

前面我们已经讲了《企业埋点体系搭建方法论及实践经验(1)》,感兴趣的朋友可以点击阅读。
二、如何高效、准确地实现埋点设计
1、什么是埋点
埋点是为了满足快捷、高效、丰富的数据应用而做的用户行为过程及结果的记录。神策将每一个事件分为 Who、When、 What、Where、How 等维度进行记录,即用户在什么时间做了什么样的事情,当时他做这个事情的位置和场景是怎样的等。 先通过两个例子来了解下。
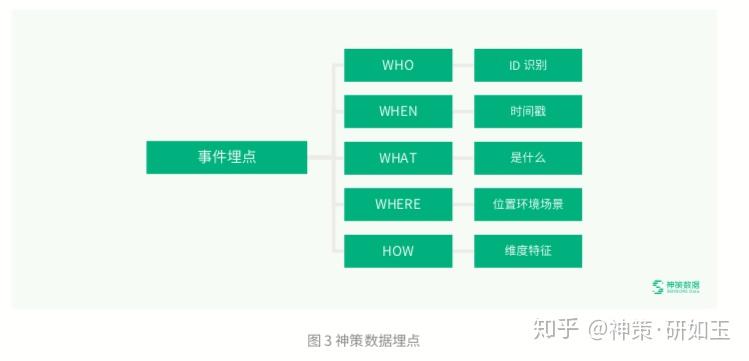
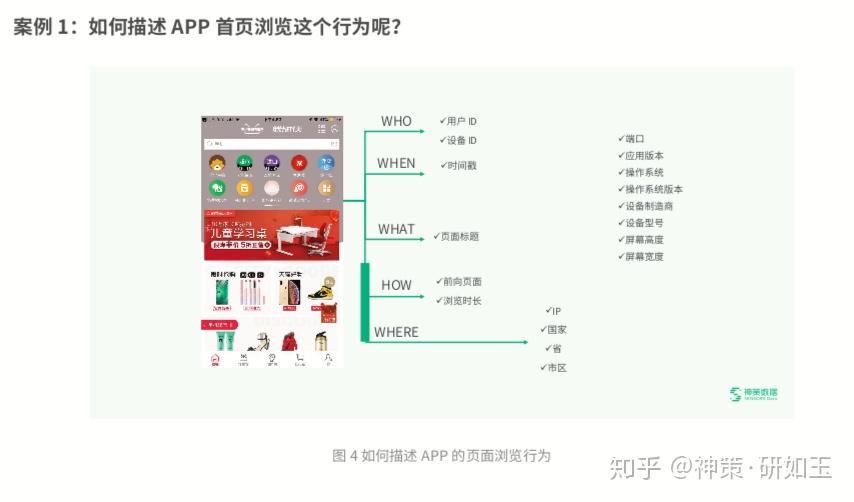
● WHO:即参与这个事件的用户是谁。用户进入一个功能页面,我们要知道进来的用户是谁,并且同一个用户以不同身 份状态在不同的端操作时,都能是识别出来就是同一个人,一套合适且完备的 ID-mapping 解决方案,对于提高用户行为 分析的准确性、完整性有非常大的影响,对用户数量的统计、以及漏斗、留存、路径等期望用户行为流相关的分析尤其明显。 同一用户的识别出现断层,会导致以上分析数据不准确或不可用。因此,我们在进行任何数据接入之前,都应当先确定如 何来标识用户。以 APP 的页面浏览为例,在互联网时代,用户都以设备为载体,因此可通过设备 ID 来记录;具体业务场 景下,用户自身也带着业务属性,可通过 user_id、login_id 等类似的业务身份标识来记录,确保单个用户在多设备之间 的行为可以打通。总之,关于“WHO”大家要想清楚要如何准确地标识客户,一个项目的 ID 机制要在项目开始时特别慎 重地进行确认,之后技术人员需要遵循这个规范来埋点,否则后期修改 ID 机制、清洗 ID 错误都是一个非常麻烦的事情。 神策分析关于用户标识的原理及用户标识方案,已经有了非常全面的各行业、各业务类型下的 ID-mapping 解决方案。
● WHEN:即这个事件发生的时间,神策分析通过自动采集的时间戳属性来记录。
● WHAT:WHAT 描述了一个事件具体是什么,这里就是神策事件设计模型的一个独特的地方。在这里场景下,按照神策 的事件设计规范,事件是“APP 页面浏览”,而不是“首页的浏览”,通过增加『页面名称』这个属性来区分究竟浏览的是 哪个具体的页面,大家可以思考下,为什么是这种设计思路呢?实际上,一般一个产品会有 N 多个不同的页面,如果将每 个页面都单独定义为一个事件,那么后台的事件将会有几百上千个,业务人员在使用时会非常的麻烦,筛选事件的成本也 会非常大。神策分析在做埋点需求设计时,针对所有类似的触发机制和场景的事件,都会做聚合处理,因此企业的事件量 通常会维持在 30-50 个左右,配以神策的归类机制,极大方便企业进行事件管理,给业务人员带来极强的易用性。
● HOW:即用户从事这个事件的方式,HOW 关联的是与事件强相关的属性内容。这是企业在事件梳理过程中非常容易出 纰漏的地方。比如在 APP 页面浏览或者 APP 的点击事件上,经常会出现找不到按钮,或者无法定位页面的情况,原因就 是研发的规范性较差,比如对页面标题的定义不规范等。神策针对页面标题做了自定义和规范,主要包括两方面:一是所 有页面本身都有名字,并且与 APP 的页面是同一个名字,如此保证业务同学定位该页面时很容易找到;一是针对 iOS 与安 卓经常出现两个同样的页面命名不一样的情况,神策分析会做维度字典的规整,如此,其可用性能够满足绝大多数的应用 场景。
● WHERE:IP、国家、省、市区等用户的操作属性,神策分析都是会在基础信息采集上做加工衍生,可以做到自动采集。 端口、应用版本、操作系统、操作系统版本、设备制造商、设备型号、屏幕高度、屏幕宽度这些前端维度与属性,神策分 析的采集也是默认获取的。对于后端自定义采集来说,则需要根据分析需求进行判断和梳理,确认是否需要通过接口透传 等方式获取到对应这些前端属性,否则将会影响后续的多维分析。

这是一个比较典型的业务类埋点案例。除了前面说到的一些要点外,这里重点介绍下业务类需求设计时的独特性。首先, 订单的流水会有一个唯一标识,类似前面 APP 页面浏览中的『页面名称』,是订单的唯一标识,这是必须要进行采集的, 否则无法与后台数据进行匹配,因为后台的数据通常唯一标识是按照订单的流水号。
针对支付订单事件,强关联的属性也会在 HOW 中,比如支付金额、支付方式(信用卡 or 储蓄卡 or 微信等)、所属银行、 是否成功。“是否成功”是一个非常典型的属性,我们判断用户“是否支付成功”,其触发机制必须等到前端拿到后端服务 器处理结果后,再进行上报。如果我们希望了解的是,“用户是否有意愿支付”,那么当用户点击“支付订单”这个按钮时, 进行前端采集即可,这部分在接下来的内容还会做重点介绍。
这个例子中的“是否成功”属性也再次提醒我们:事件采集显然是要与用户的分析诉求强相关的。在同一个事件中,对其 业务属性的价值定义和分析应用的场景,与技术端去做采集的触发时机是强相关的。这需要对接人有特别清晰的定义,才 能保证埋点的正确性。
2、埋点设计的思路与方法
(1)埋点采集的顶层规则设计
事件设计的顶层规则包括用户识别机制、同类抽象、采集一致、渠道配置四方面,这是保证数据采集的准确性、数据环境 可用性的基础。下面进行详细介绍:
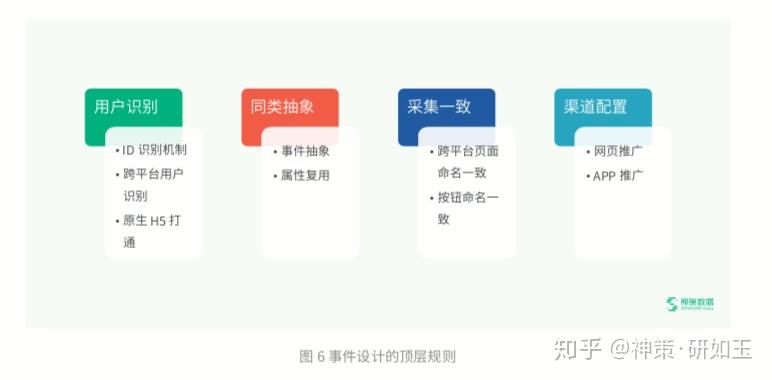
用户识别机制:用户识别机制的混乱会导致两个结果:一是数据不准确,比如 UV 数据对不上;二是涉及到漏斗分析环 节都会出现异常。因此企业应该做到:a. 要严格规范 ID 本身的识别机制;b. 跨平台用户识别。
神策分析 1.14 版本支持用户跨平台的识别,比较典型的应用场景是跨渠道推广,可打通用户在 H5 端与 APP 端的操作,无 论是匿名还是登录状态下都能唯一识别;另外,神策分析 1.14 版本支持用户原生 H5 的打通,用户从 APP 到 H5 页面,能 够无缝实现用户的漏斗的自动关联。
同类抽象:同类抽象包括事件抽象和属性复用。前面讲到了事件抽象,即将页面的浏览与点击进行聚合,以保证整个系 统环境的可用性。关于属性复用,属性在很多情况下也是可以复用的,比较典型的场景是“申请验证码”这个功能,用户 可能会在注册时、登录时、修改密码时等多场景下“申请验证码”,那么可以将其抽象为一个事件⸺申请验证码,并在属 性字段增加“场景”,借此从场景来区分用户究竟在什么情况下申请验证码。
采集一致:采集一致包括两点,一是跨平台页面命名一致,二是按钮命名一致。作为业务人员,最直观的感受是平台界 面展示的事件和属性,因为业务人员不了解埋点的规则,当其在平台上搜索想要的数据时,通常是按照页面来进行搜索, 如果命名不规范,很可能会拿一个错误的数据去做后续分析。作为系统的管理员,要规避这样的问题,才能保证企业内部 能够真正用起来。
渠道配置:神策数据有一套渠道配置的方法,实现渠道的监测,这里不做详细介绍。
(2)埋点采集事件及属性设计
在埋点设计环节,整体可以根据需求梳理和转化的路径,分为业务分解、分析指标、事件设计、属性设计的四个阶段。其中, 业务分级和分析指标,是事件设计和属性设计的关键信息输入,通过对业务场景和分析需求的梳理,确认埋点的内容和范围, 而事件和属性设计,则是将这些业务分析诉求,转换成面向开发的需求语言,让开发能看懂需要他在什么场景和规则下采 集哪些数据。接下来,我们以优惠券营销场景为案例,讲述该如何进行埋点设计。
例:优惠券营销场景的事件设计

业务拆解:做事件设计之前,需要先做业务拆解,梳理和确认业务流程、操作路径和各种不同的细分场景。一般的拆解 思路是,根据用户在产品上具象的操作方式和流程,定义用户行为路径。比如在优惠券营销场景中,核心环节是券投放 - 券使用 / 券过期,那么业务拆解则应该是“领取优惠券”“使用优惠券”“优惠券过期”,领取优惠券又会有主动领取、系统 直接发放两种方式,使用优惠券是在下单时进行抵扣的,优惠券过期是在券即到了失效期还没有使用的情况下触发的。
分析指标:在业务拆解之后,对特定的事件,我们要思考,这些事件会用于哪些指标的分析,具体分析时的核心维护是 哪些。在该场景中,优惠券的领取率、使用率、促 GMV 成交金额、优惠比例、ROI 等都是关心的指标,尤其以活动页面投 放的场景来看,用户通过什么方式进入到领券活动页,优惠券的领取率是多少,不同优惠券的领取率是否有差异,就是领 取这个环节的核心指标。
事件设计:在定义分析指标之后,就需要从对应的指标涉及中抽取事件和事件的关联属性信息了。回到刚刚领取优惠券 的场景,从用户进入领取优惠券的页面、用户点击优惠券领取、使用优惠券成交等行为,这些都需要进行埋点,才能算出 优惠券的领取率、使用率、促 GMV 成交金额等指标。这里面涉及 4 个行为,其中进入优惠券页面本身是一个页面浏览行为 ,且不涉及到额外的一些页面特定属性,那么上报至页面浏览事件即可。领取优惠券的行为,涉及到大量优惠券本身的属 性信息需要记录,因此考虑单独一个事件。而使用优惠券成交,本质上是成交时是否使用优惠券的状态差异,因此不需要 单独一个事件,而是将是否使用优惠券、优惠券抵扣金额、优惠券类型等作为成交的属性。在事件设计的整体框架上,建 议大家按照功能模块 - 业务流程的方式,系统性的梳理业务场景以及对应的分析需求,再对事件设计做一层抽象归类。整 体来说,事件设计可以整体分为三大类,供大家在做具体的事件设计时参考:
● 常规通用采集事件:APP 启动、APP 退出、页面浏览、点击事件等等,这些基本涵盖了用户基本行为操作的主要部分, 神策分析目前对这些通用事件做了全埋点采集,基本上可以满足大多数行为记录的需求;
● 重要点击事件:由于全埋点经常会出现点击事件的内容等属性采集不完全,可用性不高,建议对重要的点击事件进行梳 理,根据具体的点击事件的类型以及个性化属性,进行归类采集,常见的点击事件有 Banner 位点击、icon 点击、频道 Tab、功能重要操作点击等事件;
● 业务流程:除了以上常规通用采集和重要点击事件之外,多数业务流程会有些特定的个性化事件,比如注册的输入手机 号、发送验证码、输入验证码,或者具备较多丰富属性的业务流程,比如电商主流程一般都需要记录丰富的商品、活动、 供应商、店铺等字段信息,建议这些都作为额外的自定义事件进行采集,以确保重要事件不遗漏、属性采集都完备。

属性设计:回到刚刚领券的场景,要深入了解各个券的吸引力和营销效果,需要对比分析不同券的数据表现,那么关于 券的维度属性,例如优惠券 ID、优惠券类型、优惠券面值、优惠券适用条件、优惠券有效期等属性就非常关键了。值得强 调的点是,在属性设计时,除了维度全面之外,还必须保证每一个属性都是独立采集,比如优惠券类型和领取方式不合并 字段,以保证后续灵活的下钻分析。以下是埋点采集中常见事件属性的类型举例,主要包含用户属性、事件属性、对象属 性和环境属性四大类,并列举了一些常见的字段供参考,帮助大家完善和核对属性设计的完善性。当然,要对属性设计做 到游刃有余,核心还是要熟悉业务场景和分析诉求,知道哪些维度会影响业务的数据表现,做到心中有数,才会游刃有余。

3、埋点采集方式和触发时机
(1)常见埋点采集方式
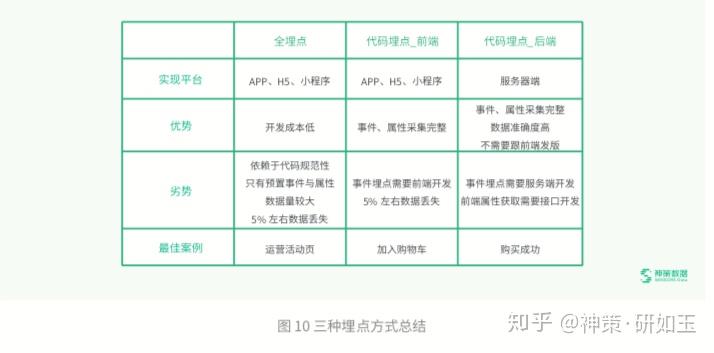
目前埋点采集业态下,常见的采集方式,包含全埋点、代码埋点 - 前端、代码埋点 - 后端三种,以下是这三种方式在主要 维度的对比,方便大家在做事件设计的时候,能根据需求和场景,科学的选择最合适的埋点方式。
(2)埋点事件的触发逻辑类型
具体到一份埋点需求文档中的具体事件的采集,除了确定事件和事件属性,还必须要定义清楚事件的触发逻辑,即什么样 的情况下触发数据的采集和上报。从事件上报的触发逻辑上面来讲,可分为前端触发上报、前端获取后端结果后上报、后 端触发上报、后端获取前端属性后上报四个比较类别,如下图所示,下面以京东下单流程中的“购买成功”为例,详细介 绍下埋点事件的触发逻辑类型。
例:以购买成功为例看事件上报的触发逻辑

前端触发就上报:点击“去支付”按钮就触发,这是最常见的前端采集方式,如果业务方是想了解的是“用户是否有 意愿支付”,那么当用户点击“支付订单”这个按钮时或者发出支付请求就触发采集即可。这是时机埋点采集时最常用的一 种方式。
前端获取后端结果后上报:这种方式一般是由于除了记录用户操作外,还需要获取用户操作的结果,比如需要收到 后端结果的返回,以判断用户是否支付成功,以及失败情况下具体的报错原因,那么其触发机制必须等到前端拿到后端服 务器处理结果后,再进行上报。
后端触发就上报:这种方式是指后端处理后直接上报,比如后端处理付款请求出结果时直接后端触发上报。采用这种 方式的主要好处是数据不会出现漏报,但也由于是直接后端上报,基本是拿不到用户的设备终端及软硬件环境属性的,比 如用户在支付时用的是什么设备、网络环境是什么等信息。
后端获取前端属性且触发后上报:这种情况就是为了解决后端埋点的软硬件环境属性问题,让前端在用户点击“去 支付”时,将相应的属性一并传回服务器,服务器发生“支付成功”时,带上相应的前端属性上报数据。当然这种方式理 论上是数据准确度、完备性最高的,但同时这种方式的采集成本会比较高,意味着所有端的前后端接口需要做变更,建议 是只在数据准确性、前端属性获取两个需求都非常强时采用。
通过以上的描述大家也能看得出来,每种触发时机有各自的优劣势,在具体设计触发时机中,决定具体采用哪种方式的因 素,特别值得关注:业务含义、ID 识别机制、前端软硬件环境属性获取、业务处理结果获取、数据准确性要求。神策团队 在给企业做事件设计时也会格外关注这些点;在后续企业自己做事件设计时候,企业也应该从这几个方面给研发同学讲解 清楚,以保证采集的数据更符合场景诉求。
免费下载《企业埋点体系搭建方法论及实践经验》白皮书:
方法一:关注本专栏,关注神策数据·用户研究那些事儿
