

一、ELK 简介, 架构组成, 各组件功能介绍
1. ELK介绍
ELK 是三个开源软件的缩写,分别代表 Elasticsearch, Logstash, Kibana, 这是最早的日志收集分析系统结构。
elasticsearch : 开源分布式搜索引擎, 主要有搜集, 分析, 存储数据三打功能, 有分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等特点
logstash : 主要有日志的搜集、分析、过滤功能,支持大量的数据获取方式
Kibana : 汇总、分析和搜索日志, 并提供更友好的web界面
filebeat : 轻量级的日志收集处理工具, 占用资源更少, 一般收集数据之后发生给logstash或缓存系统,也可以直接发给elasticsearch。
filebeat隶属于 Beats, 还有 Metricbeat , Packetbeat , Winlogbeat , Auditbeat , Heartbeat , Functionbeat 等采集器
Redis : 在日志收集系统种主要负责缓存, 防止丢失数据
2. 架构图
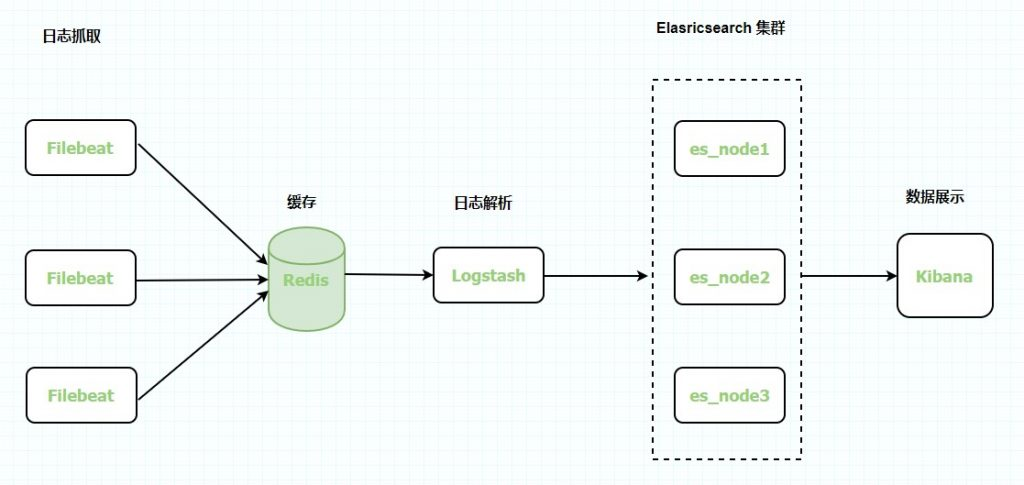
二、环境准备
系统版本及组件版本:
- ubuntu16.04
- elasticsearch_6.6.2
- logstash_6.6.2
- kibana_6.6.2
- filebeat_6.6.2
- jdk8
由于Elasticsearch 是使用java开发的,需要JVM才可以跑起来。因此我们首先要安装一下JDK,这里Elasticsearch6.6.2 的版本需要JDK8及以上。
安装JDK8:
官网下载安装包: www.oracle.com/technetwork…
说明: 现在官网下载JDK安装包需要注册一个oracle账号才能下载,或者自行下载第三方提供JDK压缩包
选择linux x64的压缩包下载
解压:
tar -zxvf jdk-8u211-linux-x64.tar.gz -C /opt/ # 存放目录自定义添加环境变量:
vi ~/.bashrc 在末尾追加以下四行
export JAVA_HOME=/opt/jdk1.8.0_211 # 这里的目录根据你的真实目录修改
export JRE_HOME=$JAVA_HOME/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH配置即时生效
source ~/.bashrc测试是否安装成功, 输入 java -version 查看是否输出java版本号, 输出下图这样就代表jdk安装成功了,接下来就可以安装elasticsearch啦~

三、 ELK+filebeat+Redis安装配置
1. Elasticsearch集群搭建
我这里准备了三台虚拟机用来搭建es集群: 192.168.50.17 192.168.50.2 192.168.50.4
官网下载安装包,我这里选择下载6.6.2的版本: artifacts.elastic.co/downloads/e…
解压:
tar -xvf elasticsearch-6.6.2.tar.gz进入解压目录编辑配置文件:
vi config/elasticsearch.yml #编辑此配置文件
cluster.name: sdy-office-es # 集群名字,只有集群名字一样才能加入到此集群中
node.name: test02 # 当前节点名称
network.host: 0.0.0.0 # 这里设置为 0.0.0.0 为了让其他节点能访问
http.port: 9200 # 获取数据端口 默认就是9200
# 下边为配置集群自动发现节点, 集群中的节点通信端口为9300
discovery.zen.ping.unicast.hosts: ["192.168.50.17:9300","192.168.50.2:9300","192.168.50.4:9300"]
discovery.zen.minimum_master_nodes: 3 # 当前集群有几个能成为master的节点其他两台节点重复以上步骤, 如果集群节点较多,可以直接把当前配置文件scp到其他节点上
分别运行三个节点的elasticsearch:
./bin/elasticsearch 检测运行是否成功: 使用浏览器或curl命令向 ip:9200 发送GET 请求, 如果返回下图这样就运行成功
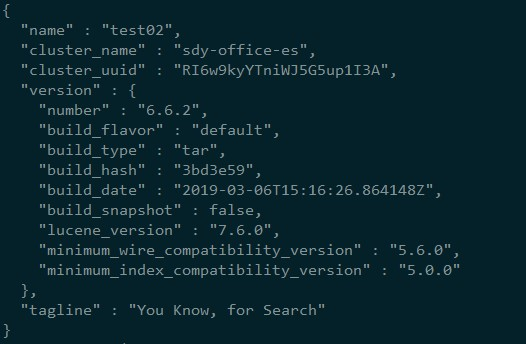
查看集群中的其他节点
curl 127.0.0.1:9200/_cat/nodes
es还提供了接口来查看elasticsearch的相关信息, 请求 ip:9200/_cat 这个接口会返回所有可用的查询接口, 下面贴几个常用的
/_cat/master # 查看当前集群的master节点信息
/_cat/nodes # 查看当前集群所有节点
/_cat/indices # 查看当前集群所有的index
/_cat/health # 查看节点健康状态
等.......
以上所有接口后都可以加 ?v 来获取详细信息Elasticstash安装启用常见问题解决
问题1:用户权限问题, can not run elasticsearch as root
解决方法1: 切换至root用户, 将es的目录变更改给已有用户,之后用此账户操作
chown -R live:live elasticsearch-6.2.4 # 用户和组都要变更 live为用户解决方法2: 切换至root用户, 创建ES 账户,修改文件夹 文件 所属用户 组
问题2:用户最大可创建文件数太小,至少65536
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
解决方法: 修改切换到root用户修改配置 /etc/security/limits.conf 添加下面四行
* hard nofile 65536
* soft nofile 65536
* hard nproc 4096
* soft nproc 4096更改后, 保存退出, 注销当前账户,重新登录之后生效
问题3: 用户最大可创建线程数太小, 最低需要 2048
max number of threads [1024] for user [lish] likely too low, increase to at least [2048]
解决方法: 修改切换到root用户修改配置 /etc/security/limits.d/90-nproc.conf 修改以下配置:
* soft nproc 1024
# 上边内容修改为
* soft nproc 2048问题4: 最大虚拟内存太小
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决方法: 切换到root用户下,在配置文件 /etc/sysctl.conf 下添加下面的配置
vm.max_map_count=655360问题5: ElasticSearch节点之间的jdk版本不一致
org.elasticsearch.transport.RemoteTransportException: Failed to deserialize exception response from stream
解决方法: 统一集群中每个节点的jdk环境
2. logstash 安装配置
官网下载安装包,我这里选择下载6.6.2的版本: artifacts.elastic.co/downloads/l…
解压:
tar -xvf logstash-6.6.2.tar.gz我们新建一个配置文件: test.conf (conf格式)
# 我们先配置不使用redis的配置方式
input {
beats { # 这里的配置为 从filebeat获取日志数据
port => 5044
}
}
filter{
}
output {
elasticsearch { # 这里输出到 elasticsearch 集群
hosts => ["192.168.50.17:9200","192.168.50.2:9200","192.168.50.4:9200"]
index => "syslog_%{+YYYY-MM-dd}" # 这里我们新建一个es索引
}
}
#配置文件分三大块 input, filter, output 组成,其中input和output必须配置,filter可根据自己需求配置启用:
./bin/logstash -f test.conf测试配置文件的格式是否正确:
./bin/logstash -f test.conf -t热加载配置文件(更改配置文件后不需要重启logstash):
./bin/logstash -f test.conf --config.reload.automatic3. Filebeat 安装配置
官网下载安装包:artifacts.elastic.co/downloads/b…
解压:
tar -xvf filebeat-6.6.2-linux-x86_64.tar.gz新建一个配置文件 test.yml:
filebeat.inputs:
- type: log
enables: true
paths:
- /var/log/syslog # 抓取的日志路径
tags: ["syslog"] # 自定义的tags
fields: # 自定义字段
log_from: sys_log
server: test02
fields_under_root: true # 是否要把自定义字段放置根节点
# 这里我们先输出到logstash
output.logstash:
hosts: ["192.168.50.17:5044"]启动:
./filebeat -c test.yml # -c指定自定义的配置文件4. kibana 安装启用
官网下载安装包: artifacts.elastic.co/downloads/k…
解压:
tar -xvf kibana-6.6.2-linux-x86_64.tar.gz进入解压目录编辑配置文件 config/kibana.yml :
server.port: 5601 # 指定端口,默认就是5601
server.host: "192.168.50.17" # 本机ip
elasticsearch.hosts: ["http://localhost:9200"] # elasticsearch集群地址其他配置字段可参考官方文档: www.elastic.co/guide/cn/ki…
启动:
./bin/kibana &启动之后打开浏览器,输入ip:5601 就可以看到kibana已经正常运行啦,到这一步,elk已经搭建完成了, 我们在kibana中点击 Management => Index Patterns => Create index pattern 搜索我们刚刚logstash新建的index, syslog*
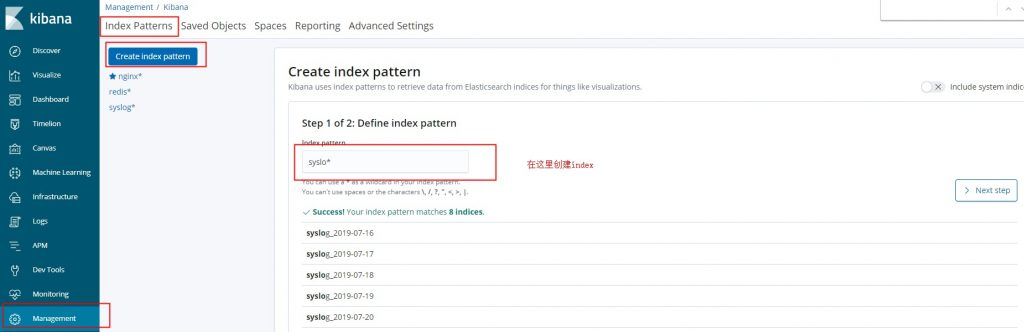
然后在Discover中选择syslog这个索引就可以看到采集到的日志数据啦
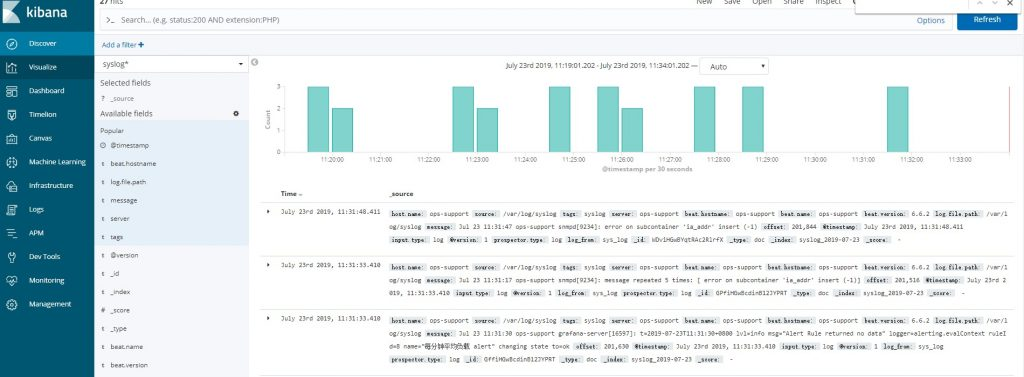
到这里,我们不使用缓存系统的ELK日志收集系统,已经搭建完成, 并已经可以在kibana中看到数据了, 但是目前这种架构, 当日志的数据量突然暴涨 很容易让我们的服务器崩溃, 丢失数据, 所以我们需要引入redis / kafka 来做一个缓冲, 让filebeat的数据先写到 缓存系统, logstash再从缓存系统里去抽取数据。
5. redis 安装配置
我们这里的数据量比较小,所以使用redis就可以了,如果是大型企业 数据量很大, 推荐使用kafka来做缓存。
安装:
sudo apt-get install redis-server 安装完后会自动启用redis, 使用redis-cli 可进入到redis命令行界面, 输入 ping 检查服务是否可用如果返回 PONG 就是正常可用
修改配置文件, /etc/redis/redis.conf
daemonize yes # 后台运行
port 6379 # 运行端口 默认就是 6379
bind 0.0.0.0 # 配置为0.0.0.0 其他节点才能访问
timeout 60 # 超时时间配置完后重启redis服务
sudo service redis restart到这里redis就已经配置好了,我们需要修改filebeat中的 output 和 logstash中的 input 才能让redis起到缓存的作用:
修改filebeat的配置文件 test.yml
filebeat.inputs:
- type: log
enables: true
paths:
- /var/log/syslog
tags: ["syslog"]
fields:
log_from: sys_log
server: test02
fields_under_root: true
output.redis: # 输出到redis
hosts: ["192.168.50.17"]
port: 6379
key: "logs" # 这个是输出到redis时 创建的key, logstash就通过这个key来抽取日志数据
配置完重启下filebeat, 这个时候 数据就已经输入到redis中了, 我们先不配置logstash 进入到redis中 看下是否有数据:
redis-cli # 进入redis
keys * # 查看所有的key这里就能看到我们filebeat中自定义的key => "logs",署名filebeat和redis已经连通了, 我们再配置logstash
修改logstash的配置文件 test.conf
input {
redis { # 使用redis作为数据来源
port => "6379"
host => "192.168.50.17"
data_type => "list"
key => "logs" # 抽取数据时使用的key, 就是filebeat中自定义的key
}
}
filter{
}
output {
elasticsearch {
hosts => ["192.168.50.17:9200","192.168.50.2:9200","192.168.50.4:9200"]
index => "syslog_%{+YYYY-MM-dd}"
}
} 重启logstash, 先kill到logstash的pid, 再启用logstash
我们再进入到redis中查看keys, 这个时候 "logs" 这条数据不见了, 就说明已经被logstash抽取走了, 我们就可以进到kibana中去看数据
四、 ELK 抓取 nginx日志 实例
nginx安装: 自行安装
抓取nginx日志有两种方法, 一种是使用 filebeat自带的nginx模块, 另一种是自己在filebeat中自定义nginx日志路径, 并进行格式化
1. 使用filebeat自带nginx模块
启用nginx模块
./filebeat modules enable nginx启用后可用 下边的命令查看是否启用成功:
./filebeat modules list
# 如果 nginx出现在 Enabled列表中则启用成功
Enabled:
nginx配置nginx 采集模块 vim modules.d/nginx.yml :
- module: nginx
access:
enabled: true
var.paths: /var/log/nginx/*access.log
error:
enabled: true
var.paths: /vra/log/nginx/*error.log
重启下filebeat 后就能在kibana中看到nginx的日志啦
2. 不使用自带nginx模块
实现原理: 我们需要先处理nginx日志格式, 将nginx日志处理成json格式, filebeat再配置采集
配置nginx日志格式, 打开nginx.conf 文件, 将原来的 log_format 这一段注释,添加自定义的格式
log_format log_json escape=json '{ "timestamp": "$time_iso8601", '
'"remote_addr": "$remote_addr",'
'"remote_port": "$remote_port",'
'"scheme": "$scheme",'
'"request_api": "$request_uri",'
'"request_method": "$request_method",'
'"request_time": "$request_time",'
'"request_length": "$request_length",'
'"status": "$status",'
'"body_bytes_sent": "$body_bytes_sent",'
'"http_referer": "$http_referer",'
'"http_user_agent": "$http_user_agent",'
'"http_x_forwarded_for": "$http_x_forwarded_for",'
'"upstream_addr": "$upstream_addr",'
'"upstream_response_time": "$upstream_response_time" }';
access_log /var/log/nginx/access.log log_json; # 使用log_json 格式配置filebeat的配置文件:
filebeat.prospectors:
- type: log
enables: true
paths:
- /var/log/syslog
tags: ["syslog"]
fields:
log_from: sys_log
server: ops-support
fields_under_root: true
# 上边这段是采集系统日志
- type: log
enables: true
paths:
- /var/log/nginx/*.log
tags: ["nginx"] # 自定义tags
fields: # 自定义字段
log_from: nginx
server: ops-support
fields_under_root: true
json.keys_under_root: true # 将json日志中的字段放置 根节点
json.overwrite_keys: true # 是否要覆盖原有的key,设为true后,就能把filebeat默认的key值给覆盖
output.redis:
hosts: ["192.168.50.17"]
port: 6379
key: "logs"我们采集到nginx日志后,默认是和系统日志在一个索引下, 这样不好看, 我们要在logstash中处理一下:
input {
redis {
port => "6379"
host => "192.168.50.17"
data_type => "list"
key => "logs"
}
}
output {
if "nginx" in [tags] { # 我这里用自定义tags 来判断日志来源, 你也可以用其他字段来判断
elasticsearch {
hosts => ["192.168.50.17:9200","192.168.50.2:9200","192.168.50.4:9200"]
index => "nginx_%{+YYYY-MM-dd}"
}
}
else {
elasticsearch {
hosts => ["192.168.50.17:9200","192.168.50.2:9200","192.168.50.4:9200"]
index => "syslog_%{+YYYY-MM-dd}"
}
}配置完成后你需要在kibana中添加nginx的索引, 添加后你就可以看到两个索引了,选择nginx就可以看到nginx的日志啦
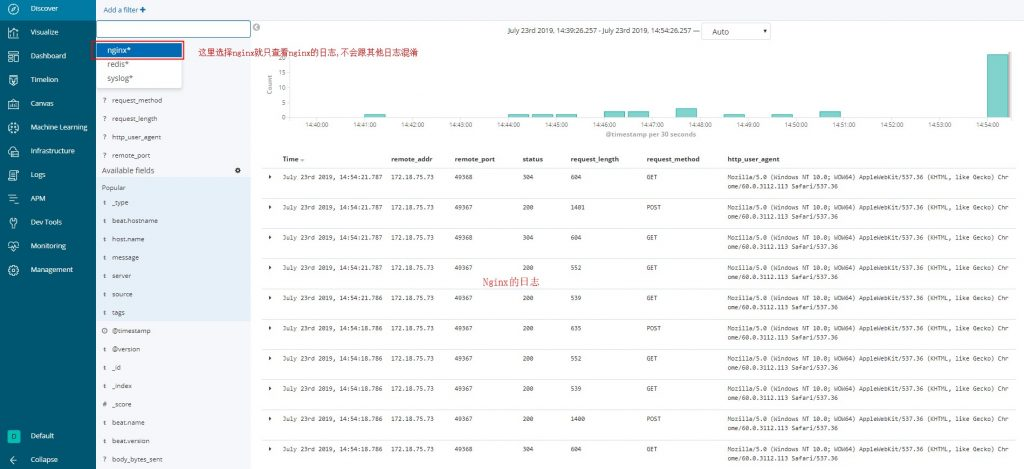
到这里nginx的日志采集就OK啦!
~ OVER ~
