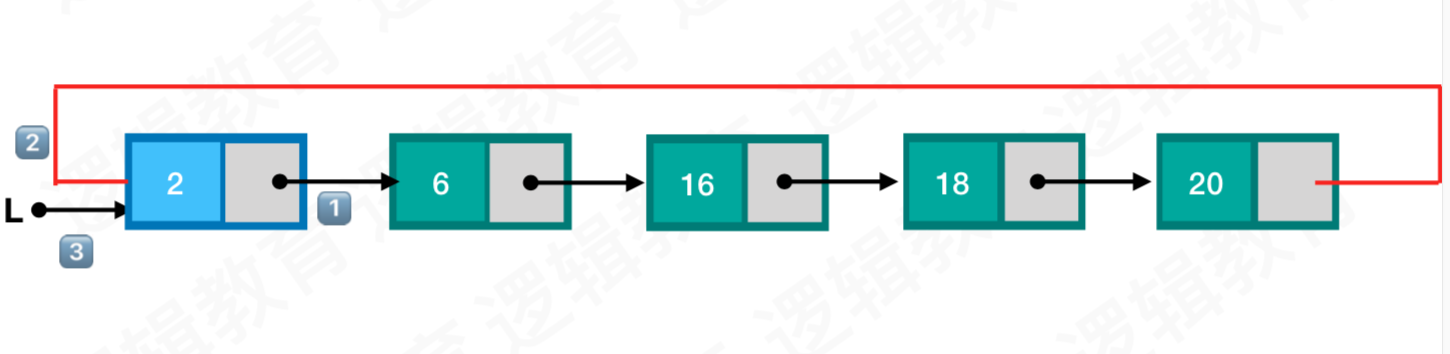
插入位置为普通节点
- 创建新结点temp,并判断是否创建成功,成功则赋值,否则返回ERROR;
- 先找到插入的位置,如果超过链表长度,则自动插入队尾;
- 通过target找到要插入位置的前一个结点, 让target->next = temp;
- 插入结点的前驱指向新结点,新结点的next 指向target原来的next位置 ;
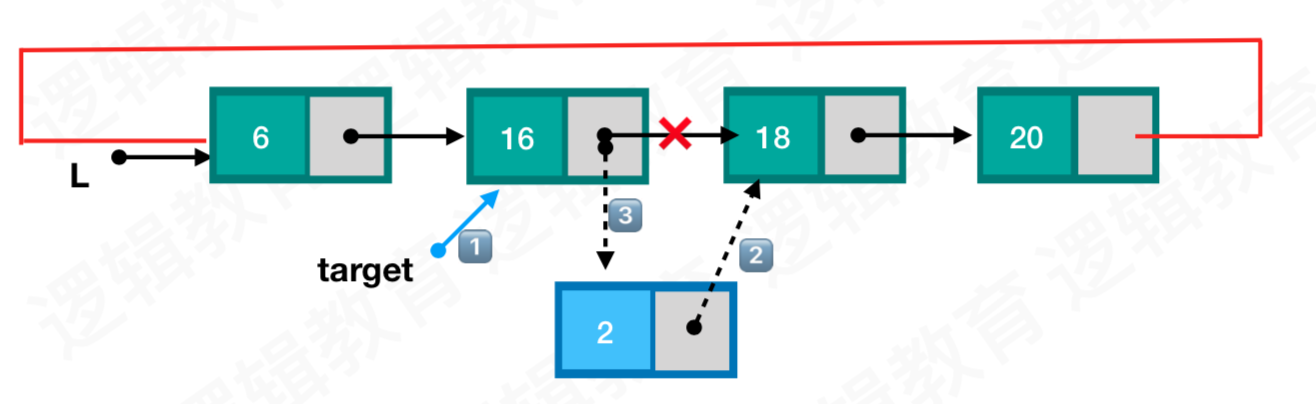
//4.3 循环链表插入数据
Status ListInsert(LinkList *L, int place, int num){
LinkList temp ,target;
int i;
if (place == 1) {
//如果插入的位置为1,则属于插入首元结点,所以需要特殊处理
//1. 创建新结点temp,并判断是否创建成功,成功则赋值,否则返回ERROR;
//2. 找到链表最后的结点_尾结点,
//3. 让新结点的next 执行头结点.
//4. 尾结点的next 指向新的头结点;
//5. 让头指针指向temp(临时的新结点)
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) {
return ERROR;
}
temp->data = num;
for (target = *L; target->next != *L; target = target->next);
temp->next = *L;
target->next = temp;
*L = temp;
}else
{
//如果插入的位置在其他位置;
//1. 创建新结点temp,并判断是否创建成功,成功则赋值,否则返回ERROR;
//2. 先找到插入的位置,如果超过链表长度,则自动插入队尾;
//3. 通过target找到要插入位置的前一个结点, 让target->next = temp;
//4. 插入结点的前驱指向新结点,新结点的next 指向target原来的next位置 ;
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) {
return ERROR;
}
temp->data = num;
for ( i = 1,target = *L; target->next != *L && i != place - 1; target = target->next,i++) ;
temp->next = target->next;
target->next = temp;
}
return OK;
}
总结
在处理单向循环列表的时候,要注意首元节点的特殊性。
