

「笔记很无味,点赞请准备。」

索引定义
❝数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据库表中的数据。
❞
从定义中可以看出,索引其实就是一种「数据结构」。数据都是以文件的形式存储在磁盘上的,每一行数据都有它的磁盘地址,如果没有索引,要从几百万行数据中检索一条数据,只能遍历整张表才能找过结果。有了索引之后,只需要在索引里面去检索这条数据就可以了,因为索引是一种特殊的专门用来快速检索的数据结构,当我们找到数据磁盘地址后,就可以拿到想要的数据。
索引类型
以InnoDB存储引擎为例,索引类型有:
Normal(普通索引)
❝
也叫非唯一索引,是最普通的索引,没有任何限制条件。
❞Unique(唯一索引)
❝
唯一索引要求键值不能重复。
主键索引是一种特殊的唯一索引,它多了一个限制条件,要求键值不能为空。
❞Fulltext(全文索引)
❝
全文索引主要是针对比较大的数据,比如我们存放的是消息内容,有几kb的数据,如果要解决like查询效率低的问题,可以创建全文索引。只有文本类型的字段才可以创建全文索引,比如char、varchar、text。
❞全文索引的使用:
select * from table where match(content) against ('xxxx' IN NATURAL LANGUAGE MODE);聚集索引(聚簇索引)
❝
聚集索引就是索引键值的逻辑顺序跟表数据行的物理存储顺序是一致的。在InnoDB中,主键索引就是聚集索引,非主键索引是非聚集索引。
❞
索引存储模型
索引的存储模型有二分查找、二叉查找树(BST Binary Search Tree)、平衡二叉树(AVL Tree)、多路平衡查找树(B Tree)、加强版多路平衡查找树(B+ Tree)。
存储模型是一步一步演进过来的。
InnoDB逻辑存储结构
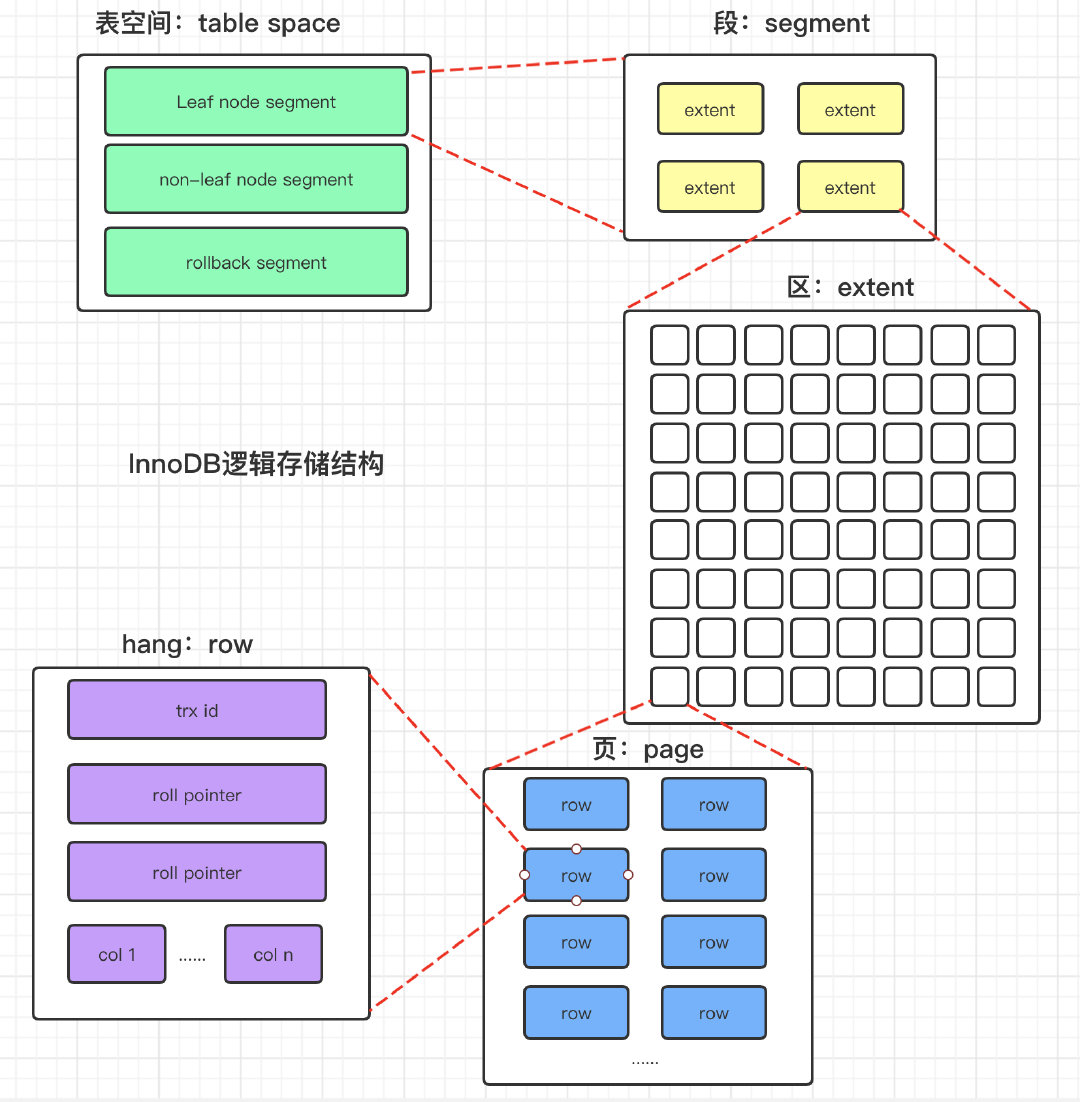
mysql的存储结构分为5级,表空间、段、簇、页、行。
- 表空间
❝表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。表空间又分为:系统表空间、独占表空间、通用表空间、临时表空间、Undo表空间。
❞
- 段(Segment)
❝表空间是由各个段组成,段又分为:数据段、索引段、回滚段。
段是一个逻辑概念,一个ibd文件(独立的表空间文件)里面会有很多个段组成。
创建一个索引会创建两个段,一个是索引段(leaf node segment),一个是数据段(non-leaf node segment)。索引段管理非叶子节点的数据,数据段管理叶子节点数据。
❞
- 簇(Extent)
❝一个段又是由多个簇(也可以叫区)组成,每个簇的大小是1MB(64个连续的页)。
每一个段至少有个一个簇,一个段所管理的空间大小是无限的,可以一直扩展下去,扩展的最小单位就是簇。
❞
- 页(Page)
❝簇是由连续的页组成的空间,一个簇中有64个连续的页。
一个表空间最多拥有2^32个页,默认情况下一个页的大小为16KB,也就是说一个表空间最多存储64TB的数据。
❞
- 行(Row)
❝InnoDB存储引擎是面向行(Row-oriented)存储的。
❞
索引使用原则
列的离散度
❝
列的离散度计算公式:count(distinct(column_name))/count(*),列的全部不同值和所有数据行的比例。数据行数相同的情况下,分子越大,列的离散度就越高。
简单来说,如果列的重复值越多,离散度就越低,重复值越少,离散度就越高。
❞联合索引最左匹配
❝
联合索引在B+Tree中是复合的数据结构,它是按照从左到右的顺序来建立搜索树的。
❞
我们在建立联合索引的时候,一定要把最常用的列放到最左边。
例如:给表table中建立联合索引a和b,
select * from table where a='xxx' and b='xxx' /*是可以用到联合索引的。*/
select * from table where a='xxx' /*可以用到联合索引*/
select * from table where b='xxx' /*无法使用联合索引*/
给a和b建立联合索引其实就是相当于(a)和(a,b)建立了两个索引。
在给a、b、c建立联合索引的时候其实就是建立了(a)索引,(a,b)索引,(a,b,c)索引,这时,如果条件where b=‘xxx‘和where b=‘xxx' and c='xxx',还有where a='xxx' and c='xxx'都是用不到联合索引的。
「说明联合索引的使用条件时不能不使用第一个字段,也不能中断。」
什么时候用不到索引
在索引列上使用函数(「replace、substr、concat、sum、count、avg」)、表达式、计算(「+、-、*、/」)。
字符串不加引号,出现隐式转换。
like条件前面带%。
负向查询
❝
not like 不能使用索引。
!=、<>、not in在某些情况下可能用到索引。
「注意:一个sql语句是否使用到索引,是跟数据库版本,数据量、数据选择度都有关系的。」
❞
其实用不用到索引,最终都是由「优化器」说了算。
「优化器是基于cost开销来决定的,怎么样开销小就怎么来。它不基于规则,也不基于语义。」
覆盖索引
❝在辅助索引里面,不管是单列索引还是联合索引,如果select后的数据列只要从索引中就能够得到,不用在从数据区中读取,这时候使用的索引就叫覆盖索引,这样也避免了回表。
❞
回表
❝非主键索引,是先通过索引找到主键索引的键值,在通过主键值查出索引里面没有的数据,它比基于主键索引查询的时候多了一次查询,这个过程就是回表。
❞
索引下推
❝例如:给a和b建立索引。
- 先根据a列从存储引擎中把符合规则的数据拉取到mysql的server层。
- 在server层按照b进行数据过滤。
这个过程就叫索引下推
❞
B+ Tree
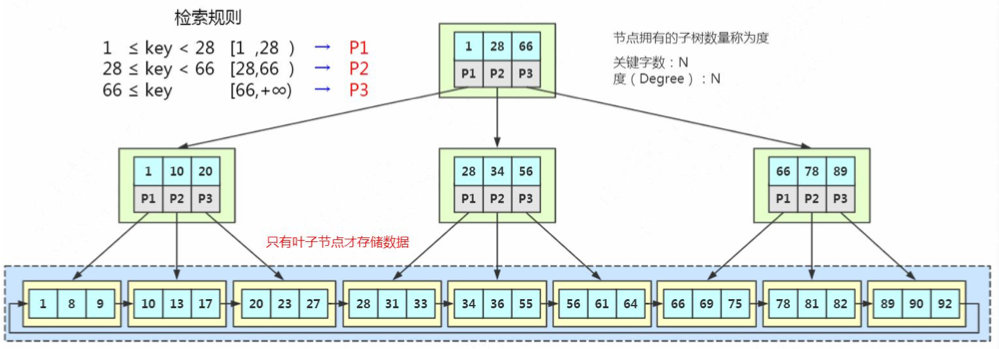
特点
- 它的关键字的数量是跟路数相等的。
- B+Tree的根据节点和枝节点都不会存储数据,只有叶子节点才存储数据。搜索到关键字不会直接返回,会到最后一层叶子节点。
- B+Tree的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,这样就形成了一个有序链表的结构。
- 它是根据左闭右开的区间来检索数据的。
- 整理不易,转载请注明出处,喜欢的小伙伴可以关注公众号查看更多喜欢的文章。
- 微信:ffj2000

